基于上下文感知主题的查询表示及混合检索模型建立方法与流程
本发明涉及互联网信息检索技术领域,尤其涉及一种基于上下文感知主题模型的查询表示及混合检索模型建立方法。
背景技术:
查询表示一直是信息检索领域的核心,其中最常见的问题是用户查询太短(仅包含几个关键词),容易造成检索过程中相关文档与查询不匹配。比如对于“缺水”这个用户查询,如果文档中含有“干旱”等与查询相关的词,虽然相关性很高,但由于不含原始的查询关键词“缺水”,最终匹配度将会很低,进而影响查询的准确率。
常见的解决方法是基于伪相关反馈的查询扩展。该方法建立在初步检索结果的基础上,假设排在前面的K个文档(简称为“伪相关反馈文档”)是与原查询相关的,其中的关键词可以采用相关算法提取出来用于查询扩展表示。然而该方法是无监督的,容易带来一些与查询无关的词。虽然理论上可以采用有监督的分类方法,综合考虑扩展词的多种特征,挑选出真正与查询相关的词。然而,这种方法依赖于特征工程和标注训练集,实际应用的代价较高。
最近一些研究开始关注如何利用各种上下文信息来缓解查询表示中的无关扩展词引入问题。上下文信息来源主要包括高质量的外部数据源(如百科全书,领域本体等)和基于数据集本身的伪相关反馈文档。前者由于仅适用部分查询,且外部数据源大多情况下更新慢,获取困难,所以实际应用并不广泛。而后者基于数据集自身的伪相关反馈文档实际上也提供了对查询的上下文背景描述,具有更大的研究前景。比如,对于“缺水”这一查询,伪相关反馈文档1描述:“英国未来几年将面临缺水问题,所以请节约用水,修复好你的水龙头。”;伪相关反馈文档2描述:“旱作农业:一种缓解干旱和缺水问题的方法”。这两篇都是关于缺水问题的应对措施,这些上下文信息都可以用来辅助查询表示。然而现有的扩展词选取方法一般只考虑了扩展词与原查询词在伪相关反馈的上下文窗口中的共现度,仍然存在以下问题:(1)需要显式地选择哪些词用作最终查询扩展,在无监督的情况下依然会引入一些无关词,甚至是“有害词”。比如:在涉及各种环境资源的文章中,关键词“缺水”出现较频繁,但其上下文中也会出现类似的“水力发电”、“天然气”等,会偏离原始查询,降低查询的准确度;(2)最终查询表示依然基于词典空间,忽略了查询隐含的语义信息,如潜在的主题;(3)基于这种查询表示的检索模型主要考虑关键词匹配,而忽略了文档与查询在语义层次上的匹配。
技术实现要素:
本发明的目的是针对现有技术的不足而提出的一种基于上下文感知主题模型的查询表示及混合检索模型设计方法,在查询表示中融入基于伪相关反馈的上下文主题信息,从而在原有基于关键词匹配的检索模型基础上增加主题匹配,提升检索结果的准确性。
本发明提出了一种基于上下文感知主题的查询表示及混合检索模型建立方法,包括如下步骤:
步骤一:基于查询的关键词集合,获取所述查询的伪相关反馈文档,从所述伪相关反馈文档中选取与所述查询相关的上下文;
步骤二:引入上下文感知主题模型,将所述上下文融入所述上下文感知主题模型中,基于语料库主题挖掘所述上下文窗口所隐含的主题信息,得到其相应的主题向量;
步骤三:将所述查询以所述主题向量与所述关键词集合联合表示;基于所述主题向量和所述关键词集合,建立混合检索模型,得到最终的检索得分。
本发明提出的所述基于上下文感知主题的查询表示及混合检索模型建立方法中,步骤一中将所述伪相关反馈文档划分成多个滑动窗口,并计算出每个窗口与所述查询的相关性,取相关性高于阈值的窗口作为与所述查询相关的上下文窗口。
