基于MapReduce的语义推理方法及系统与流程
本发明涉及计算机推理优化技术领域,尤其涉及一种基于MapReduce的语义推理方法及系统。
背景技术:
RDF用主语S(Subject)、谓语P(Project)、宾语O(Object)的三元组<S,P,O>形式描述Web上的资源。其中主语一般用统一资源标识符URI(Uniform Resource Identifier)表示Web上的信息实体(或者概念),谓语描述实体所具有的相关属性,宾语是对应的属性值。
例如:
<http://example.org/book/book1>,<http://purl.org/dc/elements/1.1/title>,"SPA RQL Tutorial">表示图书book1的题目是《SPARQL Tutorial》。这种表述方式使得RDF可以用来表示Web上的任何被标识的信息,并且使它可以在应用程序之间进行信息交换而不丧失语义信息。
RDFS(RDF Schema)扩展了RDF词汇表,通过建模原语定义被描述的资源的类以及资源的属性,并对类和属性进行约束。RDFS在RDF基础上定义了建模原语,如主要的类有:rdfs:Class和rdfs:Resourse;主要属性有rdfs:subPropertyOf和rdfs:subClassOf;表示属性限制的有rdfs:domain、rdfs:range和rdfs:ConstraintProperty等。RDFS描述的数据之间的关系主要有类与实例、子类和类结构、属性、子属性与属性层次和属性限制。
区分RDF和RDFS的一个方式为推理出新三元组的能力,RDFS三元组可以根据对应的RDFS规则集得出新的RDF三元组,挖掘出Web资源隐含的关系。在基于RDFS规则推理时,RDF三元组通常称为实例三元组,RDFS三元组称为模式三元组。
随着语义Web的快速发展,各领域RDF(Resource Description Framework)语义数据急剧增加,由于传统语义推理的工具都是运行于单机环境中,计算性能和可扩展性方面都存在不足,基于RDFS规则推理的时间一直有待提高。
目前,通过MapReduce对语义推理优化的方法中,Urbani等人将RDFS规则分类,并且根据RDFS规则间的依赖关系确定了规则的执行顺序,在RDFS规则依赖图的指导下,将原来需要多次迭代才能完成的推理简化为只需4次MapReduce作业,即将推理过程分为四次迭代完成,每次迭代作业的创建以及数据传输占据了推理过程中大部分时间,计算性能较低,仍需进一步改进。
技术实现要素:
本发明目的在于公开一种基于MapReduce的语义推理方法及系统,以使推理在一个MapReduce作业内完成,缩减推理的时间。
为实现上述目的,本发明公开了一种基于MapReduce的语义推理方法,包括:
构建实例三元组及谓语中含有rdfs:domain,rdfs:range,rdfs:subPropertyOf或rdfs:subClassOf的模式三元组;
将RDFS规则分类,根据RDFS规则分类构建模式三元组的规则模型subP、subC及domR;其中,domR基于谓语中含有rdfs:domain,rdfs:range的模式三元组构建,subP规则模型基于谓语中含有rdfs:subProperyOf的模式三元组构建,subC规则模型基于谓语中含有rdfs:subClassOf的模式三元组构建;
根据subP、domR和subC规则模型的依赖关系,确定规则模型在MapReduce框架中的应用顺序为:subP->domR->subC;
按照subP->domR->subC规则模型非循环的应用顺序,在map函数中分析读入的实例三元组,实现RDFS规则推理;
先后通过本地的Combiner阶段和全局Reduce阶段消除推理过程中产生的重复数据。
为达上述目的,本发明还公开一种基于MapReduce的语义推理系统,包括:
三元组构建模块,用于构建实例三元组及谓语中含有rdfs:domain,rdfs:range,rdfs:subPropertyOf或rdfs:subClassOf的模式三元组;
规则模型分类构建模块,用于将RDFS规则分类,根据RDFS规则分类构建模式三元组的规则模型subP、subC及domR;其中,domR基于谓语中含有rdfs:domain,rdfs:range的模式三元组构建,subP规则模型基于谓语中含有rdfs:subProperyOf的模式三元组构建,subC规则模型基于谓语中含有rdfs:subClassOf的模式三元组构建;
