一种用于大数据平台的管理方法及系统与流程
本发明实施例涉及大数据处理技术领域,尤其涉及一种用于大数据平台的管理方法及系统。
背景技术:
随着社会信息化技术的不断提高以及互联网技术快速普及,各个领域对海量数据处理的需求也越来越多,传统的集中式数据处理方法已无法对海量数据进行高效处理,由此出现了分布式的大数据处理平台(大数据平台)。具体的,大数据平台可理解为由多种服务组件通过业务敲定和实际数据处理需求组合构建的分布式处理平台。
在根据大数据平台进行数据处理时,大数据平台上的各服务组件独立工作但各服务组件间又相互协作,如果某个服务组件中的服务进程出现中断或宕机,则有可能对整个数据处理过程产生影响。因此,需要对大数据平台进行监控和预警,以使运维人员更好的运维管理大数据平台。目前,对大数据平台的监控和预警通常采用如下做法:分别运行一套监控系统和一套预警系统共同提供大数据平台的稳健运行;或者,对组成大数据平台的集群节点的物理特性进行监控,例如监控集群节点的内存、中央处理器、磁盘、输入/输出设备等物理设备的使用情况,然后以配置短信、邮件等方式进行预警。
现有的监控和预警的方法存在的问题有:1、采用上述第一种方法时,对于监控和预警两项功能需要在大数据平台上同时运行两套系统,从运维管理的角度而言,运维人员需要耗费更多的时间和精力学习两套系统的相关内容并分别实现对两套系统的运维管理,从系统资源的角度而言,大数据平台的服务器将需要更大的磁盘空间、内存空间等资源提供给两套系统运行,此外,该种方法对服务进程和网络端口的监控比较底层,只有当服务进程挂掉或者显示地提醒用户该服务进程不可用时,运维人员才会进入对该服务做一些应急处理,如果此服务进程面向大量客户进行服务,则通过上述处理手段进行服务恢复将会极大的影响用户体验;2、采用上述第二种方法时,仅仅是对大数据平台硬件级别的监控和预警,并没有实现对大数据平台上服务组件的监控和预警,其监控和预警力度过低。
技术实现要素:
本发明实施例提供了一种用于大数据平台的管理方法及系统,简单高效地实现了对大数据平台各服务组件的监控和预警。
一方面,本发明实施例提供了一种用于大数据平台的管理方法,包括:
获取大数据平台上的服务组件对应的日志信息;
检测所述日志信息中的日志状态标识;
如果所述日志状态标识符合预设的报警条件,则根据所述日志状态标识对应的日志信息输出所述服务组件的报警信息。
另一方面,本发明实施例提供了一种用于大数据平台的管理系统,包括:
日志信息获取模块,用于获取大数据平台上的服务组件对应的日志信息;
状态标识检测模块,用于检测所述日志信息中的日志状态标识;
报警信息输出模块,用于当所述日志状态标识符合预设的报警条件时,根据所述日志状态标识对应的日志信息输出所述服务组件的报警信息。
本发明实施例中提供的一种用于大数据平台的管理方法及系统,该方法首先获取大数据平台上的服务组件对应的日志信息;然后对所获取的日志信息的日志状态标识进行检测;当日志状态标识符合预设报警条件时,根据日志状态标识对应的日志信息就能够输出服务组件的报警信息。利用该方法,能够简单高效地实现对大数据平台上各服务组件的实时监控和预警,精细了对大数据平台各服务组件的管理粒度;此外,该方法不仅减少了运维管理的人力资源投入,也减少了大数据平台所在服务器的资源消耗;同时还进一步提升了大数据平台的用户体验。
附图说明
图1为本发明实施例一提供的一种用于大数据平台的管理方法的流程示意图;
图2为本发明实施例二提供的一种用于大数据平台的管理方法的流程示意图;
图3a为本发明实施例三提供的一种用于大数据平台的管理方法的优选实施例的流程示意图;
图3b为本发明实施例三提供的一种大数据平台的框架图;
