一种健壮的复杂背景视频文本定位和抽取方法与流程
本发明属于视频图像处理领域,具体涉及一种健壮的复杂背景视频文本定位和抽取方法。
背景技术:
随着现代科技的快速发展,生活中的很多信息都是通过多媒体的形式传递。其中,视频中的文字是最有用的信息类型之一,这些文本提供了很多有价值的信息,例如节目介绍、场景位置、特别公告、扬声器的名称、赛事比分、日期和时间、房地产走势、新闻事件和视频内容等。文本识别已经有很多现实应用,如视频分类、文档分析、基于视频内容的视频检索、帮助盲人、自动标注、车牌识别等。所以对视频的文本信息进行提取,对理解视频的深层语义信息具有重要意义。
现在国内外已有了很多视频文字定位和抽取的算法,主要可以分为基于连通域的、基于纹理的、基于边缘的和基于学习的方法。其中基于连通域的方法定位速度比较快,但是易受图像对比度变化的干扰;基于纹理和边缘的方法定位比较稳定,但却有时间复杂度高的缺点;而基于学习的方法定位好坏完全取决于样本的训练。
技术实现要素:
本发明针对现有技术中复杂背景下视频文本定位不健壮的问题,提出了一种视频中复杂背景文本的定位和抽取健壮方法。
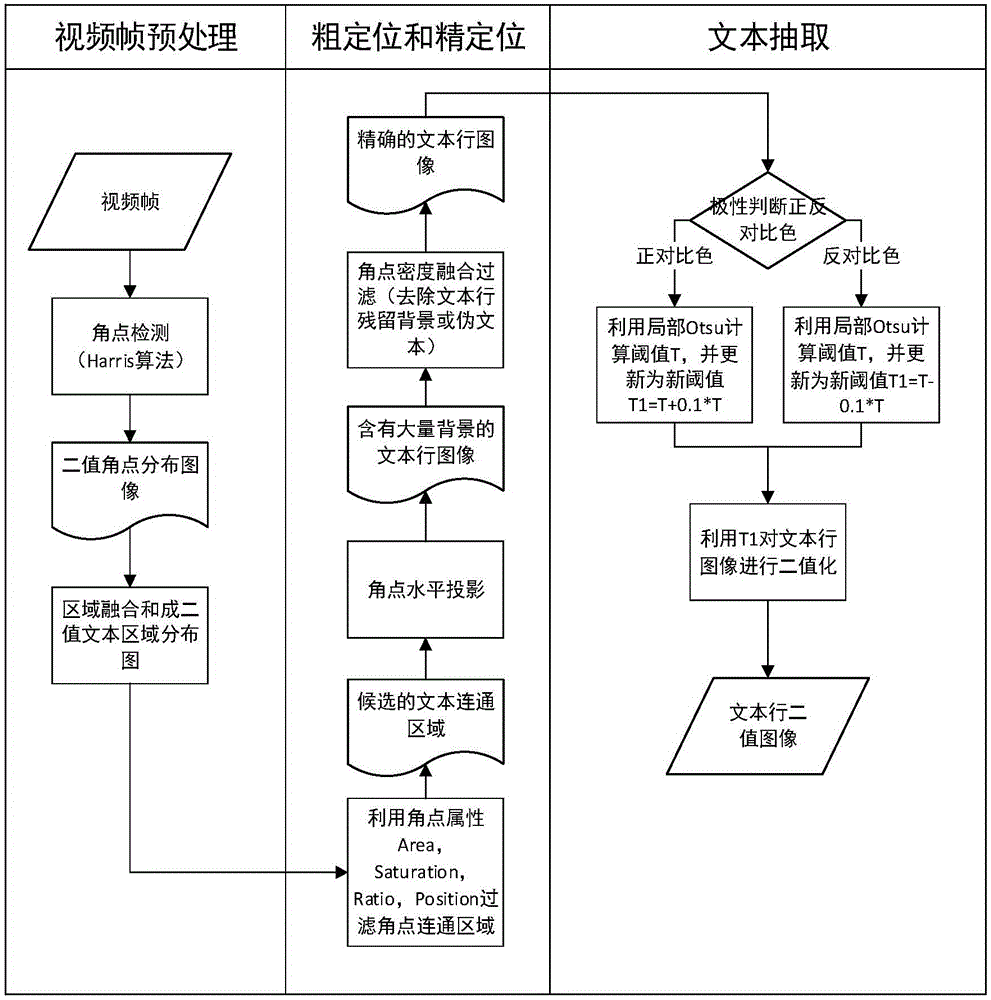
本发明的目的是通过以下技术方案来实现的:一种健壮的复杂背景视频文本定位和抽取方法,包括以下步骤:
预处理:输入视频帧,将视频帧转化为灰度图像,对视频帧进行角点检测,得到角点二值分布图;
文本粗定位:首先利用角点二值分布图通过滑动窗口进行区域合并,形成二值文本区域分布图,然后利用二值文本区域分布图的四个属性过滤掉非文本区域内的角点,实现文本区域粗定位;
文本精定位:通过角点水平投影和角点密度融合的方法,实现文本行精定位;
文本抽取:对定位后的文本行图像进行基于二值图像的极性判断,然后利用改进的局部OTSU算法计算每一块区域内的阈值,并根据极性判断结果调整为最佳阈值,最后完成文本行的二值化。
进一步地,所述的二值文本区域分布图经过区域融合得到,具体是选择一个n*n的矩形框,5≤n≤15,以角点为中心,对矩形框区域内的颜色置为角点颜色,遍历完所有角点,最终得到二值文本区域分布图。
进一步地,所述的二值文本区域分布图具有多个连通区域。
进一步地,所述的二值文本区域分布图的属性包括:Area,Saturation,Ratio和Position。
进一步地,所述的过滤掉非文本区域内的角点是指通过四个属性特征Area,Saturation,Ratio和Position逐步进行过滤,具体是:
首先,Area属性过滤是指对当前二值文本区域分布图中的每一个连通区域Area按照面积大小进行排序,过滤掉相对较小的区域Area;然后,Saturation过滤是指计算每个连通区域Area的面积A(Area)与外接矩形框Rect的面积A(Rect)的比例,Saturation=A(Area)/A(Rect),(Saturation∈(0,1)),过滤掉Saturation较小的连通区域;然后,Ratio过滤是指计算每个连通区域外接矩形框的高宽比,过滤掉Ratio大于1:2.5的连通区域;最后,Position过滤方法具体是计算连通区域的位置信息,过滤掉视频帧2/3上部分的连通区域。
进一步地,所述的角点水平投影和角点密度融合的方法是指:
首先,通过统计每行的角点直方图,利用直方图的波峰波谷将文本区域分割为文本行,其波谷判断依据是将连续q行的角点数小于角点平均值数的1/4或1/3视为波谷,3≤q≤6。然后利用角点密度融合的方法去除文本行的背景区域或伪文本行。
进一步地,所述的角点密度融合的方法是指过滤掉文本行残存的背景或去除伪文本行,其过滤规则利用H*1/2H(H为文本行的高度)水平滑动窗口进行水平滑动,去除角点密度小于阈值C的区域,C为角点个数,最后再将矩形框间距小于H的矩形框融合成新的文本行。
