一种金融行业中并行跑批的方法与流程
本发明涉及并行计算和批处理
技术领域:
,具体地说是一种金融行业中并行跑批的方法。
背景技术:
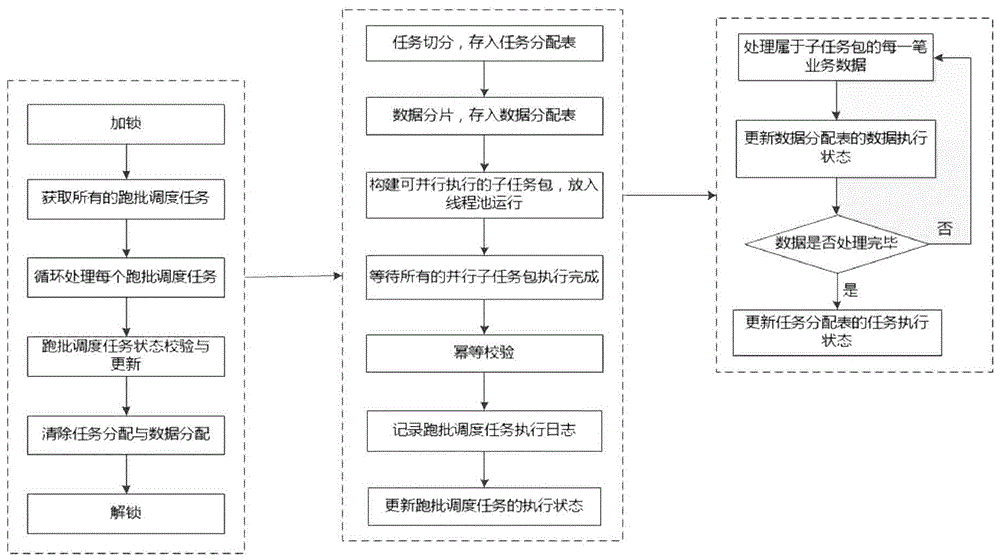
:跑批是金融行业中的一项非常核心的业务功能,计提,计息,日切等业务都在跑批中执行,其处理的数据量非常大,对程序的可靠性和性能要求也非常高。传统的方式是单线程一条数据接一条数据地处理,这样做能有效的保证可靠性,但是其性能非常低,数据量大时,跑批时间会非常长。如果其中有一条数据执行出错,后续其它所有的数据都无法执行跑批,已经跑批完成的数据也有可能回滚。跑批处理时一般都会终止其它所有的业务操作,因此有大量的CPU,内存,网络等资源可供使用,但是目前的方式却没有充分地利用这些资源,造成资源的极大浪费。由此可见,在现有的技术方案中,跑批系统具有性能低下,容错性差,资源浪费严重等问题。基于此,现提供一种高性能、有一定容错能力、金融行业中并行跑批的方法。技术实现要素:本发明的技术任务是针对以上不足之处,提供一种高性能、有一定容错能力,且资源得到有效利用的金融行业中并行跑批的方法。一种金融行业中并行跑批的方法,其实现过程为:将任务切分成若干个子任务,并将数据集划分为若干个数据片,根据每一个子任务及其对应的数据分片构建一个可并行执行的独立子任务包,将这些子任务包放入统一的线程池中进行独立的并行执行。在进行任务切片前,首先需要进行资源预处理的步骤,该步骤具体为:对资源进行加锁;检查系统是否可以进行跑批处理,可以执行跑批则查询获取所有的跑批调度任务,否则返回;循环处理每个跑批调度任务,然后进入任务切片的步骤;相对应的,在所有的跑批调度任务全部执行成功后,对资源进行解锁。所述任务切片过程为:根据配置的任务并行度参数,对任务进行切分操作,切分后的子任务存入任务分配表。数据集分片的过程为:根据子任务数,对数据进行分片操作,分片后的数据ID存入数据分配表,并与子任务建立关联。构建独立子任务包后进行并行执行过程为:处理每一个并行任务包所关联的数据分片中的每一笔业务数据;根据业务数据的执行成功与否来更新数据分配表的数据执行状态,数据处理成功则将状态置为成功,数据处理失败则将状态置为失败,并记录错误信息,同时终止该子任务的执行;数据执行状态为成功的记录在跑批重试时将不再执行;一直循环执行上述两个步骤,直至该子任务所对应的数据分片中的数据全部成功处理完成,或者处理失败;根据子任务在其对应的数据分片上的执行情况,更新任务分配表的子任务执行状态,子任务在其对应的数据分片的数据上全部执行成功,则将该子任务的执行状态更新为成功,否则更新为失败,并记录错误信息,任务执行状态为成功的子任务在跑批重试时将不再执行;等待所有的并行子任务包全部执行完成;进行幂等校验,验证是否所有的并行子任务包全部都执行成功,如果未全部执行成功,则终止执行,等待跑批重试。在并行跑批过程中,还包括任务追踪与容错的步骤,即在并行执行的过程中通过记录子任务执行状态与错误信息,数据执行状态与错误信息来对任务执行过程进行追踪与容错。所述任务追踪与容错的具体过程为:记录正在执行的跑批调度任务的执行日志;根据跑批调度任务的执行情况,更新跑批调度任务的执行状态,跑批调度任务执行成功,则将其执行状态更新为成功,否则将其执行状态更新为失败。状态为成功的跑批调度任务在跑批重试时将不再执行;等待所有的跑批调度任务执行完成,检查是否所有的跑批调度任务都成功执行,如果所有的跑批调度任务都执行成功,则更新所有的跑批调度任务状态为初始态,等待下一个业务日期的跑批;否则终止执行,等待跑批重试。本发明的一种金融行业中并行跑批的方法和现有技术相比,具有以下有益效果:本发明的一种金融行业中并行跑批的方法,通过将原来的一个大任务在一个大数据集上的跑批处理转化为多个小任务分别在对应的小数据集上的并行跑批,从而可以充分利用现有系统的资源,提高跑批处理的性能。在并行执行的过程中通过记录子任务执行状态与错误信息,数据执行状态与错误信息来对任务执行过程进行追踪与容错;本发明具有高性能,容错,充分利用系统资源等特点,可以广泛应用于金融行业的跑批处理系统中,实用性强,适用范围广泛。