一种众包环境下的基于遗传算法的任务分配方法与流程
本发明涉及一种对众包平台上一个较复杂的任务的各子任务和竞标参与人进行分配的方法,特别涉及一种众包环境下的基于遗传算法的任务分配方法。
背景技术:
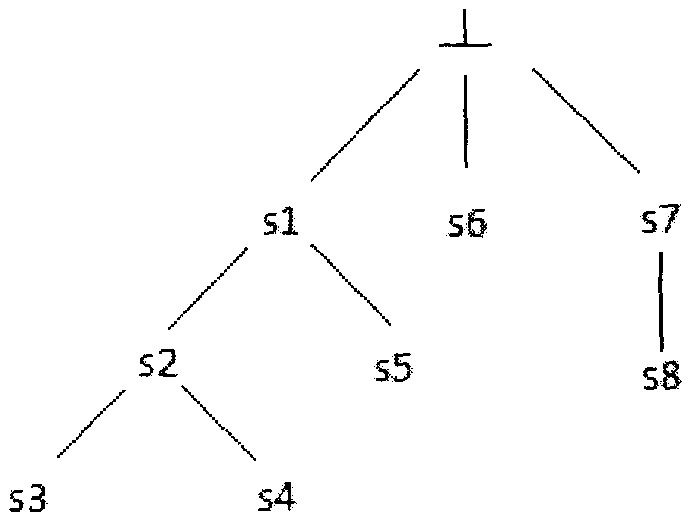
:近年来,众包得到了工业界和学术界的广泛关注。众包(crowdsourcing)这一概念是由美国《连线》杂志的记者杰夫·豪(JeffHowe)在2006年6月提出的.杰夫·豪对“众包”的定义是:“一个公司或机构把过去由员工执行的工作任务,以自由自愿的形式外包给非特定的(而且通常是大型的)公众网络的做法.众包的任务通常由个人来承担,但如果涉及到需要多人协作完成的任务,也有可能以依靠开源的个体生产的形式出现.”如今,众包平台已经证明了它支持多种软件开发活动如开发和测试的能力,可以看到几个成功的众包平台如TopCoder、uTest以及国内的猪八戒网。但是,对众包环境下的大规模且复杂的软件开发和测试任务来说,仍有几个优化问题需要解决。譬如,任务分工即搜寻一组合适的注册者以及对注册者的任务分配问题。在众包环境中,一个任务可能被分配给不同地区的不同专业背景的注册者,因此最终任务交付的质量是一个关键问题。作为提高质量的第一步,我们需要一个系统化和自动化的方法来优化注册者的任务分配,目的就是为不同的任务找到一组最合适的注册者。而现行的众包平台的任务分配方案往往是工人去自行搜索并选择想要参与的任务,然后由任务提交者或平台人工去分配,既费时费力,而且往往得不到较好的结果。一些仅有的众包平台下的任务分配方法也通常是只从任务的角度出发,仅仅关注于任务与工人之间的联系,而没有考虑到因工人与工人之间的相似度而影响的合作关系也是最终任务交付质量的影响因素之一。此外,现行的一些众包任务分配策略,通常要求工人技能和任务所需技能严格匹配,这常常导致因没有严格技能匹配的工人而分配失败。技术实现要素:本发明的目的就在于克服上述缺陷,研制一种众包环境下的基于遗传算法的任务分配方法。本发明的技术方案是:一种众包环境下的基于遗传算法的任务分配方法,其主要技术特征在于如下步骤:(1)接收一个任务提交者提交任务和分解后的的多个子任务,每个子任务分别包含如下特征:任务名称、任务所需技能和任务预算;(2)接收由众包平台提供的参与此任务竞标的工人信息,每个工人包含如下特征:工人所拥有的技能及其技能等级、工人信誉度、历史完成任务列表和该工人对各子任务预期的薪水;(3)在众包平台上挖掘该任务的竞标参与人的技能信息,构建各个参与人技能间关系的技能分层树;(4)结合步骤3所构建的技能分层树与各个工人所拥有的技能及其信誉度以及各子任务所需技能,得出各个工人所能提供给各子任务的价值;(5)结合步骤2所提供的参与工人信息的历史完成任务列表进行预处理并提取关键词信息,得到各个工人的关键词词库,再将各个工人的关键词词库进行比对,得出各个工人之间的相似度;(6)采用遗传算法求解任务分配方案,即各个子任务和多组工人间的对应关系;(7)由众包平台根据步骤6中得出的方案进行任务的分配。所述步骤(1)中所述的技能分层树,指的是一种树状结构,它的每个节点表示一种技能,如拥有技能s’的工人可近似执行需求技能s的任务,则s’为s的子节点。所述步骤4中的工人i能提供给子任务j的价值Valueij计算式如下:Valueij=maxs∈skill(i)(level(i,s)*(1-d(skill(j),s))d(s,s′)=0,if(s=s′)dmax-depth(lca(s,s′))dmax,otherwise]]>其中,skill(i)为工人i所拥有的技能列表,skill(j)为子任务j需求的技能,dmax为技能分层树的最大深度,lca(s,s’)为s和s’的最低共同祖先,depth(s)为s在这颗树中的深度,d(s,s’)为技能s距技能s’的距离,level(i,s)为工人i的技能s的技能等级。所述步骤(6)所诉的采用遗传算法求解任务分配方案的具体流程如下:(6.1).初始化种群;(6.2).