规则模型应用顺序确定模块,用于根据subP、domR和subC规则模型的依赖关系,确定规则模型在MapReduce框架中的应用顺序为:subP->domR->subC;
推理执行模块,用于按照subP->domR->subC规则模型非循环的应用顺序,在map函数中分析读入的实例三元组,实现RDFS规则推理;
消重模块,用于先后通过本地的Combiner阶段和全局Reduce阶段消除推理过程中产生的重复数据。
本发明具有以下有益效果:
采用本发明优化后的推理方案,使推理在一个MapReduce作业内完成,缩减了推理的时间。在对不同规模大小的数据集进行推理实验,发现平均推理时间仅为Urbani推理时间的1/3。而且,该方案在效率、稳定性和可扩展性上均有显著提升。
下面将参照附图,对本发明作进一步详细的说明。
附图说明
构成本申请的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是本发明实施例公开的基于MapReduce的语义推理方法总体流程图;
图2是本发明实施例公开的图domR规则模型;
图3是本发明实施例公开的图4基于domR规则模型推理;
图4是本发明实施例公开的subP规则模型;
图5是本发明实施例公开的基于subP规则模型推理;
图6是本发明实施例公开的subC规则模型;
图7是本发明实施例公开的基于subC规则模型推理;
图8是本发明实施例公开的推理规则模型依赖图;
图9是本发明实施例公开的规则推理算法;
图10是本发明实施例公开的对比实验中平均推理时间增长曲线图。
具体实施方式
以下结合附图对本发明的实施例进行详细说明,但是本发明可以由权利要求限定和覆盖的多种不同方式实施。为便于本发明技术的充分公开,在详细阐述本发明实施例前,对本发明实施例所用的部分概念定义如下:
模式三元组,指谓语中含有rdfs:domain,rdfs:range,rdfs:subPropertyOf或rdfs:subClassOf的RDF三元组。
实例三元组,指RDF三元组数据中去除模式三元组后的RDF三元组。
subP,表示谓语为rdfs:subPropertyOf的模式三元组推理的规则模型,模型中节点代表主语和宾语,有向边代表主语和宾语之间的subProperty关联。
subC,表示谓语为rdfs:subClassOf的模式三元组推理的规则模型,模型中节点代表主语和宾语,有向边代表主语和宾语之间的subClass关联。
domR,表示谓语为rdfs:domain或rdfs:range的模式三元组推理的规则模型,模型中节点代表主语和宾语,有向边代表主语和宾语之间的domain或range关联。
可达性,指在推理规则模型中的节点间通过有向边可达。
实施例1
本实施例公开一种基于MapReduce的语义推理方法,如图1所示,包括下述步骤。
步骤S1、构建实例三元组及谓语中含有rdfs:domain,rdfs:range,rdfs:subPropertyOf或rdfs:subClassOf的模式三元组。
步骤S2、将RDFS规则分类,根据RDFS规则分类构建模式三元组的规则模型subP、subC及domR;其中,domR基于谓语中含有rdfs:domain,rdfs:range的模式三元组构建,subP规则模型基于谓语中含有rdfs:subProperyOf的模式三元组构建,subC规则模型基于谓语中含有rdfs:subClassOf的模式三元组构建。
如表1所示为RDFS规则,其中规则2和3是根据RDFS中属性的限制domain和range进行推理,规则5和7根据子属性与属性的层次关系subProperty推理,规则9和规则11根据子类和类的结构subClass推理。
表1:
规则1、4、6、8和10中只有一个条件语句,不会对推理算法产生影响;规则12和13在RDF三元组数据中应用频率很低,不具有代表性。因此本实施例根据表2中规则设计推理算法。
表2:
本实施例将表2中规则分为三类,分别是:(1)基于rdfs:domain或rdfs:range推理,对应规则2和3;(2)基于rdfs:subProperyOf推理,对应规则5和7;(3)基于rdfs:subClassOf推理,对应规则9和11。相应地,将模式三元组划分为三类,分别构建规则模型domR、subP和subC。
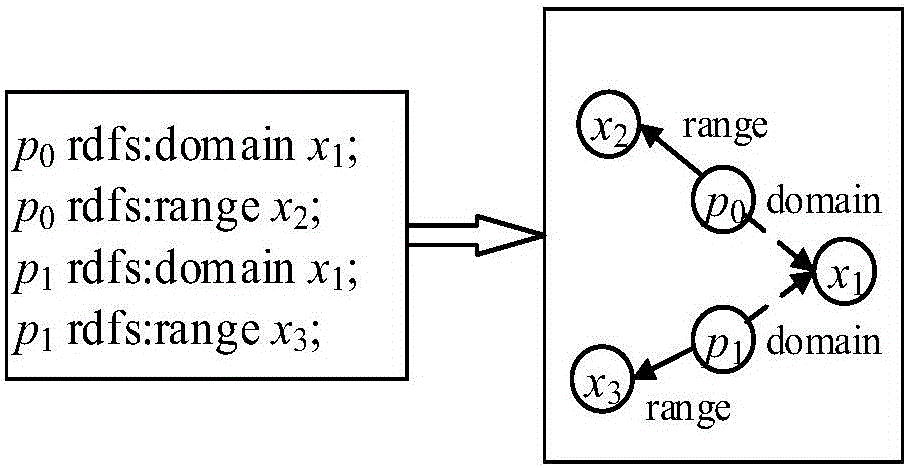