进一步地,所述的基于二值图像的极性判断是基于局部OTSU二值图像进行的极性判断,首先,利用局部OTSU方法进行文本行的二值化,然后把上述二值图像后的四个边界作为种子像素点,进行四连通域种子填充算法填充,填充值为p,0<p<255,最后计算黑白二值所占的比例,比重大的颜色则为文字的极性。
进一步地,所述的根据极性判断结果调整为最佳阈值是指利用局部OTSU算法计算出每个块内的阈值T,但不进行二值化处理。然后利用文本极性判断结果,再修改当前阈值为最佳阈值,最后利用修改后的最佳阈值执行二值化操作。
进一步地,所述的修改当前阈值为最佳阈值具体是指,如果极性判断文字颜色为黑色,则新阈值T1=T-T*0.1,反之,白色文字时,新阈值T1=T+T*0.1。
本发明的有益效果是:在文本定位阶段,本发明选取健壮的角点作为文字的基本特征,然后通过粗定位完成候选文本区域的定位,尽可能多的保留文本区域;再利用精定位实现文本区域的文本行的分割和校验。文本抽取阶段,通过基于二值图像的极性判断与局部OTSU相结合的方法完成复杂背景下最佳阈值选取困难的问题。经过对本发明的大量实验测试,本发明的文本定位和抽取算法对复杂背景视频具有很好的健壮性。
附图说明
图1为本发明方法流程图。
具体实施方式
以下结合附图对本发明作进一步说明。
如图1所示,本发明提供的一种健壮的复杂背景视频文本定位和抽取方法,包括以下步骤:
预处理:输入视频帧,将视频帧转化为灰度图像,对视频帧进行角点检测,得到角点二值分布图;
文本粗定位:首先利用角点二值分布图通过滑动窗口进行区域合并,形成二值文本区域分布图,然后利用二值文本区域分布图的四个属性过滤掉非文本区域内的角点,实现文本区域粗定位;
文本精定位:通过角点水平投影和角点密度融合的方法,实现文本行精定位;
文本抽取:对定位后的文本行图像进行基于二值图像的极性判断,然后利用改进的局部OTSU算法计算每一块区域内的阈值,并根据极性判断结果调整为最佳阈值,最后完成文本行的二值化。
进一步地,所述的二值文本区域分布图经过区域融合得到,具体是选择一个n*n的矩形框,5≤n≤15,以角点为中心,对矩形框区域内的颜色置为角点颜色,遍历完所有角点,最终得到二值文本区域分布图。
进一步地,所述的二值文本区域分布图具有多个连通区域。
进一步地,所述的二值文本区域分布图的属性包括:Area,Saturation,Ratio和Position。
进一步地,所述的过滤掉非文本区域内的角点是指通过四个属性特征Area,Saturation,Ratio和Position逐步进行过滤,具体是:
首先,Area属性过滤是指对当前二值文本区域分布图中的每一个连通区域Area按照面积大小进行排序,过滤掉相对较小的区域Area;然后,Saturation过滤是指计算每个连通区域Area的面积A(Area)与外接矩形框Rect的面积A(Rect)的比例,Saturation=A(Area)/A(Rect),(Saturation∈(0,1)),过滤掉Saturation较小的连通区域;然后,Ratio过滤是指计算每个连通区域外接矩形框的高宽比,过滤掉Ratio大于1:2.5的连通区域;最后,Position过滤方法具体是计算连通区域的位置信息,过滤掉视频帧2/3上部分的连通区域。
进一步地,所述的角点水平投影和角点密度融合的方法是指:
首先,通过统计每行的角点直方图,利用直方图的波峰波谷将文本区域分割为文本行,其波谷判断依据是将连续q行的角点数小于角点平均值数的1/4或1/3视为波谷,3≤q≤6。然后利用角点密度融合的方法去除文本行的背景区域或伪文本行。
进一步地,所述的角点密度融合的方法是指过滤掉文本行残存的背景或去除伪文本行,其过滤规则利用H*1/2H(H为文本行的高度)水平滑动窗口进行水平滑动,去除角点密度小于阈值C的区域,C为角点个数,最后再将矩形框间距小于H的矩形框融合成新的文本行。
