一种基于K_means算法解决作业车间工艺瓶颈问题的制作方法
本发明涉及调度领域,具体地涉及用算法解决作业车间工艺瓶颈问题。
背景技术:
在企业的整个经营过程中,总有某一个环节制约着企业的产销率,我们将其称为“瓶颈”。企业的目标就是在现在或将来赚取更多的利润,所以要不断的进行改进和突破,让瓶颈不再成为企业增收的障碍。但是在改进的过程中,日的瓶颈消失了,新的瓶颈又将产生。所以对企业来说,对瓶颈的改造和突破是一个循环往复、持续改进的过程。
通过对以上定义的分析,可以发现,判别某资源是否为瓶颈资源时,有以下六种典型情况:
1.部分生产资源的生产能力低于市场需求。
2.所有生产资源的生产能力低于市场需求。
3.所有生产资源的生产能力均高于市场需求。
4.添加新的生产资源或改进工艺时,对瓶颈资源产生的影响。
5.通过外包加工提高生产能力时,对瓶颈资源产生的影响。
6.通过营销等措施使市场需求提高时,对瓶颈资源产生的影响。
约束理论认为应该平衡系统中的物流,而不是平衡系统中的能力,那些占极少数的瓶颈资源是控制物流的关键,决定了占大多数的非瓶颈资源的利用程度,同时决定了系统的有效产出。因此,理论的工具、原则就成为瓶颈资源识别的关键技术之一。本章主要研究瓶颈资源的识别方法,以便科学合理、快速有效地识别出系统中的瓶颈资源。瓶颈资源限制了整个系统的有效产出,是系统能力最薄弱的地方。
K_means算法在大量数据处理中有着非常广泛的应用,它的主要思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使生成的每个聚类内紧凑,类间独立。K_means算法有计算时间短、速度快、容易解释等优点。但是对异常值敏感、对一些问题的解不够精确。
技术实现要素:
针对现有技术的上述不足,本发明要解决的技术问题是提供一种基于K_means算法解决作业车间工艺瓶颈问题。
本发明的目的是克服现有技术中存在的问题:作业车间产能供不应求,存在工艺瓶颈问题;对异常值敏感、对一些问题的解不够精确。
本发明为实现上述目的所采用的技术方案是:一种基于K_means算法解决作业车间工艺瓶颈问题。
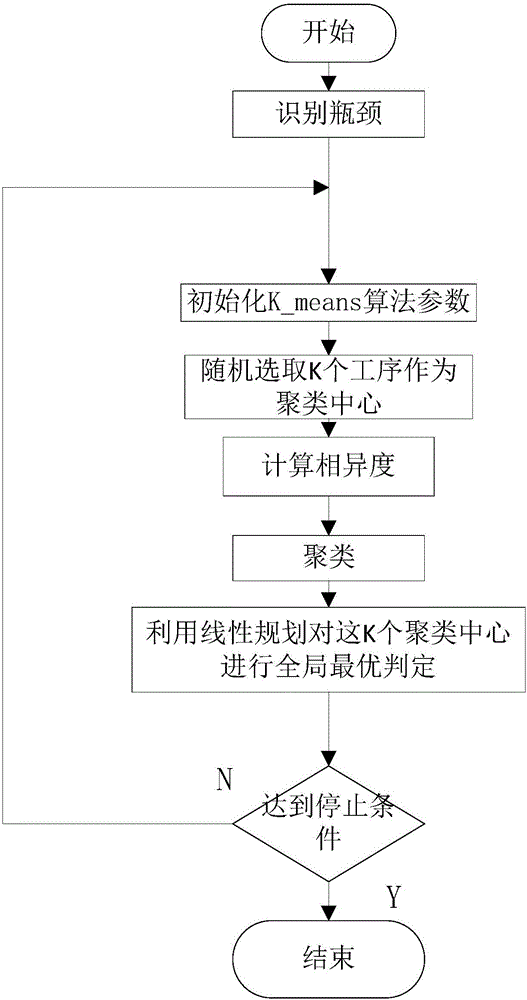
该算法的步骤如下:
步骤1:识别瓶颈:瓶颈的识别方法如下:
步骤1.1:根据TOC原理判断瓶颈资源。
步骤1.2:当需求超过能力时,排队最长的机器就是瓶颈。
步骤2:优化瓶颈:利用一种基于K_means算法优化车间瓶颈工艺加工的调度。具体流程如下:
步骤2.1:初始化算法参数:初始个体(作业工序)数量N,机器数量K。
步骤2.2:初始化聚类。具体如下:
(1)随机选取K个工序作为聚类中心。
(2)以这K个工序作为中心点,计算工序群体N中每个工序与这K个工序的相异度。相异度用作业的操作时间来刻画。
(3)聚类。
步骤2.3:利用线性规划对这K个聚类中心进行全局最优判定。
步骤3:得到满意结果或迭代次数达到一定值,输出最优解,算法结束。否则,以当前聚类的平均值作为中心,返回步骤2.2。
本发明的有益效果是:
1.通过识别瓶颈,对瓶颈有正对性地优化瓶颈工艺的作业调度,避免了很多不必要的优化程序,加快了算法的执行速度,同时,也提高了算法解的精确度。
2.利用TOC规划瓶颈判断,简单有效,准确。
3.利用K_means算法解决调度问题,保证局部最优,提高及机器利用率,提高产量,减低瓶颈。
