一种基于HOG和视觉词袋的相似图像搜索方法和装置与流程
本发明涉及一种相似图像搜索方法,尤其涉及一种基于HOG和视觉词袋的相似图像搜索方法和装置。
背景技术:
互联网的普及以及搜索引擎技术的巨大发展为人们的生活带来了极大的便利,人们可以快速、准确地在互联网上找到所需要的东西。
图像搜索是一个新兴的搜索模式,而互联网上有约数以百亿的图像,并且每天都在以数百万的速度增长,要快速有效地识别所搜索的图像,其相关技术条件不是非常成熟,具有较好的发展空间。
方向梯度直方图特征,简称HOG特征是通过计算和统计图像局部区域的梯度方向直方图来构成特征,HOG特征结合SVM分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功;词袋模型已被应用到图像处理领域,用来进行图像分类,即通过将一幅图像看成是由一系列视觉单词组成的文章,实现图像的高速分类,是一种有效的基于图像语义特征提取与描述的图像分类算法,但是,目前还未有一种将HOG特征提取和视觉词袋模型结合在一起,来提高相似图像搜索准确率的方法和装置。
鉴于上述缺陷,本发明创作者经过长时间的研究和实践终于获得了本发明。
技术实现要素:
为解决上述问题,本发明采用的技术方案在于,一方面提供一种基于HOG和视觉词袋的相似图像搜索装置,包括预处理单元、输入单元、高斯差分单元、选取单元、HOG特征提取单元、聚类单元、视觉词袋单元和训练单元;
所述预处理单元,用于将训练的图像进行分类作为训练集图像,并对测试图像和所述训练集图像的大小进行归一化;
所述输入单元,用于输入归一化后的所述测试图像和所述训练集图像;
所述高斯差分单元,用于通过高斯差分算法寻找所述输入单元中的所述测试图像和所述训练集图像中每一幅图像的稳定关键点;
所述选取单元,用于选取所述测试图像和所述训练集图像中每一幅图像的稳定关键点的最密集的前N个区域;
所述HOG特征提取单元,用于对所述最密集的前N个区域进行HOG特征提取;
所述聚类单元,用于通过K-Means聚类算法对所述训练集图像中的所述HOG特征进行聚类,得到的n个聚类中心为视觉词袋的n个视觉单词;
所述视觉词袋单元,用于在所述训练集图像的视觉单词中寻找与所述测试图像中的每一个特征最近邻的视觉单词,并统计所述测试图像中所找到的所有视觉单词出现的频率,得到的频率直方图为所述测试图像的视觉词袋;
所述训练单元,用于使用支持向量机分类器对所述训练集图像的视觉词袋进行训练,得到的模型对所述测试图像的视觉词袋进行测试,得到所述测试图像的分类结果,反馈同一类别的图片。
进一步,所述高斯差分单元包括分层模块、差分模块、比较模块、第一删除模块和第二删除模块;
所述分层模块,用于对所述相应图像f(x,y)加入高斯滤波Gσ1(x,y)、Gσ2(x,y),得到两幅图像g1(x,y)和g2(x,y):
g1(x,y)=Gσ1(x,y)×f(x,y)
g2(x,y)=Gσ2(x,y)×f(x,y)
所述差分模块,用于将得到的两幅图像g1(x,y)、g2(x,y)进行相减,得到高斯差分图像:
g1(x,y)-g2(x,y)=Gσ1×f(x,y)-Gσ1×f(x,y)=DoG×f(x,y)
所述比较模块,用于将高斯差分图像中每一个像素点与其所有的相邻点进行比较,若每一个所述像素点比其图像域和尺度域中的相邻点都大或都小,那该所述像素点则为极值点;
所述第一删除模块,用于去除对比度低的所述极值点,利用高斯差分函数在尺度空间Taylor展开式分别对所述高斯差分空间的多层图像的行、列及尺度三个分量进行修正,Taylor展开式为:
对所述Taylor展开式进行求导并令其为0,得到:
