基于传播结构的微博谣言识别方法和系统与流程
本发明涉及数据库技术,具体地,涉及基于传播结构的微博谣言识别方法和系统。
背景技术:
经对现有技术进行检索,发现如下相关检索结果。
相关检索结果1:
申请(专利)号:201210586904.8,名称:一种鉴定网络谣言的方法和装置
该专利文献适用于互联网通信领域,提供了一种鉴定网络谣言的方法,所述方法包括:对数据库中的网络信息进行分析并提取特征;用机器学习法建模,生成打分函数;利用打分函数对网络信息进行鉴定。该专利文献对数据库中的网络信息进行分析并提取特征,通过分析网络信息的种类(主题)、网络信息的发布者、网络信息的传播者、网络信息的受众、网络信息的重要性、网络信息的模糊性、网络信息的反常度等特征,利用机器学习法建模,生成打分函数,从而对网络信息进行谣言鉴定。但其中,发布者、传播者、受众三个特征高度依赖于数据库的规模。若待鉴定的谣言所涉及到的用户不包含在分析用的数据库中,则无法使用这三个特征。另外,网络信息的反常度分析需要人工参与,效率低下,无法应用于大规模自动鉴别谣言。
技术要点比较:
1.该专利文献在用机器学习法建模时,主要考虑的谣言特征包括网络信息的种类(主题)、网络信息的发布者、网络信息的传播者、网络信息的受众、网络信息的重要性、网络信息的模糊性、网络信息的反常度;而本发明中考虑的谣言特征包括网络信息的时间跨度、网络信息所包含的情感倾向、发布网络信息的客户端、网络用户是否经过大V认证、网络用户的性别、网络用户的粉丝数、网络用户的种类等。
2.该专利文献并未考虑发布信息在传播过程中的特征;而本发明试图从网络信息的包含有传播结构的传播特征(转发数、转发包含的情感倾向)等角度进一步鉴别谣言。
相关检索结果2:
申请(专利)号:201210350085.7,名称:虚假网络舆情识别方法
该专利文献公开了一种虚假网络舆情识别方法,用于解决现有的互联网虚假网络舆情识别方法需要处理大量网络信息的技术问题。技术方案是首先采用行为分析技术,对网络论坛信息传播行为进行建模分析,检测出网络热点事件和舆情。然后依据网络水军行为特征,对网络舆情进行多个层面关联性分析,包括空间关联性、时间关联性、主题关联性以及情感关联性等,识别出可能存在的虚假网络舆情。将所处理的网络信息量减少到了最低限度。该专利文献首先建立用户-用户、用户-事件、事件-事件网络模型,通过计算中心度和威望度来找出网络热点事件。其次通过分析网络热点事件之间的四种关联性,来鉴别其是否虚假。该方法只能分析检测出的网络热点事件的真实性,无法针对特定信息进行鉴别,且计算结果无法重复利用,计算量大。
技术要点比较:
1.该专利文献主要分析检测出的网络热点事件的ip地址、发帖时间、主题内容及情感倾向的关联性,无法针对特定事件进行鉴别,且计算结果无法重复利用,计算量大;而本发明则通过分析已知谣言的信息特征、用户特征及传播特征,从而鉴别新的信息是否为谣言,可针对特定事件进行鉴别,且计算结果可重复利用,计算量小。
相关检索结果3:
申请(专利)号:201310186271.6,名称:一种微博伪造信息的检测方法
该专利文献涉及一种微博伪造信息的检测方法,方法是在微博发布和管理部门设立微博检测系统,设有信息采集模块、特征分析模块、特征库、检测预警模块和响应处理模块,系统通过信息采集模块采集并保存被检测的微博帐号所发布的微博数据;由特征分析模块分析该帐号发布的微博静态、动态及传播特征,建立特征库并定期更新;由检测预警模块检测当前采集的该帐号的微博信息,若当前采集的微博静态、动态及传播特征与特征库的特征差异超出了预定的报警阈值时则自动报警,表明出现了微博帐号盗用和伪造信息的发布;报警后由响应处理模块采取相应的措施处理。该专利文献主要通过分析热门微博的静态特征、动态特征和传播特征来鉴定微博信息是否伪造,主要特征包括常用字集合、转发数、转发速度等。该专利考虑的微博特征较为浅显简单,且通过人工设定各特征权重,容易导致鉴别结果不准确,准确率和召回率不高。