附图说明附图1为本发明的架构原理图。附图2为本发明的处理流程图。具体实施方式下面结合附图及具体实施例对本发明作进一步说明。如附图所示,本发明提供一种金融行业中并行跑批的方法,其实现过程为:通过将大任务切分成多个子任务,将大数据集划分为多个小数据片,然后根据每一个子任务及其对应的数据分片构建一个可并行执行的独立子任务包,并将这些子任务包放入统一的线程池中进行独立的并行执行。这样就将原来的一个大任务在一个大数据集上的跑批处理转化为多个小任务分别在对应的小数据集上的并行跑批,从而可以充分利用现有系统的资源,提高跑批处理的性能。本发明提出的技术方案如下:如附图1所示,跑批系统通常由许多跑批调度任务组成,由于各个跑批调度任务之间存在业务依赖关系,无法并行执行,跑批调度任务之间是根据其业务顺序一个接一个串行执行的。跑批调度任务内部是并行执行的,采用fork-join的思想,根据配置的任务并行度n,将一个在N条数据上运行的大任务分解为n个可独立执行的小任务,对于前n-1个任务,任务k(1≤k≤n-1)处理的数据从(k-1)*N/n+1至k*N/n,最后一个任务n处理的数据从(n-1)*N/n+1至N。整体处理流程如图2系统整体处理流程图所示。具体步骤如下:对资源进行加锁;检查系统是否可以进行跑批处理,可以执行跑批则查询获取所有的跑批调度任务,否则返回;循环处理每个跑批调度任务;根据配置的任务并行度参数,对任务进行切分,切分后的子任务存入任务分配表;根据子任务数,对数据进行分片,分片后的数据ID存入数据分配表,并与子任务建立关联;根据每一个子任务及其对应的数据分片构建一个可并行执行的子任务包,并将子任务包放入统一的线程池进行并行执行;处理每一个并行任务包所关联的数据分片中的每一笔业务数据;根据业务数据的执行成功与否来更新数据分配表的数据执行状态,数据处理成功则将状态置为成功,数据处理失败则将状态置为失败,并记录错误信息,同时终止该子任务的执行。数据执行状态为成功的记录在跑批重试时将不再执行;一直循环执行上述处理步骤,直至该子任务所对应的数据分片中的数据全部成功处理完成,或者处理失败;根据子任务在其对应的数据分片上的执行情况,更新任务分配表的子任务执行状态,子任务在其对应的数据分片的数据上全部执行成功,则将该子任务的执行状态更新为成功,否则更新为失败,并记录错误信息。任务执行状态为成功的子任务在跑批重试时将不再执行;等待所有的并行子任务包全部执行完成;幂等校验,验证是否所有的并行子任务包全部都执行成功,如果未全部执行成功,则终止执行,等待跑批重试;记录该跑批调度任务的执行日志;根据跑批调度任务的执行情况,更新跑批调度任务的执行状态,跑批调度任务执行成功,则将其执行状态更新为成功,否则将其执行状态更新为失败。状态为成功的跑批调度任务在跑批重试时将不再执行;等待所有的跑批调度任务执行完成,检查是否所有的跑批调度任务都成功执行,如果所有的跑批调度任务都执行成功,则更新所有的跑批调度任务状态为初始态,等待下一个业务日期的跑批;否则终止执行,等待跑批重试;所有的跑批调度任务全部执行成功后,清除任务分配与数据分配数据;对资源进行解锁。本发明采用java语言实现;本发明中的任务分配表参考模型如下:本发明中的数据分配表参考模型如下:本发明中的控制参数如下:序号参数名称参数值类型描述1BATCH_PROCESS_TASKS正整数任务并行度如此,可以实现金融行业中的并行跑批处理,解决现有跑批系统性能低下,容错性差,资源浪费严重等问题。通过上面具体实施方式,所述
技术领域:
的技术人员可容易的实现本发明。但是应当理解,本发明并不限于上述的具体实施方式。在公开的实施方式的基础上,所述
技术领域:
的技术人员可任意组合不同的技术特征,从而实现不同的技术方案。除说明书所述的技术特征外,均为本专业技术人员的已知技术。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1