(一)、domR规则模型的构建。domR规则模型基于谓语中含有dfs:domain或rdfs:range的模式三元组构建,如图2所示。domR模型中节点代表模式三元组中主语或宾语,有向边代表谓语,表示节点之间有domain或range关联。
基于domR规则模型的推理。结合domR规则模型和规则2、3可得,如果实例三元组中谓语部分有domain属性,则推理出的新三元组中主语部分不变,谓语为rdf:type,宾语为原三元组谓语的domain属性值;如果实例三元组中谓语部分有range属性,则推理出的新三元组主语为原三元组宾语,谓语为rdf:type,宾语为原三元组谓语的range属性值。如图3所示,给定实例三元组<s0,p0,o0>和<s1,p1,o1>,基于domR规则模型,p0的domain属性值为x1,range属性值为x2,因此根据<s0,p0,o0>推理出新三元组分别为<s0,rdf:type,x1>和<o0,rdf:type,x2>;同理,p1的domain属性值为x1,range属性值为x3,因此根据<s1,p1,o1>推理出新三元组分别为<s1,rdf:type,x1>和<o1,rdf:type,x3>。
(二)、subP规则模型的构建。subP规则模型基于谓语中含有rdfs:subProperyOf的模式三元组构建,如图4所示。subP规则模型中节点代表模式三元组中的主语或宾语,有向边代表谓语,表示节点之间有subProperty关联。
基于subP规则模型的推理。结合subP规则模型和规则5、7可得,如果实例三元组中谓语有subProperty属性,则推理出的新三元组的主语和宾语部分不变,谓语为原三元组谓语的subProperty属性值。由subP模型可知,subProperty属性具有传递性,所以新三元组中的谓语可以由原三元组谓语在subProperty属性上可达的任意一个值代替。如图5所示,给定实例三元组<s0,p0,o0>,基于subP规则模型,p0可达的有p1、p2和p3,因此推理出新的三元组分别为<s0,p1,o0>、<s0,p2,o0>和<s0,p3,o0>。
(三)、subC规则模型的构建。subC规则模型基于谓语中含有rdfs:subClassOf的模式三元组构建,如图6所示。subC规则模型中节点代表模式三元组中的主语或宾语,有向边代表谓语,表示节点之间有subClass关联。
基于subC规则模型的推理。结合subC规则模型和规则9、11可得,如果实例三元组中谓语为rdf:type,并且宾语部分有subClass属性,则推理出的新三元组的主语和谓语部分不变,宾语为原三元组宾语的subClass属性值。由subC模型可知,与subProperty相同,subClass属性也具有传递性,所以新三元组中的宾语可以由原三元组宾语在subClass属性上可达的任意一个值代替。如图7所示,给定实例三元组<s0,rdf:type,o0>,基于subC规则模型,o0可达的o1、o2、o3和o4,因此推理出新三元组分别为<s0,rdf:type,o1>、<s0,rdf:type,o2>、<s0,rdf:type,o3>和<s0,rdf:type,o4>。
步骤S3、根据subP、domR和subC规则模型的依赖关系,确定规则模型在MapReduce框架中的应用顺序为:subP->domR->subC。
RDFS规则间存在依赖关系,如应用表2中规则7推理后的输出结果可以作为规则2和3的输入数据,引发规则2和规则3的执行,同理,domR、subP和subC规则模型间也存在依赖关系。为保证推理结果的正确性和全面性,需要确定在MapReduce框架中推理时各类规则模型的应用顺序。
首先从各类规则模型的输入数据分析。由图3和图5知,domR规则模型和subP规则模型的输入数据为普通的实例三元组,对主语、谓语和宾语部分并没有特殊限制。根据图7得,subC规则模型的输入数据限定实例三元组的谓语部分必须是rdf:type,而对主语和宾语没有限制。
分析各类规则模型的输出数据。由图3和图7知,domR规则模型和subC规则模型输出数据的谓语部分统一为rdf:type,主语和宾语和原实例三元组一致。根据图5得,subP模型输出数据为普通的实例三元组。
根据以上对各规则模型输入输出数据的分析,得出domR、subP和sucC规则模型间的依赖关系如图8所示;藉此,根据subP、domR和subC规则模型的依赖关系,确定规则模型在MapReduce框架中的应用顺序为:subP->domR->subC,从而使得本实施例对每条规则只应用一次即可推导出所有的隐含数据,推理过程不需要多次迭代,从而简化推理的复杂度,缩减推理的时间。