技术要点比较
1.该专利文献主要考虑微博信息的一些简单特征,如常用字组合、微博转发数、微博转发速度等;而本发明倾向于深入分析微博信息的复杂特征,例如微博内容的主题、微博转发的传播结构等。
2.该专利文献的特征权重和打分函数由系统预先人为设定;而本发明通过机器学习建模,自动设定特征权重和打分函数。具体地说,本发明采用支持向量机(SVM)的监督式学习模型,在给出特征集合及数据训练集后,监督式学习模型将根据算法来设定各特征的权重,以期在数据训练集获得最佳的分类效果。这样的好处在于不需要人为干预,监督式学习模型可根据数据来自动调整特征权重。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种基于传播结构的微博谣言识别方法和系统。本发明要解决的技术问题体现在以下几点:
(1)所有信息抓取和特征分析均保证自动化,无需人工判断或打分,以提高鉴别效率,用于大规模微博谣言自动鉴别。
(2)保证方法可鉴别特定微博信息;保证计算结果可重复利用,降低计算量。
(3)深入考虑微博信息的特征,例如信息特征、用户特征和传播特征,通过深层次的特征分析来鉴别微博谣言,力图提高准确率和召回率。
根据本发明提供的一种基于传播结构的微博谣言识别系统,包括如下装置:
数据采集模块:用于收集和提取微博的信息特征、用户特征以及传播特征;
模型建立模块:用于通过支持向量机的机器学习的方法,以微博的信息特征、用户特征以及传播特征的特征数据为数据建立模型,以用于识别谣言;其中,建立模型时所使用的微博数据为数据库中的微博,即已经提前人工标记好是否为谣言的微博;每条微博用一棵传播树和一个特征向量表示,其中,传播树用以表示传播特征中的传播结构,将信息特征、用户特征、非传播结构的传播特征作为特征向量的各维;
模型识别模块:用于利用模型建立模块已建立好的模型,分析待识别微博,从而判断待识别微博是否为谣言;其中,待识别微博的信息特征、用户特征和传播特征来自于数据采集模块。
优选地,所述信息特征包括:微博是否包含多媒体、微博所包含的情感倾向、微博是否包含URL链接、微博的发布时间相距用户的注册时间、微博发布的客户端、微博的话题种类、微博通过搜索引擎返回的结果数;
所述用户特征包括:发微博用户是否经过大V认证、发微博用户是否含有个人描述、发微博用户的性别、发微博用户的账号注册地点、发微博用户的粉丝数、发微博用户的关注数、发微博用户的发微博数、发微博用户的注册时间、发微博用户的用户种类;
所述传播特征包括:微博的传播结构、微博的转发数、微博的评论数、他人转发微博时的情感倾向、他人转发微博时候所使用的表情、转发微博的时间分数。
优选地,模型建立模块得到一个分类器模型,该分类器模型用于接收对应于一条微博的一棵传播树和一个特征向量作为输入,并给出该微博是否为谣言作为输出;
模型识别模块在识别一条待识别微博是否为谣言时,将该微博构建成一个特征向量和一棵传播树,再将该微博的特征向量和传播树代入到已建立的分类器模型中计算相似性,从而得到该微博是否为谣言。
优选地,传播树中的结点均表示一个网络用户;
根结点代表微博的发布者,传播树中的父子关系代表子结点表示的网络用户直接转发了父结点表示的网络用户的微博;
