基于矩阵加权关联模式的印尼汉跨语言检索方法及系统与流程
本发明属于文本信息检索领域,具体是一种基于矩阵加权关联模式的印尼汉跨语言检索方法及系统,适用于采用印尼语查询检索中文文档的跨语言文本信息检索等领域。
背景技术:
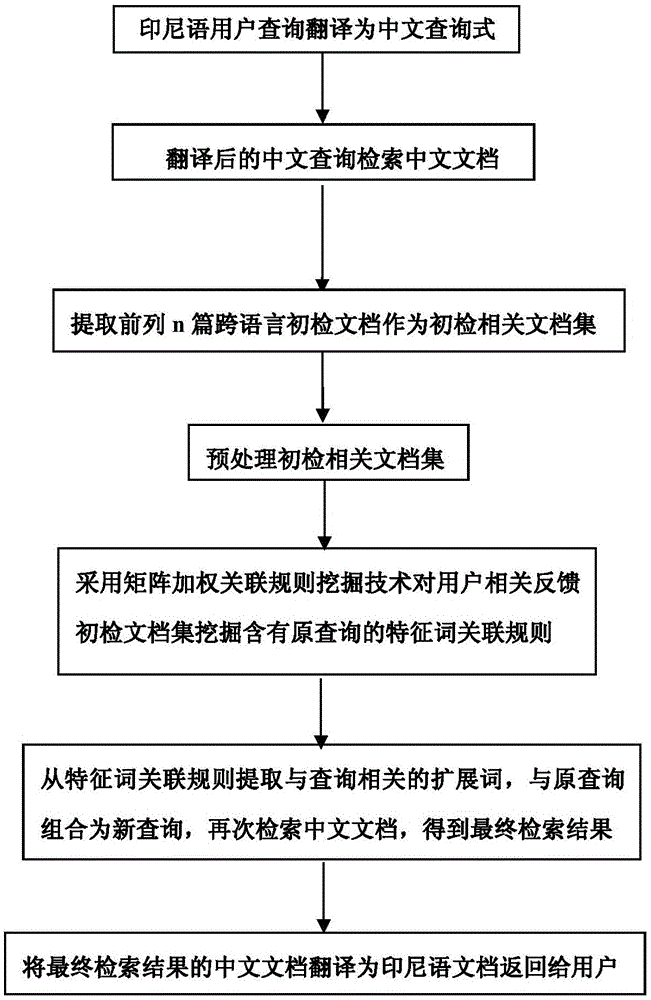
:跨语言信息检索指的是以一种语言的查询检索其他语言的信息资源的技术。印尼汉跨语言信息检索方法是用印尼语查询检索中文文档的跨语言检索问题,其中,表达查询的印尼语言称为源语言,所检索的文档的中文语言称为目标语言。随着中国和东盟国家交流越来越密切,面向东盟国家语言的跨语言信息检索方法研究显得迫切和重要。世界各地学者从不同的角度和方向对跨语言信息检索方法及系统进行了深入探讨和研究,取得了丰富的成果,然而,当前跨语言信息检索研究所存在的问题还没有完全解决,该领域亟待解决和关注度比较高的问题之一是跨语言信息检索过程中存在的严重查询主题漂移问题,面临着比单语言检索更为严重的词不匹配问题,这些问题常常导致跨语言检索性能低下,不如单语言检索性能。针对上述问题,近年来,基于查询扩展的跨语言信息检索研究得到了更多的关注和讨论,其研究主要集中在基于相关反馈的(PartonK,GaoJ.CombiningSignalsforCross-LingualRelevanceFeedback[C].Proceedingsof8thAsiaInformationRetrievalSocietiesConference(AIRS2012),Tianjin,China.Springer-VerlagBerlinHeidelberg2012,LNCS7675,InformationRetrievalTechnology.2012:356-365.LeeCJ,CroftWB.Cross-LanguagePseudo-RelevanceFeedbackTechniquesforInformalText[C].Proceedingsof36thEuropeanConferenceonIRResearch(ECIR2014),Amsterdam,TheNetherlands.AdvancesinInformationRetrieval.SpringerInternationalPublishing,2014:260-272.)、潜在语义的(闭剑婷,苏一丹.基于潜在语义分析的跨语言查询扩展方法[J].计算机工程,2009,35(10):49-53.宁健,林鸿飞.基于改进潜在语义分析的跨语言检索[J].中文信息学报,2010,24(3):105-111.)、语言模型的和主题模型的(GangulyDebasisandLevelingJohannesandJonesGarethJ.F.Cross-lingualtopicalrelevancemodels[C].In:24thInternationalConferenceonComputationalLinguistics(COLING2012),2012.;WangXuwen,ZhangQiang,WangXiaojie,etal.LDAbasedpseudorelevancefeedbackforcrosslanguageinformationretrieval[C].IEEEInternationalConferenceonCloudComputingandIntelligenceSystems(CCIS2012).Hangzhou:IEEE,2012:1993-1998.;XuwenWang,QiangZhang,XiaojieWang,etal.Cross-lingualPseudoRelevanceFeedbackBasedonWeakRelevantTopicAlignment.Proceedingsofthe29thPacificAsiaConferenceonLanguage,InformationandComputation,PACLIC29,Shanghai,China,2015:529-534.)