一种众包环境下复杂任务分配方法与流程
本发明涉及任务分配、激励机制领域,特别涉及一种众包环境下复杂任务分配方法。
背景技术:
众包就是拥有预算的请求者发布任务,请求以获得报酬为目的、有特定技能的工人来完成任务一种方式。现今,有很多众包平台,例如,amazonmechanicalturk(amtforshort)。在amt中,请求者发布hits(humanintelligencetasks)给在线的工人。但一般amt中只是发布微小奖励的微型任务,比如,社会科学实验、发布照片等等,而topcoder是针对软件开发所设计的大型众包平台。
在本发明作出之前,现有的众包平台中存在如下几个难点:
1)众包任务分配根据参与者的可达性,可分为离线和在线两种场景。在离线的情况下,分配刚开始,任务请求者/工人就同时提交报价/要价给平台,并且没有后续的实体。众包平台能够根据手上所有的信息决定分配结果。相反,在在线的情景下,一旦请求者/工人到达,报价/要价向量被顺序送达。在线的场景是比较复杂的情景,因为众包平台必须随时进行决策,并且没有接下来到达的参与者的信息,实现全局优化是比较难的。也就是说,相对于离线,在线情况更加复杂,却是现实生活中的实际的场景。但现阶段的众包平台任务分配算法大多考虑离线场景,存在很大的局限性。
2)在任务分配阶段,不仅有效的分配要考虑到,也要考虑参与者的质量。通过探索和收集质量信息,分配过程可以被优化。工人的质量意味着可依赖性,即完成工作的优劣程度,对于分配的结果是至关重要的。理性的任务请求者更想把任务交付给质量高的工人完成。为了防止恶意的请求者,请求者的质量也应该被考虑到。现存的众包平台只是单纯地考虑分配的结果,而没有将分配和参与者的质量结合起来。
3)第三个挑战是因为自私的参与者会通过谎报报价/要价来增加自己的效益。现在大部分的众包平台并没有考虑自私的参与者,没有考虑防策略(strategy-proof)机制来阻止慌报的发生。最终定价决策大多由工人所报的价格或者请求者所提供的价格决定。为了保证真实性,拍卖被应用在很多领域,例如协作通信、云资源供应以及众包平台。毫无疑问,拍卖是防止谎报的有效方式。现有的众包任务分配没有考虑参与者的策略性,使得一些欺诈者获利,加大了交易的不公平性。
技术实现要素:
本发明的目的就在于克服上述问题,研发一种众包环境下复杂任务分配方法。
本发明的技术方案为:
一种众包环境下复杂任务分配方法,其主要技术特征在于步骤如下:
(1)任务请求者提交任务完成所需的特定技能,以及完成这些技能的报价;
(2)工人提交拥有的技能以及每个技能的要价;
(3)众包平台作为拍卖者负责整个分配过程的运作,主要包括筛选参与者、决策阶段和更新质量三个阶段的工作。
所述的筛选参与者用于确定现阶段在线的参与者,在线的参与者包括上一阶段未被分配仍然在线的参与者,以及在这个时间槽新到的参与者;
所述的决策阶段包括如下步骤:
步骤1:对在线的任务请求者,综合考虑任务的紧急程度和质量情况进行排序。紧急程度越高、质量越高的任务请求者享有越高的分配优先权;
步骤2:根据任务请求者的分配优先权依次遍历任务请求者进行分配;对于任务请求者ri,ai存储对ri有技能贡献的工人。aj为在ai中单位技能单位质量拥有最小成本的工人。迭代选择aj,直到ai为空,或者ri的技能被完全覆盖。迭代完成时,若ri的技能被完全覆盖,ri被成功分配到某个团队;否则,任务请求者ri为输者;
步骤3:对于每个候选组员aj,迭代计算临界价格,即如果aj报价高于临界价格,aj就不能成功地被分配,临界价格为ai剩余工人中单位技能单位质量拥有的最大成本;
所述的更新质量阶段主要是应用学习算法来实现。
本发明的优点和效果在于平台在每个时间槽收集任务请求者和工人的信息,决定最终的分配结果,包括赢者,支付以及赢者之间的匹配关系。本发明考虑的主要是复杂任务,所以一个赢者任务请求者可能对应多个工人。
本发明采用拍卖的方式进行决策,其中任务请求者是买方,工人是卖方。本发明主要包括在线用户的筛选、赢者决策/定价策略、更新质量三个阶段,实现了任务请求者和工人之间的匹配,并决定了最终双方的支付。将参与者的质量考虑到拍卖中,使得拍卖的结果更加合理。除此以外,整个过程是一种防策略(strategy-proof)的分配机制,即双方即使谎报价格也不能提高他们的效用,也就是说,报出真实的价格是一个占优策略(dominantstrategy)。因此,拍卖的双方为了自身的利益,就不会再选择谎报。大部分现有的众包环境下任务分配未考虑买卖双方的策略性,存在参与者的欺诈行为。现有的众包平台一般将复杂任务分配给一个工人承担,但交给一个人承担复杂任务会降低任务完成的质量。本发明考虑到复杂任务交给一个工人完成的不合理性,将复杂任务分配给一个团队共同协作完成。