传播树中的结点均标记为p或n;若一个网络用户的粉丝数除以该网络用户的关注数的商值超过阈值即标记为p,否则标记为n;其中,p代表意见领袖,n代表普通用户;
传播树的边上也有标记,为一个三元组v=(θ(a),θ(d),θ(s)),表示了子结点表示的网络用户在转发父结点表示的网络用户微博的情感倾向;其中,a代表赞成情感分数,d代表反对情感分数,s代表总情感分数,θ(x)=2-ρtx为衰减函数,其中,t为时间,ρ为一个取值在0-1之间的参数,可在模型建立过程中进行调节,例如ρ可以设置为0、0.5、1等。
优选地,传播树经如下简化:
从根节点开始,将相邻的同标记为n的父子结点不断合并,直到不能合并为止。
优选地,两条微博信息mi和mj间的支持向量机的核函数K(mi,mj)用下式表示:
K(mi,mj)=βK(Ti,Tj)+(1-β)K(Xi,Xj)
其中,mi和mj为两条微博信息,β为分配系数,用于决定传播树和特征向量的相对重要程度,β值在0-1之间变化,Ti、Tj分别为微博信息mi、微博信息mj对应的传播树,Xi、Xj分别为微博信息mi、微博信息mj对应的特征向量,K(Ti,Tj)为两棵传播树Ti、Tj间的核函数,K(Xi,Xj)为两个特征向量Xi、Xj间的核函数。
优选地,K(Ti,Tj)采用随机游走法进行计算,其计算公式如下:
K(Ti,Tj)=eT(I-λA×)-1e
其中,e表示所有元素均为1的行向量,上标T表示转置,I表示单位矩阵,λ表示为小于1的常数,用于使计算结果收敛,A×为传播树Ti、Tj的直积图所对应的邻接矩阵;
对于两棵传播树T=(V,E)和T′=(V′,E′),该两棵传播树的直积图G×为G×=(T×T′)=(V×,E×),其中
V×={(v,v′)∈V×V′:label(v)=label(v′)}
V表示传播树T的顶点集,E表示传播树T的边集,V′表示传播树T′的顶点集,E′表示传播树T′的边集,v表示顶点集V中的任意顶点,v′表示顶点集V'中的任意顶点,label(v)表示边v的标记,label(v′)表示边v′的标记,u表示顶点集V中的不同于v的另一顶点,u′表示顶点集V'中的不同于v′的另一顶点。
优选地,所述他人转发微博时的情感倾向,为所有转发微博的情感分数的平均值;对于转发微博,首先进行中文分词和剔除停用词,其次采用以下公式计算:
其中,n是转发微博的数目,NPi和NNi分别是微博信息mi的积极词汇和消极词汇,|mi|是微博信息mi所有词汇的个数;积极词汇表示赞成情感,消极词汇表示反对情感;
所述转发微博的时间分数,是通过转发微博和原始微博之间所相差的天数来进行计算,计算公式如下:
其中,n是转发微博的数目,ti是第i条转发微博的发布时间,t0是原创微博的发布时间。
根据本发明提供的一种基于传播结构的微博谣言识别方法,利用上述的基于传播结构的微博谣言识别系统对微博谣言进行识别,包括如下步骤:
收集和提取微博的信息特征、用户特征以及传播特征;
通过支持向量机的机器学习的方法,以微博的信息特征、用户特征以及传播特征的特征数据为数据建立模型,以用于识别谣言;其中,建立模型时所使用的微博数据为数据库中的微博,即已经提前人工标记好是否为谣言的微博;每条微博用一棵传播树和一个特征向量表示,其中,传播树用以表示传播特征中的传播结构,将信息特征、用户特征、非传播结构的传播特征作为特征向量的各维;
利用已建立好的模型,分析待识别微博,从而判断待识别微博是否为谣言;其中,待识别微博的信息特征、用户特征和传播特征来自于数据采集模块。
与现有技术相比,本发明具有如下的有益效果:
1、深入考虑了微博信息的特征,尤其是对微博信息传播结构的比较,可大幅提高鉴别微博谣言的准确率和召回率。
2、所有特征均通过数据采集模块自动抓取和计算,无需人工干预,大幅提高鉴别速度,可用于大规模微博谣言的鉴别。
3、计算量较大的机器学习建模只需计算一次,之后即可重复使用。后续可鉴别特定微博信息,且计算量小。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明的模块示意图。
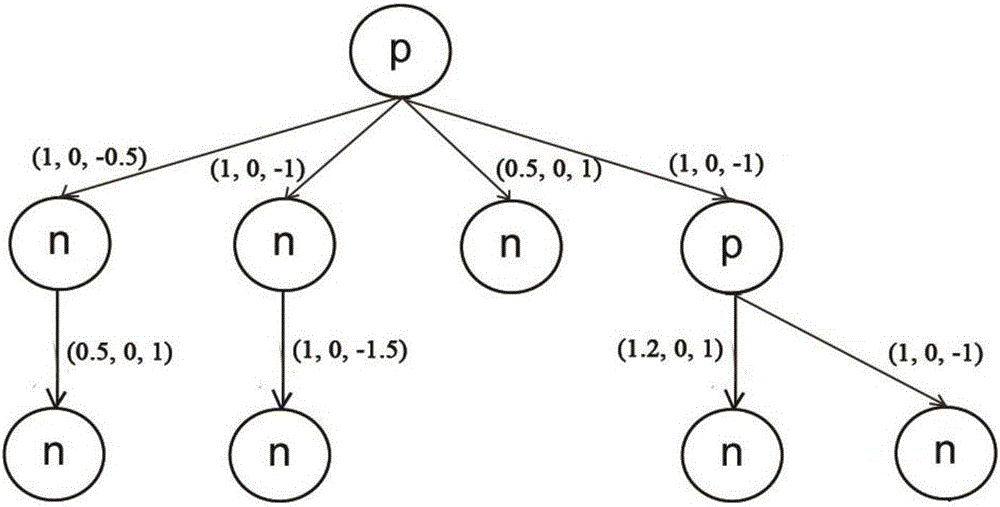
图2为传播结构表示图。
图3为简化后的传播结构表示图。
图4为本发明的流程图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
本发明的主要功能是利用和分析数据库中已知谣言和非谣言的信息特征、用户特征和传播特征,利用机器学习的方法进行建模,从而得到能够通过各特征来鉴别谣言的模型。然后,当出现待识别微博时,同样分析其信息特征、用户特征和传播特征,再根据已有的模型来判断待识别微博是否属于谣言。
本发明提供的基于传播结构的微博谣言识别系统,包括:数据采集模块、模型建立模块以及模型识别模块,如图1所示。
所述数据采集模块,用于收集和提取微博的信息特征、用户特征以及传播特征;
-信息特征包括:微博是否包含多媒体(图片、音频、视频)、微博所包含的情感倾向、微博是否包含URL链接、微博的发布时间相距用户的注册时间、微博发布的客户端、微博的话题种类、微博通过搜索引擎返回的结果数;
-用户特征包括:发微博用户是否经过大V认证、发微博用户是否含有个人描述、发微博用户的性别、发微博用户的账号注册地点、发微博用户的粉丝数、发微博用户的关注数、发微博用户的发微博数、发微博用户的注册时间、发微博用户的用户种类;
-传播特征包括:微博的传播结构、微博的转发数、微博的评论数、他人转发微博时的情感倾向、他人转发微博时候所使用的表情、转发微博的时间分数。
所述模型建立模块,用于通过机器学习的方法,以所述信息特征、用户特征以及传播特征的特征数据为数据建立模型,以用于识别谣言。
其中,模型建立模块所使用的微博数据为数据库(见附图1)中的微博,即已经提前人工标记好是否为谣言的微博。
在建立模型时,可采用支持向量机(SVM)的机器学习经典算法。其中,每条微博可以用一棵传播树(传播树用以表示传播特征中的传播结构)和一个特征向量表示,将从数据采集模块得到的信息特征、用户特征、非传播结构的传播特征作为特征向量的各维,再给予微博谣言和微博非谣言不同的人工标记来参与计算。
在标记时,将微博谣言和微博非谣言标记为不同的两类(class,例如0和1),这样即可将谣言的识别问题转换为机器学习中的分类问题(classification problem)从而参与计算。
在计算时,采用交叉验证的方法,以提高模型的准确率和召回率。模型建立模块最终会得到一个分类器模型,该分类器可接受一棵传播树和一个特征向量(两者合起来即一条待识别微博,其中传播结构用传播树表示,信息特征、用户特征、非传播结构的传播特征作为特征向量各维)作为输入,并给出该微博是否为谣言(class为0或1)作为输出。
所述模型识别模块,用于利用模型建立模块已建立好的模型,分析待识别微博,从而判断其是否为谣言。其中待识别微博(见附图1)的特征信息也来自于数据采集模块。仍然采用支持向量机的方法,用已建立的模型来计算待识别微博,再判断其是否为谣言。
