基于人工智能的对话系统的行为管理方法及装置与流程
本发明涉及人机交互技术领域,尤其涉及基于人工智能的对话系统的行为管理方法及装置。
背景技术:
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
现有的对话系统的行为管理方案是依靠相关的产品经验使用静态规则配置的方式来生成候选系统行为以及选择最佳系统行为。也就是根据当前特定的产品应用,在配置文件中填写该应用相关的系统行为触发和排序规则,并在所选取的行为执行时使用预先配置的静态规则对后续用户行为进行预测。
由于现有的基于规则的候选行为触发和排序规则都是根据特定产品的特点人为手工配置的。因而,现有技术有以下的一些不足:1)使用静态规则配置的垂类对话流程比较固定,只能够完成规则中明确的逻辑,不够灵活;2)静态规则是基于特定产品的具体逻辑来进行设置,不具备泛化能力,不能够将这些规则用在其他的垂类和产品上。
技术实现要素:
有鉴于此,本发明实施例提供基于人工智能的对话系统的行为管理方法及装置,以提高基于人工智能的对话系统的灵活性以及泛化能力。
第一方面,本发明实施例提供了基于人工智能的对话系统的行为管理方法,包括:
依据当前系统交互状态、当前用户状态和系统行为序列,生成当前对话特征;
依据所述当前对话特征以及训练得到的系统行为触发模型,从所述系统行为序列中选择用户关联的候选系统行为;
依据所述候选系统行为与所述用户进行交互。
第二方面,本发明实施例提供了基于人工智能的对话系统的行为管理装置,包括:
当前特征生成模块,用于依据当前系统交互状态、当前用户状态和系统行为序列,生成当前对话特征;
候选行为选择模块,用于依据所述当前对话特征以及训练得到的系统行为触发模型,从所述系统行为序列中选择用户关联的候选系统行为;
系统行为决策模块,用于依据所述候选系统行为与所述用户进行交互。
本发明实施例提供的技术方案,预先通过机器学习对系统行为触发的规则进行建模,得到系统行为触发模型,随后依据当前系统交互状态、当前用户状态和系统行为序列,生成当前对话特征,并依据当前对话特征和系统行为触发模型确定候选系统行为,即,本方案中候选系统行为是依据系统行为触发模型确定的,相比于现有技术中通过依据静态配置的系统行为触发规则确定候选系统行为,提高了基于人工智能的对话系统的灵活性以及泛化能力。
附图说明
图1是本发明实施例一提供的基于人工智能的对话系统的行为管理方法的流程图;
图2是本发明实施例二提供的基于人工智能的对话系统的行为管理方法的流程图;
图3是本发明实施例三提供的基于人工智能的对话系统的行为管理方法的流程图;
图4是本发明实施例三提供的基于人工智能的对话系统的行为管理方法的示意图;
图5是本发明实施例四提供的基于人工智能的对话系统的行为管理装置的结构图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
实施例一
图1是本发明实施例一提供的基于人工智能的对话系统的行为管理方法的流程图。本实施例的方法可以由基于人工智能的对话系统的行为管理装置执行,该装置可通过硬件和/或软件的方式实现。本实施例的方法一般可适用于对话系统与用户进行人机交互的情形。参考图1,本实施例提供的基于人工智能的对话系统的行为管理方法具体可以包括如下:
S11、依据当前系统交互状态、当前用户状态和系统行为序列,生成当前对话特征。
