基于分数阶微积分与广义逆神经网络的手写数字识别方法与流程
本发明涉及模式识别的技术领域,尤其是一种基于分数阶微积分与广义逆神经网络的手写数字识别方法。
背景技术:
随着人工智能、信息检索和海量数据处理等技术的发展,模式识别成为了研究热点。在模式识别中,手写数字的识别因其计算复杂,识别率成为亟待解决的问题。在手写数字的识别中知识和经验的利用是必不可少的,然而知识的获取确是当前面临的瓶颈问题,特别是人脑的知识获取过程几乎是一种潜在的过程,神经网络作为一种抽取不易明确表达的知识和经验的方法在模式识别领域发挥着越来越重要的作用。
目前,传统的神经网络学习方法---单隐藏层前馈神经网络(Single-hidden Layer Feed-forward Neural Network,SLFN)已经在模式识别领域取得了广泛的应用,但传统学习方法的训练速度远远不能满足实际模式识别的需要,成为制约其发展的主要瓶颈。产生这种情况的主要原因是:传统的神经网络学习方法中的误差反向传播方法(Back Propagation,BP)主要基于梯度下降的思想,需要多次迭代,网络的所有参数都需要在训练过程中迭代确定,因此该算法应用于模式识别领域所产生的计算量和搜索空间很大。
针对传统的神经学习方法的不足,黄广斌提出来了超限学习机(Extreme Learning Machine,ELM)理论,ELM是的一种新型的、快速有效的单隐层前馈神经网络的学习算法,只需要设置合适的网络隐层节点个数,在执行过程中只需要为网络的输入权值和隐藏层偏差进行随机赋值,不需要再进行调整,然后输出层权值的最优解通过最小二乘法得到。整个过程一次完成,无需迭代,因此具有参数选择容易、因此具有学习速度极快(是BP算法的100倍以上)且泛化性能好的优点。但是,传统ELM算法为了弥补随机选取的隐层节点参数,往往需要较多的隐层节点个数。
俞栋等人发表的《Efficient and effective algorithms for training single-hidden-layer neural networks》将BP算法和ELM算法相结合,提出了一种用梯度下降法来选择合适的隐层节点输入参数的方法。这种算法使用最速下降法来更新从输入层到隐层之间的权值,优化网络结构,在达到好的精度前提下,减少了隐层节点个数。然而,将BP算法和ELM算法相结合,提出了一种用梯度下降法来选择合适的隐层节点输入参数的方法。这种算法使用最速下降法来更新从输入层到隐层之间的权值,优化网络结构,在达到好的精度前提下,减少了隐层节点个数。
因此,在现有的手写数字的识别中,传统的基于整数阶梯度下降法的神经网络在训练时速度缓慢,精度较低;ELM算法虽然速度快,但所需要的网络隐层节点数过多;而基于最速下降法的ELM算法虽然已经得到改进,但由于用的是整数阶导数,精度有待提高。
技术实现要素:
本发明的目的是为克服上述现有技术的不足,提供一种基于分数阶微积分与广义逆神经网络的手写数字识别方法。