将结果代入所述Taylor展开式中得:
式中,x表示所述极值点,D表示所述极值点处的Harris响应值,T表示转秩,若则所述极值点保留,否则删除所述极值点;
所述第二删除模块,用于去除边缘不稳定的所述极值点,所述高斯差分函数的极值点在横跨边缘的方向有较大的主曲率,在垂直边缘的方向有较小的主曲率,主曲率通过计算所述极值点位置尺度的二阶Hessian矩阵求出:
式中,D表示所述极值点处的Harris响应值,H表示二阶Hessian矩阵,所述D的主曲率和所述H的特征值成正比,令α为较大的所述特征值,β为较小的所述特征值,则
Tr(H)=Dxx+Dyy=α+β
Det(H)=DxxDyy-(Dxy)2=αβ
令α=rβ得,由于在所述α、β相等的时候最小,随着r的增大而增大,因此当不满足下式时,所述极值点删除,反之保留,保留下来的所述极值点是稳定关键点:
式中,H表示Hessian矩阵,Tr(H)代表Hessian矩阵的对角线元素之和,Det(H)代表Hessian矩阵的行列式。
进一步,所述HOG特征提取单元包括第一处理模块、第二处理模块、划分模块、第一计算模块、第一串联模块、第二串联模块和转换模块;
所述第一处理模块,用于将所述测试图像或所述训练集图像中每一幅图像的所述前N个区域中的每一块区域视为一个图像,进行灰度化;
所述第二处理模块,用于通过Gamma校正法对灰度化后的每一块区域对应的每一个图像进行颜色空间的归一化;
所述划分模块,用于将归一化后的所述每一个图像划分为单元格,每2×2个像素点组成一个单元格;
所述第一计算模块,用于计算所述每一个图像中每个像素点(x,y)的梯度,捕获轮廓信息,其中,所述梯度包括大小和方向:
Gx(x,y)=H(x+1,y)-H(x-1,y)
Gy(x,y)=H(x,y+1)-H(x,y-1)
Gx(x,y),Gy(x,y),H(x,y)分别代表所述像素点(x,y)处的水平方向梯度、垂直方向梯度和像素值;
所述像素点(x,y)处的梯度幅值和梯度方向分别为:
采用无符号(0-180)形式,并将(0-180)分成9等分,每个所述单元格产生9维的特征;
所述第一串联模块,用于将每2×2个所述单元格组成一个块,一个块内所有单元格的所述特征向量串联起来后归一化,便得到该块的HOG特征;
所述第二串联模块,用于将所述每一个图像中的所有块的HOG特征串联起来就得到所述每一个图像的HOG特征;
变换模块,用于将所述每一个图像的HOG特征进行归一化,所述归一化的过程为:对所述HOG特征提取后的特征向量v进行特征变换,如下式:
v←v/255
式中,v为特征向量,ε为常数。
进一步,所述聚类单元包括集合模块、确定模块和第二计算模块;
所述集合模块,用于将所述训练集图像中的所有图像的HOG特征用矩阵集合统一表示;
所述确定模块,用于根据应用需求确定聚类中心数值n;
所述第二计算模块,用于对所述训练集图像的矩阵集合进行K-Means均值聚类计算,得到的n个聚类中心即为视觉词袋的n个视觉单词。
进一步,所述视觉词袋单元包括替换模块和统计模块;
所述替换模块,用于利用欧式距离法计算所述测试图像的每个HOG特征与所述视觉词袋中每个视觉单词的相似度,将所述测试图像中的所述HOG特征用所述视觉词袋中相似度最高的视觉单词近似代替,欧氏距离为:
其中,Ha,Hb分别为所述测试图像中的一个HOG特征向量和所述视觉词袋中的一个视觉单词向量,i表示所述测试图像的HOG特征的维数;
所述统计模块,用于统计所述测试图像中找到的所有视觉单词出现的频率,得到的频率直方图即为所述测试图像的视觉词袋。
另一方面,提供一种基于HOG和视觉词袋的相似图像搜索方法,包括以下步骤:
S1:用于将训练的图像进行分类作为训练集图像,并对测试图像和所述训练集图像的大小进行归一化;
S2:输入归一化后的所述测试图像和所述训练集图像,并对所述训练集图像中的每幅图像进行S3-S5的步骤;
S3:通过高斯差分算法寻找相应图像的稳定关键点;
S4:选取所述稳定关键点的最密集的前N个区域;
S5:对所述最密集的前N个区域进行HOG特征提取;
S6:在所述训练集图像中的每幅图像进行完S3-S5的步骤后,使用K-Means聚类算法对所述训练集图像中的所述HOG特征进行聚类,得到的n个聚类中心为视觉词袋的n个视觉单词;
S7:对输入的所述测试图像进行S3-S5的操作;
S8:在所述训练集图像的视觉单词中寻找与所述测试图像中的每一个特征最近邻的视觉单词,并统计所述测试图像中所找到的所有视觉单词出现的频率,得到的频率直方图为所述测试图像的视觉词袋;
S9:使用支持向量机分类器对所述训练集图像的视觉词袋进行训练,得到的模型对所述测试图像的视觉词袋进行测试,得到所述测试图像的分类结果,反馈同一类别的图片。
进一步,所述步骤S3具体包括:
步骤S31:对所述相应图像f(x,y)加入高斯滤波Gσ1(x,y)、Gσ2(x,y),得到两幅图像g1(x,y)和g2(x,y):
g1(x,y)=Gσ1(x,y)×f(x,y)
g2(x,y)=Gσ2(x,y)×f(x,y)
步骤S32:将得到的两幅图像g1(x,y)、g2(x,y)进行相减,得到高斯差分图像:
g1(x,y)-g2(x,y)=Gσ1×f(x,y)-Gσ1×f(x,y)=DoG×f(x,y)
步骤S33:将高斯差分图像中每一个像素点与其所有的相邻点进行比较,若每一个所述像素点比其图像域和尺度域中的相邻点都大或都小,那该所述像素点则为极值点;
步骤S34:去除对比度低的所述极值点,利用高斯差分函数在尺度空间Taylor展开式分别对所述高斯差分空间的多层图像的行、列及尺度三个分量进行修正,Taylor展开式为:
对所述Taylor展开式进行求导并令其为0,得到:
将结果代入所述Taylor展开式中得:
式中,x表示所述极值点,D表示所述极值点处的Harris响应值,T表示转秩,若则所述极值点保留,否则删除所述极值点;
步骤S35:去除边缘不稳定的所述极值点,所述高斯差分函数的极值点在横跨边缘的方向有较大的主曲率,在垂直边缘的方向有较小的主曲率,主曲率通过计算所述极值点位置尺度的二阶Hess i an矩阵求出:
式中,D表示所述极值点处的Harris响应值,H表示二阶Hessian矩阵,所述D的主曲率和所述H的特征值成正比,令α为较大的所述特征值,β为较小的所述特征值,则
Tr(H)=Dxx+Dyy=α+β
Det(H)=DxxDyy-(Dxy)2=αβ
令α=rβ得,由于在所述α、β相等的时候最小,随着r的增大而增大,因此当不满足下式时,所述极值点删除,反之保留,保留下来的所述极值点是稳定关键点:
式中,H表示Hessian矩阵,Tr(H)代表Hessian矩阵的对角线元素之和,Det(H)代表Hessian矩阵的行列式。
进一步,所述步骤S5具体包括:
步骤S51:将所述相应图像中所述前N个区域的每一块区域视为一个图像,进行灰度化;
步骤S52:采用Gamma校正法对灰度化后的每一块区域对应的每一个图像进行颜色空间的归一化;
步骤S53:将归一化后的所述每一个图像划分为单元格,每2×2个像素点组成一个单元格;
步骤S54:计算所述每一个图像中每个像素点(x,y)的梯度,捕获轮廓信息,其中,所述梯度包括大小和方向:
Gx(x,y)=H(x+1,y)-H(x-1,y)
Gy(x,y)=H(x,y+1)-H(x,y-1)
