一种基于solr的Hbase秒级查询方案的制作方法
本发明涉及hbase技术领域,尤其涉及一种基于solr的Hbase秒级查询方案。
背景技术:
Solr是apache旗下基于lucene的一个完整的搜索服务。Solr主要包括两部分核心组件:索引组件和搜索组件。索引组件用于将需要索引的数据在搜索程序中建立索引,而搜索组件用于响应客户端的请求来查询索引。Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。文档通过Http利用XML加到一个搜索集合中。查询该集合也是通过http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
Hbase是Hadoop家族针对海量数据的分布式存储方案,当我们通过rowkey对存于Hbase中的海量数据进行查询时可以达到秒级的响应,实现比较理想的用户体验。但是,当在比较复杂的场景下,如需要对数据做多条件查询时,Hbase提供的解决方案都不是很理想。
针对多条件查询,Hbase本身现阶段有两种比较主流的解决方案:
1、通过协处理器在插入数据时手动建索引表
Hbase中的协处理器有两种:Observer和Endpoint。Observer类似于关系型数据库中的触发器,Endpoint类似于关系型数据库中的存储过程。
我们在利用协处理器建索引表时使用的是Observer,即在往Hbase表中插入数据时,加入Observer操作,让每插入一条数据前都调用我们自定义的业务逻辑在索引表中生成需要索引字段的记录。
这样在我们针对Hbase进行多条件查询时,我们的查询操作分成两步:第一步首先根据查询条件在索引表进行查询,查询对应结果的rowkey,第二步再根据rowkey去主表查询我们需要的数据。
这种方案有几个比较大的问题:
(1)协处理器很不稳定
在现版本Hbase中,我们自己测试通过协处理器生成索引时,一旦在建立索引过程中代码抛出异常,整个Hadoop集群都会挂掉。
(2)建索引会影响插入数据的速度
由于插入数据与建索引是一个同步的过程,所以建索引的操作会在很大程度上影响插入数据的速度。
(3)需要索引的字段必须在数据插入前确定,后期不能修改
插入数据同时建索引的另一个问题就是我们必须一次性确定好所有需要建立索引的字段,如果后期需要在一个新的字段上建立索引,之前已经插入的数据是不会自动再建立索引的。
(4)每个索引字段对应一个索引表效率不高
为了后期使用索引时灵活,一般在建立索引表时会为每个单独的字段都建立一个索引表。以字段value作为索引表的rowkey,以原表的rowkey作为索引表的字段。这种方式虽然会方便我们灵活的做多条件查询,但同时会增加索引表的数量,同时当单词查询的查询条件比较多时,需要进行多次的索引表查询操作,对查询的响应也会有比较大的影响。
2、使用Hbase自带的过滤器在服务端过滤
Hbase自带很多种类的过滤器,同时我们也可以自定义自己的过滤器。当我们在查询的时候使用过滤器,Hbase会在集群的服务端对查询的结果数据按过滤器的逻辑进行过滤。
但同样,这种方案也有一个问题:过滤器依然需要扫描数据,效率低。
过滤器虽然是在服务端进行过滤,但是依然需要将所有符合rowkey查询条件的数据全部查询出来,然后再在这些数据上进行扫描,过滤掉不符合过滤条件的数据。这个过程在原始查询数据量比较大时会占用很多服务端内存,同时扫描时间也会很长,光这一个过程的耗时就已经不能达到秒级查询的要求。
基于以上两种方案都有某些特性不能满足我们的需求,我们提出了一种基于solr的Hbase秒级查询方案。