对话系统使用聊天机器人交互框架与用户进行交互,该交互框架包括:NLU((Natural Language Understanding,自然语言理解)模块,用于理解用户的自然语言如用户的查询语言,将用户的自然语言转换为机器可以理解的结构化表示;UST(User Status Updates,用户状态更新)模块,用于依据NLU模块的输出更新用户的对话状态信息,其中用户的对话状态信息包括系统交互状态、用户意图和用户状态等;系统行为触发(Action-Trigger)模块,用于根据UST模块更新后的用户的对话状态信息,挑选出一系列后续可能执行的候选系统行为,构成候选系统行为列表;行为决策(Policy)模块,用于对系统触发模块触发的候选系统行为进行排序并选择一个最佳系统行为,并对后续的用户行为进行预测;最佳行为执行(Action-Exe)模块:执行行为决策模块选择的最佳系统行为;NLG(Natural Language Generation,自然语言生成)模块,用于根据最佳行为执行模块的执行结果进行自然语言生成,生成最终展现给用户的自然语言结果。
在本实施例中,当前系统交互状态用于表征用户当前交互所处的某个系统阶段,如开始状态阶段、澄清状态阶段和推荐状态阶段等。当前用户状态可以包括用户本轮的需求意图,如用于获取餐馆信息的订餐意图,用户在不同需求维度上的多轮需求取值,如在找餐馆场景下,用户在餐馆风味这个需求槽位上可以去川菜和粤菜等不同的风味。系统行为序列指的是由系统行为组成的序列,系统行为指的是对话系统能够执行的行为,如系统行为是推荐动作、澄清动作和信息满足等。
具体的,NLU模块获取用户的当前自然语言,并将用户的当前自然语言处理成结构化表示,UST模块依据结构化表示信息确定当前用户状态,随后,系统行为触发模块获取当前用户状态,并确定当前系统交互状态和系统行为序列,且生成当前对话特征。由于当前对话特征是依据当前系统交互状态、当前用户状态和系统行为序列生成的,因而当前对话特征包含了当前系统交互状态、当前用户状态和各系统行为的特征。
S12、依据所述当前对话特征以及训练得到的系统行为触发模型,从所述系统行为序列中选择用户关联的候选系统行为。
在本实施例中,系统行为触发模型可以是预先通过机器人学习离线训练得到的,用于挑选出一系列后续可能执行的候选系统行为。
示例性的,所述系统行为触发模型可以通过如下方式训练得到:基于人工标注数据,确定业务场景与系统行为之间的第一关联关系,以及用户状态与系统行为之间的第二关联关系;依据所述第一关联关系和所述第二关联关系,提取通用交互特征,其中所述通用交互特征包括系统交互状态、用户状态、用户意图以及上轮系统行为的执行结果;依据提取的通用交互特征,构建所述系统行为触发模型。
其中,用户意图指的是用户的需求意图,如获取餐馆信息的订餐意图。具体的,在对话过程中需要执行系统行为的时候标注人员人工地标注业务场景与系统行为之间的第一关联关系,以及用户状态与系统行为之间的第二关联关系,标注人员还可以对业务场景下的对话逻辑进行标注,其中业务场景可以是旅游场景、订餐场景、订票场景或休闲娱乐场景等。随后,基于人工标准信息如关联关系提取通用交互特征,且使用机器学习模型对系统行为触发规则进行离线建模,如可以基于决策树模型,依据通用交互特征构建系统行为触发模型。
由于本实施例中候选系统行为是依据机器学习得到的系统行为触发模型确定的,该机器学习方式使得行为触发逻辑相比于纯静态配置具有灵活性和泛化能力,从而可以推广到不同领域的垂类。