等跨语言信息检索研究,其语言对象主要是以英语为主,大多都是研究英语和其他语言的跨语言检索问题。当前,中国南宁市作为中国-东盟博览会永久举办地以来,中国与东盟国家的政治、经济、文化等往来更加频繁和密切,面向东盟国家语言的跨语言信息检索和跨语言信息服务研究显得更加迫切,其重要性日益凸显。技术实现要素:本发明的目的在于针对现有技术中的上述问题,将矩阵加权关联规则挖掘技术应用于印尼汉跨语言信息检索,提供一种基于矩阵加权关联模式的印尼汉跨语言检索方法及系统,能提高和改善印尼中跨语言信息检索性能,对长查询的印尼中跨语言检索效果更好。为实现上述发明目的,本发明采用了如下技术方案:一种基于矩阵加权关联模式的印尼汉跨语言检索方法,包括如下步骤:(1)将印尼语用户查询通过机器翻译模块翻译为中文查询式,然后检索中文文档得到跨语言初检结果中文文档集;(2)提取跨语言初步检索结果前n篇中文文档作为初检中文相关文档集;(3)预处理初检中文相关文档集,即进行中文分词、去除停用词、计算特征词权值和提取特征词的预处理操作,构建初检前列文档数据库;(4)扫描初检前列文档数据库,挖掘矩阵加权特征词1_候选项集C1,计算C1权值W(C1),统计C1以外的项目的最大权值maxCwi(!C1)和C1的支持计数nc1,ms为最小支持度阈值,计算KIWT(1,2)的值,KIWT(1,2)的计算公式是:KIWT(1,2)=n×1×ms-nc1×maxCwi(!C1);(5)计算特征词1_候选项集C1的支持度FTISup(C1),如果FTISup(C1)≧ms则从1_候选项集C1挖掘1_频繁项集L1,并加到矩阵加权特征词频繁项集集合L,FTISup(C1)的计算公式是:(6)挖掘k_项集,其中所述的k≧2,包括步骤(6.1)至(6.7):(6.1)比较候选(k-1)_项集Ck-1权值和KIWT(k-1,k)值,剪除其W(Ck-1)<KIWT(k-1,k)的候选项集Ck-1;(6.2)将余下的进行候选(k-1)项集Ck-1进行Aproiri连接,得到Ck;(6.3)当k=2时,剪除不含查询项的候选2_项集;(6.4)扫描初检前列文档数据库,统计Ck以外的项目的最大权值maxCwi(!Ck)和Ck的支持计数nck,计算Ck权值W(Ck)和KIWT(k-1,k)的值,KIWT(k-1,k)的计算公式是:KIWT(k-1,k)=n×k×ms-nck×maxCwi(!Ck);(6.5)剪除nck为0的候选项集Ck;(6.6)对余下的候选k_项集Ck,计算Ck支持度FTISup(Ck),如果FTISup(Ck)≧ms,则从候选k_项集Ck中挖掘k_频繁项集Lk,并加到矩阵加权特征词频繁项集集合L,FTISup(Ck)的计算公式是:(6.7)若k大于候选项集长度阈值或者候选k_项集为空集,则挖掘结束,否则,继续循环步骤(6.1)至(6.6);(7)从矩阵加权特征词频繁项集集合L中挖掘含有查询词项的特征词矩阵加权关联规则,构建矩阵加权关联规则库;(8)从矩阵加权关联规则库中提取与原查询相关的跨语言扩展词,构建扩展词库;(9)将原查询和扩展词组合为新查询再次检索得到最终检索结果中文文档;(10)将最终结果中文文档通过机器翻译模块翻译为印尼语文档,最后将最终检索结果中文文档和将最终检索结果印尼语文档返回给用户。上述步骤(3)中所述的特征词权值的计算采用tf-idf方法,其计算公式是:其中,tfm,n表示特征词tm在文档dn中的出现次数,dfm表示含有特征词tm的文档数量,N表示文档集合中总的文档数量,max(tfn)为文档dn中特征词的最大词频。