一种基于负相关反馈的时间序列相似性搜索方法与流程
本发明属于信息技术领域,特别涉及一种基于负相关反馈的时间序列相似性搜索方法。
背景技术:
数据挖掘就是从大型数据库的数据中提取人们感兴趣的、隐含的和事先未知的知识。在许多现实数据库中,数据常常是按时间顺序记录的一系列观测值,对象的属性值可能会随时间而变化。因此,从时间序列数据中挖掘潜在的有用知识具有重要的理论和实践意义。针对时间序列数据模式挖掘的研究,主要集中于时间序列数据相似性模式挖掘。时间序列数据相似性模式挖掘就是在数据库中发现与给定时间序列数据模式很相似的时间序列序列。它具有广泛的实用价值,例如:对观测的空间数据库记录的恒星和行星的时间序列数据进行相似性分析,能帮助天文学家发现新的星星;根据各种商品的销售记录,找出具有相似的商品销售模式,根据相似产品的销售模式来制定相似的销售策略等;找出自然灾害发生的相同前兆,从而对预报自然灾害进行决策研究等。
相似性搜索在1993年由R.Agrawal首次提出,他是时间序列预测、分类、聚类以及序列模式挖掘等等的重要基础。时间序列相似性查找与传统的精确查询不同,由于时间序列在数值上具有连续性以及有不同的噪声影响,因此,大部分情况下不需要时间序列很精确匹配。另一方面是时间序列相似性查询不是针对时间序列中的某个具体的数值,而根据给定的查询序列在所给的时间序列数据集来找查找是在一段时间内具有相似形态特征和变化趋势的时间序列。在时间序列相似性搜索中,需解决的问题包括时间序列特征提取、时间序列索引以及相似度量等。针对相似度量,研究人员提出了各种度量方法,如欧氏距离及其基于Lp准则的变种、动态时间弯曲距离(Dynamic Time Warping,DTW)、编辑距离(Edit Distance,ED)、模式距离(Pattern Distance,PD)、以及最长公共子串(Longest Common Subsequence,LCSS)等。
然而,在实际应用中用户往往开始时并不很明确所要查询的时间序列,当由时间序列数据相似性模式挖掘算法获得的时间序列序列不能满足用户要求时,目前的时间序列数据相似性模式挖掘算法缺乏有效手段进一步获得使用户满意的结果,而且在上述算法中,用户难以有效地参与时间序列数据相似性模式的挖掘过程。
相关反馈技术(relevance feedback)可以让用户与查询系统进行交互,用户对查询结果进行标注(指出结果中相似和不相似的部分),查询系统根据用户的反馈重新组织查询,以提高用户的满意度。传统的相关反馈技术都是在查询过程中利用正相关的结果重新组织查询序列,并进行新查询。但是,在一些查询中,由于用户不熟悉需要查询的内容,很难组织合适的查询序列,或者数据序列中,正相关的序列极少,这些都使得查询很难检索得到用户所需要的内容。
技术实现要素:
发明目的:为了克服现有技术存在的问题,本发明提供了一种查询效率高,查询结果精准,满意度高的基于负相关反馈的时间序列相似性搜索方法。
技术方案:本发明提供了一种基于负相关反馈的时间序列相似性搜索方法,包括以下步骤:
首先根据查询序列Q对时间序列数据集S进行初步相似查询;当用户对这一结果不满意时,则根据初步查询的结果标注出数据序列集中和查询序列负相关的序列以及与查询序列正相关的序列,并将负相关序列合并成一个序列记为Qneg,用户可根据经验和应用要求对所获得正相关序列赋予相应的权值,并通过反馈与原给定序列叠加获得新的查询序列记为Qnew;其次是分别计算数据序列集中的每一个序列与Qnew的相似度以及Qneg的相似度;并且通过组合每一个序列与Qnew的相似度以及Qneg的相似度得到一个最终的相似度;最后根据时间序列数据集中的每一个时间序列所得到的相似度结果进行排名从而得到最终的相似性结果;用户对这一结果进行评判若是满意则查询结束,若是不满意则再次修改查询序列重新查询。
所述n为所有负相关序列个数,m为负相关序列的标号,S’m表示第m个负相关序列。
所述获得新的查询序列记为Qnew=(w1S'1+w2S'2+...+wpS'p+Q)/(w1+w2+...+wp+1),其中,S'1,S'2,...,S'p表示正相关序列集,共有p个标注的正相关序列,S'p表示第p个标注的正相关序列,w1,w2,...,wp表示每个正相关序列对应的权重。从而使搜素的结果更加准确,满意度更高。
进一步,最终待查序列与查询序列的相似性度量结果是时间序列数据集中的每一个时间序列与Qnew的相似度以及Qneg的相似度差值;按照相似度差值从小到大的顺序将对应的时间序列展示给用户。