S13、依据所述候选系统行为与所述用户进行交互。
本实施例提供的技术方案,预先通过机器学习对系统行为触发的规则进行建模,得到系统行为触发模型,随后依据当前系统交互状态、当前用户状态和系统行为序列,生成当前对话特征,并依据当前对话特征和系统行为触发模型确定候选系统行为,即,本方案中候选系统行为是依据系统行为触发模型确定的,相比于现有技术中通过依据静态配置的系统行为触发规则确定候选系统行为,提高了对话系统的灵活性以及泛化能力。
示例性的,从所述系统行为序列中选择用户关联的候选系统行为之前可以包括:基于预设的行为配置规则,对所述系统行为序列中包含的系统行为进行预筛选处理。
示例性的,从所述系统行为序列中选择用户关联的候选系统行为之后可以包括:基于预设的行为配置规则,对所述候选系统行为进行增删干预处理。
采用机器学习的方式对候选行为的触发进行了建模,并且与人工配置的静态行为配置规则共同完成候选行为的触发工作,触发逻辑相比纯静态配置具有一定的灵活性和泛化能力,可以推广到不同的领域的垂类。
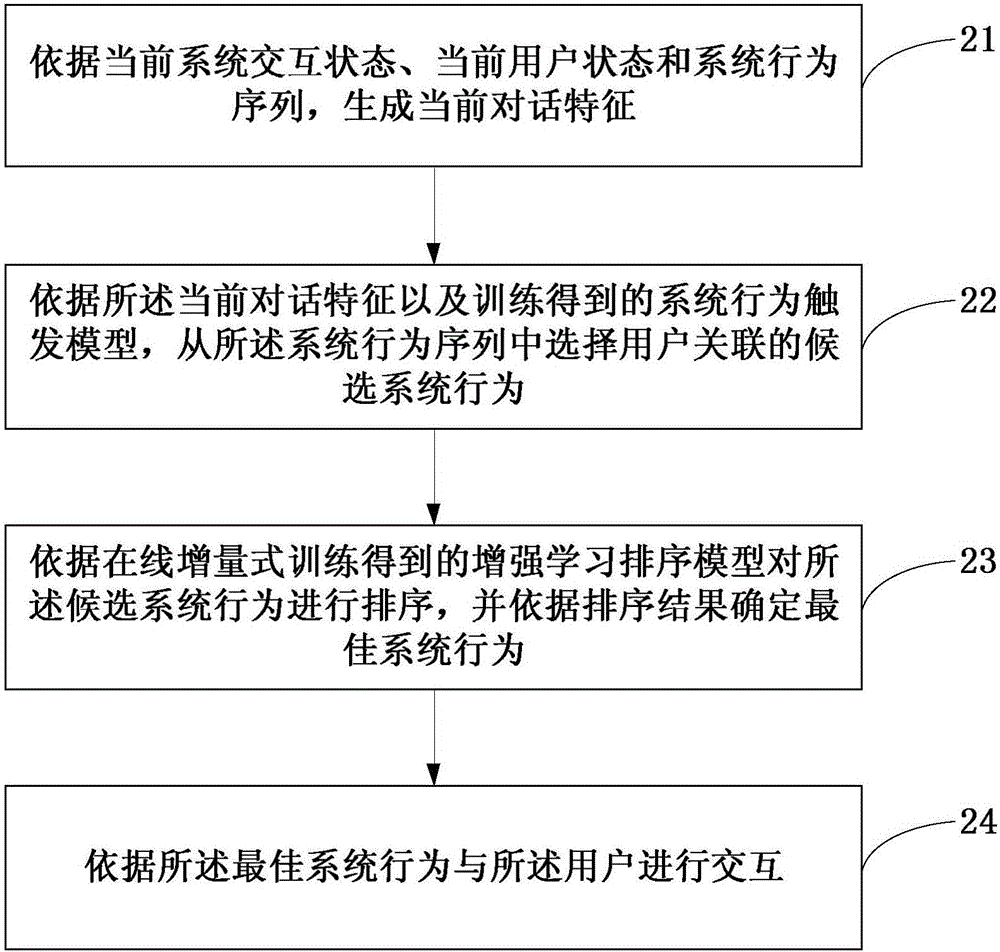
实施例二
本实施例在上述实施例一的基础上提供了一种新的基于人工智能的对话系统的行为管理方法。图2是本发明实施例二提供的基于人工智能的对话系统的行为管理方法的流程图。参考图2,本实施例提供的基于人工智能的对话系统的行为管理方法具体可以包括如下:
S21、依据当前系统交互状态、当前用户状态和系统行为序列,生成当前对话特征。
S22、依据所述当前对话特征以及训练得到的系统行为触发模型,从所述系统行为序列中选择用户关联的候选系统行为。
S23、依据在线增量式训练得到的增强学习排序模型对所述候选系统行为进行排序,并依据排序结果确定最佳系统行为。
在经过候选行为触发后,增强学习排序模型得到触发的各候选系统行为,并依据当前系统状态和当前用户状态对各候选系统行为进行排序,得到最佳系统行为。
示例性的,所述增强学习排序模型通过如下方式在线训练得到:依据系统交互状态、用户状态、用户意图、所述候选系统行为以及所述候选系统行为的环境反馈信息,通过在线增量式训练得到所述增强学习排序模型。
在本实施例中,所述候选系统行为的环境反馈信息可以包括用户点击行为、用户下单行为、用户回复信息以及用户评价信息。例如,若本轮交互用户有点击行为则作为本轮交互的正反馈,若本轮交互用户没有点击行为则作为本轮交互的负反馈。
选用增强学习(Reinforcement Learning)模型对候选行为的排序进行建模。增强学习又称作强化学习,是近年来机器学习和智能控制领域的研究热点之一。增强学习旨在通过在无外界“老师”参与的情况下,智能系统(Agent)自身不断地与环境交互或试错,根据反馈评价信号调整动作,得到最优的策略以适应环境。相比有监督学习,增强学习的过程包含几个要素:1)适应性,即智能系统不断利用环境反馈信息来改善模型性能;2)反应性,即智能系统可以从经验中直接获取状态动作规则;3)增量特性,即强化学习是一种增量式学习,可以在线使用。
综上,对话系统通过与用户的不断对话,获取用户对候选系统行为的环境反馈信息,进行自我学习和调整,完成在线增量式的学习,得到增强学习排序模型。随着学习量的增加,排序模型的效果不断提升。
S24、依据所述最佳系统行为与所述用户进行交互。
具体的,行为决策模块从候选系统行为中选择最佳系统行为之后,执行最佳系统行为,NLG模块依据最佳系统行为的执行结果生成最终展现给用户的自然语言结果。