为实现上述目的,本发明采用下述技术方案:
基于分数阶微积分与广义逆神经网络的手写数字识别方法,包括以下步骤:
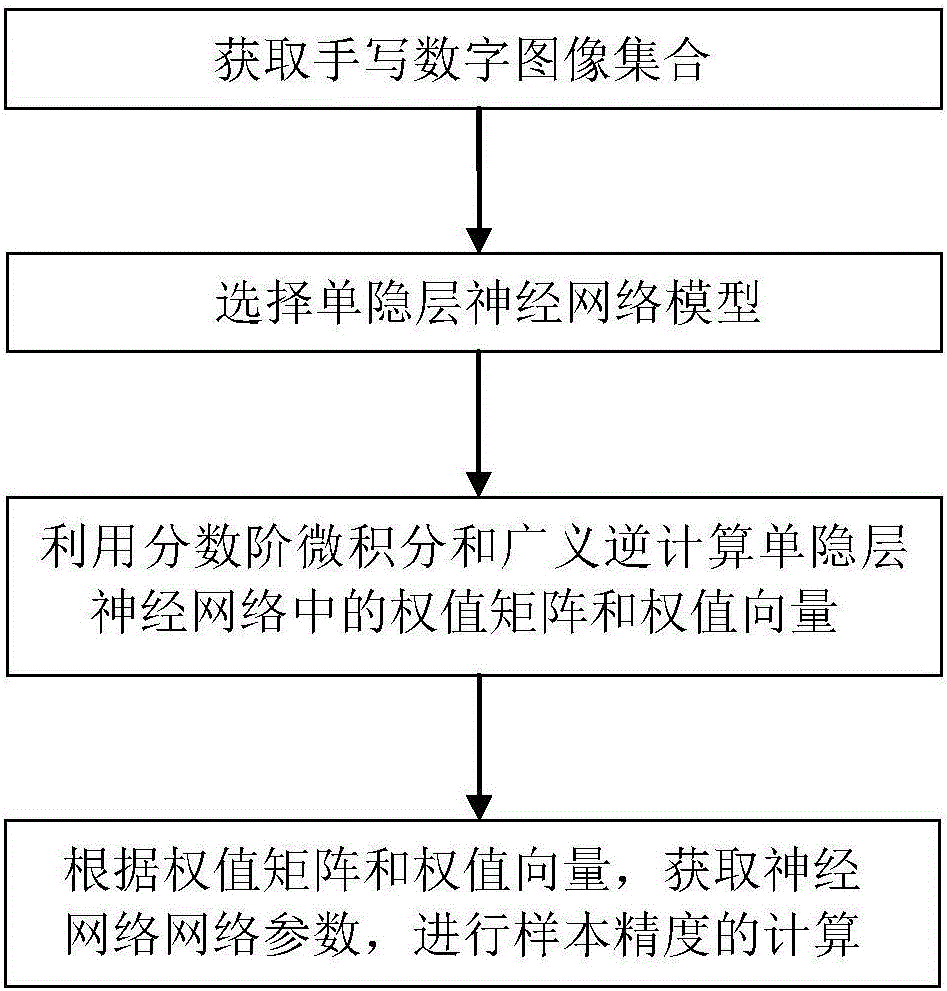
步骤一:获取手写数字图像集合,所述手写数字图像集合包括训练集合与待识别集合;
步骤二,根据所述手写数字图像集合,选择单隐层神经网络模型;
步骤三,利用分数阶微积分和广义逆计算单隐层神经网络中的权值矩阵和权值向量;
步骤四:根据所述权值矩阵和所述权值向量,获取神经网络网络参数,进行样本精度的计算。
优选的,所述步骤三包括以下子步骤:
步骤S31:初始化输入层到隐层的权值矩阵,获取初始权值矩阵V0;
步骤S32:对初始权值矩阵V0进行优化。
进一步优选的,所述步骤S32优化步骤如下:
步骤S321:设置最大迭代次数K并初始迭代次数k=0;
步骤S322:利用最小化误差函数方法求解隐层到输出层的网络权值U;
式中,C表示正则化系数,G表示隐层输出矩阵,O表示训练集的理想输出矩阵;
步骤S323:若k<K,则执行步骤四,否则顺序执行步骤S324;
步骤S324:计算误差函数关于连接输入层和隐层的权值矩阵V的分数阶梯度,分数阶梯度导数公式为:
式中,α表示分数阶数;c表示连接输入层和隐层的权值矩阵V中元素的最小值;Γ(·)表示Gamma函数;
步骤S325:利用更新函数对步骤S324中的权值矩阵进行更新,更新函数表达式为:
式中,学习率ηk为常数;
步骤S326:迭代次数加一,返回执行步骤S322。
进一步优选的,所述步骤S325中,学习率ηk通过线搜索的方式获得。
求解从隐层到输出层旳权值时,采用了广义逆的方法,无需迭代,一步求输出权值的最小范数最小二乘解,相比于基于梯度下降法的相关算法(如BP算法)训练速度要快;
本发明的有益效果是:
1.本发明在进行模式识别中的手写数字图像的识别精度高:因为本发明在优化输入权值矩阵时运用了分数阶导数,由于分数阶导数与整数阶相比,优点是具有记忆性和遗传性,且对于一些复杂的系统,采用整数阶系统来描述其描述精度相对较低,并不能准确反映系统性能,因此本发明比基于整数阶求导的梯度下降算法精度高,能够较为准确地反应神经网络模型的性能;
2.本发明在进行模式识别中的手写数字图像识别时样本训练速度快且隐层节点数少:因为本发明对权值的迭代优化,在达到相同训练精度的前提下,本发明所需要的隐层节点数大大少于超限学习机算法所需要的隐层节点数;
在求解从隐层到输出层旳权值时,采用了广义逆的方法,无需迭代,一步求输出权值的最小范数最小二乘解,因此本发明比基于梯度下降法的相关算法(如BP算法)训练速度要快;
3.本发明在进行模式识别中的手写数字图像识别时有效降低训练样本中存在的噪声:本发明引入参数C,使得神经网络模型可以根据数据集的特点进行微调,从而得到更好的泛化性能,增强了系统的可控性,同时,正则化项可以降低数据集中存在的噪声,达到降噪的目的。
附图说明