计算种群的适应度值;(6.3).执行选择、交叉、变异等遗传操作,生成新一代种群;(6.4).判断是否满足结束条件:是,输出最优解:否,执行步骤(6.2)。所述步骤(6.1)所述的初始化种群是指对任务分配的解进行编码,其遗传编码用矩阵T(m×n)表示,Tij=1表示工人i被分配到任务j中去,Tij=0表示工人i没有被分配到任务j中去。所述步骤(6.2)所述的适应度值由适应度函数计算得出,适应度函数选取为:f(T)=Σj=1m(α×Jj(T)+β×Sj(T))]]>Jj(T)=Σj=1nTijValueij]]>Sj(T)=Σi=1nTijSimilarityij]]>Similarityij=Σk=1nTkjSimikΣk=1nTkj]]>其中,f(T)为适应度,Ji为任务j的目标函数,Sj为被分配到任务j的一组工人的总相似度,similarityij为工人i与被分配到任务j的一组工人的相似度,Simik为工人i与工人k之间的相似度,αβ为权重系数。本发明的优点和效果在于主要针对众包平台下的各种任务,将其分配给技能匹配且群组相似度较大的一组工人。在分配任务时,本发明不仅考虑了工人所拥有技能和任务所需技能的匹配程度,也考虑到了被分配到同一任务中的团队的历史完成任务相似度。本发明还考虑到,在知识密集型的软件开发中,任务所需技能与工人的技能不一定完全匹配,故采用一种技能分层树的方法使得工人与任务较好的匹配起来。本发明在满足任务所要求的预算的前提下,尽量分配最合适的一个团队到一个任务中去,这样不仅可以提升最终任务的交付质量,也能使工人在完成这项任务时能尽可能与自己开发经历一致的工人更好地协同合作。本发明的其它优点和效果还在于:(1)目前的众包平台大都是以工人竞标的形式来独自获得任务,本发明能够让任务自动匹配到一组技能匹配且群组相似度高的工人。从这组工人的历史完成任务中来获得该组工人的相似度。(2)在知识密集型的软件开发中,任务所需技能与工人的技能不一定完全匹配,故本发明采用一种技能分层树的方法使得工人与任务较好的匹配起来。(3)在满足任务预算的情况下,本发明不仅使得最终交付的质量越高越好,而且这组工人拥有类似的开发经历,从而团队协作的也越好。本发明的其它具体优点和效果将在下面继续说明。附图说明图1——本发明流程示意图。图2——本发明的技能分层树结构示意图。图3——本发明输出结果示意图。图4——本发明中工人历史完成任务列表示意图。图5——本发明中工人关键词词库示意图。具体实施方式下面结合实施例及附图进一步的叙述本发明:实施例:任务提交者提交的任务及参与的工人信息如表1、表2所示。表1任务数据:子任务名称123所需技能s2s2s4任务预算1008070表2工人信息(参与者):每位工人的历史完成任务列表如图4所示。一种众包环境下的基于遗传算法的任务分配方法(总体流程图如图1),其特征在于如下步骤:步骤1).接收一个任务提交者提交任务和分解后的的多个子任务,每个子任务分别包含如下特征:任务名称、任务所需技能和任务预算;如表1所示,读入任务的有关数据,包括任务名称、任务所需技能和任务预算。步骤2).接收由众包平台提供的参与此任务竞标的工人信息,每个工人包含如下特征:工人所拥有的技能及其技能等级、工人信誉度、历史完成任务列表和该工人对各子任务预期的薪水;如表2所示,读入工人的数据。步骤3).在众包平台上挖掘该任务的竞标参与人的技能信息,构建各个参与人技能间关系的技能分层树;此步骤在于构造一颗技能分层树,用以描述各个技能之间的匹配程度,在没有工人拥有与任务所需技能严格匹配的技能时,可以使用与之相近的技能去匹配这种任务,以防任务分配失败。具体构造方法为考虑任务所需的技能以及工人所拥有的技能,人为给定各个技能间的匹配关系,如拥有技能A的工人可近似完成需求技能B的任务,则A为B的子节点。在本例中,假设根据读入的工人信息和平台数据可构造一技能分层树如图2所示。该图表示本次分配中的各个技能间的匹配关系,如当没有人拥有技能s2时,可以考虑使用与之距离相近的技能s3去近似匹配这一技能。步骤4).