基于内存的MapReduce引擎数据处理方法和装置与流程
本发明涉及到MapReduce引擎数据处理领域,特别是涉及到一种基于内存的MapReduce引擎数据处理方法和装置。
背景技术:
自大数据处理技术Hadoop问世以来,其中的数据处理引擎MapReduce性能的优化一直是业界比较关心的问题。
以reduce为例,每个Map输出文件(MOF)中的整个分区(partition,P1)会被拷贝到Reduce端,然后所有分区(P1,P1,P1)会合并成为一个有序的总的集合(P1),最后做Reduce,由于数据量的不可控,上述拷贝环节内存溢出不可避免,随后合并及进行Reduce过程中也会产生更多硬盘IO的访问。
目前业界在MapReduce中减少IO的方法主要是用压缩(compression)与结合(combination),基于内存的mapreduce就是mellanox公司的UDA(Unstructured DataAccelerator)做过流水线化(Pipelining)的尝试,但是它主要是基于硬件的加速技术,而且由于shuffle协议的设计限制,每个批次只shuffle少量数据,没有实现大吞吐量。
技术实现要素:
本发明的主要目的为提供一种通过软件实现的数据大吞吐量的基于内存的MapReduce引擎数据处理方法和装置。
为了实现上述发明目的,本发明首先提出一种基于内存的MapReduce引擎数据处理方法,包括:
将每个分区的Map输出结果数据进行粒度切割,并将切割后的粒度进行排序;
将每个分区切割后的粒度进行多批次shuffle,并将各批次的数据依次进行拷贝、合并和reduce的流水线式数据处理,将reduce进程处理的数据控制在内存中。
进一步地,所述将每个分区切割后的粒度进行多批次shuffle,并将各批次的数据依次进行拷贝、合并和reduce的流水线式数据处理,将reduce进程处理的数据控制在内存中的步骤,包括:
Reduce进程的每个处理过程为自主运行的子线程,各子线程之间通过共享的先进先出异步的消息队列进行通信。
进一步地,所述将每个分区切割后的粒度进行多批次shuffle,并将各批次的数据依次进行拷贝、合并和reduce的流水线式数据处理,将reduce进程处理的数据控制在内存中的步骤,包括:
所述流水线式数据处理多批次并发运行,根据可用内存的大小除以每个批次配置的内存大小控制并发的批次数。
进一步地,所述将每个分区的Map输出结果数据进行粒度切割,并将切割后的粒度进行排序的步骤之前,包括:
通过所述流水线式处理指定批次数据后,同步所有reduce一次;
所述将每个分区的Map输出结果数据进行粒度切割,并将切割后的粒度进行排序的步骤之后,包括:
按相对bucket ID排序来存MOF文件,相应地按同样顺序来预缓存。
进一步地,所述将每个分区切割后的粒度进行多批次shuffle,并将各批次的数据依次进行拷贝、合并和reduce的流水线式数据处理,将reduce进程处理的数据控制在内存中的步骤,包括:
粒度内部数据选择性地排序,如果粒度内部数据未排序,则拷贝后在reduce端进行排序。
本发明还提供一种基于内存的MapReduce引擎数据处理装置,包括:
切割单元,用于将每个分区的Map输出结果数据进行粒度切割,并将切割后的粒度进行排序;
流水线单元,用于将每个分区切割后的粒度进行多批次shuffle,并将各批次的数据依次进行拷贝、合并和reduce的流水线式数据处理,将reduce进程处理的数据控制在内存中。