本实施例提供的技术方案中,对话系统依据机器学习训练得到的系统行为触发模型确定候选系统行为,并通过在线增量式训练得到的增强学习排序模型对候选系统行为进行排序,得到最佳系统行为,并依据最佳系统行为与用户进行交互。由于增强学习排序模型是对话系统通过与用户的不断对话,获取环境反馈信息,并依据环境反馈信息进行自我学习和调整得到的,因而该排序方法灵活、准确且具有通用性。
实施例三
本实施例在上述实施例一和实施例二的基础上提供了一种新的基于人工智能的对话系统的行为管理方法。图3是本发明实施例三提供的基于人工智能的对话系统的行为管理方法的流程图。参考图3,本实施例提供的基于人工智能的对话系统的行为管理方法具体可以包括如下:
S31、依据当前系统交互状态、当前用户状态和系统行为序列,生成当前对话特征。
S32、依据所述当前对话特征以及训练得到的系统行为触发模型,从所述系统行为序列中选择用户关联的候选系统行为。
S33、依据在线增量式训练得到的增强学习排序模型对所述候选系统行为进行排序,并依据排序结果确定最佳系统行为。
S34、依据所述最佳系统行为与所述用户进行交互。
S35、确定所述最佳系统行为对应的候选引导选项。
在本实施例中,候选引导选项用于引导用户的候选动作。
S36、依据在线增量式训练得到的增强学习行为预测模型,从所述候选引导选项中选择最佳引导选项。
具体的,在得到候选引导选项后,增强学习行为预测模型依据当前系统状态和当前用户状态对各候选引导选项进行排序,得到最佳引导选项,即预测出下轮用户行为。
示例性的,所述增强学习行为预测模型通过如下方式在线训练得到:依据系统交互状态、用户状态、用户意图、所述候选引导选项以及所述候选引导选项的环境反馈信息,通过在线增量式训练得到所述增强学习行为预测模型。
在本实施例中,所述候选引导选项的环境反馈信息可以包括用户回复信息以及用户评价信息,例如,使用用户对于展示的引导选项的点击行为作为该引导选项的正反馈,若该引导选项没有点击则即为负反馈。
综上,参考图4,在对话系统与用户交互之前通过如下方式离线训练得到系统行为触发模型:获取人工标注的标注数据集合,特征提取模块从标准数据中提取通用交互特征,并依据通用交互特征线下训练得到系统行为触发模型。在于用户交互过程中,NLU模块获取并结构化表示用户的自然语言,将处理结果传输给UST模块,UST模块更新用户的状态信息,且将用户的状态信息传输给系统行为触发模块,系统行为触发模块依据系统行为触发模型、用户的状态信息预先配置的静态规则和意图,以及系统行为的预执行信息,确定候选系统行为,且将包含候选系统行为的候选动作列表传输给行为决策模块。一方面,行为决策模块依据用户对候选系统行为的反馈信息在线学习得到排序模型,依据排序模型对候选系统行为进行排序,且依据排序结果确定最佳系统行为;另一方面,行为决策模块确定最佳系统行为的候选引导路径,依据用户对候选引导路径的反馈信息在线学习得到行为预测模型,并依据行为预测模型进行下轮用户行为预测。最佳行为执行最佳系统行为;NLG模块根据最佳行为执行模块的执行结果生成最终展现给用户的自然语言结果。
本实施例提供的技术方案中,对话系统依据机器学习训练得到的系统行为触发模型确定候选系统行为,并通过在线增量式训练得到的增强学习排序模型对候选系统行为进行排序,得到最佳系统行为,并依据最佳系统行为与用户进行交互。并且,通过在线增量式训练得到的增强学习行为预测模型对候选引导选项进行排序得到最佳引导选项。由于增强学习排序模型是对话系统通过与用户的不断对话,获取环境反馈信息,并依据环境反馈信息进行自我学习和调整得到的,因而行为预测方法灵活、准确且具有通用性。