结合步骤3所构建的技能分层树与各个工人所拥有的技能及其信誉度以及各子任务所需技能,得出各个工人所能提供给各子任务的价值;工人i能提供给子任务j的价值Valueij计算式如下:Valueij=maxs∈skill(i)(level(i,s)*(1-d(skill(j),s))d(s,s′)=0,if(s=s′)dmax-depth(lca(s,s′))dmax,otherwise]]>其中skill(i)为工人i所拥有的技能列表,skill(j)为子任务j需求的技能,dmax为技能分层树的最大深度,lca(s,s’)为s和s’的最低共同祖先,depth(s)为s在这颗树中的深度,d(s,s’)为技能s距技能s’的距离,level(i,s)为工人i的技能s的技能等级。以计算Value12为例,工人1所拥有的技能为s3和s6,任务2需求的技能为s2,dmax=3,则故level(1,s3)*(1-d(s3,s2))=0.6,level(1,s6)*(1-d(s6,s2))=0,Value12取最大值,故Value12=0.6.步骤5).结合步骤2所提供的参与工人信息的历史完成任务列表进行预处理并提取关键词信息,得到各个工人的关键词词库,再将各个工人的关键词词库进行比对,得出各个工人之间的相似度;假设工人的历史完成任务列表如图4所示,该图表示每位工人的之前已经完成的任务名称信息列表,可反映出每位工人的历史开发经验。经预处理和提取关键词信息后可得到如图5所示的工人关键词词库,该图表示的内容是更具体的每位工人的历史开发经验,以便于量化各工人间的相似程度。通过比对各工人的关键词词库即可求出各个工人之间的相似程度以备之后求解使用。此步骤的目的是为了之后能尽可能求解出一组相似程度较大的工人提供数据支持,而历史开发经历相似的一组工人显然可以更好的合作以完成任务。步骤6).采用遗传算法求解任务分配方案,即各个子任务和多组工人间的对应关系;步骤(6.1).初始化种群;采用矩阵T(m×n)表示编码,其中m为子任务个数,n为工人个数,Tij=1表示工人i被分配到任务j中去,Tij=0表示工人i没有被分配到任务j中去。设定种群数量为50,随机生成初始种群。步骤(6.2).计算种群的适应度值;适应度值由适应度函数计算得出,适应度函数选取为:f(T)=Σj=1m(α×Jj(T)+β×Sj(T))]]>Jj(T)=Σi=1nTijValueij]]>Sj(T)=Σi=1nTijSimilarityij]]>Similarityij=Σk=1nTkjSimikΣk=1nTkj]]>其中,f(T)为适应度,Ji为任务j的目标函数,Sj为被分配到任务j的一组工人的总相似度,similarityij为工人i与被分配到任务j的一组工人的相似度,Simik为工人i与工人k之间的相似度,αβ为权重系数。其中的权重系数可根据不同任务的需要取不同的值以满足不同任务的个性化需求。步骤(6.3).执行选择、交叉、变异等遗传操作,生成新一代种群;采用轮盘赌的方式对个体进行选择,每个个体的选择概率=个体适应值/全部个体适应值总和。对于交叉算子,取交叉概率为0.8,先随机产生一与个体编码结构一致的0/1矩阵P(m×n),对于两执行交叉操作的个体,如果Pij=1,则不进行对应位上的交叉操作;如果Pij=0,则交换对应位上的基因。对于变异算子,取变异概率0.1,对种群中的个体进行变异操作,即将其对应的基因取反。步骤(6.4).判断是否满足结束条件:是,输出最优解:否,执行步骤(6.2)迭代次数加1,同时判断是否达到了系统所定义的最大迭代次数,如果已经达到,执行步骤7,如果没有达到,执行步骤(6.2).步骤7).由众包平台根据步骤6中得出的方案进行任务的分配。最终结果应为最终种群中的适应度最高的个体,其形式应为一矩阵T(m×n),表示分配结果,假设最终结果T如图3所示,则与之对应的分配方案为:任务1:工人1任务2:工人2任务3:工人3、工人4最终的分配结果交由众包平台执行。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1