基于用户访问量以及预测机制的动态副本文件访问方法与流程
本发明属于大数据存储系统技领域,具体是一种动态副本文件访问方法。
背景技术:
随着互联网用户的增多,“大数据”挑战也随之而来。目前数据的规模已经达到了TB级甚至是PB级,这使得数据的维护以及处理变得越来越困难。云计算作为一种新兴的商业计算模式顺应产生,被广泛应用于大数据领域,为用户提供基础设施即服务(IaaS)、平台即服务(PaaS)、软件即服务(SaaS)等各种服务。其中云储存是云计算的存储部分,它将大量类型各异的廉价的存储设备通过网络连接成存储资源池,并将存储和数据服务以统一的接口按需提供给授权用户,具有超大规模、高可扩展性等特点。
在存储系统中,常使用多副本技术以及节点故障自动容错技术来保证文件的高可靠性和可用性。多副本技术是指将一个文件复制多份,并分别存放在不同的存储节点,既避免了由于存储节点发生故障导致文件无法访问的情况,同时也避免由于高访问量造成用户访问延迟的增加。目前副本技术策略大致可以分为静态副本技术和动态副本技术。采用静态副本技术时,每个文件副本数都是固定的,HDFS中通常为3。在静态副本技术中,在高访问量的时候,过少的副本会增加文件的访问延迟;而在低访问量的时候,过多的闲置副本又会导致资源的浪费。动态副本技术则根据用户的需求、带宽等变化来动态地改变文件的副本数。因此相比于静态副本技术,动态副本技术更为常用。
尽管很多科研人员都在研究如何有效的动态的控制文件副本数,才能有效地实现提高文件的可用性、降低文件访问时延以及均衡系统负载等目标,但他们往往忽略了在磁盘上频繁增删文件带来的后果:存在在某一周期时,系统为文件增加了多个副本,而在下一周期时需要删除文件的多个副本,或者先删后增,频繁删除过大的文件时,会对磁盘造成一定的损害。为了降低文件创建和删除的频率,本发明将动态副本技术和预测机制结合在一起,降低文件的访问延迟,同时减少文件的增删频率。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种降低文件的访问延迟,同时减少文件的增删频率,提高大数据文件的处理效率的基于用户访问量以及预测机制的动态副本文件访问方法。本发明的技术方案如下:
一种基于用户访问量以及预测机制的动态副本文件访问方法,其包括以下步骤:
101、预先设置一个文件访问的响应时间阈值td,求取出在响应时间阈值td下存储节点所能处理的文件的最大访问量,从而求取出当前周期文件的副本个数;
102、根据文件的历史访问记录,预测出文件下一周期的访问量,并根据步骤101动态求取出文件当前周期与下一周期的副本个数,并求取出文件的最佳副本个数;
103、在选取存储节点集合进行副本添加或删除时,动态地通过粒子群算法,选取最优的节点集合来放置文件副本的位置。
进一步的,步骤101中求取出在响应时间阈值td下存储节点所能处理的文件的最大访问量包括步骤:
(1)设置响应时间阈值td;
(2)根据文件发送时间公式计算出节点所能处理的文件的最大访问量;
(3)根据用户访问量,求取文件的副本个数。
进一步的,所述步骤(2)具体为:要求访问的响应时间tresponse不超过td,即tresponse≤td,因此,单个存储节点上处理单个文件的访问量不得超过:
tresponse表示访问文件的响应时间;ttransfer表示文件的发送时间;s(i)表示文件i的大小;v(j)表示存储节点j的发送速度;k的最大值为:
其中,td表示某文件上单个访问发送时延的最大值,由用户设定;kmax表示文件在节点上的最大访问量;
假设某文件在存储系统上包含原文件本身在内及副本的个数为Ncurrent,则为了满足每个访问的发送时延不超过td,则文件的最大访问量应为:
Amax=Ncurrent×kmax