图4为本发明实施例四提供的一种用于大数据平台的管理系统的结构框图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
实施例一
图1为本发明实施例一提供的一种用于大数据平台的管理方法的流程示意图,适用于对大数据平台上运行的各服务组件进行监控和预警的情况,该方法可以由用于大数据平台的管理系统执行,其中该系统可由软件和/或硬件实现,作为大数据平台的一部分集成在大数据平台中。
一般的,大数据平台主要基于运行其上的至少一个服务组件实现对大数据的处理操作,示例性的,常见的大数据平台如Hadoop分布式平台,在Hadoop分布式平台运行的服务组件包括Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)、Hadoop数据仓库如Hive以及分布式面向列的开源数据库如Hbase等。如果其上的服务组件停止运行或运行错误,则会影响大数据的处理操作,因此需要对大数据平台上各服务组件的工作状态进行监控和预警。本实施例提供的用于大数据平台的管理方法能够实现对大数据平台中各服务组件的监控和预警。
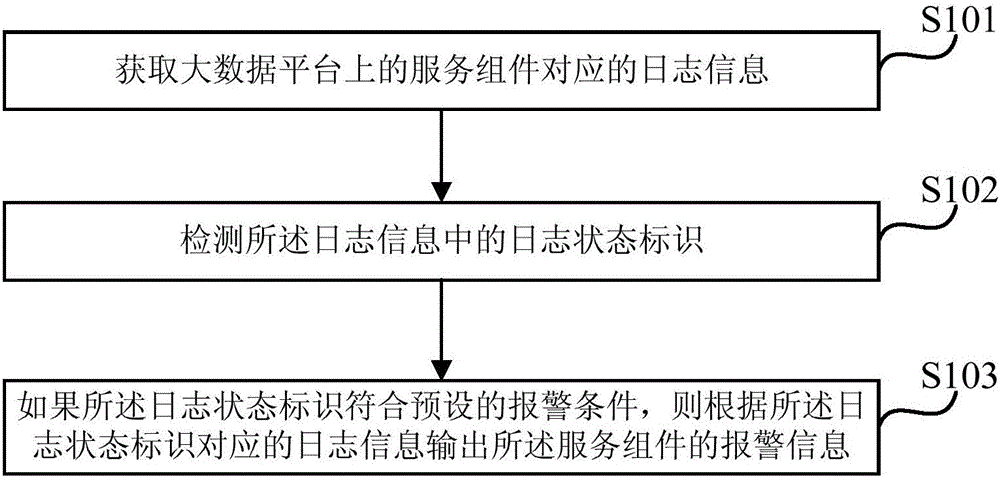
如图1所示,本发明实施例一提供的一种用于大数据平台的管理方法,包括如下操作:
S101、获取大数据平台上的服务组件对应的日志信息。
一般的,用于大数据处理的大数据平台为一个分布式平台,且运行在大数据平台上各服务组件均可由一个主节点和至少一个从节点组成,示例性的,如Hadoop分布式平台上的HDFS,其主节点可以表示为NameNode,从节点可以表示为DataNode。此外,对于所述服务组件而言,其相应的主节点和从节点可分别看作一个服务进程,而服务组件的运行主要依赖于相应的服务进程,因此,可以通过监控服务组件的服务进程的运行情况来实现对服务组件的管理。
具体的,所述服务组件中的服务进程在运行过程中会产生相应的运行日志,所述运行日志具体可用于记录所述服务进程的运行信息。在本实施例中,所述服务组件的日志信息具体可看作所述服务组件中至少一个服务进程的运行日志,由此通过获取服务组件中至少一个服务进程的运行日志来确定服务组件的日志信息,并基于所述日志信息对所述服务组件的工作状态进行监控和预警管理。
S102、检测所述日志信息中的日志状态标识。
一般的,在大数据平台上运行服务组件时,服务组件的服务进程所产生的运行日志中具体描述了所述服务进程的具体运行状态,并会进行相应的运行状态标记。示例性的,对于运行错误的服务进程而言,则会在相应的运行日志中进行错误标记,并记录产生错误的详细信息,又如,对于运行正常的服务进程而言,则会其运行日志中进行正常标记,并记录正常的运行信息。
在本实施例中,所述日志状态标识具体可指所述日志信息中记录的服务进程的运行状态标记,用于描述服务进程的运行状态的稳定程度。具体的,在获取到所述服务组件对应的日志信息后,可以对所述日志信息中的日志状态标识进行检测,来确定相应服务组件的具体工作状态,由此实现对相应服务组件工作状态的监控管理。
进一步的,所述日志状态标识包括运行错误标识、运行警告标识和/或运行正常标识。
在本实施例中,可以通过对日志信息的日志状态标识的检测来实现对服务组件工作状态的监控。具体的,在检测出所述日志状态标识为运行错误标识时,可以认为相应服务组件在运行过程中出现了错误运行的情况,出现错误的服务组件的工作状态很不稳定,甚至有可能对大数据平台中的其他服务组件的运行产生影响;在检测出所述日志状态标识为运行警告标识时,可以认为所述服务组件在运行过程中出现了警告提示,服务组件的工作状态存在波动,虽然不会影响大数据平台其他服务组件的运行,但有可能会对相应服务组件的其他服务进程产生影响;在检测出所述日志状态标识为运行正常标识时,可以认为所述服务组件为正常运行,工作状态稳定,此时不会影响自身或其他服务组件的运行。