上述步骤(7)的方法包括步骤(7.1)至(7.4):(7.1)从矩阵加权特征词频繁项集集合L中提取某一矩阵加权i_频繁项集tlLi,找出tlLi的所有真子集;(7.2)从tlLi的真子集集合中任意取出两个真子集tlI1和tlI2,当并且tlI1∪tlI2=Li,若FTARConf(tlI1→tlI2)≧mc,则挖掘出矩阵加权特征词强关联规则tlI1→tlI2;若FTARConf(tlI2→tlI1)≧mc,则挖掘出矩阵加权特征词强关联规则tlI2→tlI1;所述的mc为最小置信度阈值,tlI1和tlI2为矩阵加权特征词频繁项集,是tlLi的真子集项集,FTARConf(tlI1→tlI2)为矩阵加权特征词关联规则tlI1→tlI2的置信度,其计算公式是:其中,FTISup(Li)为矩阵加权频繁项集Li的支持度,FTISup(tlI1)为矩阵加权频繁项集tlI1的支持度;(7.3)循环进行步骤(7.2),直到矩阵加权i_频繁项集tlLi的真子集集合中每个真子集都被取出一次,而且仅能取出一次,则转入步骤(7.4);(7.4)循环进行步骤(7.1)至(7.3),当矩阵加权特征词频繁项集集合L中的项集都被取出一次,而且仅能取出一次,则挖掘结束。一种适用于上述基于矩阵加权关联模式的印尼汉跨语言检索方法的检索系统,包括以下5个模块和3个数据库:机器翻译模块:该模块使用必应机器翻译接口,用于将用户提交的印尼语用户查询翻译为中文查询式,以及将最终检索结果中文文档翻译为印尼语文档提交给用户;基于向量空间模型的文本检索模块:该模块采用基于向量空间模型的检索技术,用于对译后的中文查询式在中文文档集上进行检索,得到跨语言初检结果文档集;面向印尼中跨语言检索的矩阵加权关联规则挖掘模块:用于对初检前列文档数据库进行矩阵加权关联规则挖掘,挖掘含有原查询词项的矩阵加权特征词项频繁项集和关联规则模式,构建矩阵加权关联规则库;跨语言查询扩展模块:用于从矩阵加权关联规则库中提取与原查询相关的扩展词,扩展词和原查询组合为新查询再次通过基于向量空间模型的文本检索模块检索中文文档,得到最终检索结果中文文档;最终结果显示模块:用于将最终检索结果中文文档提交到机器翻译模块翻译为印尼语文档,并将最终检索结果中文文档和最终检索结果印尼语文档返回用户;初检前列文档数据库;矩阵加权关联规则库;扩展词库。上述面向印尼中跨语言检索的矩阵加权关联规则挖掘模块包括以下3个模块:初检前列相关文档提取模块:用于从跨语言初检结果中文文档集中提取跨语言初检结果前n篇中文文档作为初检中文相关文档集;中文文档预处理模块:用于对初检中文相关文档集进行中文分词、去除停用词、计算特征词权值和提取特征词的预处理,构建初检前列文档数据库;矩阵加权关联规则挖掘模块:用于对所述初检前列文档数据库进行矩阵加权关联规则挖掘,挖掘含有原查询词项的矩阵加权特征词项频繁项集和关联规则模式,构建矩阵加权关联规则库。上述跨语言查询扩展模块包括以下2个模块:跨语言查询扩展词生成模块:用于从矩阵加权关联规则库中提取与原查询相关的扩展词,构建扩展词库;跨语言查询扩展实现模块:用于从扩展词库中提取中文扩展词,将扩展词和原查询组合成新查询,再次提交给基于向量空间模型的文本检索模块中检索,得到最终检索结果中文文档。相比于现有技术,本发明的优势在于:(1)本发明将矩阵加权关联规则挖掘技术应用于印尼汉跨语言信息检索,提出基于矩阵加权关联模式的印尼汉跨语言检索方法及系统,与单语言中文文本检索基准MB和传统的基于伪相关反馈的跨语言信息检索方法CLR_PRF(文献JianfengGao,JianyunNie,JianZhang,etal,TREC-9CLIRExperimentsatMSRCN.In:Proc.ofthe9thTextRetrievalEvaluationConference,2001:343-353.;吴丹,何大庆,王惠临.基于伪相关的跨语言查询扩展.情报学报,2010,29(2):232-239.)