实施例四
图5是本发明实施例四提供的基于人工智能的对话系统的行为管理装置的结构图。该装置一般可适用于基于人工智能的对话系统与用户进行人机交互的情形。参见图5,本实施例提供的基于人工智能的对话系统的行为管理装置的具体结构如下:
当前特征生成模块41,用于依据当前系统交互状态、当前用户状态和系统行为序列,生成当前对话特征;
候选行为选择模块42,用于依据所述当前对话特征以及训练得到的系统行为触发模型,从所述系统行为序列中选择用户关联的候选系统行为;
系统行为决策模块43,用于依据所述候选系统行为与所述用户进行交互。
示例性的,上述装置包括行为触发模型训练模块,所述行为触发模型训练模块可以用于:
基于人工标注数据,确定业务场景与系统行为之间的第一关联关系,以及用户状态与系统行为之间的第二关联关系;
依据所述第一关联关系和所述第二关联关系,提取通用交互特征,其中所述通用交互特征包括系统交互状态、用户状态、用户意图以及上轮系统行为的执行结果;
依据提取的通用交互特征,构建所述系统行为触发模型。
示例性的,上述装置可以包括:
预筛选模块,用于在从所述系统行为序列中选择用户关联的候选系统行为之前,基于预设的行为配置规则,对所述系统行为序列中包含的系统行为进行预筛选处理;或者,
增删干预模块,用于在从所述系统行为序列中选择用户关联的候选系统行为之后,基于预设的行为配置规则,对所述候选系统行为进行增删干预处理。
示例性的,所述系统行为决策模块43可以包括:
最佳系统行为确定单元,用于依据在线增量式训练得到的增强学习排序模型对所述候选系统行为进行排序,并依据排序结果确定最佳系统行为;
系统对话单元,用于依据所述最佳系统行为与所述用户进行交互。
示例性的,上述装置包括排序模型训练模块,所述排序模型训练模块可以用于:
依据系统交互状态、用户状态、用户意图、所述候选系统行为以及所述候选系统行为的环境反馈信息,通过在线增量式训练得到所述增强学习排序模型。
示例性的,所述候选系统行为的环境反馈信息可以包括用户点击行为、用户下单行为、用户回复信息以及用户评价信息。
示例性的,上述装置可以包括:
候选引导选项确定模块,用于在依据排序结果确定最佳系统行为之后,确定所述最佳系统行为对应的候选引导选项;
最佳引导选项选择模块,用于依据在线增量式训练得到的增强学习行为预测模型,从所述候选引导选项中选择最佳引导选项。
示例性的,上述装置可以包括行为预测模型训练模块,所述行为预测模型训练模块可以用于:
依据系统交互状态、用户状态、用户意图、所述候选引导选项以及所述候选引导选项的环境反馈信息,通过在线增量式训练得到所述增强学习行为预测模型。
本实施例提供的基于人工智能的对话系统的行为管理装置,与本发明任意实施例所提供的基于人工智能的对话系统的行为管理方法属于同一发明构思,可执行本发明任意实施例所提供的基于人工智能的对话系统的行为管理方法,具备执行基于人工智能的对话系统的行为管理方法相应的功能模块和有益效果。未在本实施例中详尽描述的技术细节,可参见本发明任意实施例提供的基于人工智能的对话系统的行为管理方法。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!