进一步地,所述流水线单元,包括:
共享通信模块,用于Reduce进程的每个处理过程为自主运行的子线程,各子线程之间通过共享的先进先出异步的消息队列进行通信。
进一步地,所述流水线单元,包括:
并发运行模块,用于所述流水线式数据处理多批次并发运行,根据可用内存的大小除以每个批次配置的内存大小控制并发的批次数。
进一步地,所述基于内存的MapReduce引擎数据处理装置,还包括:
同步单元,通过所述流水线式处理指定批次数据后,同步所有reduce一次;
存储单元,按相对bucket ID排序来存MOF文件,相应地按同样顺序来预缓存。
进一步地,所述流水线单元,包括:
粒度内部数据处理模块,用于粒度内部数据选择性地排序,如果粒度内部数据未排序,则拷贝后在reduce端进行排序。
本发明的基于内存的MapReduce引擎数据处理方法和装置,通过纯软件方式对MapReduce的reduce进程进行流水线化(pipelining)设计,即对数据进行了分批并发处理,每个批次的shuffle或拷贝,合并(merge)与reduce可控制在内存中(In-Memory)中进行,极大地减少了IO的访问与延迟;还可以根据可用内存的多少来调节并发批次的数目,从而提高了mapreduce引擎的吞吐量与整体性能,实测结果是原来的1.6倍-2倍以上。
附图说明
图1为本发明一实施例的基于内存的MapReduce引擎数据处理方法的流程示意图;
图2为本发明一实施例的流水线化的Reduce进程示意图;
图3为本发明一实施例的基于内存的MapReduce引擎数据处理方法的流程示意图;
图4为本发明一实施例的Reduce进程间按批次同步处理基于zookeeper的示意图;
图5为本发明一实施例的bucket ID的映射关系的示意图;
图6为本发明一实施例的基于内存的MapReduce引擎数据处理装置的结构示意框图;
图7为本发明一实施例的流水线单元的结构示意框图;
图8为本发明一实施例的基于内存的MapReduce引擎数据处理装置的结构示意框图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
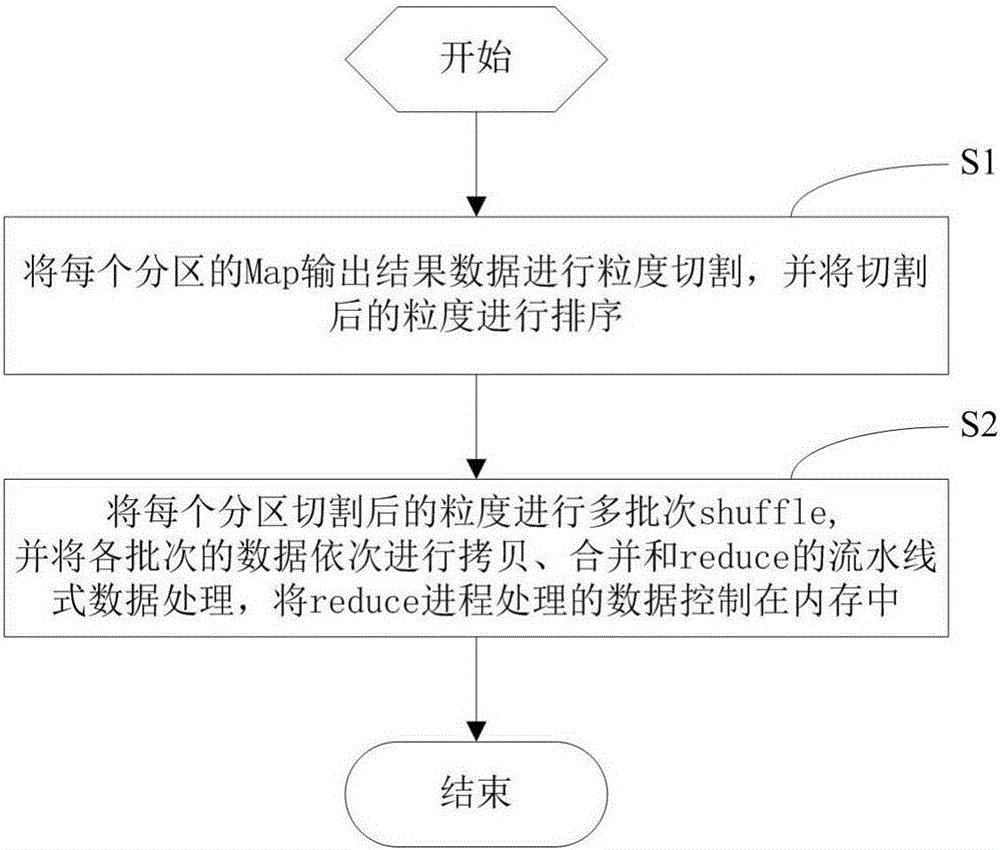
参照图1,本发明实施例提供一种基于内存的MapReduce引擎数据处理方法,包括步骤:
S1、将每个分区的Map输出结果数据进行粒度切割,并将切割后的粒度进行排序;
S2、将每个分区切割后的粒度进行多批次shuffle,并将各批次的数据依次进行拷贝、合并和reduce的流水线式数据处理,将reduce进程处理的数据控制在内存中。
如上述步骤S1所述,对原来每个分区(partition)的数据进行了更细粒度(bucket)的切割,为了实现后续流水化的数据处理,bucket之间必须有序。本实施例中,
如上述步骤S2所述,为了实现流水化作业,相比原生的shuffle整个分区的协议,新的shuffle协议会把一个分区进行多批次(pass)shuffle,每个批次只按次序拷贝原来整个分区数据的子集(bucket),这样通过调整bucket的大小,reduce进程的处理的数据就可控制在内存中。通过纯软件方式对MapReduce的reduce进程进行流水线化(pipelining)设计,即对数据进行了分批次处理,每个批次的shuffle或拷贝,合并(merge)与reduce可控制在内存中(In-Memory)中进行,极大地减少了IO的访问与延迟;还可以根据可用内存的多少来调节并发批次的数目,从而提高了mapreduce引擎的吞吐量与整体性能。