S103、如果所述日志状态标识符合预设的报警条件,则根据所述日志状态标识对应的日志信息输出所述服务组件的报警信息。
在本实施例中,在基于上述步骤实现对相应服务组件工作状态的监控管理后,可以进一步对所述服务组件进行预警管理。具体的,本实施例可以对符合报警条件的服务组件基于相应的日志信息确定报警信息,并将报警信息以设定的方式输出给大数据平台的运维管理人员,以实现对所述服务组件的预警管理。
在本实施例中,所述报警条件具体可理解为设定的用于确定是否进行相应服务组件报警信息输出的判定条件。一般地,所述报警条件可以为运行错误标识、运行警告标识以及运行正常标识中的一种或几种,可以由运维人员基于大数据平台的实际工作需求预先设定。示例性的,如果服务组件中服务进程运行错误时会对大数据平台的处理操作产生影响,就可以将日志状态标识中的运行错误标识设定为报警条件;又如,当对数据处理要求较高时,除了运行错误标识还需要将日志状态标识中的运行警告标识也作为报警条件。
在本实施例中,当确定所述日志信息中的日志状态标识符合所述报警条件时,可以对所述日志信息的具体内容进行解析,由此形成与所述日志信息对应服务组件的报警信息,并输出所述报警信息。具体的,可以基于设定的解析规则或通过相应的机器学习算法对所述日志信息的具体内容进行解析,所形成的报警信息中可以包括所述日志信息的关键词、所述日志信息对应的报警级别以及对所述日志信息进行报警的具体原因等;最终可以基于邮件或短信息的输出方式将所述报警信息输出给运维人员,实现服务组件的预警管理。
本发明实施例一提供的一种用于大数据平台的管理方法,首先获取大数据平台上的服务组件对应的日志信息;然后对所获取的日志信息的日志状态标识进行检测;当日志状态标识符合预设报警条件时,根据日志状态标识对应的日志信息就能够输出服务组件的报警信息。利用该方法,能够简单高效地实现对大数据平台上各服务组件的实时监控和预警,精细了对大数据平台各服务组件的管理粒度;此外,该方法不仅减少了运维管理的人力资源投入,也减少了大数据平台所在服务器的资源消耗;同时还进一步提升了大数据平台的用户体验。
实施例二
图2为本发明实施例二提供的一种用于大数据平台的管理方法的流程示意图。本发明实施例以上述实施例为基础进行优化,在本实施例中,还优化包括了:如果所述日志状态标识不符合预设的报警条件,则输出所述服务组件的状态正常信息。
进一步的,本实施例将获取大数据平台上的服务组件对应的日志信息具体化为:获取所述大数据平台上服务组件中的至少一个服务进程对应的运行日志;将所述运行日志存储到所述大数据平台的分布式文件系统的指定目录文件中,并将所述指定目录文件中的运行日志作为所述服务组件的日志信息。
进一步的,本实施例还将根据所述日志状态标识对应的日志信息输出所述服务组件的报警信息具体化为:将所述日志状态标识对应的日志信息按照预设的基础诊断库的信息格式进行解析,形成报警日志信息;根据所述报警日志信息查找所述基础诊断库,确定所述服务组件的报警信息并输出。
如图2所示,本发明实施例二提供的一种用于大数据平台的管理方法,具体包括如下操作:
S201、获取所述大数据平台上服务组件中的至少一个服务进程对应的运行日志。