图1是本发明结构示意图;
图2是本发明与传统神经网络建模方法的曲线图;
具体实施方式
下面结合附图和实施例对本发明进一步说明。
本实施例利用本发明中的基于分数阶微积分与广义逆神经网络的手写数字识别方法对手写数字进行模式识别,并且将其训练精度与LM算法、USA算法进行比较。USA算法是文献《Efficient and effective algorithms for training single-hidden-layer neural networks》中的提出的算法,该算法是结合了整数阶最速下降法和广义逆的神经网络学习算法。
分数阶微积分(Fractional Derivatives and Integrals,或Fraction Calculus,简写为FC)即指函数对变量非整数阶求导或积分,是古典微积分理论的自然推广,也是数学分析的一个重要的分支。一直以来,它在数学领域得到很大的发展。近年来,分数阶理论逐步应用于在电磁、信号处理、量子演变等实际复杂系统方面。许多研究者指出,分数阶具有能够很好地描述实际处理过程的记忆性和遗传性,分数阶系统甚至具有无限的记忆。考虑到这些方面,将分数阶理论引入到模式识别中,与神经网络理论相结合,即在神经网络模型中植入记忆模块,是值得研究的课题。神经网络本身的自学习性、自适应性、容错性、鲁棒性等性质也使得其在实际应用中具有很大的优势。综上而言,不管是在算法还是应用方面,将神经网络与分数阶理论结合使用都具有研究价值。
MNIST数据集是Google实验室的Corinna Cortes和纽约大学柯朗研究所的Yann LeCun建立的一个手写数字模式识别数据库,训练样本有60,000张手写0-9的数字图像,测试样本有10,000张。每张图片灰度级都是8,且每张图片可以使用一个784大小的向量表征。
利用本发明中的基于分数阶微积分与广义逆神经网络的手写数字识别方法对MNIST数据集进行建模,本算法采用了2/3分数阶为例,也可选用其他阶数。
如图1所示,基于分数阶微积分与广义逆神经网络的手写数字识别方法,包括以下步骤:
步骤一:从MNIST数据集中获取手写数字图像集合,所述手写数字图像集合包括训练集合与待识别集合;
步骤二,根据所述手写数字图像集合,选择单隐层神经网络模型;
步骤三,利用分数阶微积分和广义逆计算单隐层神经网络中的权值矩阵和权值向量;
步骤四:根据权值矩阵和权值向量,获取神经网络网络参数,进行样本精度的计算。
优选的,所述步骤二中单隐层神经网络模型为:
单隐层神经网络中输入层,隐层和输出层神经元个数分别为p,n,m,从获取手写数字图像集合中给定j个输入样本xj∈Rp,相应的理想输出样本为Oj∈R,j=1,2,…,J;
设g:和f:R→R分别为隐层单元和输出层的激活函数,连接输入层和隐层的权值矩阵为V=(vij)n×p,记Vi=(vi1,vi2,…,vip)T∈Rp,i=1,2,…,n,连接隐层和输出层的权值向量为U=(uij)n×m,记Ui=(ui1,ui2,…,uip)T∈Rm,i=1,2,…,n,网络的最终输出即实际输出为Y=f(UTG(Vx)),神经网络模型误差函数为