技术实现要素:
本发明的目的是为了解决现有技术中存在的缺点,而提出的一种基于solr的Hbase秒级查询方案。
一种基于solr的Hbase秒级查询方案,包括以下步骤:
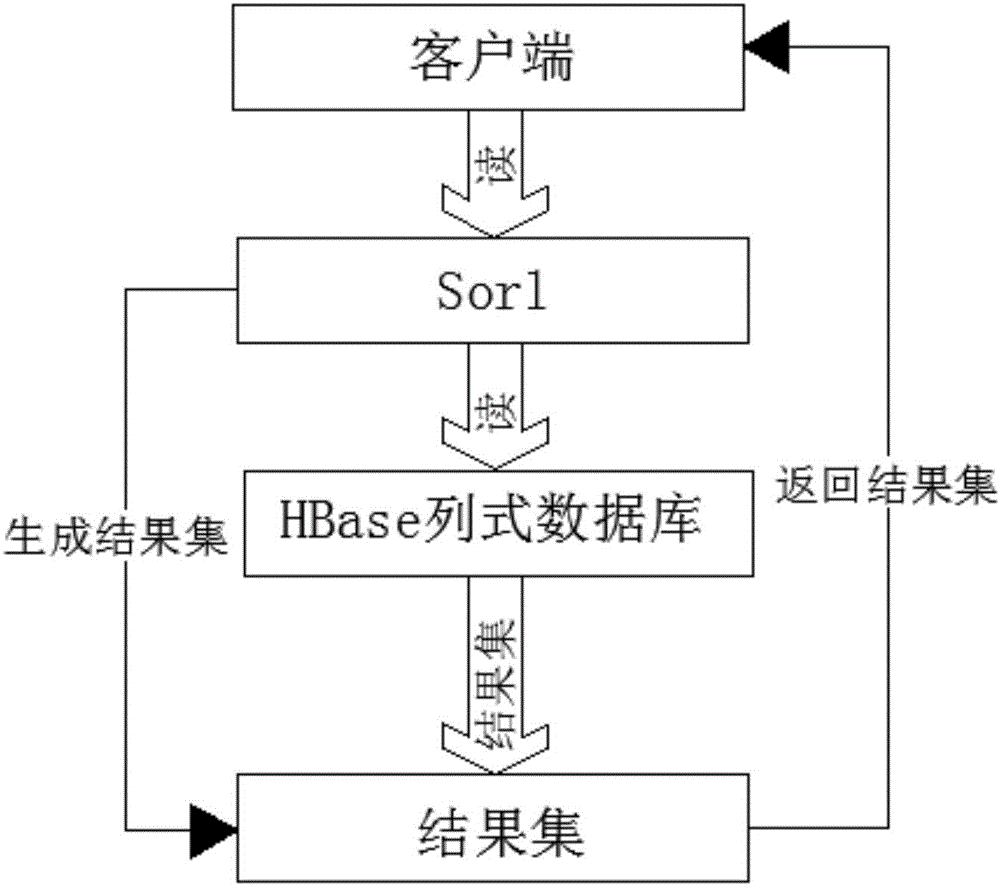
步骤1、将原始数据插入Hbase列式数据库中,保持Hbase原有方式,不需做其他任何更改;
步骤2、获取原始数据并将原始数据以solr特有的文档格式存入solr的服务端,在建立文档之后solr会自动对文档进行分析,完成分析后,solr以切分出的单词作为key,以文档作为value进行倒排索引,即形成索引,定时调用MapReduce增量更新solr中建立的索引;
步骤3、查询时,访问solr服务端,在需要查询的字段上单独建立索引,查询索引,从索引中获取rowkey,再根据rowkey去Hbase列式数据库中查询,即生成所需要的结果数据。
优选的,所述solr建立索引之后,会将索引压缩存储在solr服务端的磁盘中,同时会利用Map做部分的缓存。
优选的,所述solr索引可以对分词器进行优化,针对业务场景对分词进行定制化的优化,提取出行业特殊用词。
优选的,所述solr自带分页功能,可以每次返回一页数据的rowkey。
优选的,所述sorl可与成熟的内存数据库相结合,直接将索引存在内存数据库中。
优选的,所述solr建立索引的操作也可以放在Hbase的协处理器中执行。
本发明提出的一种基于solr的Hbase秒级查询方案,搜索速度快,准确率高,通过solr和hbase相结合的技术,实现对海量数据的秒级检索,solr自带的分页功能可以每次返回一页数据的rowkey,由于每页数据的数量极其有限,所以再基于该页的rowkey去Hbase查询时响应速度非常快,可控制在毫秒级。
附图说明
图1为数据存储流程图;
图2为数据查询流程图。
具体实施方式
下面结合具体实施例对本发明作进一步解说。
参照图1-2,本发明提出的一种基于solr的Hbase秒级查询方案,包括以下步骤:
步骤1、将原始数据插入Hbase列式数据库中,保持Hbase原有方式,不需做其他任何更改;
步骤2、定时调用MapReduce增量更新solr中索引,先获取插入Hbase列式数据库中的原始数据并将原始数据以solr特有的文档格式存入solr的服务器中,建立文档之后solr会自动对文档进行分析,这其中涉及对文档中的内容按特定的分词技术进行分词,完成分词后,solr以切分出的单词作为key,以文档作为value进行倒排索引;
步骤3、查询时,访问solr服务端,在需要查询的字段上单独建立索引,建立索引之后,solr会将索引压缩存储在solr服务端的磁盘中,同时会利用Map做部分的缓存,查询索引,从索引中获取rowkey,solr自带分页功能,可以每次返回一页数据的rowkey,再根据rowkey去Hbase列式数据库中查询,即生成所需要的结果数据。
本发明中solr建立索引的操作也可以放在Hbase的协处理器中执行,sorl可与成熟的内存数据库相结合,直接将索引存在内存数据库中。
本发明提出的一种基于solr的Hbase秒级查询方案,搜索速度快,准确率高,通过solr和hbase相结合的技术,实现对海量数据的秒级检索,solr自带的分页功能可以每次返回一页数据的rowkey,由于每页数据的数量极其有限,所以再基于该页的rowkey去Hbase查询时响应速度非常快,可控制在毫秒级。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!