在本实施例中,所述服务组件中相应服务进程的运行日志是基于服务进程的运行实时产生的,因此,可以在所述服务组件相应服务进程的运行过程中实时获取对应的运行日志。需要说明的是,所述服务组件中可能存在一个或多个服务进程,本实施例可以基于所述服务组件中至少一个服务进程的运行日志来确定所述服务组件的日志信息。一般的,为了保证对所述服务组件监控和预警的准确性,可以优选地获取所述服务组件中所有服务进程对应的运行日志,并基于所述运行日志确定相应的日志信息。
S202、将所述运行日志存储到所述大数据平台的分布式文件系统的指定目录文件中,并将所述指定目录文件中的运行日志作为所述服务组件的日志信息。
在本实施例中,可以设定相应的管理周期,以一定的管理周期对大数据平台的服务组件进行监控和预警管理操作。由于所述服务组件中服务进程是实时获取的,因此,本实施例需要对所获取运行日志进行存储,具体的,可以将所述运行日志存储到大数据平台的分布式文件系统的指定目录中。
在本实施例中,所述指定目录相当于存储所述运行日志所需的存储路径,本实施例可以根据大数据平台中存在的各服务组件在分布式文件系统中设定相应的存储路径,其中,大数据中的分布式文件系统具体用于分布式存储大数据处理时所需的各种数据信息。在将所述服务组件对应的运行日志存储到指定目录后,可将各指定目录中的运行日志作为相应服务组件的日志信息,所述日志信息用于对所述服务组件的监控和预警管理。
S203、如果所述日志状态标识符合预设的报警条件,则将所述日志状态标识对应的日志信息按照预设的基础诊断库的信息格式进行解析,形成报警日志信息,之后执行步骤S204。
在本实施例中,所述日志状态标识包括运行错误标识、运行警告标识和/或运行正常标识,则可设定所述报警条件为所述运行错误标识、运行警告标识以及运行正常标识中的一种或几种,优选的,本实施例设定所述报警条件为运行错误标识。在本实施例中,所述基础诊断库具体可理解为包含大数据平台中服务组件运行时常见错误信息的数据信息库,一般可以预先设定在大数据平台中,可以理解的是初始的基础诊断库中的数据信息可以为空,之后可在对大数据平台的服务组件进行管理操作时逐渐进行数据信息积累。
在本实施例中,在确定所述日志状态标识符合所述报警条件后,可以基于所述日志状态标识对应的日志信息进行报警信息的输出。具体的,首先需要对所述日志状态标识对应的日志信息的具体内容进行解析,本实施例优选的基于所述基础诊断库中所存储数据信息对应的信息格式对所述日志信息进行解析,并将解析后的信息内容记为报警日志信息,其中,本实施例将所述基础诊断库中的信息格式优选为类似[A,B]的二元字符组形式,且对二元字符组中A和B的表示形式没有具体限定。
进一步的,所述将所述日志状态标识对应的日志信息按照预设的基础诊断库的信息格式进行解析,形成报警日志信息包括:从所述日志状态标识对应的日志信息中获取至少一个关键词;根据所述至少一个关键词确定所述日志信息对应的报警级别;根据预设的基础诊断库的信息格式创建所述日志信息的二元字符组,形成所述日志信息的报警日志信息,其中,所述二元字符组包括第一元素和第二元素,所述第一元素包括所述至少一个关键词和所述报警级别,所述第二元素包括与所述日志状态标识对应的日志信息。
在本实施例中,当所述日志状态标识符合所述报警信息后,可以将所述日志状态标识对应的日志信息看作一段具体文字信息,之后基于设定的语义解析规则或者基于设定的机器学习算法从所述具体文字信息中解析出所述日志信息的至少一个关键词,同时还可以基于所述至少一个关键词以及预先设定的报警级别匹配表确定所述日志信息对应的报警级别,其中,所述报警级别匹配表具体可以是技术人员预先设定的关键词与报警级别的关系表,所述关系表可以基于历史经验信息确定。