比较,本发明方法的检索性能获得了很大的改善和提高,实验结果表明,当矩阵加权支持度阈值变化时,本发明方法检索结果的MAP值高于传统的伪相关跨语言检索方法CLR_PRF的值,提高的幅度最大可以达到43.5%,同时,达到单语言检索基准MB的42.07%和42.43%。当置信度阈值变化时,本发明获得很好的检索结果,MAP值高于高于传统的伪相关跨语言检索方法CLR_PRF的值,提高的幅度最大可以达到91.33%,同时,达到单语言检索基准MB的54.64%至56.57%。(2)实验结果表明,本发明提出的基于矩阵加权关联模式的印尼汉跨语言检索方法及系统是有效的,能改善和提高跨语言信息检索性能。其主要原因分析如下:在跨语言信息检索中,查询翻译结果对跨语言检索结果影响较大,常常导致跨语言初检结果质量不如单语言的初检结果,即出现查询主题漂移问题。而本发明将矩阵加权关联模式挖掘技术应用到印尼中跨语言信息检索模型,可以获得与原查询最相关的反馈信息,通过矩阵加权关联规则挖掘得到与原查询相关的扩展词实现跨语言查询扩展,避免了跨语言检索中存在的严重主题漂移问题,提高了印尼中跨语言检索性能。附图说明图1是本发明基于矩阵加权关联模式的印尼汉跨语言检索方法的框图。图2是本发明基于矩阵加权关联模式的印尼汉跨语言检索系统整体流程图。图3是本发明基于矩阵加权关联模式的印尼汉跨语言检索系统结构框图。图4是本发明所述的面向印尼中跨语言检索的矩阵加权关联规则挖掘模块结构框图。图5是本发明所述的跨语言查询扩展模块结构框图。具体实施方式以下结合实施例及其附图对本发明技术方案作进一步非限制性的详细说明。一、为了更好地说明本发明的技术方案,下面将本发明涉及的相关概念介绍如下:假设用户查询经过跨语言检索后得到的目标语言(TargetLanguage,TL)初检相关文档集为TLdoc={tld1,tld2,…,tldn},tldi(1≦i≦n)表示目标语言文档集TLdoc中的第i篇文档,tldj={t1,t2,…,tm,…,tp},tm(m=1,2,…,p)称为目标语言特征词项目(Feature-termItem,FTI),简称为特征项,一般是由字、词或词组构成,tldi中对应的特征项权值集合Wi={wi1,wi2,…,wim,…,wip},wim为第i篇文档tldi中第m个特征项tm的对应的权值,令tlI={t1,t2,…,tk}表示TLdoc中全体特征项集合,则tlI的子集Y称为TLdoc中的特征词项集(Feature-termItemsets),即项集Y。对于项集(tlI1,tlI2),且根据矩阵加权关联模式挖掘理论知识(黄名选,严小卫,张师超.基于矩阵加权关联规则挖掘的伪相关反馈查询扩展.软件学报,Vol.20,No.7,July2009,pp.1854-1865),给出如下一些基本概念。定义1特征词项集I(I=(tlI1,tlI2))的矩阵加权支持度(Feature-termItemsetsSupport,FTISup)计算公式如(1)式所示。其中,是项集I在TLdocD中各篇文档的权值总和,k为项集I的项目长度(即项目个数),n是TLdoc中文档总数。定义2词间关联规则tlI1→tlI2的矩阵加权置信度(Feature-termAssociationRuleConfidence,FTARConf)如(2)式所示。其中,FTIsup(tlI1,tlI2)为项集(tlI1,tlI2)的矩阵加权支持度。定义3假设最小支持度阈值为ms,最小置信度阈值为mc,若满足:FTISup(tlI1,tlI2)≧ms,FTARConf(tlI1→tlI2)≧mc,则称特征词项集(tlI1,tlI2)为频繁项集,词间关联规则(tlI1→tlI2)为强关联规则。定义4包含q_项集的特征词k_项集权值阈值(k-ItemWeightedThreshold,KIWT)(q<k)是指对包含q_项集的后续项集的权值预测。设tlT是矩阵加权q-项集,且q<k,在(tlI-tlT)项集中,记前(k-q)个权值最大的项目相应的权值为w1,w2,…wk-q,q-项集tlT在TLdoc中的支持计数为SC(tlT),根据文献(黄名选,严小卫,张师超.