优选的,所述步骤三包括以下子步骤:
步骤S31:初始化输入层到隐层的权值矩阵,获取初始权值矩阵V0;
步骤S32:对初始权值矩阵V0进行优化。
进一步优选的,所述步骤S32优化步骤如下:
步骤S321:设置最大迭代次数K并初始迭代次数k=0;
步骤S322:利用最小化误差函数方法求解隐层到输出层的网络权值U;
式中,C表示正则化系数,G表示隐层输出矩阵,O表示训练集的理想输出矩阵;
加入上述正则化项后,神经网络的数学模型可表示为:
上式是条件极值问题,通过拉格朗日方程转换为无条件极值问题进行求解:
其中α=[α1,α2,…,αn],αj∈Rm(j=1,2,…,n)代表拉格朗日乘子。
求拉格朗日方程的梯度并令其为0:
解上述方程组,得到:
本发明引入参数C,使得神经网络模型可以根据数据集的特点进行微调,从而得到更好的泛化性能,增强了系统的可控性,同时,正则化项可以降低数据集中存在的噪声,达到降噪的目的。
步骤S323:若k<K,则执行步骤四,否则顺序执行步骤S324;
步骤S324:计算误差函数关于连接输入层和隐层的权值矩阵V的分数阶梯度,分数阶梯度导数公式为:
式中,α表示分数阶数;本实施例中的c表示连接输入层和隐层的权值矩阵V中元素的最小值;Γ(·)表示Gamma函数;
权值ui的修正量可写为如下形式:
根据Caputo分数阶定义,得到:
因此,分数阶梯度导数公式为:
步骤S325:利用更新函数对步骤S324中的权值矩阵进行更新,更新函数表达式为:
式中,学习率ηk为常数;
步骤S326:k=k+1,返回执行步骤S322。
通过本发明中步骤四计算出测试样本的精度,并且与USA算法和ELM算法对测试样本的精度值进行比较,实验结果如图2所示。
从图2中可以看出,对于相同的隐层节点个数,本发明算法的测试精度高于USA算法和ELM算法。实验结果说明本发明算法有效的优化了初始权值,使网络在相同的隐层节点个数下,得到更高的训练精度。
本发明在优化输入权值矩阵时运用了分数阶导数,由于分数阶导数与整数阶相比,优点是具有记忆性和遗传性,且对于一些复杂的系统,采用整数阶系统来描述其描述精度相对较低,并不能准确反映系统性能。而大量的研究表明对于各种实际系统,分数阶模型的描述往往比整数阶模型更加准确。因此本发明比基于整数阶求导的梯度下降算法精度高。
本发明对权值通过迭代方式进行优化,因此在达到相同训练精度的前提下,本发明所需要的隐层节点数大大少于超限学习机算法所需要的隐层节点数。
本发明在求解从隐层到输出层旳权值时,采用了广义逆的方法,无需迭代,一步求输出权值的最小范数最小二乘解。因此本发明比基于梯度下降法的相关算法(例如BP算法)训练速度要快。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!