本发明提出的所述基于上下文感知主题的查询表示及混合检索模型建立方法中,所述与查询相关的上下文选取阈值为该查询下所有窗口相关性的平均值。
本发明提出的所述基于上下文感知主题的查询表示及混合检索模型建立方法中,所述上下文感知主题模型是根据查询相关上下文及整个语料库所设计,利用所述上下文感知主题模型在主题建模过程中假设上下文窗口和其所在的伪相关反馈文档共享同样的主题分布,得到上下文的主题向量。
本发明提出的所述基于上下文感知主题的查询表示及混合检索模型建立方法中,所述伪相关反馈文档使用检索模型关键词匹配得分计算获得。
本发明提出的所述基于上下文感知主题的查询表示及混合检索模型建立方法中,所述检索得分以如下公式表示:
其中,s表示传统检索模型中基于关键词匹配的得分,s′表示基于新查询表示Q′的主题匹配得分,λ是这两种得分之间的权重参数,也是两种匹配方式的权衡系数。
本发明的有益效果在于:本发明充分利用了语料库本身基于伪相关反馈的上下文信息,解决了高质量外部数据源难以获取的问题。且通过将伪相关反馈文档分割成一个个上下文窗口,并从中选取出与查询比较相关的上下文片段用于查询表示,减少了“噪声”引入和查询漂移,是一种查询表示质量控制的创新性举措。本发明中提出的上下文感知主题模型,充分挖掘了与查询相关的上下文对应的主题信息,突破了传统仅基于关键词层面的理解,有助于更全面、更深入地理解用户查询。传统的检索模型主要基于关键词匹配,而忽略了深层次的语义相关性。本发明设计的混合检索模型综合考虑了关键词匹配和主题匹配,这种多样化的匹配方式有助于促进检索效果的提升。本发明提出的查询表示方法及混合检索模型在Microblog Track 2011-2014的数据集上都被证明是有效的,在查询中融入上下文主题信息,其最终检索的MAP值超过了最新的一些查询表示方法。
附图说明
图1是本发明基于上下文感知主题的查询表示及混合检索模型建立方法的流程图。
图2是基于伪相关反馈的上下文选取流程图。
图3是上下文感知主题模型的图模型表示。
具体实施方式
结合以下具体实施例和附图,对本发明作进一步的详细说明。实施本发明的过程、条件、实验方法等,除以下专门提及的内容之外,均为本领域的普遍知识和公知常识,本发明没有特别限制内容。
如图1所示,本发明基于上下文感知主题的查询表示及混合检索模型建立方法包括如下步骤:
步骤一:基于查询的关键词集合,获取查询的伪相关反馈文档,从伪相关反馈文档中选取与查询相关的上下文;
步骤二:引入上下文感知主题模型,将上下文融入上下文感知主题模型中,基于语料库主题挖掘上下文窗口所隐含的主题信息,得到其相应的主题向量;
步骤三:将查询以主题向量与关键词集合联合表示;基于主题向量和关键词集合,建立混合检索模型,得到最终的检索得分。
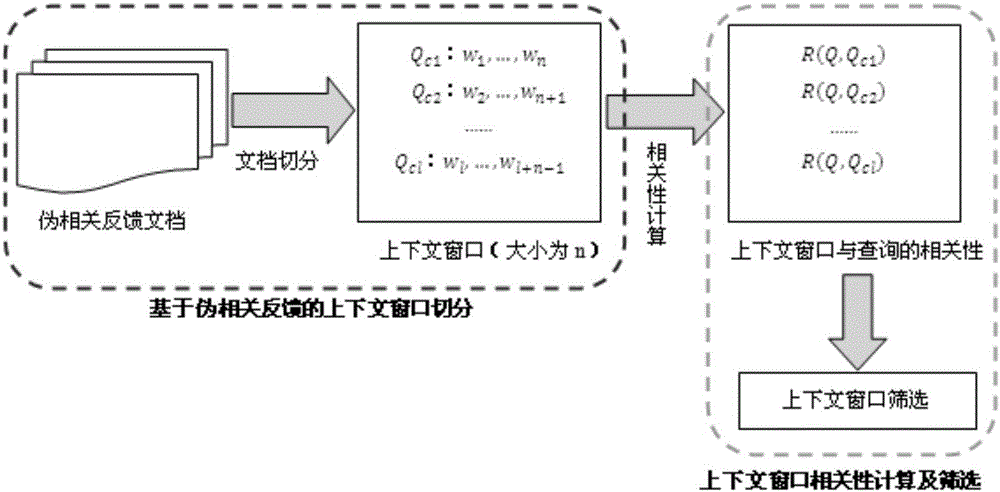
(一)、基于伪相关反馈的相关上下文选取
由于伪相关反馈文档易于获取且包含很多与查询相关的内容,本发明将从中选取出与查询比较相关的上下文用于查询表示,其具体流程见附图2。
首先,对伪相关反馈文档进行切分,得到多个大小为n的上下文窗口。定义Q={q1,q2,...,q|Q|}为一个查询,其中qi表示一个查询关键词,|Q|表示该查询中关键词的个数。是查询Q对应的伪相关反馈文档集合,即第一次检索时排在top k的文档。对于一个伪相关反馈文档将以滑动窗口的形式,把它分割成如图2所示的若干个大小为n的上下文窗口(包含n个词),即Qc1,Qc2,...,Qcl,I表示上下文窗口的数目。
