基于深度卷积神经网络模型的大规模人脸识别方法与流程
本发明属于计算机视觉、人工智能技术领域,具体涉及大规模人脸识别方法。
背景技术:
在当前机器学习技术及计算机硬件性能高速提升的情况下,近年来计算机视觉、自然语言处理和语音识别等应用领域取得了突破性进展。人脸识别作为计算机视觉领域一项基础的任务,其精度也得到了大幅提升。
在过去的几年当中,许多大型科技公司以及著名的研究机构提出了许多高效的人脸识别的方法,在行业内最著名的人脸评测集LFW上的准确率超过了99%。这样显著的成绩主要归功与两个方面:深度学习和海量数据。深度学习解决了人脸识别当中的特征表达的问题,相比传统的方法,能够更加全面地学习人脸的特征。海量的训练数据直接提升了人脸识别的精度。
在实际运用场景中,当需要识别的对象在百万量级的数据库当中,LFW评测集上表现接近完美的模型性能也大打折扣。MegaFace评测集是第一个百万级别的人脸评测数据集,更加接近现实生活。
目前提升人脸识别性能的方法主要有三种:
(1)增加训练数据;
(2)通过多任务学习的方式训练模型;
(3)利用度量学习找到更加合适的学习方法。
通过海量的数据训练能够提升人脸识别模型的性能,然而收集大量的人脸数据是一件极其困难的工作;训练多个模型,然后进行模型混合的方法会让人脸识别的过程变得过于复杂,不利于实际场景中的运用;度量学习对训练模型的技巧要求太高,而且模型的泛化能力不强。因此通过一种高效的深度卷积神经网络模型来提升人脸识别精度成为了一种新的有效的途径。
技术实现要素:
本发明的目的在于提供一种基于深度卷积神经网络模型的大规模人脸识别方法,来提升人脸识别精度,以解决当前实际运用场景下大规模人脸识别困难的问题。
本发明首先提出一个全新的基于残差学习的深度卷积神经网络模型,此模型能够学习到更多的特征,更好地进行特征表达,更加适合大规模的人脸识别任务。
本发明提出的大规模人脸识别方法,采用上述基于残差学习的深度卷积神经网络模型,实现的硬件平台需要一张NVIDIA TITANX显卡。本发明首先对数据集图片进行预处理,然后训练深度卷积神经网络模型,最后通过深度卷积神经网络模型提取特征,利用特征向量计算相似度,实现人脸识别。具体包括3个过程:预处理图片、训练深度卷积神经网络模型、面向大规模人脸识别:
步骤1、预处理图片
(1)检测图片中的人脸;
(2)检测人脸中的5个关键点(两眼、鼻尖、两边嘴角);
(3)进行人脸对齐操作;
(4)将人脸图片大小归一化,例如把人脸图片大小归一化至112×96。
步骤2、训练深度卷积神经网络模型
(1)搭建基于残差学习的深度卷积神经网络模型;
(2)前向传播计算损失误差(SoftMax Loss);
(3)反向传播损失误差(SoftMax Loss)更新模型参数;
(4)获得训练好的深度卷积神经网络模型。
步骤3、大规模人脸识别
(1)测试图片通过深度卷积神经网络模型;
(2)提取特征向量;
(3)利用特征向量进行相似度计算;
(4)输出识别结果。
步骤2训练深度卷积神经网络模型,具体介绍如下:
(1)搭建本发明提出的基于残差学习的深度卷积神经网络模型:
本发明提出的模型由卷积层、下采样层、残差层以及全连接层组成,其中残差层由两路数据(一路是若干个卷积层级联的数据和一路原始数据)相加求和构成,并且网络结构中每一个卷积层之后都做批量归一化(Batch Normalization)操作;
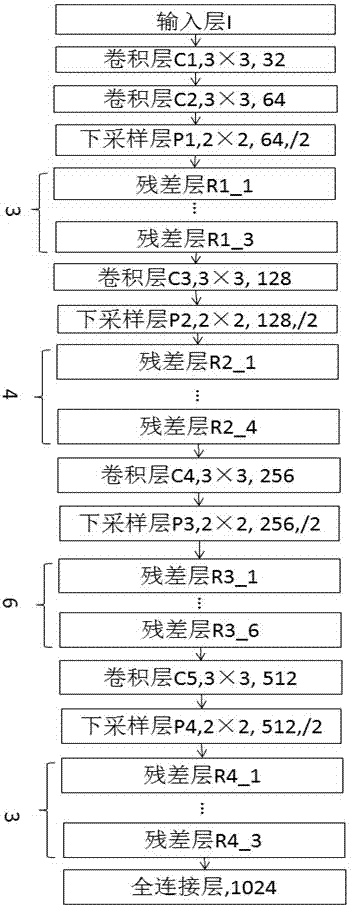
具体的网络模型从输入层I开始,依次经过卷积层C1,卷积层C2,下采样层P1,残差层R1_1,残差层R1_2,残差层R1_3,卷积层C3,下采样层P2,残差层R2_1,残差层R2_2,残差层R2_3,残差层R2_4,卷积层C4,下采样层P3,残差层R3_1,残差层R3_2,残差层R3_3,残差层R3_4,残差层R3_5,残差层R3_6,卷积层C5,下采样层P4,残差层R4_1,残差层R4_2,残差层R4_3,最后到全连接层F1;
(2)用10575个人的49万张图片作为训练数据,分批次输入搭建好的网络模型;
(3)训练集图片通过模型,前向传播用全连接层参数计算损失误差(SoftMax Loss);
(4)将损失误差(SoftMax Loss)反向传播更新模型参数;