参照图2,本实施例中,上述将每个分区切割后的粒度进行多批次shuffle,并将各批次的数据依次进行拷贝、合并和reduce的流水线式数据处理,将reduce进程处理的数据控制在内存中的步骤S2,包括:
S21、Reduce进程的每个处理过程为自主运行的子线程,各子线程之间通过共享的先进先出异步的消息队列进行通信。
如上述步骤S21所述,拷贝线程(fetcher)完成后会通知合并线程(merger),合并线程完成后会通知reduce线程(reducer),由于每个批次间保持有序,reducer可以不必等剩余的数据拷贝过来而直接做reduce计算,整个过程中,数据访问可以控制在内存中进行,延迟会大幅度地降低。
本实施例中,上述将每个分区切割后的粒度进行多批次shuffle,并将各批次的数据依次进行拷贝、合并和reduce的流水线式数据处理,将reduce进程处理的数据控制在内存中的步骤S2,包括:
S22、上述流水线式数据处理多批次并发运行,根据可用内存的大小除以每个批次配置的内存大小控制并发的批次数。
如上述步骤S22所述,根据内存的可用大小适配地进行并发运行,相比原生方法,吞吐量极大提高。
本实施例中,上述将每个分区切割后的粒度进行多批次shuffle,并将各批次的数据依次进行拷贝、合并和reduce的流水线式数据处理,将reduce进程处理的数据控制在内存中的步骤,包括:
S23、上述粒度内部数据选择性地排序,如果粒度内部数据未排序,则拷贝后在reduce端进行排序。
如上述步骤S23所述,如果粒度内部的数据不排序,则可以拷贝后在reduce端进行排序,这样就把一些排序的cpu消耗从map端转移到了reduce端,这对map端cpu成为瓶颈的作业具有减压帮助。
参照图3、图4和图5,本实施例中,上述将每个分区的Map输出结果数据进行粒度切割,并将切割后的粒度进行排序的步骤S1之前,包括:
S11、同步单元,通过所述流水线式处理指定批次数据后,同步所有reduce一次;
上述将每个分区的Map输出结果数据进行粒度切割,并将切割后的粒度进行排序的步骤S1之后,包括:
S12、存储单元,按相对bucket ID排序来存MOF文件,相应地按同样顺序来预缓存。
如上述步骤S11所述,由于reduce启动顺序的差异化,以及节点计算能力还有网络的差异化,每个reduce运行的批次(pass)差异化有时会很明显,比如一个reduce在运行pass 0,另一个reduce在运行pass 5,如此对于MOF的按批次的预缓存是个考验,内存可能不够cache这么多从0到5批次的数据,需要一种同步机制来锁住(lock)批次,等所有reduce完成相同批次的处理后,统一进入下一批次的处理,以保证MOF的cache被击中(hit)。参照图4,由于各个reduce可能分布在不用的节点上,本实施例采用了hadoop系统中的节点同步机制zookeeper来实现,控制每隔开指定数量的批次同步一次所有reduce,也就是说reduce之间差异化不会超过指定数量个批次。
参照图5,如上述步骤S12所述,由于多批次shuffle,每个reduce都从相对的bucket 0开始按顺序进行,我们按相对bucket ID排序来存MOF文件,相应地按同样顺序来预缓存(cache)的新方法,有效地减少了随机IO的几率,增加了cache击中(hit)几率。