Gx(x,y),Gy(x,y),H(x,y)分别代表所述像素点(x,y)处的水平方向梯度、垂直方向梯度和像素值;
所述像素点(x,y)处的梯度幅值和梯度方向分别为:
采用无符号(0-180)形式,并将(0-180)分成9等分,每个所述单元格产生9维的特征;
步骤S55:将每2×2个所述单元格组成一个块,一个块内所有单元格的所述特征向量串联起来后归一化,便得到该块的HOG特征;
步骤S56:将所述每一个图像中的所有块的HOG特征串联起来就得到所述每一个图像的HOG特征;
步骤S57:将所述每一个图像的HOG特征进行归一化,所述归一化的过程为:对所述HOG特征提取后的特征向量v进行特征变换,如下式:
v←v/255
式中,v为特征向量,ε为常数。
进一步,所述步骤S6具体包括:
步骤S61:将所述训练集图像中的所有图像的HOG特征用矩阵集合统一表示;
步骤S62:根据应用需求确定聚类中心数值n;
步骤S63:对所述训练集图像的矩阵集合进行K-Means均值聚类计算,得到的n个聚类中心即为视觉词袋的n个视觉单词。
进一步,所述步骤S8具体包括:
步骤S81:利用欧式距离法计算所述测试图像的每个HOG特征与所述视觉词袋中每个视觉单词的相似度,将所述测试图像中的所述HOG特征用所述视觉词袋中相似度最高的视觉单词近似代替,欧氏距离为:
其中,Ha,Hb分别为所述测试图像中的一个HOG特征向量和所述视觉词袋中的一个视觉单词向量,i表示所述测试图像的HOG特征的维数;
步骤S82:统计所述测试图像中找到的所有视觉单词出现的频率,得到的频率直方图(n维)即为所述测试图像的视觉词袋。
与现有技术比较本发明的有益效果在于:
1.使用高斯差分算子寻找稳定关键点并确定特征提取区域,减少了传统使用HOG特征提取时对整幅图像进行滑窗扫描操作,既节省了时间,又提高了效率;
2.使用HOG特征可以让图像局部像素点之间的关系得到很好的表征,除此之外,位置和方向空间的量化在一定程度上抑制了平移和旋转带来的影响;
3.使用视觉词袋模型,相对基于文本的相似图像搜索,更好地避免了语义鸿沟的问题。
附图说明
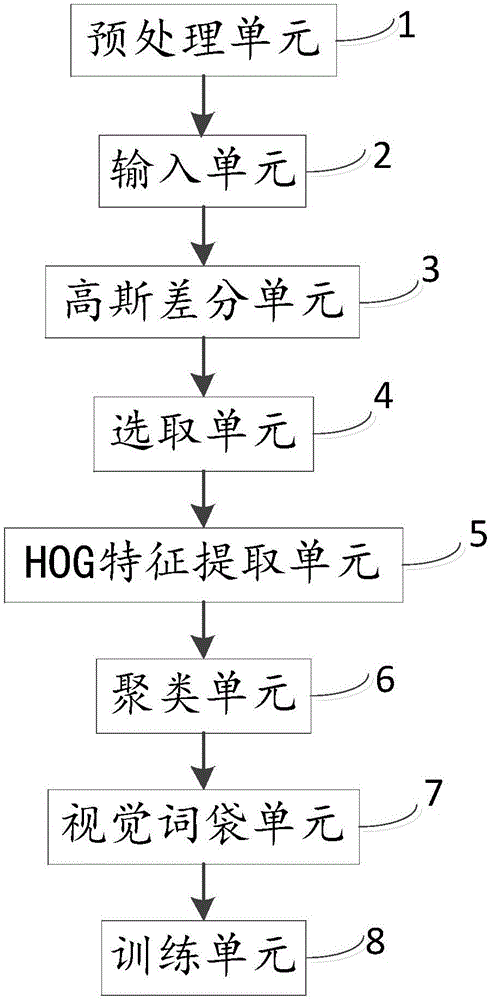
图1为本发明基于HOG和视觉词袋的相似图像搜索装置的功能框图;
图2为本发明预处理单元的功能框图;
图3为本发明高斯差分单元的功能框图;
图4为本发明选取单元的功能框图;
图5为本发明HOG特征提取单元的功能框图;
图6为本发明聚类单元的功能框图;
图7为本发明视觉词袋单元的功能框图;
图8为本发明基于HOG和视觉词袋的相似图像搜索方法的流程图。
具体实施方式
以下结合附图,对本发明上述的和另外的技术特征和优点作更详细的说明。
实施例一
如图1所示,其为本发明一种基于HOG和视觉词袋的相似图像搜索装置的功能框图,一种基于HOG和视觉词袋的相似图像搜索装置包括:预处理单元1、输入单元2、高斯差分单元3、选取单元4、HOG特征提取单元5、聚类单元6、视觉词袋单元7和训练单元8;
所述预处理单元1,用于将训练的图像进行分类作为训练集图像,并对测试图像和所述训练集图像的大小进行归一化;
所述输入单元2,用于输入归一化后的所述测试图像和所述训练集图像;
所述高斯差分单元3,用于通过高斯差分(DoG)算法寻找所述输入单元中的所述测试图像和所述训练集图像中每一幅图像的稳定关键点;
所述选取单元4,用于选取所述测试图像和所述训练集图像中每一幅图像的稳定关键点的最密集的前N个区域;
所述HOG特征提取单元5,用于对所述最密集的前N个区域进行HOG特征提取;
所述聚类单元6,用于通过K-Means聚类算法对所述训练集图像中的所述HOG特征进行聚类,得到的n个聚类中心为视觉词袋的n个视觉单词;