(5)获得训练好的深度卷积神经网络模型。
步骤3面向大规模人脸识别,具体介绍如下:
(1)将一百万张人脸图片作为测试数据,依次输入训练好的网络模型;
(2)取网络模型中全连接层的1024个参数作为人脸图片的特征向量;
(3)利用特征向量进行相似度计算;
(4)输出识别结果。
本发明方法的主要特点有:
(1)利用此模型在百万级别的人脸识别任务中取得了极好的效果;
(2)模型训练数据量少,仅使用不到50万张人脸图片作为训练数据;
(3)模型结构简单,不需要使用模型混合、多任务训练以及度量学习等方法。
本发明方法利用了深度卷积神经网络学习能力强和残差学习收敛好的特性,在百万级人脸数据库中检索人脸这项高难度的任务中取得很高的准确率。相比于传统的计算机视觉方法,本发明方法利用深度卷积神经网络结构,充分学习输入图片特征,更加完整地进行图片特征表达,大幅提升了人脸识别的精度,尤其是在百万级人脸识别任务中取得了优秀的成绩。并且不同于目前广泛运用的度量学习、模型混合和多任务学习的方法,本发明方法提出的深度卷积神经网络模型简单高效,有效解决了百万级人脸识别任务中准确率不高以及模型搭建复杂的问题。
在面向大规模人脸识别领域,本发明较之基线模型在准确率方面得到了极大提升,在百万级人脸数据库中人脸检索的准确率达到了74.25%。
附图说明
图1一种面向大规模人脸识别的残差学习深度网络模型流程图。
图2本发明提出的基于残差学习的深度卷积神经网络模型结构图。
图3残差层网络结构图。
具体实施方式
以下结合附图解释运用了本发明,基于残差学习的深度卷积神经网络模型在百万级别的人脸识别任务中的具体实施,实现的具体运算步骤如附图1所示。
1、预处理图片
首先利用图片处理工具MTCNN[19]检测图片中的人脸,然后利用MTCNN检测人脸中的5个关键点(两眼、鼻尖、两边嘴角),然后人脸对齐方法[20]进行人脸对齐操作,最后将处理过的图片大小归一化至112×96。
2、搭建本发明提出的基于残差学习的深度卷积神经网络模型
利用深度学习框架Caffe,搭建本发明提出的基于残差学习的深度卷积神经网络模型,如附图2所示。此模型由卷积层,下采样层,残差层以及全连接层组成,其中残差层由两路数据(一路是若干个卷积层级联的数据和一路原始数据)相加求和构成,如附图3所示,并且网络结构中每一个卷积层之后都做批量归一化(Batch Normalization)操作;
其中,输入层I大小为112×96×3,卷积层C1(卷积核大小为3×3,滑动步长为1,填充为0,输出为32),卷积层C2(卷积核大小为3×3,滑动步长为1,填充为0,输出为64),下采样层P1(最大池化,大小为2×2,滑动步长为2,输出为64),残差层R1_1(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为64)级联的数据和一路原始数据相加),残差层R1_2(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为64)级联的数据和一路原始数据相加),残差层R1_3(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为64)级联的数据和一路原始数据相加),卷积层C3(卷积核大小为3×3,滑动步长为1,填充为0,输出为128),下采样层P2(最大池化,大小为2×2,滑动步长为2,输出为128),残差层R2_1(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为128)级联的数据和一路原始数据相加),残差层R2_2(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为128)级联的数据和一路原始数据相加),残差层R2_3(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为128)级联的数据和一路原始数据相加),残差层R2_4(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为128)级联的数据和一路原始数据相加),卷积层C4(卷积核大小为3×3,滑动步长