在本实施例中,在确定所述基础诊断库的信息格式为二元字符组之后,就可以创建所述日志信息的二元字符组[C,D],且所述二元字符组相当于所述日志信息的报警日志信息,其中,元素C表示所述二元字符组的第一元素,元素D表示所述二元字符组的第二元素,具体的,所述第一元素具体包括了所述日志信息的至少一个关键词以及对应的报警级别,所述第二元素具体包括了所述日志信息的具体内容。
S204、根据所述报警日志信息查找所述基础诊断库,确定所述服务组件的报警信息并输出。
在本实施例中,基于步骤S203可以确定,所述日志信息的报警日志信息为二元字符组的形式,所述基础诊断库也为二元字符组形式,因此可以在所述基础诊断库中对所述报警日志信息进行查找匹配,并可以通过匹配结果确定要输出的报警信息。
进一步的,所述根据所述报警日志信息查找所述基础诊断库,确定所述服务组件的报警信息并输出包括:确定所述报警日志信息中的第一元素是否与所述基础诊断库中二元字符组的第一元素相匹配;如果匹配,则将所述基础诊断库中对应的二元字符组作为报警信息输出;如果不匹配,则将所述报警日志信息中的报警级别修改为设定标记值,并将所述报警日志信息作为报警信息输出。
在本实施例中,当所述报警日志信息中的第一元素与所述基础诊断库中二元字符组的第一元素相匹配时,表明所述基础诊断库中存在与该日志信息相同的报警信息,此时可以直接将所述基础诊断库中对应的二元字符组作为报警信息以邮件或短信的形式输出给运维人员。
在本实施例中,当所述报警日志信息中的第一元素与所述基础诊断库中二元字符组的第一元素不相匹配时,表明所述基础诊断库中不存在与该日志信息相同的报警信息,此时可以将所述报警日志信息中的报警级别修改为设定标记值,以引起所述运维人员的注意,之后将所述报警日志信息作为报警信息输出给运维人员,以时运维人员及时对所述报警信息进行处理。其中,所述设定标记值可以由技术人员自行设定。
S205、如果所述日志状态标识不符合预设的报警条件,则输出所述服务组件的状态正常信息。
在本实施例中,还可以对不符合报警条件的服务组件也进行信息输出,此时输出的是所述服务组件的状态正常信息。
基于上述步骤S201至步骤S205的操作,实现了对大数据平台中服务组件的监控和预警管理,并且在进行预警管理时,所输出的报警信息中包含了服务组件的具体出错原因,与现有的大数据平台的管理方法相比,为运维人员提供了更精确的报警信息,使得运维人员能够快速的确定出错原因并及时解决,很大程度节省了运维人员处理时间。此外,需要说明的是,在基于本实施例提供的管理方法对服务组件进行管理时,所述日志信息均存放于所述分布式文件系统的指定目录下,随着时间的累计所述指定目录下运行日志的信息量将会越来越大,因此需要对所述指定目录下的运行日志进行定期清理,如,运行日志中均包括了相应的运行时刻,可以基于运行时刻设定清理条件,当达到清理条件时就可以删除或移除所述运行日志,以确保指定目录下运行日志时效性。
本发明实施例二提供的一种用于大数据平台的管理方法,具体化了服务组件日志信息的获取过程,同时也具体化了服务组件的报警信息的确定过程。利用该方法,简单高效地基于日志信息实现了对大数据平台上各服务组件的实时监控和预警,精细了对大数据平台各服务组件的管理粒度;不仅减少了运维管理的人力资源投入,同时也减少了大数据平台所在服务器的资源消耗;此外,还进一步提升了大数据平台的用户体验。
进一步的,在上述优化的基础上,所述报警级别包括可恢复级别和不可恢复级别;相应的,本发明实施例提供的用于大数据平台的管理方法,在确定所述报警日志信息中的第一元素与所述基础诊断库中二元字符组的第一元素相匹配之后,还包括:如果所述报警级别为可恢复级别,则重启所述报警日志信息对应的服务组件;如果所述报警级别为不可恢复级别,则获取运维人员编辑的第一二元字符组,并将所述基础诊断库中对应的二元字符组替换为所述第一二元字符组。此外,在确定所述报警日志信息中的第一元素与所述基础诊断库中二元字符组的第一元素不匹配之后,该方法还包括:获取运维人员编辑的第二二元字符组,并将所述第二二元字符组写入所述基础诊断库。