在综合利用信息特征、用户特征和传播特征,识别出谣言时,具体来说,在识别一条待识别微博(见附图1)是否为谣言时,可将该微博的各特征数据(信息特征、用户特征、传播特征)也构建成一个特征向量和一棵传播树,再将该微博的特征向量和传播树代入到已建立的支持向量机模型中,从而得到该微博是否为谣言。
本发明是基于经典的支持向量机分类算法基础之上,支持向量机分类算法的核心在于给定两个特征向量之后,如何通过核函数来计算两者之间的相似性。本发明创新点在于将从微博中提取的特征数据用特征向量及传播树表示,并发明了新的核函数来计算两条微博(一个微博用一棵传播树与一个特征向量表示)之间的相似性,具体如何利用核函数来计算请参照实施举例2。在定义好核函数之后,即可采用经典的支持向量机算法来建立模型及识别谣言微博。
根据本发明提供的一种基于传播结构的微博谣言识别方法,利用上述的基于传播结构的微博谣言识别系统对微博谣言进行识别,包括如下步骤:
收集和提取微博的信息特征、用户特征以及传播特征;
通过支持向量机的机器学习的方法,以微博的信息特征、用户特征以及传播特征的特征数据为数据建立模型,以用于识别谣言;其中,建立模型时所使用的微博数据为数据库中的微博,即已经提前人工标记好是否为谣言的微博;每条微博用一棵传播树和一个特征向量表示,其中,传播树用以表示传播特征中的传播结构,将信息特征、用户特征、非传播结构的传播特征作为特征向量的各维;
利用已建立好的模型,分析待识别微博,从而判断待识别微博是否为谣言;其中,待识别微博的信息特征、用户特征和传播特征来自于数据采集模块。
实施举例1:传播结构的表示和简化
识别谣言时的一个重要特征是微博的传播结构。微博的传播结构以树结构来表示,如图2所示。一条微博的传播结构即为一棵传播树,传播树可以反映该条微博在社交网络中的传播模式(propagation pattern),通过在核函数中计算两条微博的传播树之间的相似性,即可用经典的支持向量机算法鉴别谣言微博。
传播树中的结点均表示一个网络用户。其中根结点代表微博的发布者,树中的父子关系代表子结点的用户直接转发了父结点的用户的微博。树结点均标记为p或n,若一个用户的粉丝数除以其关注数,超过阈值即标记为p,否则标记为n。其中,p代表意见领袖(public opinion leader),n代表普通用户(normal user)。意见领袖在概念上类似于新浪微博中的大V用户,即拥有大量的普通用户为其粉丝。之所以将意见领袖和普通用户区分开来,是因为意见领袖的发言(如声明某微博很赞,或某微博是虚假的)会得到很多普通用户的转发和赞同。这在后续的谣言识别中十分重要。通过计算一条待识别微博的传播结构是否和数据库中的已标记为谣言的微博的传播结构相似(例如均在传播树的早期被意见领袖误传为是非谣言),可快速识别该微博是否为谣言(具体方法详见实施举例2)。树的边上也有标记,为一个三元组v=(θ(a),θ(d),θ(s)),表示了子结点用户在转发父结点用户微博的情感倾向。其中a代表赞成情感分数,d代表反对情感分数,s代表总情感分数,详细计算方法请参见实施举例3。三元组作为树的边的标记,将会参与核函数的计算(详见实施举例2)。其中θ(x)=2-ρtx为衰减函数,其中t为时间,ρ为一个取值在0-1之间的参数,可在模型建立过程中进行调节;该函数值会随着时间的增大而衰减。为减小计算量,将传播树再做一定简化。具体简化原则是从根节点开始,将相邻的同标记为n的父子结点不断合并,直到不能合并为止。例如图2的传播树经过简化后如图3所示。
实施举例2:支持向量机的核函数