为1,填充为0,输出为256),下采样层P3(最大池化,大小为2×2,滑动步长为2,输出为256),残差层R3_1(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为256)级联的数据和一路原始数据相加),残差层R3_2(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为256)级联的数据和一路原始数据相加),残差层R3_3(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为256)级联的数据和一路原始数据相加),残差层R3_4(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为256)级联的数据和一路原始数据相加),残差层R3_5(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为256)级联的数据和一路原始数据相加),残差层R3_6(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为256)级联的数据和一路原始数据相加),卷积层C5(卷积核大小为3×3,滑动步长为1,填充为0,输出为512),下采样层P4(最大池化,大小为2×2,滑动步长为2,输出为512),残差层R4_1(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为512)级联的数据和一路原始数据相加),残差层R4_2(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为512)级联的数据和一路原始数据相加),残差层R4_3(一路由3个卷积层(卷积核大小为3×3,滑动步长为1,填充为0,输出为512)级联的数据和一路原始数据相加),最后,全连接层F1(维度为1024)。
3、把训练数据输入搭建好的网络模型
用人脸数据集CASIA-WebFace作为训练数据,该数据集来自10575位名人的49万张图片。将训练集图片做水平翻转操作,以实现数据增强。训练数据分批次进入网络模型进行训练,每次进入网络模型的训练图片批次大小为64,一共迭代训练7万次。
4、训练集图片通过模型,用全连接层参数计算损失误差(SoftMax Loss)。
5、将计算得到的损失误差(SoftMax Loss)反向传播更新模型参数。
6、获得面向大规模人脸识别的残差学习深度网络模型。
7、在百万级人脸识别评测集MegaFace上进行测试。
利用MegaFace团队提供的测试代码,将一百万张人脸图片作为测试数据,依次输入训练好的基于残差学习的深度神经卷积网络模型,取模型中全连接层的1024个参数作为特征向量。对输入图片的特征向量计算余弦距离,把余弦距离按照大小排序,通过余弦距离的大小输出人脸识别结果。人脸识别首位准确率(Rank 1 Face Identification accuracy)为74.25%,处于当前国际领先水平,如下表1所示。
表1、本发明方法在MegaFace评测集上,人脸识别首位准确率与业内先进方法对比
。
参考文献
[1] Florian Schroff, Dmitry Kalenichenko, and JamesPhilbin, “Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015, pp. 815–823.
[2] Omkar M Parkhi, Andrea Vedaldi, and Andrew Zisserman, “Deep face recognition,” in British Machine Vision Conference, 2015, vol. 1, p. 6.
[3] Yi Sun, Xiaogang Wang, and Xiaoou Tang, “Deeplearning face representation by joint identificationverification,” arXiv preprint arXiv:1406.4773, 2014.