基于矩阵加权关联规则挖掘的伪相关反馈查询扩展.软件学报,Vol.20,No.7,July2009,pp.1854-1865)的k-权值阈值理论知识,给出了包含q_项集的特征词k_项集权值阈值的计算公式如式(3)所示。二、如图1所示,本实施例的基于矩阵加权关联模式的印尼汉跨语言检索方法,包括如下步骤:(1)将印尼语用户查询通过机器翻译模块翻译为中文查询式,然后检索中文文档得到跨语言初检结果中文文档集;本实施例采用的机器翻译模块采用必应机器翻译接口,即MicrosoftTranslatorAPI;(2)提取跨语言初步检索结果前n篇中文文档作为初检中文相关文档集;(3)预处理初检中文相关文档集,即进行中文分词、去除停用词、计算特征词权值和提取特征词的预处理操作,构建初检前列文档数据库;所述的特征词权值的计算采用tf-idf方法,其计算公式是:其中,tfm,n表示特征词tm在文档dn中的出现次数,dfm表示含有特征词tm的文档数量,N表示文档集合中总的文档数量,max(tfn)为文档dn中特征词的最大词频;(4)扫描初检前列文档数据库,挖掘矩阵加权特征词1_候选项集C1,计算C1权值W(C1),统计C1以外的项目的最大权值maxCwi(!C1)和C1的支持计数nc1,ms为最小支持度阈值,计算KIWT(1,2)的值,KIWT(1,2)的计算公式是:KIWT(1,2)=n×1×ms-nc1×maxCwi(!C1);(5)计算特征词1_候选项集C1的支持度FTISup(C1),如果FTISup(C1)≧ms则从1_候选项集C1挖掘1_频繁项集L1,并加到矩阵加权特征词频繁项集集合L,FTISup(C1)的计算公式是:(6)挖掘k_项集,其中k≧2,包括步骤(6.1)至(6.7):(6.1)比较候选(k-1)_项集Ck-1权值和KIWT(k-1,k)值,剪除其W(Ck-1)<KIWT(k-1,k)的候选项集Ck-1;(6.2)将余下的进行候选(k-1)项集Ck-1进行Aproiri连接,得到Ck;(6.3)当k=2时,剪除不含查询项的候选2_项集;(6.4)扫描初检前列文档数据库,统计Ck以外的项目的最大权值maxCwi(!Ck)和Ck的支持计数nck,计算Ck权值W(Ck)和KIWT(k-1,k)的值,KIWT(k-1,k)的计算公式是:KIWT(k-1,k)=n×k×ms-nck×maxCwi(!Ck);(6.5)剪除nck为0的候选项集Ck;(6.6)对余下的候选k_项集Ck,计算Ck支持度FTISup(Ck),如果FTISup(Ck)≧ms,则从候选k_项集Ck中挖掘k_频繁项集Lk,并加到矩阵加权特征词频繁项集集合L,FTISup(Ck)的计算公式是:(6.7)若k大于候选项集长度阈值或者候选k_项集为空集,则挖掘结束,否则,继续循环步骤(6.1)至(6.6);(7)从矩阵加权特征词频繁项集集合L中挖掘含有查询词项的特征词矩阵加权关联规则,构建矩阵加权关联规则库;方法包括步骤(7.1)至(7.4):(7.1)从矩阵加权特征词频繁项集集合L中提取某一矩阵加权i_频繁项集tlLi,找出tlLi的所有真子集;(7.2)从tlLi的真子集集合中任意取出两个真子集tlI1和tlI2,当并且tlI1∪tlI2=Li,若FTARConf(tlI1→tlI2)≧mc,则挖掘出矩阵加权特征词强关联规则tlI1→tlI2;若FTARConf(tlI2→tlI1)≧mc,则挖掘出矩阵加权特征词强关联规则tlI2→tlI1;所述的mc为最小置信度阈值,tlI1和tlI2为矩阵加权特征词频繁项集,是tlLi的真子集项集,FTARConf(tlI1→tlI2)为矩阵加权特征词关联规则tlI1→tlI2的置信度,其计算公式是:其中,FTISup(Li)为矩阵加权频繁项集Li的支持度,FTISup(tlI1)为矩阵加权频繁项集tlI1的支持度;(7.3)循环进行步骤(7.2),直到矩阵加权i_频繁项集tlLi的真子集集合中每个真子集都被取出一次,而且仅能取出一次,则转入步骤(7.4);(7.4)循环进行步骤(7.1)至(7.3),当矩阵加权特征词频繁项集集合L中的项集都被取出一次,而且仅能取出一次,则挖掘结束;(8)从矩阵加权关联规则库中提取与原查询相关的跨语言扩展词,构建扩展词库;(9)将原查询和扩展词组合为新查询再次检索得到最终检索结果中文文档;(10)将最终结果中文文档通过机器翻译模块翻译为印尼语文档,最后将最终检索结果中文文档和将最终检索结果印尼语文档返回给用户。三、如图2至5所示,适用于本实施例基于矩阵加权关联模式的印尼汉跨语言检索方法的检索系统,包括以下5个模块和3个数据库:机器翻译模块:该模块使用必应机器翻译接口,即MicrosoftTranslatorAPI,用于将用户提交的印尼语用户查询翻译为中文查询式,以及将最终检索结果中文文档翻译为印尼语文档提交给用户;基于向量空间模型的文本检索模块:该模块采用基于向量空间模型的检索技术,用于对译后的中文查询式在中文文档集上进行检索,得到跨语言初检结果文档集;面向印尼中跨语言检索的矩阵加权关联规则挖掘模块:用于对初检前列文档数据库进行矩阵加权关联规则挖掘,挖掘含有原查询词项的矩阵加权特征词项频繁项集和关联规则模式,构建矩阵加权关联规则库;跨语言查询扩展模块:用于从矩阵加权关联规则库中提取与原查询相关的扩展词,扩展词和原查询组合为新查询再次通过基于向量空间模型的文本检索模块检索中文文档,得到最终检索结果中文文档;最终结果显示模块:用于将最终检索结果中文文档提交到机器翻译模块翻译为印尼语文档,并将最终检索结果中文文档和最终检索结果印尼语文档返回用户;初检前列文档数据库;矩阵加权关联规则库;扩展词库。其中,所述面向印尼中跨语言检索的矩阵加权关联规则挖掘模块包括以下3个模块:初检前列相关文档提取模块:用于从跨语言初检结果中文文档集中提取跨语言初检结果前n篇中文文档作为初检中文相关文档集;中文文档预处理模块:用于对初检中文相关文档集进行中文分词、去除停用词、计算特征词权值和提取特征词的预处理,构建初检前列文档数据库;矩阵加权关联规则挖掘模块:用于对所述初检前列文档数据库进行矩阵加权关联规则挖掘,挖掘含有原查询词项的矩阵加权特征词项频繁项集和关联规则模式,构建矩阵加权关联规则库。其中,所述跨语言查询扩展模块包括以下2个模块:跨语言查询扩展词生成模块:用于从矩阵加权关联规则库中提取与原查询相关的扩展词,构建扩展词库;跨语言查询扩展实现模块:用于从扩展词库中提取中文扩展词,将扩展词和原查询组合成新查询,再次提交给基于向量空间模型的文本检索模块中检索,得到最终检索结果中文文档。四、结合本发明的技术方案,下面通过实验对本发明的有益效果做进一步说明:编写了本发明方法及系统的源程序进行本发明的实验。采用日本情报信息研究所主办的多国语言处理国际评测会议上的跨语言信息检索标准数据测试集NTCIR-5CLIR的中文语料作为本实验语料。NTCIR-5CLIR有查询集、文档测试集以及结果集,其中,查询集有50个查询主题,分有TITLE、DESC、NARR和CONC等4种类型,本发明实验选择DESC类型的查询主题。其结果集有Rigid和Relax等2种评价标准。为了进行本文印尼中跨语言信息检索模型的实验,邀请翻译机构专业翻译人士将NTCIR-5CLIR中文版50个查询主题人工翻译为印尼语查询。本文实验中,采用汉语词法分析系统ICTCLAS对中文实验语料和译后中文查询进行预处理。特征词权值计算采用传统的tf-idf方法,译后查询项权重(wi,q)计算公式(来自文献G.Salton,C.Buckley.Term-weightingapproachesinautomatictextretrieval[J].InformationProcessing&Management,1988,24(5):513-523.)