所述视觉词袋单元7,用于在所述训练集图像的视觉单词中寻找与所述测试图像中的每一个特征最近邻的视觉单词,并统计所述测试图像中所找到的所有视觉单词出现的频率,得到的频率直方图(n维)为所述测试图像的视觉词袋;
所述训练单元8,用于使用支持向量机(SVM)分类器对所述训练集图像的视觉词袋进行训练,得到的模型对所述测试图像的视觉词袋进行测试,得到所述测试图像的分类结果,反馈同一类别的图片。
如图2所示,为本发明预处理单元的功能框图,所述预处理单元1包括分类模块11和预处理模块12;
所述分类模块11,用于对要训练的图像进行分类,添加类别标签,并从每类中挑选相同数目的图像作为训练集图像;
所述预处理模块12,用于对测试图像和所述训练集图像进行尺寸大小归一化。
如图3所示,为本发明高斯差分单元3的功能框图,所述高斯差分单元3包括分层模块31、差分模块32、比较模块33、第一删除模块34和第二删除模块35;
所述分层模块31,用于对所述测试图像f(x,y)或所述训练集图像中的每一幅训练图像f(x,y)加入高斯滤波Gσ1(x,y)、Gσ2(x,y),得到两幅图像g1(x,y)和g2(x,y),如下式:
g1(x,y)=Gσ1(x,y)×f(x,y)
g2(x,y)=Gσ2(x,y)×f(x,y)
其中,σ1,σ2表示不同的高斯滤波;
所述差分模块32,用于将得到的两幅图像g1(x,y)、g2(x,y)进行相减,得到高斯差分(DOG)图像:
g1(x,y)-g2(x,y)=Gσ1×f(x,y)-Gσ1×f(x,y)=DoG×f(x,y)
所述比较模块33,用于将高斯差分图像中每一个像素点与其所有的相邻点进行比较,若每一个所述像素点比其图像域和尺度域中的相邻点都大或都小,那该所述像素点则为极值点,其中,所述图像域为每一个所述像素点所在的层面,所述尺度域为与所述图像域相邻上下两层所在的层面;
所述第一删除模块34,用于去除对比度低的所述极值点,利用高斯差分函数(DOG)在尺度空间Taylor展开式分别对所述高斯差分(DOG)金字塔空间的多层图像的行、列及尺度三个分量进行修正,Taylor展开式为:
对所述Taylor展开式进行求导并令其为0,得到:
将结果代入所述Taylor展开式中得:
式中,x表示所述极值点,D表示所述极值点处的Harris响应值,T表示转秩,若则所述极值点保留,否则删除所述极值点;
所述第二删除模块35,用于去除边缘不稳定的所述极值点,所述高斯差分函数的极值点在横跨边缘的方向有较大的主曲率,在垂直边缘的方向有较小的主曲率,主曲率通过计算所述极值点位置尺度的二阶Hessian矩阵求出:
式中,D表示所述极值点处的Harris响应值,H表示二阶Hessian矩阵,所述D的主曲率和所述H的特征值成正比,令α为较大的所述特征值,β为较小的所述特征值,则
Tr(H)=Dxx+Dyy=α+β
Det(H)=DxxDyy-(Dxy)2=αβ
令α=rβ得,由于在所述α、β相等的时候最小,随着r的增大而增大,因此当不满足下式时,所述极值点删除,反之保留,保留下来的所述极值点是稳定关键点:
式中,H表示Hessian矩阵,Tr(H)代表Hessian矩阵的对角线元素之和,Det(H)代表Hessian矩阵的行列式。
如图4示,为本发明选取单元4的功能框图,所述选取单元4包括分割模块41和选择模块42;
所述分割模块41,用于将所述测试图像或所述训练集图像中的每一幅图像按照m×m(m<M,M=km,k∈Z)大小进行分块,统计每一块中的所述稳定关键点的个数,其中,M代表所述测试图像的边长或所述训练集图像中每一幅图像的边长;