在本实施例中,本实施例二的上述操作已经能够实现服务组件的监控和预警管理,在此基础上,本实施例提供的管理方法,还可以对符合设定条件的报警信息对应的服务组件在没有人为干预的情况下进行自恢复操作。
具体的,首先可以将所述服务组件所对应报警日志信息中的报警级别确定为可恢复级别和不可恢复级别;之后,当所述报警日志信息中的第一元素与所述基础诊断库中二元字符组的第一元素相匹配时,如果所述报警日志信息中的报警级别为可恢复级别,则无需人为干预可以直接对所述服务组件进行自启动,由此不仅实现了服务组件的监控和报警,还实现了对服务组件的自恢复,与现有的管理方法相比,本实施例提供的管理方法更便于运维人员对大数据平台的管理;如果所述报警日志信息中的报警级别为不可恢复级别,则运维人员可以在获取所述服务组件的报警信息后,对所述服务组件进行人为处理,并可以重新编辑所述报警信息形成第一二元字符组,最终可以获取所述第一二元字符组并用所述第一二元字符组替换所述基础诊断库中对应的二元字符组,以实现基础诊断库的信息更新,便于后续使用。
此外,当所述报警日志信息中的第一元素与所述基础诊断库中二元字符组的第一元素不匹配时,运维人员也可以在获取所述服务组件的报警信息后,对所述服务组件进行人为处理,并可以重新编辑所述报警信息形成第二二元字符组,最终可以获取所述第二二元字符组并存放到所述基础诊断库中,进一步实现基础诊断库的信息更新,便于后续使用。
实施例三
图3a为本发明实施例三提供的一种用于大数据平台的管理方法的优选实施例的流程示意图。图3b为本发明实施例三提供的一种大数据平台的框架图,本实施例以图3b所示的大数据平台作为应用背景,如图3b所示的,所述大数据平台中包含的服务组件有:分布式应用协调服务如Zeekooper、跨平台数据信息传递工具如Sqoop、分布式分析引擎如Kylin、通用并行框架如Spark、大数据集运算模型如MapReduce、分布式资源管理器如Yarn、分布式文件系统如HDFS、分布式数据仓库如Hive以及分布式面向列的开源数据库如Hbase等。基于本实施例提供的管理方法,可以实现对上述各服务组件的监控和预警管理。
如图3a所示,本发明实施例三提供的一种用于大数据平台的管理方法的优选实施例,具体包括如下操作:
S301、获取大数据平台中各服务组件的日志信息。
需要说明的是,本实施例以数据流的形式对所述大数据平台中各服务组件进行监控和预警管理。
示例性的,获取大数据平台中各服务组件中相应服务进程的运行日志,并存放于各服务组件在分布式文件系统中对应的日志信息目录下,作为各服务组件的日志信息。如,基于存储路径log_model/hbase_log存储Hbase服务组件中的HMaster服务进程和/或至少一个HRegionServer服务进程的运行日志。
S302、对所述各服务组件的日志信息中日志状态标识进行检测。
示例性的,所述日志状态标识包括运行错误标识、运行警告标识和/或运行正常标识,由此实现对各服务组件中日志信息的监控操作。
S303、确定各服务组件中日志信息的日志状态标识是否符合报警条件,若是,则执行步骤S304;若否,则执行步骤S309。
示例性的,确定所述报警条件为运行错误标识。
S304、根据所述服务组件中符合报警条件的日志信息获取所述服务组件对应的报警日志信息。