在模型建立模块中,需要通过支持向量机的方法建立模型,模型里需要包含从数据采集模块中得到的各个特征(特别是传播特征)的信息。在本发明中,每条微博的特征数据可用一个特征向量X和一颗传播树T来表示其中特征向量的各维为各个细化特征,传播树用于表示微博的传播特征中的传播结构。随后,可将数据库中已人工标记好的微博的特征向量和传播树用支持向量机算法来建立模型。在本发明中,两条微博信息mi和mj间的支持向量机的核函数K(mi,mj)用下式表示:
K(mi,mj)=βK(Ti,Tj)+(1-β)K(Xi,Xj)
其中,mi和mj为两条微博信息,Xi、Xj为微博信息mi、微博信息mj对应的向量,Ti、Tj为微博信息mi、微博信息mj对应的传播树。β为分配系数,用于决定传播树(T)和特征向量(X)的相对重要程度,该值可在0-1之间变化,β=0时核函数值只由特征向量决定,β=1时核函数值只由传播树决定。下标i表示微博mi,下标j表示微博mj。K(Xi,Xj)为两个向量Xi、Xj间的核函数,其计算方法和传统向量机一致(径向基核函数)。K(Ti,Tj)为两棵传播树Ti、Tj间的核函数,在本发明中采用随机游走法(random walk)进行计算,其计算公式如下:
K(Ti,Tj)=eT(I-λA×)-1e
其中A×为传播树Ti、Tj的直积图所对应的邻接矩阵,e表示所有元素均为1的行向量,I表示单位矩阵,λ表示为小于1的常数,用于使计算结果收敛。对于两棵传播树T=(V,E)和T′=(V′,E′),该两棵传播树的直积图G×为G×=(T×T′)=(V×,E×),其中
V×={(v,v′)∈V×V′:label(v)=label(v′)}
V表示传播树T的顶点集,E表示传播树T的边集,V′表示传播树T′的顶点集,E′表示传播树T′的边集,v表示顶点集V中的任意顶点,v′表示顶点集V'中的任意顶点,label(v)表示边v的标记(三元组),label(v′)表示边v′的标记(三元组),u表示顶点集V中的不同于v的另一顶点,u′表示顶点集V'中的不同于v′的另一顶点。
实施举例3:微博特征的具体采集方法
在数据采集模块,需要采集微博的信息特征、用户特征和传播特征,本领域技术人员可以参照现有技术实现。现将其中较复杂的特征的具体采集方法陈述如下:
微博的话题种类:根据新浪微博的官方分类,本发明将微博话题共分为18类,并采用LDA模型对微博进行分类。其中,假设一条微博可属于一个或多个话题。
微博通过搜索引擎返回的结果数:将微博的原始内容和关键字“谣言”一起在搜索引擎中进行检索,以获得其返回的结果数。由于搜索引擎有长度的限制,对于较长的微博可按照标点符号分为几小段,再分别和“谣言”一起作为关键字进行搜索。
发微博用户的用户种类:新浪微博不仅对用户进行大V认证,还会进一步将其分为不同种类。例如未认证、官方媒体、娱乐明星等。
他人转发微博时的情感倾向:为所有转发微博的情感分数的平均值。对于转发微博,首先进行中文分词和剔除停用词,其次采用以下公式计算:
其中NPi和NNi分别是微博信息mi的第i个积极词汇和第i个消极词汇,|mi|是微博信息mi所有词汇的个数,n是转发微博的数目。下标i表示第i个词汇。若将公式中的词汇换做赞成词汇或反对词汇,即可计算传播树中的边的标记三元组里的a和d(见实施举例1)。
转发微博的时间分数:通过转发微博和原始微博之间所相差的天数来进行计算,其计算公式如下:
其中n是转发微博的数目,ti是第i条转发微博的发布时间,t0是原创微博的发布时间。此特征可表示转发微博的反响速度。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
- 还没有人留言评论。精彩留言会获得点赞!