所述选择模块42,用于选择所述测试图像或所述训练集图像中每一幅图像的稳定关键点的最密集的前N个区域,其中,N取整数。
本发明使用高斯差分算子寻找稳定关键点并确定特征提取区域,减少了传统使用HOG特征提取时对整幅图像进行滑窗扫描操作,既节省了时间,又提高了效率。
如图5示,为本发明HOG特征提取单元5的功能框图,所述HOG特征提取单元5包括第一处理模块51、第二处理模块52、划分模块53、第一计算模块54、第一串联模块55、第二串联模块56和转换模块57。
所述第一处理模块51,用于将所述测试图像或所述训练集图像中每一幅图像的所述前N个区域中的每一块区域视为一个图像,进行灰度化;
所述第二处理模块52,用于通过Gamma校正法对灰度化后的每一块区域对应的每一个图像进行颜色空间的归一化,这样,可以调节所述每一个图像的对比度,降低所述每一个图像局部的阴影和光照变化所造成的影响,同时抑制噪音的干扰;
所述划分模块53,用于将归一化后的所述每一个图像划分为单元格,每2×2个像素点组成一个单元格;
所述第一计算模块54,用于计算所述每一个图像中每个像素点(x,y)的梯度,捕获轮廓信息,其中,所述梯度包括大小和方向:
Gx(x,y)=H(x+1,y)-H(x-1,y)
Gy(x,y)=H(x,y+1)-H(x,y-1)
Gx(x,y),Gy(x,y),H(x,y)分别代表所述像素点(x,y)处的水平方向梯度、垂直方向梯度和像素值。
所述像素点(x,y)处的梯度幅值和梯度方向分别为:
梯度方向分为有符号(0-360)和无符号(0-180)两种形式,本装置采用的是无符号的形式,并将(0-180)分成9等分,所以,所述每一个图像中每个所述单元格的梯度方向都分成9个方向块,使用所述单元格中的梯度方向和大小对9个方向块进行加权投影,最后,每个所述单元格产生9维的特征。
所述第一串联模块55,用于将每2×2个所述单元格组成一个块,一个块内所有单元格的所述特征向量串联起来后归一化,便得到该块的HOG特征;
所述第二串联模块56,用于将所述每一个图像中的所有块的HOG特征串联起来就得到所述每一个图像的HOG特征;
变换模块57,用于将所述每一个图像的HOG特征进行归一化,所述归一化的过程为:对所述HOG特征提取后的特征向量v进行特征变换,如下式:
v←v/255
式中,v为特征向量,ε为常数。
本发明使用HOG特征可以让图像局部像素点之间的关系得到很好的表征,除此之外,位置和方向空间的量化在一定程度上抑制了平移和旋转带来的影响。
如图6示,为本发明聚类单元6的功能框图,所述聚类单元6包括集合模块61、确定模块62和第二计算模块63;
所述集合模块61,用于将所述训练集图像中的所有图像的HOG特征用矩阵集合统一表示;
所述确定模块62,用于根据应用需求确定聚类中心数值n;
所述第二计算模块63,用于对所述训练集图像的矩阵集合进行K-Means均值聚类计算,得到的n个聚类中心即为视觉词袋的n个视觉单词。
如图7示,为本发明视觉词袋单元7的功能框图,所述视觉词袋单元7包括替换模块71和统计模块72;
所述替换模块71,用于利用欧式距离法计算所述测试图像的每个HOG特征与所述视觉词袋中每个视觉单词的相似度,将所述测试图像中的所述HOG特征用所述视觉词袋中相似度最高的视觉单词近似代替。欧氏距离为:
其中,Ha,Hb分别为所述测试图像中的一个HOG特征向量和所述视觉词袋中的一个视觉单词向量,i表示所述测试图像的HOG特征的维数。
所述统计模块72,用于统计所述测试图像中找到的所有视觉单词出现的频率,得到的频率直方图(n维)即为所述测试图像的视觉词袋。