本实施例中,由于流水线化后成了基于内存的计算,内存的使用与管理对性能的影响也非常大,基于Java虚拟机(JVM)管理的内存受垃圾回收(Garbbage Collection)性能的限制,明显不适合本发明。本发明采用了从系统直接分配内存然后自己管理,而不使用JVM。
在一具体实施例中,做一种对比试验,进行4、实验数据比较分析,如下:
(1)测试环境:4数据节点
hadoop软件-三大供应商CDH,HDP,MAPR结果类似
CPU 2x8核
RAM 128GB
Disk 2TBx12
(2)实测结果,如下表:
从上表可以看出,本发明显著提高了MapReduce自身的数据处理能力,大概是原来的1.6倍-2倍。
本实施例的基于内存的MapReduce引擎数据处理方法,通过纯软件方式对MapReduce的reduce进程进行流水线化(pipelining)设计,即对数据进行了分批并发处理,每个批次的shuffle或拷贝,合并(merge)与reduce可控制在内存中(In-Memory)中进行,极大地减少了IO的访问与延迟;还可以根据可用内存的多少来调节并发批次的数目,从而提高了mapreduce引擎的吞吐量与整体性能,实测结果是原来的1.6倍-2倍以上。
参照图6,本发明实施例还提供一种基于内存的MapReduce引擎数据处理装置,包括:
切割单元10,用于将每个分区的Map输出结果数据进行粒度切割,并将切割后的粒度进行排序;
流水线单元20,用于将每个分区切割后的粒度进行多批次shuffle,并将各批次的数据依次进行拷贝、合并和reduce的流水线式数据处理,将reduce进程处理的数据控制在内存中。
如上述切割单元10,对原来每个分区(partition)的数据进行了更细粒度(bucket)的切割,为了实现后续流水化的数据处理,bucket之间必须有序。本实施例中,
如上述流水线单元20,为了实现流水化作业,相比原生的shuffle整个分区的协议,新的shuffle协议会把一个分区进行多批次(pass)shuffle,每个批次只按次序拷贝原来整个分区数据的子集(bucket),这样通过调整bucket的大小,reduce进程的处理的数据就可控制在内存中。通过纯软件方式对MapReduce的reduce进程进行流水线化(pipelining)设计,即对数据进行了分批次处理,每个批次的shuffle或拷贝,合并(merge)与reduce可控制在内存中(In-Memory)中进行,极大地减少了IO的访问与延迟;还可以根据可用内存的多少来调节并发批次的数目,从而提高了mapreduce引擎的吞吐量与整体性能。
参照图7,本实施例中,上述流水线单元20,包括:
共享通信模块21,用于Reduce进程的每个处理过程为自主运行的子线程,各子线程之间通过共享的先进先出异步的消息队列进行通信。
如上述共享通信模块,拷贝线程(fetcher)完成后会通知合并线程(merger),合并线程完成后会通知reduce线程(reducer),由于每个批次间保持有序,reducer可以不必等剩余的数据拷贝过来而直接做reduce计算,整个过程中,数据访问可以控制在内存中进行,延迟会大幅度地降低。
本实施例中,上述流水线单元20,包括:
并发运行模块22,用于所述流水线式数据处理多批次并发运行,根据可用内存的大小除以每个批次配置的内存大小控制并发的批次数。
如上述并发运行模块,根据内存的可用大小适配地进行并发运行,相比原生方法,吞吐量极大提高。
本实施例中,上述流水线单元20,包括:
粒度内部数据处理模块23,用于粒度内部数据选择性地排序,如果粒度内部数据未排序,则拷贝后在reduce端进行排序。
如上述粒度内部数据处理模块23,如果粒度内部的数据不排序,则可以拷贝后在reduce端进行排序,这样就把一些排序的cpu消耗从map端转移到了reduce端,这对map端cpu成为瓶颈的作业具有减压帮助。
参照图8,本实施例中,上述基于内存的MapReduce引擎数据处理装置,还包括:
同步单元110,通过所述流水线式处理指定批次数据后,同步所有reduce一次;
存储单元120,按相对bucket ID排序来存MOF文件,相应地按同样顺序来预缓存。
如上述同步单元110,由于reduce启动顺序的差异化,以及节点计算能力还有网络的差异化,每个reduce运行的批次(pass)差异化有时会很明显,比如一个reduce在运行pass 0,另一个reduce在运行pass 5,如此对于MOF的按批次的预缓存是个考验,内存可能不够cache这么多从0到5批次的数据,需要一种同步机制来锁住(lock)批次,等所有reduce完成相同批次的处理后,统一进入下一批次的处理,以保证MOF的cache被击中(hit)。参照图4,由于各个reduce可能分布在不用的节点上,本实施例采用了hadoop系统中的节点同步机制zookeeper来实现,控制每隔开指定数量的批次同步一次所有reduce,也就是说reduce之间差异化不会超过指定数量个批次。
参照图5,如上述存储单元120,由于多批次shuffle,每个reduce都从相对的bucket 0开始按顺序进行,我们按相对bucket ID排序来存MOF文件,相应地按同样顺序来预缓存(cache)的新方法,有效地减少了随机IO的几率,增加了cache击中(hit)几率。
本实施例中,由于流水线化后成了基于内存的计算,内存的使用与管理对性能的影响也非常大,基于Java虚拟机(JVM)管理的内存受垃圾回收(Garbbage Collection)性能的限制,明显不适合本发明。本发明采用了从系统直接分配内存然后自己管理,而不使用JVM。
在一具体实施例中,做一种对比试验,进行4、实验数据比较分析,如下:
(1)测试环境:4数据节点
hadoop软件-三大供应商CDH,HDP,MAPR结果类似
CPU 2x8核
RAM 128GB
Disk 2TBx12
(2)实测结果,如下表:
从上表可以看出,本发明显著提高了MapReduce自身的数据处理能力,大概是原来的1.6倍-2倍。
本实施例的基于内存的MapReduce引擎数据处理装置,通过纯软件方式对MapReduce的reduce进程进行流水线化(pipelining)设计,即对数据进行了分批并发处理,每个批次的shuffle或拷贝,合并(merge)与reduce可控制在内存中(In-Memory)中进行,极大地减少了IO的访问与延迟;还可以根据可用内存的多少来调节并发批次的数目,从而提高了mapreduce引擎的吞吐量与整体性能,实测结果是原来的1.6倍-2倍以上。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!