进一步地,所述的基于二值图像的极性判断是基于局部OTSU二值图像进行的极性判断,首先,利用局部OTSU方法进行文本行的二值化,然后把上述二值图像后的四个边界作为种子像素点,进行四连通域种子填充算法填充,填充值为p,0<p<255,最后计算黑白二值所占的比例,比重大的颜色则为文字的极性。
进一步地,所述的根据极性判断结果调整为最佳阈值是指利用局部OTSU算法计算出每个块内的阈值T,但不进行二值化处理。然后利用文本极性判断结果,再修改当前阈值为最佳阈值,最后利用修改后的最佳阈值执行二值化操作。
进一步地,所述的修改当前阈值为最佳阈值具体是指,如果极性判断文字颜色为黑色,则新阈值T1=T-T*0.1,反之,白色文字时,新阈值T1=T+T*0.1。
实施例
本实施例的实现,包括以下步骤:
1、输入视频帧,对视频帧进行预处理,例如转化为灰度图像;采用Harris算法对视频帧进行角点检测,得到背景为黑色、角点为白色的角点二值分布图;
2、利用6*6的矩形框,以角点为中心,将每个角点的矩形框内置为角点一致的颜色,得到二值文本区域分布图;
3、采用由粗到精的文本定位方法进行文本定位;
粗定位:选取二值文本区域分布图的四个属性去除伪文本区域,得到候选文本区域。分别是面积,饱和度,高宽比和位置,记为Area,Saturation,Ratio,Position。
Area:找到每一个连通区域Area,然后按照连通区域的面积大小进行排序,过滤掉相对较小的区域。因为面积较小的区域一定不是视频帧反映的主要内容,并且小面积区域很容易被过滤掉。
Saturation:即角点的饱和度特征,统计每个连通区域的外接矩形框Rect。过滤掉Saturation较小的连通区域。
Saturation=A(Area)/A(Rect),(Saturation∈(0,1));
其中A(Area)是连通域的面积,A(Rect)是连通域的外接矩形框的面积。由于视频中的叠加字幕都是水平的,因此Saturation的值接近于1,而伪文本连通区域的Saturation值接近于0。
Ratio:连通区域外接矩形框高宽比,根据汉字的自身特点,本发明过滤掉Ratio大于1:2.5的连通区域。
Position:连通区域的位置信息,过滤掉视频帧上2/3的连通区域。因为视频帧中的叠加字幕信息一般都是在视频帧的下方。
精定位:由于每个候选的连通区域中可能包含多行文本或者是伪文本,因此,可以利用角点进行水平投影,将每个候选的连通区域分割成文本行并实现精确定位;最后利用角点密度融合方法对文本行的背景或者伪文本行进一步过滤,过滤窗口大小为H*1/2H(H为文本行的高度),之后再将矩形框间距小于H的矩形框融合成新的文本行,文本行定位完成;
4、文本抽取。本发明采用基于二值图像的极性判断和改进的局部OTSU二值化相结合的方法完成文本行的抽取。
局部OTSU二值化:将文本行图像划分为等大小的区域,每个小区域的大小为H*H(文本行的高度)。每个区域进行局部OTSU二值化;
基于二值图像的极性判断:把上述二值图像后的四个边界作为种子像素点,进行四连通域种子填充算法填充,填充的值为128,最后计算黑白二值所占的比例,比重大的颜色则为文字的极性;
改进的局部OTSU二值化:首先对文本行图像处理跟局部OTSU算法一样,将文本行分成多个大小为H*H的区域,然后执行OTSU算法计算出每个块内的阈值T,但此时不进行二值化处理。因为此时的T不是文本分割的最佳阈值。因此需要根据文本极性判断结果,再修改此阈值(如果极性判断文字颜色为黑色,则新阈值T1=T-T*0.1,反之,白色文字时,新阈值T1=T+T*0.1),最后利用修改后的最佳阈值执行二值化操作。
- 还没有人留言评论。精彩留言会获得点赞!