本发明使用视觉词袋模型,相对基于文本的相似图像搜索,更好地避免了语义鸿沟的问题。
实施例二
如图8所示,为本发明一种基于HOG和视觉词袋的相似图像搜索方法的功能框图,包括以下步骤:
S1:用于将训练的图像进行分类作为训练集图像,并对测试图像和所述训练集图像的大小进行归一化;
S2:输入归一化后的所述测试图像和所述训练集图像,并对所述训练集图像中的每幅图像进行S3-S5的步骤;
S3:通过高斯差分(DoG)算法寻找相应图像的稳定关键点;
S4:选取所述稳定关键点的最密集的前N个区域;
S5:对所述最密集的前N个区域进行HOG特征提取;
S6:在所述训练集图像中的每幅图像进行完S3-S5的步骤后,使用K-Means聚类算法对所述训练集图像中的所述HOG特征进行聚类,得到的n个聚类中心为视觉词袋的n个视觉单词;
S7:对输入的所述测试图像进行S3-S5的操作;
S8:在所述训练集图像的视觉单词中寻找与所述测试图像中的每一个特征最近邻的视觉单词,并统计所述测试图像中所找到的所有视觉单词出现的频率,得到的频率直方图(n维)为所述测试图像的视觉词袋;
S9:使用支持向量机(SVM)分类器对所述训练集图像的视觉词袋进行训练,得到的模型对所述测试图像的视觉词袋进行测试,得到所述测试图像的分类结果,反馈同一类别的图片。
所述步骤S1具体包括:
步骤S11:对要训练的图像进行分类,添加类别标签,并从每类中挑选相同数目的图像作为训练集图像;
步骤S12:用于对测试图像和所述训练集图像进行尺寸大小归一化。
所述步骤S3具体包括:
步骤S31:对所述相应图像f(x,y)加入高斯滤波Gσ1(x,y)、Gσ2(x,y),得到两幅图像g1(x,y)和g2(x,y):
g1(x,y)=Gσ1(x,y)×f(x,y)
g2(x,y)=Gσ2(x,y)×f(x,y)
σ1,σ2表示两种不同的高斯滤波;
步骤S32:将得到的两幅图像g1(x,y)、g2(x,y)进行相减,得到高斯差分(DOG)图像:
g1(x,y)-g2(x,y)=Gσ1×f(x,y)-Gσ1×f(x,y)=DoG×f(x,y)
步骤S33:将高斯差分图像中每一个像素点与其所有的相邻点进行比较,若每一个所述像素点比其图像域和尺度域中的相邻点都大或都小,那该所述像素点则为极值点,其中,所述图像域为每一个所述像素点所在的层面,所述尺度域为与所述图像域相邻上下两层所在的层面;
步骤S34:去除对比度低的所述极值点,利用高斯差分(DOG)函数在尺度空间Taylor展开式分别对所述高斯差分(DOG)空间的多层图像的行、列及尺度三个分量进行修正,Taylor展开式为:
对所述Taylor展开式进行求导并令其为0,得到:
将结果代入所述Taylor展开式中得:
式中,x表示所述极值点,D表示所述极值点处的Harris响应值,T表示转秩,若则所述极值点保留,否则删除所述极值点;
步骤S35:去除边缘不稳定的所述极值点,所述高斯差分(DOG)函数的极值点在横跨边缘的方向有较大的主曲率,在垂直边缘的方向有较小的主曲率,主曲率通过计算所述极值点位置尺度的二阶Hessian矩阵求出:
式中,D表示所述极值点处的Harris响应值,H表示二阶Hessian矩阵,所述D的主曲率和所述H的特征值成正比,令α为较大的所述特征值,β为较小的所述特征值,则
Tr(H)=Dxx+Dyy=α+β
Det(H)=DxxDyy-(Dxy)2=αβ
令α=rβ得,由于在所述α、β相等的时候最小,随着r的增大而增大,因此当不满足下式时,所述极值点删除,反之保留,保留下来的所述极值点是稳定关键点:
式中,H表示Hessian矩阵,Tr(H)代表Hessian矩阵的对角线元素之和,Det(H)代表Hessian矩阵的行列式。
