一种风电功率爬坡预测方法与流程
本发明涉及风电功率爬坡预测方法,尤其涉及一种基于原子稀疏分解和径向基神经网络的风电功率爬坡预测方法。
背景技术:
近年来,全球都面临着能源危机和自然环境水平持续下降等多方面压力,如何进行能源资源结构的调整与优化,高效的开发与利用可再生能源,已经成为世界各国能源发展战略工作的关键组成部分。其中,在可再生能源发电技术中,具有资源广泛、绿色无污染等特点的风力发电,已经成为发展水平相对成熟且装机容量较大的新能源发电技术。
同时,随着大规模高集中度风电场的发展,风电输出功率的区域性波动现象也越来越严重,不仅表现在风电功率具有不确定性,会出现速度快幅度大的爬坡现象,影响短期电网中电源与负荷之间的平衡性,而且使得风电场有功功率出力特征分析难度加大,风电功率预测精度难以提升,因此,对风电功率爬坡预测的研究已经成为越来越重要的研究领域。
技术实现要素:
本发明的目的是提供一种风电功率爬坡预测方法,进行风电功率爬坡量的预测,提高预测精度。
本发明为解决其技术问题所采用的技术方案是,
一种风电功率爬坡预测方法,其特征在于,包括以下步骤:
(1)将风电功率爬坡量进行稀疏分解;
(2)将分解后得到的原子分量进行自预测,将残差分量进行径向基神经网络预测;
(3)将各预测分量进行线性相加得到下一时刻的预测值。
步骤(1)中,将风电功率爬坡量的历史时间序列作为预测模型的输入,通过稀疏分解方法进行数据的稀疏分解:
将爬坡量时间序列表示成原子的稀疏线性组合,其一般表达式为
式中,ck是稀疏系数,为原始信号的一个逼近信号,将信号f近似地表示为M个原子的线性组合,
构造过完备字典:
通过选定Gabor原子库,取生成函数g(t)为高斯函数
再通过对生成函数的平移、伸缩等离散化处理,生成原子,从而得到过完备字典集;
原子稀疏算法采用正交匹配追踪算法,对每步分解的全部原子进行正交化处理,步骤如下:
1)先从过完备原子库中选取最为匹配的一个原子,即满足
假设R0=f,信号f分解为如下形式:
其中,表示R0对的投影,即为找出的原子库中第一个最为匹配信号的原子,R1为第一次信号分解后得到的残差,与R1是正交的,得到
选择近似最佳的原子使得
其中,0<α≤1,
取α=1,
接下来对残差R1进行相同的步骤进行运算,得到
满足
对待分解信号依次进行分解后,经过这样的m+1次迭代后就能够得到
其中满足
假设最为匹配的原子为对其进行施密特正交化的处理:
残差RM在um上投影,即:
从而,信号f的表示形式变为:
则对于待分解信号f完成了OMP算法的稀疏分解。
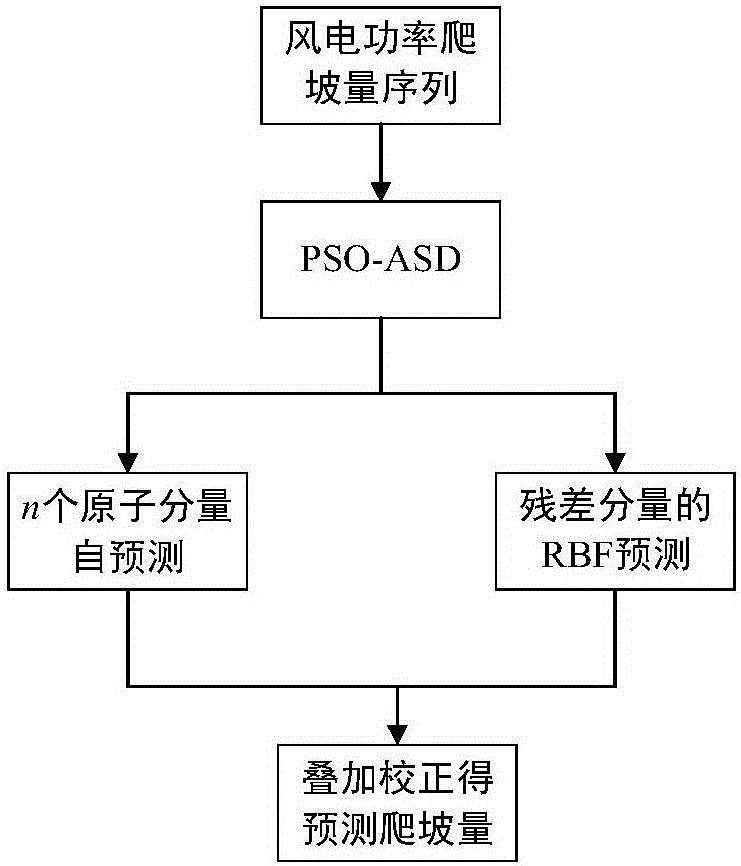
步骤(2)中:在已选出原子的基础上,将分解后的得到的n个原子分量,进行原子分量表达式的自预测,剩余的一个残差分量作为径向基网络的输入,进行模型的训练,从而预测出残差分量对应的下一时刻的预测值。
步骤(3)中:通过步骤(2)中预测的n+1个预测分量,将这些分量进行线性回归叠加和修正,即为预测的下一时刻的风电功率爬坡量的预测值。
本发明的优点在于,该方法采用基于稀疏分解法和径向基神经网络相结合的滑动预测方法进行风电功率爬坡量的预测,建立了风电功率爬坡事件的预测模型,从而进行风电功率爬坡量的预测,提高预测精度。
附图说明
图1是本发明提出的预测方法的算法流程图;
图2是该方法的预测模型流程图;