4.相异度用作业的操作时间来刻画,简单明了。
5.利用线性规划对聚类好的K个聚类中心进行全局最优判定,保证算法得到全局最优解,提高了解的精确度。
附图说明
图1为一种基于K_means算法解决作业车间工艺瓶颈问题的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合算法流程图进行详细、具体说明。
一、瓶颈的数学描述
对于系统中的n种资源X={X1,X2,...,Xn},实际产出能力C={C1,C2,...,Cn},系统的外部需求量MR={MR1,MR2,...,MRn}。某些资源之间存在护卫输入输出的关联关系R。假设与资源Xi相关联的资源的标号的集合为S,即
那么,当且仅当时,资源Xi为瓶颈资源,产出能力Ci,外部需求量MRi。
二、一种解决车间调度工艺瓶颈问题的算法
步骤1:识别瓶颈:瓶颈的识别方法如下:
步骤1.1:根据TOC原理,建立以下模型:且时,资源Xi为瓶颈资源。
步骤1.2:当需求超过能力时,排队最长的机器就是瓶颈。
步骤2:优化瓶颈:利用一种基于K_means算法优化车间瓶颈工艺加工的调度。具体流程如下:
步骤2.1:初始化算法参数:初始个体(作业工序)数量N,机器数量K。
步骤2.2:初始化聚类。具体如下:
(1)随机选取K个工序作为聚类中心。
(2)以这K个工序作为中心点,计算工序群体N中每个工序与这K个工序
的相异度。相异度用作业的操作时间来刻画。具体为:
式中,ti为第i项作业的在第n台机器的运行时间,即代价值。
相异度:
ρi=Pi-Pc
其中,Pi为任意工序的代价,Pc为中心工序的代价。
(3)聚类。如果ρi≤ε,则,第i个工序就聚到相应的c中心一类中。这时得到K。
步骤2.3:利用线性规划对这K个聚类中心进行全局最优判定。具体如下:
目标函数:
C(x*)=f(T)=min max1≤o≤w{max1≤k≤m{max1≤i≤nToik}} (1)
约束条件:
Toik-poik+M(1-aoihk)≥Toih (2)
(o=1,2,...,w;i=1,2,...,n;h,k=1,2,...,m)
Tojk-Toik+M(1-xoijk)≥poik (3)
(i,j=1,2,...,n;o=1,2,...,w;k=1,2,...,m)
Toik≥0(o=1,2,...,w;i=1,2,...,n;k=1,2,...,m) (4)
xoijk=0或1(i,j=1,2,...,n;o=1,2,...,w;k=1,2,...,m) (5)
maxi{Toi}≤To (6)
其中,式(1)表示目标函数,即完成时间(Makespan);式(2)表示工艺约束条件决定的每个工件的操作的先后顺序;式(3)表示加工每个工件的每台机器的先后顺序;式(4)表示完工时间变量约束条件;式(5)表示变量可能的取值大小。上述公式中所涉及的符号定义含义如下:Toik和poik分别为第o个订单(或阶数)中的第i个工件在机器k上的完成时间点和加工时间长度;M是一个足够大的整数;aoihk和xoijk分别为指示系数和指示变量,其含义为:
式(6)表示第o个订单的所有工件最大完成时间小于订单周期To的时间约束。
步骤2.4:如果C(x*)的结果满意,则输出当前中心点作为当前时间决策方案。否则,以当前聚类的平均值作为中心,返回步骤2.2。
步骤3:得到满意结果或迭代次数达到一定值,输出最优解,算法结束。
- 还没有人留言评论。精彩留言会获得点赞!