步骤S4、按照subP->domR->subC规则模型非循环的应用顺序,在map函数中分析读入的实例三元组,实现RDFS规则推理。
在该步骤中,Map阶段根据实例三元组和规则模型实现RDFS规则推理。根据模式三元组构建subP、domR和subC模型后,Map端从实例数据文件中读取实例三元组,并使用<s,p,o>三元组作为key,以便后续消除推理过程中产生的重复数据。可选的,本实施例采用的规则推理算法如图9所示,具体包括:
算法第3-4行对实例三元组按照subP->domR->subC顺序依次应用规则模型。
第5行在规则模型中查找原三元组的谓语或宾语,如果查找成功,应用推理规则模型进行推理。例如在subP规则模型中,查找是否包含原三元组的谓语,如果查找成功,从规则模型中找到谓语可达的节点集Q,依次用Q中节点q代替原三元组的谓语得到新三元组。在domR规则模型中,如果原三元组的谓语存在,并且有domain关联的节点x可达,则保持原三元组中的主语不变,谓语和宾语分别变为rdf:tye和x,形成新的三元组;如果谓语有range关联的节点x可达,则原三元组的宾语作为主语,谓语和宾语分别为rdf:type和x,形成新三元组。在subC规则模型中,查找是否包含原三元组的宾语,如果查找成功,从规则模型中找到宾语可达的节点集Q,依次用Q中节点q代替原三元组的宾语得到新三元组。
第13行从S中去除原三元组,只保存推理出的新三元组。
第14行遍历S,将S中推理后的所有三元组设为map函数中的key值,以便后续消除推理中产生的重复数据。
综上,如算法1所示,按照subP->domR->subC规则模型的应用顺序,在map函数中分析并遍历完所有的实例三元组,应用匹配的推理规则模型,最后输出推理后全部RDF三元组。
步骤S5、先后通过本地的Combiner阶段和全局Reduce阶段消除推理过程中产生的重复数据。
在本实施例中,推理过程中产生重复数据的类型主要有两种:(1)推理出的新三元组与原实例三元组重复;(2)推理出的新三元组数据之间存在重复。
由于Hadoop在Map端处理数据的形式为<key,value>键值对,经过map函数处理后,自动地将Map阶段输出数据按照相同键值key合并,所以本实施例将实例三元组设置为key值,经过本地的Combiner阶段和全局Reduce阶段合并处理后消除推理过程中产生的重复数据。本地数据消重处理。Combiner对Map端作业的输出进行合并,实现本地数据按照key值聚合,减少了Map端与Reduce端之间的数据传输。全局数据消重处理。Combiner的输出作为Reduce端的输入,经过reduce函数处理后,对多个节点数据按照key值合并,实现对推理后的所有三元组数据消重处理。
本实施例上述的方法可应用于采用由至少两个节点组成的云环境进行语义并行推理,将模式三元组数据作为全局数据,复制到各节点的内存中;将实例三元组数据进行数据划分,分解成与节点数量相对应的多个可同时并行执行的推理任务,以分布式方式存储在不同的节点,保证各节点之间的负载均衡。例如,本领域技术人员可以采用下述环境对本实施例的上述方法进行实验:
本实验采用Hadoop-2.5.2作为运行平台,并选用四台PC机(具体配置为:Intel(R)Core(TM)i5-3470CPU 3.20GHz 4GB内存和400GB硬盘空间)搭建Hadoop集群环境,其中1台主机为Master,负责数据的管理和作业的调度,3台主机为Slave,在Master的调度下负责数据的存储和任务的执行。
在Master节点上,将RDF实例三元组文件上传到HDFS上,并将模式三元组文件加载到内存中,推理过程中job提交后,Master节点负责将实例三元组文件切分为数据块并分配到各个Slave节点上,并将模式三元组文件加载到Slave节点的内存中,最后对Slave中执行的任务进行调度。
实验利用利哈伊大学开发的Lehigh University Benchmark(LUBM)的OWL知识库标准测试数集,分别对10、50、100、300、以及500所大学的RDF数据集进行了测试。
在相同的实验环境下,分别对本实施例优化后的RDFS推理算法和Urbani[13]提出的算法在各个LUBM数据集下进行测试。推理前和推理后数据集对应的三元组数目如表3所示。
表3:
(1)推理结果数据量的准确性分析。由表3得,在各个数据集下,本实施例方法和Urbani方法推理后的三元组数量相同,表明本实施例方法在数据量方面具备准确性。