其次,计算上下文窗口与原查询的相关性。对于一个查询和上下文窗口对(Q,Qc),本发明综合使用多种方法来计算它们之间的相关性R(Q,Qc),如基于词共现的平均点互信息(Pointwise Mutual Information)、基于词集合的Jaccard相似度、基于词向量word2vec的语义相似度等,最后取其平均值。
然后,筛选出与查询相关的上下文。先对以上得到的相关性进行归一化处理。接着,设置阈值为该查询下所有窗口相关性的平均值,过滤掉相关性低于该阈值的上下文窗口,其余的与查询比较相关的上下文将进一步用作上下文感知主题建模。
(二)、上下文主题感知建模及查询表示
给定(一)中得到的与查询相关的上下文和整个语料库,本发明设计一个上下文感知主题模型,以便将与查询相关的上下文信息融入到主题模型中,生成新的查询表示。
受相关研究的启发,由于(一)中选取的上下文窗口和其所在的伪相关反馈文档都是与查询密切相关的,因此,假设它们共享同样的主题分布。在此假设下,改进传统的LDA主题模型,从而得到上下文感知主题模型CAT,其图模型表示如附图3。模型中涉及的相关符号说明如表1。该模型是一个生成模型,具体建模过程见算法1。
表1上下文感知主题模型CAT中的相关符号说明
为了求解模型中的参数,本发明采用广泛使用的吉布斯采样(Gibbs sampling)算法。
首先,根据吉布斯采样算法,文档中第个词被分配给主题的概率以如下公式(1)表示:
其中,表示不包括当前第i个词的其他所有词的主题分配向量,表示文档d中被分配给主题k的词数(不包括当前词),表示词wi在整个语料中被分配给主题k的次数(不包括当前词)。对于符号表示中缺失的上标或下标(如和)表示对该缺失维度求和,1是一个元素全为1的向量。
类似地,文档d中第j个与查询相关的上下文窗口被分配给主题k的概率可以用下面的公式(2)表示:
其中,表示不包括当前第j个与查询相关的上下文窗口的其他所有窗口的主题分配向量,表示主题k中与查询Q相关的所有上下文窗口的个数(不包括当前窗口),θd,k表示文档d中主题k的概率,可以进一步用如下公式计算:
其中,表示文档d中被分配给主题k的总词数。
当模型收敛或达到预设的迭代次数时,将得到以下几个分布:“文档-主题”分布θ,“主题-词”分布Φ及“主题-查询上下文”分布η。η的每一列表示某查询的所有相关上下文在主题上的分布情况,这也是得到的新查询表示。可见,该表示很自然地同时将上下文信息和主题信息融合在一起,理论上将优于分别对各自建模的表示方法。
(三)、混合检索模型设计
本发明基于得到的新查询表示,设计一种同时考虑关键词匹配和主题匹配的混合检索模型,其检索得分计算公式如下:
其中s表示传统检索模型中基于关键词匹配的得分,如language model检索得分或BM25检索得分,s′表示基于新查询表示Q′的主题匹配得分,λ是这两种得分之间的权重参数,也是两种匹配方式的权衡系数。
关于主题匹配得分,可以采用多种计算方法。具体地,给定新查询表示和文档的主题分布向量,可以通过计算两者之间的主题分布相似度来得到,如Jensen-Shannon divergence(JSD)和余弦相似度(Cosine similarity)。
本发明的保护内容不局限于以上实施例。在不背离发明构思的精神和范围下,本领域技术人员能够想到的变化和优点都被包括在本发明中,并且以所附的权利要求书为保护范围。
- 还没有人留言评论。精彩留言会获得点赞!