其中,Ncurrent表示一文件在存储系统中的副本个数;Amax表示一文件在存储系统中的最大访问量。
进一步的,所述步骤102根据文件的历史访问记录,预测出文件下一周期的访问量采用指数平滑模型预测公式其中,α表示平滑系数;A(t)表示的是第t个周期文件的实际访问量;表示的是第t个周期文件的预测访问量,若当前访问量使得文件需要增加副本数,而由预测得到的下一个周期的访问量使得文件需要删除副本数时,则将不会为文件创建副本,,此时文件的最佳副本数仍保持不变;若当前的与下一个周期的访问量同时使得文件增加或者删除副本数,则取当前的与下一个周期的副本数得平均值作为最佳副本数。
进一步的,所述步骤103通过多目标优化策略选取合理的节点集,包括实现系统的可靠性以及系统负载均衡的双目标优化。
进一步的,衡量实现系统的可靠性为:
其中,SR表示系统的可靠性;R(i)表示文件i的可用性;φ(i,j)表示文件i是否在节点j上,1表示存在,0则表示不存在;pj表示节点j的失效率。
衡量系统负载是否均衡可使用负载变化幅度即标准差SL来描述:
其中,m表示存储节点的个数;SL系统负载变化幅度的标准差值;表示系统中负载的平均值;A(i,j)表示文件i在节点j上的访问量。
进一步的,将目标函数按线性加权法得到一个优化的目标函数以及其约束条件:
其中,S表示目标函数;θ表示目标所占权重,由用户确定;C表示存储节点的最大容量。
本发明的优点及有益效果如下:
1.本发明由用户设定一个响应时间阈值td,要求用户对文件的访问响应时间不得超过td,根据此要求增删文件副本个数,降低文件的发送时延从而满足用户的需求。
2.采用预测机制预测文件未来的访问量,根据当前的以及未来的文件访问量来确定文件增删的副本个数,避免文件增加副本后在下一周期会出现减少副本的情况,减少频繁改动文件副本带来的巨大开销。
3.在选取删除或增加文件副本的存储节点集合时,本发明考虑了文件可用性以及系统负载变化两个因素,保证系统处于文件高可用性,节点负载变化均衡的状态。
附图说明
图1是本发明提供优选实施例的动态副本模型图;
图2为存储系统中的文件访问模型;
图3为本发明的动态副本策略的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明的技术方案如下:
(1)节点处理文件的最大访问量
用户对文件的访问时延,包括文件的响应时间(发送时延)以及传输时延。传输时延的长短通常只与链路的带宽有关,带宽高则传输时延小,现有的带宽能够快速地发送一个文件,因此在本发明中不作考虑。而文件的响应时间通常与多种因素相关。
文件的响应时间由查找时间、旋转时间、发送时间以及等待时间组成。由于现在的文件规模比较大,查找时间和旋转时间远小于发送时间,往往可以忽略不计。因此,第k个访问的响应时间由发送时间以及等待时间两个部分组成:
其中,s(i)表示文件i的大小;
v(j)表示存储节点j的发送速度;
ttransfer表示文件的发送时间;
twaiting(k-1)表示第k个访问在处理前,需等待前k-1个访问处理完成;
tresponse(k)表示某文件上的第k访问的响应时间;
通过DMA或RDMA技术对文件进行发送,可以不需要CPU的参与,不同文件上其访问的等待时间是相对独立的。因此第k个访问的等待时间为:
第k个访问的响应时间可表示为:
本发明设置一个由用户设定的响应时间阈值td,要求访问的响应时间不超过td,即tresponse≤td。因此,单个存储节点上处理对单个文件的访问量不得超过:
k的最大值为:
其中,td表示某文件上单个访问发送时延的最大值,由用户设定;
kmax表示文件在节点上的最大访问量;