[4] Gary B Huang, Manu Ramesh, Tamara Berg, and ErikLearned-Miller, “Labeled faces in the wild: A database for studying face recognition in unconstrained environments,” Tech. Rep., Technical Report 07-49, Universityof Massachusetts, Amherst, 2007.
[5] Ira Kemelmacher-Shlizerman, Steven M Seitz, DanielMiller, and Evan Brossard, “The megaface benchmark:1 million faces for recognition at scale,” in Proceedingsof the IEEE Conference on Computer Vision and PatternRecognition, 2016.
[6] Yi Sun, Xiaogang Wang, and Xiaoou Tang, “Deep learning face representation from predicting 10,000 classes,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 1891–1898.
[7] Iacopo Masi, Anh Tuan Tran, Jatuporn Toy Leksut, TalHassner, and Gerard Medioni, “Do we really need tocollect millions of faces for effective face recognition,”arXiv preprint arXiv:1603.07057, 2016.
[8] Yandong Wen, Kaipeng Zhang, Zhifeng Li, andYu Qiao, “A discriminative feature learning approachfor deep face recognition,” in European Conference onComputer Vision. Springer, 2016, pp. 499–515.
[9] Dong Yi, Zhen Lei, Shengcai Liao, and Stan Z Li,“Learning face representation from scratch,” arXivpreprintarXiv:1411.7923, 2014.
[10] Dong Chen, Xudong Cao, Liwei Wang, Fang Wen, andJian Sun, “Bayesian face revisited: A joint formulation,”in European Conference on Computer Vision. Springer,2012, pp. 566–579.
[11] Brendan F Klare, Ben Klein, Emma Taborsky, AustinBlanton, Jordan Cheney, Kristen Allen, Patrick Grother,Alan Mah, Mark Burge, and Anil K Jain, “Pushing thefrontiers of unconstrained face detection and recognition: Iarpa janusbenchmark a,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2015, pp. 1931–1939.
[12] Yandong Guo, Lei Zhang, Yuxiao Hu, Xiaodong He,and Jianfeng Gao, “Ms-celeb-1m: A dataset and benchmark forlarge-scale face recognition,” in EuropeanConference on Computer Vision. Springer, 2016, pp.87–102.
[13] Vinod Nair and Geoffrey E Hinton, “Rectified linearunits improve restricted boltzmann machines,” in Proceedings of the 27th International Conference on Machine Learning (ICML-10), 2010, pp. 807–814.
[14] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and JianSun, “Delving deep into rectifiers: Surpassing humanlevel performance on imagenet classification,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 1026–1034.
[15] Sergey Ioffe and Christian Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” arXiv preprint arXiv:1502.03167, 2015.
[16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and JianSun, “Deep residual learning for image recognition,”arXiv preprint arXiv:1512.03385, 2015.
[17] Bart Thomee, David A Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li, “The new data and new challenges in multimedia research,” arXiv preprint arXiv:1503.01817, vol. 1, no. 8, 2015.
[18] Hao Ye, Weiyuan Shao, Hong Wang, Jianqi Ma,Li Wang, Yingbin Zheng, and Xiangyang Xue, “Facerecognition via active annotation and learning,” in Proceedings of the 2016 ACM on Multimedia Conference.ACM, 2016, pp. 1058–1062.
[19] Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, andYu Qiao, “Joint face detection and alignment usingmultitask cascaded convolutional networks,” IEEE Signal Processing Letters, vol. 23, no. 10, pp. 1499–1503,2016.
[20] Xiang Wu, Ran He, and Zhenan Sun, “A lightened cnnfor deep face representation,” in 2015 IEEE Conference on IEEE Computer Vision and Pattern Recognition(CVPR), 2015.
[21] Yangqing Jia, Evan Shelhamer, Jeff Donahue, SergeyKarayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell, “Caffe: Convolutional architecture for fast feature embedding,” in Proceedings ofthe 22nd ACM international conference on Multimedia.ACM, 2014, pp. 675–678.。
- 还没有人留言评论。精彩留言会获得点赞!