如式(1)所示。其中,tfi,q为查询项在查询文本信息中出现的初始频率,N为初检相关文档总数,dfi为包含第i个查询项的初检相关文档数。本实验中,中文扩展词的权值设置方法是:将矩阵加权关联规则的置信度作为扩展词的权值,当多个关联规则含有重复相同的查询项时,取其置信度最高者作为该扩展词权值。实验的评价指标是:平均查准率的均值(MeanAveragePrecision,MAP)。实验评测比较基准是:(1)单语言检索基准(MonolingualBaseline,MB):用中文查询直接检索中文文档得到的检索结果。(2)传统的基于伪相关反馈的跨语言检索方法CLR_PRF(JianfengGao,JianyunNie,JianZhang,etal,TREC-9CLIRExperimentsatMSRCN[C].In:Proc.ofthe9thTextRetrievalEvaluationConference,2001:343-353.;吴丹,何大庆,王惠临.基于伪相关的跨语言查询扩展[J].情报学报,2010,29(2):232-239.)。本实验中,提取跨语言前列初检文档20篇构建初检相关文档集,提取前列权值(降序排列)的20个特征词为扩展词。本发明方法实验参数:初检前列文档数n=10,挖掘的候选项集长度C_length=3。支持度变化时实验参数:mc=0.005,ms分别为0.02、0.025、0.035时得到跨语言检索结果的MAP值,取平均值实验结果值;置信度变化时实验参数:ms=0.02,mc分别为0.005、0.007、0.009、0.02、0.04时得到MAP值,取平均值作为实验结果值。编写了源程序,将本发明方法与基准方法MB和CLR_PRF在NTCIR-5CLIR测试集上进行印尼汉跨语言文本检索,比较和分析其跨语言检索性能。(1)基准实验结果运行实验源程序,提交NTCIR-5CLIR的50个DESC类型的查询主题进行中文单语言检索和传统的基于伪相关反馈的印尼汉跨语言检索,即运行基准方法MB和CLR_PRF,得到检索实验MAP结果如表1所示。表1:表1实验结果表明,传统的CLR_PRF方法检索结果的MAP值只达到单语言检索基准MB的37.21%和29.57%。这些结果说明,跨语言检索受查询翻译因素的影响,检索性能普遍低下,还达不到其相应的单语言检索性能。(2)本发明方法与基准算法的检索性能比较采用NTCIR-5CLIR的50个DESC类型的查询主题,对支持度变化和置信度变化时两种情况进行检索性能实验,与传统的CLR_PRF方法,以及单语言检索基准MB进行检索性能比较。支持度阈值变化时检索结果的MAP值如表2所示,置信度阈值变化时检索结果的MAP值如表3所示。表2:评测类型本发明方法占MB基准的比例(%)比CLR_PRF方法提高的比例(%)Relax0.154341.0710.37Rigid0.089442.4343.50表3:评测类型本发明方法占MB基准的比例(%)比CLR_PRF提高的比例(%)Relax0.205354.6446.85Rigid0.119256.5791.33从表2的实验结果可知,当矩阵加权支持度阈值变化时,本发明方法检索结果的MAP值高于传统的伪相关跨语言检索方法CLR_PRF的值,提高的幅度最大可以达到43.5%,同时,达到单语言检索基准MB的42.07%和42.43%。表3实验结果表明,当置信度阈值变化时,本发明获得很好的检索结果,MAP值高于传统的伪相关跨语言检索方法CLR_PRF的值,提高的幅度最大可以达到91.33%,同时,达到单语言检索基准MB的54.64%至56.57%。综上所述,本发明的检索性能比对比方法的好,具有推广应用价值。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1