假设某文件在存储系统上的副本个数(包含原文件本身)为Ncurrent,则为了满足每个访问的发送时延不超过td,则文件的最大访问量应为:
Amax=Ncurrent×kmax
其中,Ncurrent表示一文件在存储系统中的副本个数;
Amax表示一文件在存储系统中的最大访问量;
因此,文件在节点上的访问量不得超过Amax。当文件的访问量过高,现有的文件副本数无法满足时,需要为文件增加副本;当访问量过低时,删除多余的文件,减少资源的浪费。
(2)文件的最佳副本个数
本发明在动态副本策略中加入预测机制,在每次增删文件副本时,根据文件当前以及未来的访问量来确定副本增删的个数,避免文件增加副本后在下一周期会出现减少副本的情况,降低文件的增删频率。指数平滑模型预测公式被用于根据文件的访问历史记录来计算出文件未来的文件访问量:
其中,α表示平滑系数;
A(t)表示的是第t个周期文件的实际访问量;
表示的是第t个周期文件的预测访问量;
若当前访问量使得文件需要增加副本数,而由预测得到的未来的访问量使得文件需要删除副本数时,则本发明将不会为文件创建副本;若当前的与未来的访问量同时使得文件增加或者删除副本数,则考虑取其平均值作为最佳副本数。
(3)文件副本放置位置的选取
为一组文件增加或删除副本数时,本发明通过多目标优化策略选取合理的节点集。本发明重点考虑实现系统的可靠性以及系统负载均衡的双目标优化。
系统的可靠性为:
其中,SR表示系统的可靠性;
R(i)表示文件i的可用性;
φ(i,j)表示文件i是否在节点j上,1表示存在,0则表示不存在;
pj表示节点j的失效率;
衡量系统负载是否均衡可使用负载变化幅度(标准差)来描述:
其中,SL系统负载变化幅度的标准差值;
表示系统中负载的平均值;
A(i,j)表示文件i在节点j上的访问量;
当SR值越大时,表示文件的可靠性越高;当SL值越小时,表示节点的负载较均衡稳定。将目标函数按线性加权法得到一个优化的目标函数以及其约束条件:
其中,S表示目标函数;
θ表示目标所占权重,由用户确定;
C表示存储节点的最大容量;
本发明采用粒子群算法动态地选取副本放置的集合,使得S取得最优值。
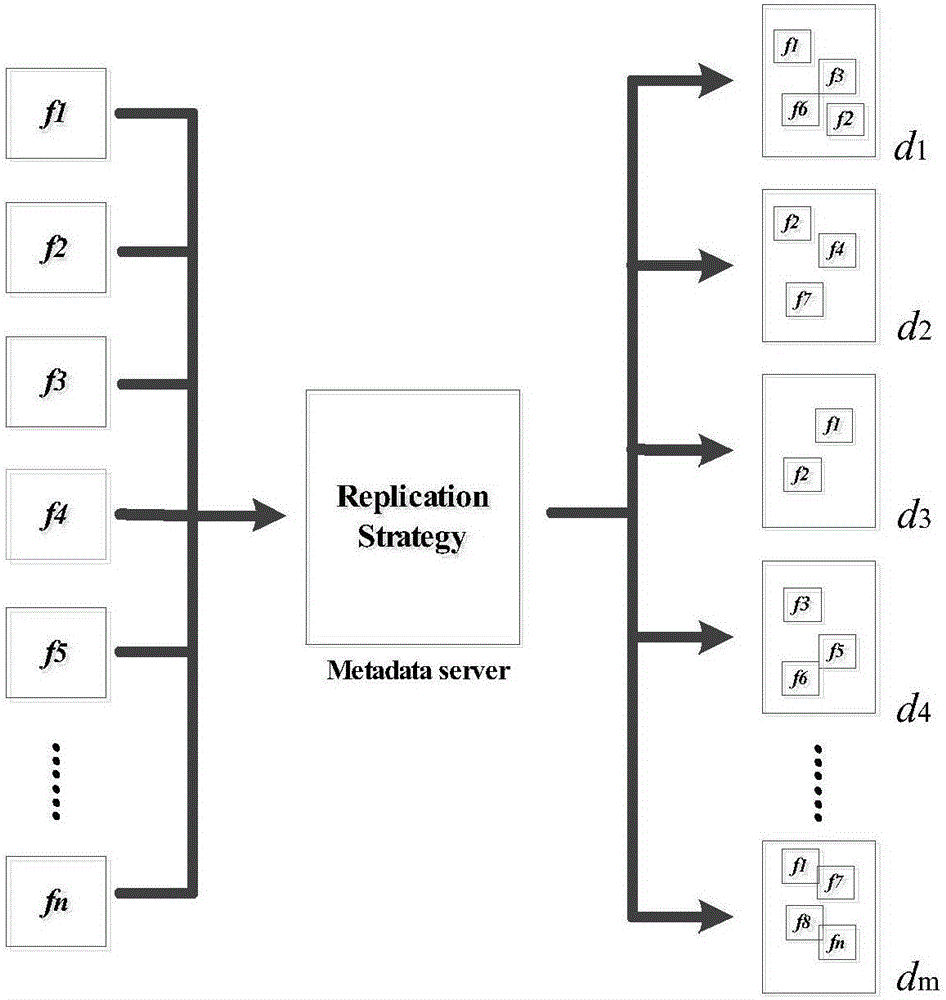
图1展示了动态副本策略的模型,将云存储的结构抽象成由多个性能相同的存储节点集合组成,单个文件在云存储系统中均有多个副本分别分布在不同的节点上,以保证文件的高可用性并减少用户的访问延迟。
参考图2,给出了文件在存储系统中的访问模型。由于DMA与RDMA技术的发展,使得文件的传输不再需要CPU的介入。因此每个访问请求的文件传输按照访问到达的先后顺序进行排列,如图中的队列,第k个访问需等待前k-1访问处理完毕才可以进行处理。
参考图3,本发明所述的动态副本策略流程图。首先,本发明设置一个用户阈值,根据当前的文件访问量,计算出文件当前所需要增加或者删除的副本数N*;然后根据文件的历史访问记录,预测文件下一周期的访问量,并计算相应增加或者删除的副本数Np;其次,当文件在前后两周期都需要增加副本时,即N*>0,Np>0,为文件增加副本;或者当文件在前后两周期都需要删除副本时,即N*<0,Np<0,为文件删除副本。取这个数的平均值作为文件应增加或删除的副本数;最后,采用粒子群算法来求取副本存储的最佳结点集合,以提高文件可用性以及平衡节点的负载为目的,根据用户需求来设置这两个目标的权重。
本发明在大数据存储系统中,采用动态副本技术以及有效的预测机制,从而实现降低文件的访问延迟、减少文件的增删频率等目标。同时利用粒子群算法动态确定副本增删的存储结点集合,使得增删文件后,系统处于负载均衡以及文件高可靠性的状态。
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!