示例性的,假设在Hbase对应的目录中获取到一个符合报警条件的日志信息,且所述日志信息的内容表示为:Caused by:org.apache.hadoop.hive.metastore.api.MetaException:Could not connect to meta store using any of the URIs provided.Most recent failure:org.apache.thrift.transport.TTransportException:java.net.ConnectException:Connection refused。
示例性的,所对应报警日志信息的获取过程为:确定预设基础诊断库中的信息格式为[key,value]的键值对格式,基于设定的解释规则解析所述日志信息,可确定所述日志信息中的关键词有hive,metastore以及connect;基于上述关键词可确定所述日志信息的报警级别为1。因此,所述报警日志信息中的key值表示为((hive,metastore,connect),1),所述报警日志信息中的value值表示为上述日志信息的所有内容,因此,所述日志信息对应的报警日志信息表示为[((hive,metastore,connect),1),String],其中,String表示上述日志信息的所有内容。
S305、确定所述服务组件对应的报警日志信息是否与预设的基础诊断库中的数据信息相匹配,若是,则执行步骤S306或步骤S307;若否,则执行步骤S308。
示例性的,可以确定所述基础诊断库中的key值是否包含有((hive,metastore,connect),1),若有,则说明相匹配,可以执行步骤S306或步骤S307;若无,则说明不匹配,需要执行步骤S308。
S306、如果所述服务组件对应报警日志信息中的报警级别为可恢复级别,则重启所述报警日志信息对应的服务组件,并输出所述服务组件的报警信息。
示例性的,所输出的报警信息为基础诊断库中相匹配的[key,value]的键值对信息。
S307、如果所述服务组件对应报警日志信息中的报警级别为不可恢复级别,则输出所述服务组件的报警信息,并获取运维人员编辑的第一报警信息,将所述基础诊断库中相应的报警日志信息替换为所述新报警信息。
示例性的,所输出的报警信息为基础诊断库中相匹配的[key,value]的键值对信息,但是,运维人员根据输出的报警信息对服务组件进行人为处理,并再次对报警信息重新编辑形成第一报警信息,且进一步将所述基础诊断库中相应的报警日志信息替换为所述新报警信息,以便后续使用。
S308、修改所述服务组件对应报警日志信息中的报警级别,将所述报警日志信息作为报警信息输出,并获取运维人员编辑的第二报警信息,并将所述第二报警信息写入所述基础诊断库。
示例性的,首先将报警日志信息中的报警级别修改为设定标记值,以提醒运维人员注意所述报警信息,运维人员根据输出的报警信息对服务组件进行人为处理,并再次对报警信息重新编辑形成第二报警信息,且进一步将所述第二报警信息更新到基础诊断库中,以便后续使用。
S309、输出所述服务组件的状态正常信息。
本发明实施例三提供了一种用于大数据平台的管理方法的优选实施例,由此简单高效地基于日志信息实现了对大数据平台上各服务组件的实时监控和预警,精细了对大数据平台各服务组件的管理粒度;不仅减少了运维管理的人力资源投入,同时也减少了大数据平台所在服务器的资源消耗;此外,还进一步提升了大数据平台的用户体验。
实施例四
图4为本发明实施例四提供的一种用于大数据平台的管理系统的结构框图。该管理系统适用于对大数据平台上运行的各服务组件进行监控和预警的情况,可由软件和/或硬件实现,作为大数据平台的一部分集成在大数据平台中。如图4所示,该管理系统包括:日志信息获取模块41、状态标识检测模块42以及报警信息输出模块43。