(2)不同大小的LUBM数据集下推理前后三元组数量对比分析。在各个数据集下,推理前后的三元组数量都保持着一定的比例。为保证推理时间的准确性,本实验在不同LUBM数据集下分别测试5次,最后取得平均值作为最终结果。实验数据如表4所示:
表4:
由表4知,在相同的LUBM测试数据集下,本实施例方法比Urbani方法在推理时间上快4倍左右,实验数据表明本实施例方法在推理效率上优于Urbani方法。而且,由表4所示,当测试数据集扩大了50倍时,本实施例方法和Urbani方法推理时间分别增长了18倍和25倍,表明本实施例方法在扩展性方面更有优势。进一步的,推理时间随LUBM数据集增大而增长的对比情况如图10所示,随着测试数据集规模的不断扩大,两个方法的平均推理时间都并没有呈现指数增长趋势,而是平缓上升,但是本实施例方法推理时间增长的趋势比Urbani方法缓慢,表明本实施例方法更稳定。
综合以上分析,本实施例推理算法在推理效率、稳定性及可扩展性方面都取得了较好的结果,所以能够更好地支持海量RDF数据的推理。藉此,本实施例技术方案优化了MapReduce框架中基于RDFS规则的推理方法。首先将RDFS规则分类,将模式三元组按照RDFS规则分类构建对应的推理规则模型;然后根据规则模型间依赖关系确定在MapReduce框架中规则模型的应用顺序;算法中依次应用subP、domR和subC规则模型完成推理,最后在Combine阶段和Reduce阶段消除推理过程中的重复数据,使推理在一个MapReduce作业内完成;而且在对不同规模大小的数据集进行推理实验,发现平均推理时间仅为Urbani推理时间的1/3。
实施例2
与上述方法实施例相对应的,本发明实施例还公开一种基于MapReduce的语义推理系统,包括:
三元组构建模块,用于构建实例三元组及谓语中含有rdfs:domain,rdfs:range,rdfs:subPropertyOf或rdfs:subClassOf的模式三元组;
规则模型分类构建模块,用于将RDFS规则分类,根据RDFS规则分类构建模式三元组的规则模型subP、subC及domR;其中,domR基于谓语中含有rdfs:domain,rdfs:range的模式三元组构建,subP规则模型基于谓语中含有rdfs:subProperyOf的模式三元组构建,subC规则模型基于谓语中含有rdfs:subClassOf的模式三元组构建;
规则模型应用顺序确定模块,用于根据subP、domR和subC规则模型的依赖关系,确定规则模型在MapReduce框架中的应用顺序为:subP->domR->subC;
推理执行模块,用于按照subP->domR->subC规则模型非循环的应用顺序,在map函数中分析读入的实例三元组,实现RDFS规则推理;
消重模块,用于先后通过本地的Combiner阶段和全局Reduce阶段消除推理过程中产生的重复数据。
上述系统中,可选的,所述在map函数中分析读入的实例三元组,实现RDFS规则推理包括:Map端从实例数据文件中读取实例三元组,并使用<s,p,o>三元组作为map函数的key;在规则模型中查找实例三元组的谓语或宾语,如果查找成功,应用规则模型进行推理;在domR规则模型中,如果原三元组的谓语存在,并且有domain关联的节点x可达,则保持原三元组中的主语不变,谓语和宾语分别变为rdf:tye和x,形成新的三元组;如果谓语有range关联的节点x可达,则原三元组的宾语作为主语,谓语和宾语分别为rdf:type和x,形成新三元组;在subC规则模型中,查找是否包含原三元组的宾语,如果查找成功,从规则模型中找到宾语可达的节点集Q,依次用Q中节点q代替原三元组的宾语得到新三元组;直至遍历完所有的实例三元组。
优选的,本实施例系统所公开的语义推理系统可采用由至少两个节点组成的云环境进行语义并行推理,并将模式三元组数据作为全局数据,复制到各节点的内存中;以及将实例三元组数据进行数据划分,分解成与节点数量相对应的多个可同时并行执行的推理任务,以分布式方式存储在不同的节点。
采用本系统优化后的推理方案,使推理在一个MapReduce作业内完成,缩减了推理的时间。在对不同规模大小的数据集进行推理实验,发现平均推理时间仅为Urbani推理时间的1/3。而且,该方案在效率、稳定性和可扩展性上均有显著提升。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!