有益效果:与现有技术相比,本发明所提供的一种基于负相关反馈的时间序列相似性搜索方法,当用户查询结果只能返回负相关序列或者是正相关序列很少时,可以通过负相关反馈进行查询扩展,即用新的查询序列Qnew以及Qneg(Qneg是由用户标注的负相关序列合并而成)来进行查询,使得一些在初始查询中错过的序列可能被重新获得,从而提高了整体性能。由Qnew的公式Qnew=(w1S'1+w2S'2+...+wpS'p+Q)/(w1+w2+...+wp+1)可知它是经用户参与的反馈修正后获得,更真实地反映了用户的意愿。第一次进行负相关反馈查询扩展时,时间序列S'1,S'2,...,S'p是根据初步相似查询,由用户进行标注为正相关的序列,因此Qnew是向相关序列靠近。第二次进行负相关反馈查询扩展时,序列S'1,S'2,...,S'p是根据Sim(Si,Qnew)-Sim(Si,Qneg)的度量函数查询得到的,根据该公式可知,相似查询结果序列S'1,S'2,...,S'p是与查询序列要有较高的相似性并且与负相关序列要有较低的相似性。综上所述,新的查询序列Qnew是向相关序列靠近,远离了负相关序列。从而使查询的结果的满意度更高。
附图说明
图1为本发明的所提出的一种基于负相关反馈的时间序列相似性搜索方法的实施流程图。
具体实施方式
下面结合附图对本发明做更进一步的解释。
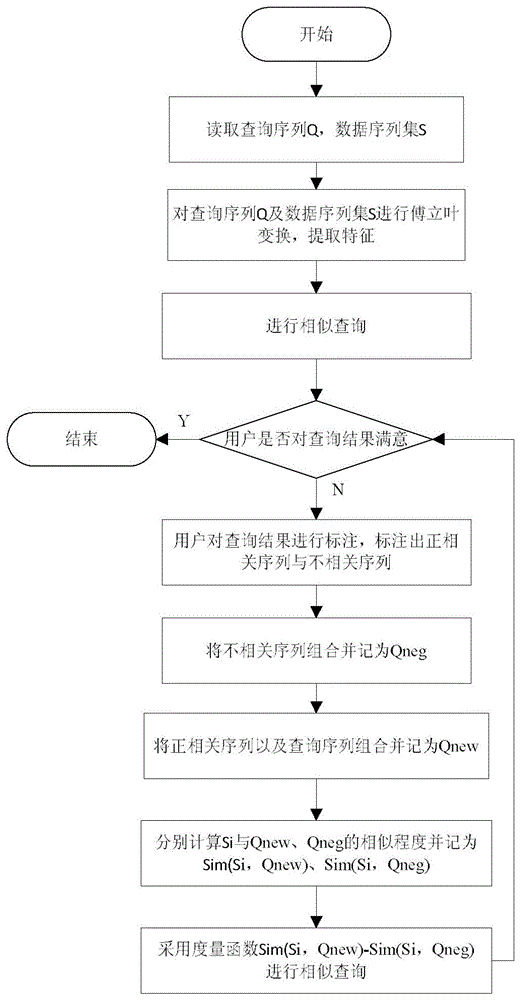
如图1所示,本发明的一种基于负相关反馈的时间序列相似性搜索方法的流程图,步骤如下:
步骤1:读取查询序列Q以及时间序列数据集S
步骤2:采用离散傅里叶变换对查询序列Q,时间序列数据集S进行特征提取。
步骤3:根据序列数据的特点选取度量函数进行相似查询,度量函数包括欧氏距离及其基于Lp准则的变种、动态时间弯曲距离(Dynamic Time Warping,DTW)、编辑距离(Edit Distance,ED)、模式距离(Pattern Distance,PD)、以及最长公共子串(Longest Common Subsequence,LCSS)等。这里以欧氏距离为例,用Distδ(ti,tj)表示δ维空间的序列ti和tj之间的距离,其中,下标i和j表示空间的序列的编号,δ维空间的序列t记为[t1,t2,...,tδ];
步骤4:进行用户交互,用户若对查询结果满意则结束查询,若不满意则进入步骤5。
步骤5:根据查询结果标注出正相关序列即用户满意的时间序列和负相关序列即用户不满意的时间序列。
步骤6:合并所有负相关的序列形成一个单一的序列记为Qneg,其中,n为所有负相关序列个数,m为负相关序列的标号。
步骤7:用户根据对所获得正相关序列的满意度赋予相应的权值,权重取值范围为0到1,并通过反馈与查询序列Q进行叠加获得新的查询序列记为Qnew,例如用户标注的正相关序列集S'1,S'2,...,S'p,其中,共有p个标注的正相关序列,S'p表示第p个标注的正相关序列,然后根据对这些正相关序列的满意度赋予相应的权重w1,w2,...,wp并与查询序列Q进行加权组合从而得到新的查询序列Qnew,Qnew=(w1S'1+w2S'2+...+wpS'p+Q)/(w1+w2+...+wp+1),其中,对S'1的满意度为20%则赋予它的权重为0.2,对S'2的满意度为10%则赋予它的权重为0.1,以此类推,最后采用加权平均法来得到新的查询序列,所以S'1到S'p的权值之和不一定要为1。该查询序列Qnew经用户参与的反馈修正后更真实地反映了用户的意愿。
步骤8:采用度量函数分别计算时间序列Si与Qnew的相似程度,并记为Sim(Si,Qnew),和时间序列Si与Qneg的相似程度,并记为Sim(Si,Qneg)。其中,Si是时间序列数据集S中第i个时间序列;
步骤9:组合步骤8中所得到的Sim(Si,Qnew)和Sim(Si,Qneg),得到最终的相似度量结果Sim(Si,Qnew)-Sim(Si,Qneg),按照Sim(Si,Qnew)-Sim(Si,Qneg)的值从小到大的顺序将对应的时间序列展示给用户,回到步骤4进行判断。要想该函数有较高的相似程度,那么Si必须是与查询序列要有较高的相似性并且与负相关序列要有较低的相似性,这就保证了查询得到的结果是与正相关序列更加接近,同时也远离负相关序列。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!