附图说明
图1——本发明机制组成结构示意图。
图2——本发明支付规则示意图。
图3——本发明更新质量示意图。
具体实施方式
本发明的技术思路是:
与实际情况相符,即考虑在线的场景,每个时间槽都要进行一次分配。在每个时间槽的开始阶段,很多任务请求者和工人到达平台。任务请求者提交他的报价向量,包括技能请求向量、完成任务给工人的报价、质量、到达时间和离开时间。其中质量信息是平台通过学习算法得到的,报价与任务完成后的估值不一定相等。工人提交他的要价向量,包括技能信息,以及每个技能的要价和质量、到达时间和离开时间。其中的质量也是平台通过学习算法得到的,每个技能的要价与工人的心里价位不一定相等。
下面具体说明本发明。
如图1所示,任务请求者提交任务完成所需的特定技能,以及完成这些技能的报价,任务请求者的质量情况是平台根据学习算法得到的,由于是在线,还包括了到达时间和离开时间;工人提交拥有的技能以及每个技能的要价,每个技能的质量情况同样也是平台通过学习算法得到的,同样,到达的工人会提交到达时间和离开时间;平台作为拍卖者负责整个分配过程的运作,决定赢者、赢者之间的匹配和支付,主要包括筛选参与者、决策阶段和更新质量三个阶段的工作。
筛选参与者用于确定现阶段在线的参与者。在线的参与者包括上一阶段未被分配仍然在线的参与者,以及在这个时间槽新到的参与者。主要是比较参与者的到达时间、离开时间和现阶段的时间槽,来判断该参与者是否还在线。时间槽表示一个时间段,如一小时、12小时、24小时。假设,现阶段时间槽为3,工人a1到达时间、离开时间向量为(1,7),且在时间槽1,2都未被分配,a1为在上一阶段未被分配仍然在线的工人;工人a2到达时间、离开时间槽为(3,5),a2为时间槽3新到的工人。
决策阶段包括赢者决策和定价策略,确定赢者和赢者之间的交易价格。包括如下步骤:
步骤1:对在线的任务请求者,综合考虑任务的紧急程度和质量情况进行排序。紧急程度越高、质量越高的任务请求者享有越高的分配优先权。紧急程度表示该任务请求者离开时间和现阶段的时间槽的差值,差值越小,意味着该任务越紧急。质量情况意味着该任务请求者的可信赖程度,由平台通过学习算法得出。如上述的a1和a2,在时间槽3时刻,a1的紧急情况为7-3=4,a2的紧急情况为5-3=2。a2相对于a1有更高的紧急情况;a1质量为8.9,a2的质量为7.8;根据实际情况,设置紧急情况和质量情况的调节参数,综合考虑紧急情况和质量情况,对任务请求者进行排序。
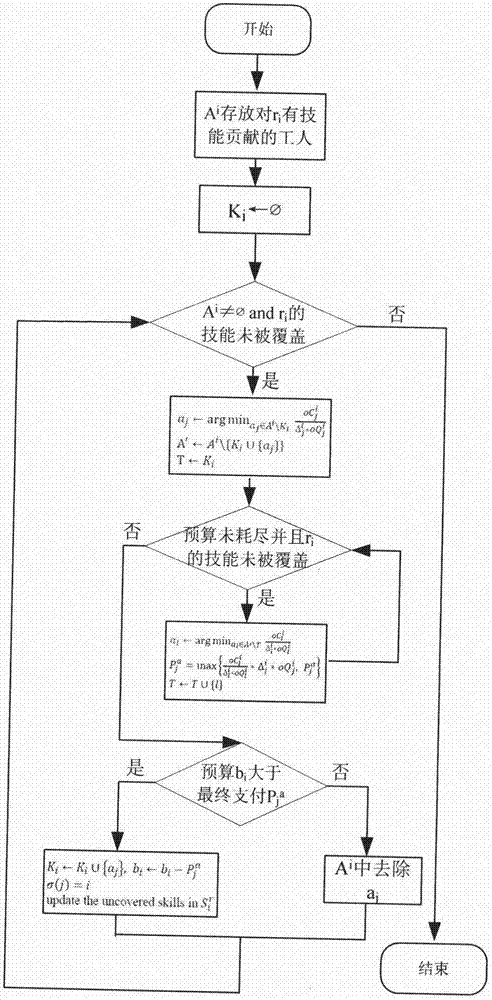
步骤2:根据任务请求者的分配优先权依次遍历任务请求者进行分配。每个任务请求者的决策阶段算法流程图如图2所示。
对于任务请求者ri,ai存储对ri有技能贡献的工人。置ki为空,用于存放完成ri任务的工人集。aj为在ai中单位技能单位质量拥有最小成本的工人,将aj作为ki团队组员的候选人。迭代选择aj,直到ai为空,或者ri的技能被完全覆盖。迭代完成时,若ri的技能被完全覆盖,任务请求者ri成功被分配到团队ki;否则,任务请求者ri为输者。
步骤3:对于每个候选组员aj进行如下操作:
计算工人aj加入到ki中,ri支付给aj的临界价格,即若aj报价高于临界价格,aj就不能成功地被分配。当aj未加入到ki中,选择al为ai\{ki∪{aj}}中单位技能单位质量拥有最小成本的工人,计算临界价格
更新质量主要是应用学习算法来实现。一旦任务被完成,赢的任务请求者和工人之间会相互评价。虽然涉及到学习算法,本发明的重点在于解决参与者的策略性问题,而不是在线学习。因此,我们不讨论学习算法,而采用现有的multi-armedbandits(mab)方法。本发明同时考虑任务请求者和工人的质量情况,主要在于众包中可能会存在恶意的任务请求者或者差评的工人,质量的更新能够改善任务分配的结果。如图3所示,根据质量历史库中的质量信息和任务完成后任务请求者和工人的相互评价,更新双方的质量信息,重新加入到质量历史库中,从而更新质量历史库。
- 还没有人留言评论。精彩留言会获得点赞!