图3是实测功率曲线和爬坡量示意图;
图4是预测功率爬坡量曲线。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合图示与具体实施例,进一步阐述本发明。
如图1、图2所示,本发明提出的预测方法其具体内容为:(1)将风电功率爬坡量的历史时间序列作为预测模型的输入,通过稀疏分解方法进行数据的稀疏分解。稀疏分解理论主要包括2大部分——过完备原子库;稀疏分解算法。将爬坡量时间序列表示成原子的稀疏线性组合,其一般表达式为:
式中,ck是稀疏系数,为原始信号的一个逼近信号,将信号f近似地表示为M个原子的线性组合
本发明构造过完备字典是通过选定Gabor原子库,取生成函数g(t)为高斯函数:
再通过对生成函数的平移、伸缩等离散化处理,生成原子,从而得到过完备字典集。
(2)原子稀疏算法采用正交匹配追踪算法(Orthogonal Matching Pursuit,OMP)算法,对每步分解的全部原子进行正交化处理,不仅满足精度要求而且收敛速度更快。步骤如下:
1)先从过完备原子库中选取最为匹配的一个原子,即满足
假设R0=f,这样信号f可以分解为如下形式:
其中,表示R0对的投影,即为找出的原子库中第一个最为匹配信号的原子,R1为第一次信号分解后得到的残差。不难看出,与R1是正交的,于是可以得到:
为了使得逼近误差R1的能量最小,就需要选择使得最大的在无穷维数当中,通常情况下是找不到的极值的,只可能在某种意义上择优选择近似最佳的原子使得
其中,α被称作是优化因子,满足条件0<α≤1。
而在有限维的情况下,|<R,gγ>|是存在最大值的。因此,在有限维的情况下使用的时候,通常取α=1。
接下来对残差R1进行相同的步骤进行运算,得到
满足
对待分解信号依次进行分解后,经过这样的m+1次迭代后就能够得到
其中满足:
OMP算法通过对迭代的每一步差值项的投影方向正交化,实现了对所选的全部原子进行正交化处理,相比于MP算法保证迭代的最优性,而且大大减少了迭代的次数从而收敛速度更快。
在OMP算法中,假设最为匹配的原子为对其进行施密特正交化的处理:
残差RM在um上投影,即:
从而,信号f的表示形式变为:
则对于待分解信号f完成了OMP算法的稀疏分解。
(3)在上述步骤已选出原子的基础上,将分解后的得到的n个原子分量,进行原子分量表达式的自预测,剩余的一个残差分量作为径向基网络的输入,进行模型的训练,从而预测出残差分量对应的下一时刻的预测值。
(4)通过步骤(3)中预测的n+1个预测分量,将这些分量进行线性回归叠加和修正,即为预测的下一时刻的风电功率爬坡量的预测值。
图3、图4为算例验证,图3为上海某风电场实际的500个数据的风电功率时间序列,和相对应的风电功率爬坡量的时间序列,通过本模型预测后50个样本点,即得到图4,并通过与常用的小波神经网络和单一径向基神经网络预测进行对比,通过误差计算可知,本发明中所述稀疏分解和径向基神经网络预测方法的误差最小,其均方根误差为11.09%,满足预测精度。
以上实施方式只为说明本发明的技术构思及特点,其目的在于让本领域的技术人员了解本发明的内容并加以实施,并不能以此限制本发明的保护范围,凡根据本发明精神实质所做的等效变化或修饰,都应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!