其中,日志信息获取模块41,用于获取大数据平台上的服务组件对应的日志信息。
状态标识检测模块42,用于检测所述日志信息中的日志状态标识。
报警信息输出模块43,用于当所述日志状态标识符合预设的报警条件时,根据所述日志状态标识对应的日志信息输出所述服务组件的报警信息。
在本实施例中,该管理系统首先通过日志信息获取模块41获取大数据平台上的服务组件对应的日志信息;然后通过状态标识检测模块42检测所述日志信息中的日志状态标识;最后通过报警信息输出模块43在所述日志状态标识符合预设的报警条件时,根据所述日志状态标识对应的日志信息输出所述服务组件的报警信息。
本发明实施例四提供的一种用于大数据平台的管理系统,能够简单高效地实现对大数据平台上各服务组件的实时监控和预警,精细了对大数据平台各服务组件的管理粒度;此外,该方法不仅减少了运维管理的人力资源投入,也减少了大数据平台所在服务器的资源消耗;同时还进一步提升了大数据平台的用户体验。
进一步的,该管理系统还包括:正常信息输出模块44,用于当所述日志状态标识不符合预设的报警条件时,输出所述服务组件的状态正常信息。
在上述实施例的基础上,所述日志信息获取模块41具体用于:
获取所述大数据平台上服务组件中的至少一个服务进程对应的运行日志;将所述运行日志存储到所述大数据平台的分布式文件系统的指定目录文件中,并将所述指定目录文件中的运行日志作为所述服务组件的日志信息。
进一步的,所述报警信息输出模块43包括:
报警日志确定单元,用于当所述日志状态标识符合预设的报警条件时,将所述日志状态标识对应的日志信息按照预设的基础诊断库的信息格式进行解析,形成报警日志信息;报警信息确定单元,用于根据所述报警日志信息查找所述基础诊断库,确定所述服务组件的报警信息并输出。
在上述优化的基础上,所述报警日志确定单元具体用于:
从所述日志状态标识对应的日志信息中获取至少一个关键词;根据所述至少一个关键词确定所述日志信息对应的报警级别;根据预设的基础诊断库的信息格式创建所述日志信息的二元字符组,形成所述日志信息的报警日志信息,其中,所述二元字符组包括第一元素和第二元素,所述第一元素包括所述至少一个关键词和所述报警级别,所述第二元素包括与所述日志状态标识对应的日志信息。
进一步的,所述报警信息确定单元具体用于:
确定所述报警日志信息中的第一元素是否与所述基础诊断库中二元字符组的第一元素相匹配;如果匹配,则将所述基础诊断库中对应的二元字符组作为报警信息输出;如果不匹配,则将所述报警日志信息中的报警级别修改为设定标记值,并将所述报警日志信息作为报警信息输出。
在上述实施例的基础上,所述报警级别包括可恢复级别和不可恢复级别;相应的,所述管理系统还包括:第一报警处理模块45,具体用于:
在确定所述报警日志信息中的第一元素与所述基础诊断库中二元字符组的第一元素相匹配之后,当所述报警级别为可恢复级别时,重启所述报警日志信息对应的服务组件;当所述报警级别为不可恢复级别时,获取运维人员编辑的第一二元字符组,并将所述基础诊断库中对应的二元字符组替换为所述第一二元字符组。
进一步的,所述管理系统系统还包括:
第二报警处理模块46,用于在确定所述报警日志信息中的第一元素与所述基础诊断库中二元字符组的第一元素不匹配之后,获取运维人员编辑的第二二元字符组,并将所述第二二元字符组写入所述基础诊断库。
在上述实施例的基础上,所述日志状态标识包括运行错误标识、运行警告标识和/或运行正常标识。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!