所述步骤S4具体包括:
步骤S41:将所述相应图像按照m×m(m<M,M=km,k∈Z)的大小进行分块,统计每一块中的所述稳定关键点的个数,其中,M代表所述相应图像的边长;
步骤S42:选择所述相应图像中的稳定关键点的最密集的前N个区域,其中,N取整数。
本发明使用高斯差分算子寻找稳定关键点并确定特征提取区域,减少了传统使用HOG特征提取时对整幅图像进行滑窗扫描操作,既节省了时间,又提高了效率。
所述步骤S5具体包括:
步骤S51:将所述相应图像中所述前N个区域的每一块区域视为一个图像,进行灰度化;
步骤S52:采用Gamma校正法对灰度化后的每一块区域对应的每一个图像进行颜色空间的归一化,这样,可以调节所述每一个图像的对比度,降低所述每一个图像局部的阴影和光照变化所造成的影响,同时抑制噪音的干扰。
步骤S53:将归一化后的所述每一个图像划分为单元格,每2×2个像素点组成一个单元格;
步骤S54:计算所述每一个图像中每个像素点(x,y)的梯度,捕获轮廓信息,其中,所述梯度包括大小和方向:
Gx(x,y)=H(x+1,y)-H(x-1,y)
Gy(x,y)=H(x,y+1)-H(x,y-1)
Gx(x,y),Gy(x,y),H(x,y)分别代表所述像素点(x,y)处的水平方向梯度、垂直方向梯度和像素值。
所述像素点(x,y)处的梯度幅值和梯度方向分别为:
梯度方向分为有符号(0-360)和无符号(0-180)两种形式,本装置采用的是无符号的形式,并将(0-180)分成9等分,所以,所述每一个图像中每个所述单元格的梯度方向都分成9个方向块,使用所述单元格中的梯度方向和大小对9个方向块进行加权投影,最后,每个所述单元格产生9维的特征。
步骤S55:将每2×2个所述单元格组成一个块,一个块内所有单元格的所述特征串联起来后归一化,便得到该块的HOG特征;
步骤S56:将所述每一个图像中的所有块的HOG特征串联起来就得到所述每一个图像的HOG特征;
步骤S57:将所述每一个图像的HOG特征进行归一化,所述归一化的过程为:对所述HOG特征提取后的特征向量v进行特征变换,如下式:
v←v/255
式中,v为特征向量,ε为常数。
本发明使用HOG特征可以让图像局部像素点之间的关系得到很好的表征,除此之外,位置和方向空间的量化在一定程度上抑制了平移和旋转带来的影响。
所述步骤S6具体包括:
步骤S61:将所述训练集图像中的所有图像的HOG特征用矩阵集合统一表示;
步骤S62:根据应用需求在所述矩阵集合中确定聚类中心数值n;
步骤S63:对所述训练集图像的矩阵集合进行K-Means均值聚类计算,得到的n个聚类中心即为视觉词袋的n个视觉单词。
所述步骤S8具体包括:
步骤S81:利用欧式距离法计算所述测试图像的每个HOG特征与所述视觉词袋中每个视觉单词的相似度,将所述测试图像中的所述HOG特征用所述视觉词袋中相似度最高的视觉单词近似代替。欧氏距离为:
其中,Ha,Hb分别为所述测试图像中的一个HOG特征向量和所述视觉词袋中的一个视觉单词向量,i表示所述测试图像的HOG特征的维数。
步骤S82:统计所述测试图像中找到的所有视觉单词出现的频率,得到的频率直方图(n维)即为所述测试图像的视觉词袋。
本发明使用视觉词袋模型,相对基于文本的相似图像搜索,更好地避免了语义鸿沟问题。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员,在不脱离本发明方法的前提下,还可以做出若干改进和补充,这些改进和补充也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!