基于人工智能的处理搜索结果方法和装置与流程
本申请涉及自然语言处理技术领域,尤其涉及一种基于人工智能的获取搜索方法和装置。
背景技术:
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
当用户使用搜索引擎搜索某一个查询时,总是希望输入一个简单的查询(query),得到与自己意图最匹配的搜索结果,这往往导致输入的是相同的query,不同的用户可能查找的是不同的信息。但是,目前的搜索结果不能很好的满足多样化等需求。
技术实现要素:
本申请旨在至少在一定程度上解决相关技术中的技术问题之一。
为此,本申请的一个目的在于提出一种基于人工智能的处理搜索结果的方法,该方法能够扩展搜索结果具有的特征,为搜索结果的多样性等需求提供基础。
本申请的另一个目的在于提出一种基于人工智能的处理搜索结果的装置。
为达到上述目的,本申请第一方面实施例提出的基于人工智能的处理搜索结果的方法,包括:接收查询,并获取与所述查询对应的搜索结果;获取多个语言模型,其中,每个语言模型采用一种来源的数据进行训练后生成;分别采用每个语言模型对所述搜索结果进行打分,以及根据打分结果确定所述搜索结果的来源。
本申请第一方面实施例提出的基于人工智能的处理搜索结果的方法,通过根据语言模型对搜索结果进行打分,并且语言模型是根据不同来源的数据训练生成的,可以根据打分结果确定搜索结果的来源,为满足搜索结果多样化等需求提供基础。
为达到上述目的,本申请第二方面实施例提出的基于人工智能的处理搜索结果的装置,包括:第一获取模块,用于接收查询,并获取与所述查询对应的搜索结果;第二获取模块,用于获取多个语言模型,其中,每个语言模型采用一种来源的数据进行训练后生成;来源确定模块,用于分别采用每个语言模型对所述搜索结果进行打分,以及根据打分结果确定所述搜索结果的来源。
本申请第二方面实施例提出的基于人工智能的处理搜索结果的装置,通过根据语言模型对搜索结果进行打分,并且语言模型是根据不同来源的数据训练生成的,可以根据打分结果确定搜索结果的来源,为满足搜索结果多样化等需求提供基础。
本申请实施例还提出了一种用于基于人工智能的处理搜索结果的装置,包括:处理器;用于存储处理器可执行指令的存储器;其中,所述处理器被配置为:接收查询,并获取与所述查询对应的搜索结果;获取多个语言模型,其中,每个语言模型采用一种来源的数据进行训练后生成;分别采用每个语言模型对所述搜索结果进行打分,以及根据打分结果确定所述搜索结果的来源。
本申请实施例还提出了一种非临时性计算机可读存储介质,当所述存储介质中的指令由终端的处理器被执行时,使得终端能够执行一种基于人工智能的处理搜索结果的方法,所述方法包括:接收查询,并获取与所述查询对应的搜索结果;获取多个语言模型,其中,每个语言模型采用一种来源的数据进行训练后生成;分别采用每个语言模型对所述搜索结果进行打分,以及根据打分结果确定所述搜索结果的来源。
本申请实施例还提出了一种计算机程序产品,当所述计算机程序产品中的指令处理器执行时,执行一种基于人工智能的处理搜索结果的方法,所述方法包括:接收查询,并获取与所述查询对应的搜索结果;获取多个语言模型,其中,每个语言模型采用一种来源的数据进行训练后生成;分别采用每个语言模型对所述搜索结果进行打分,以及根据打分结果确定所述搜索结果的来源。
本申请附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。
附图说明
本申请上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
图1是本申请一个实施例提出的基于人工智能的处理搜索结果的方法的流程示意图;
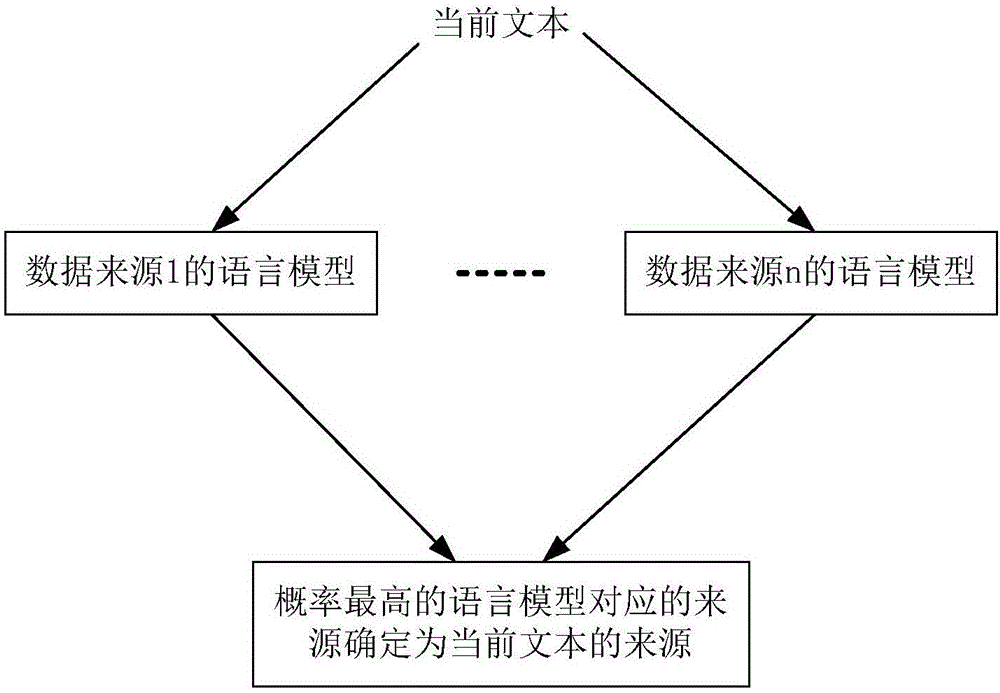
图2是本申请实施例中根据多个语言模型确定当前文本的来源的示意图;
图3是本申请实施例中一种语言模型的示意图;
图4是本申请另一个实施例提出的基于人工智能的处理搜索结果的方法的流程示意图;
图5是本申请实施例中采用语言模型对当前文本进行前向计算的结构图;
图6是本申请实施例中采用的一种非线性激活函数的曲线图;
图7是本申请实施例中采用语言模型预测下一个词出现概率的示意图;
图8是本申请一个实施例提出的基于人工智能的处理搜索结果的装置的结构示意图;
图9是本申请另一个实施例提出的基于人工智能的处理搜索结果的装置的结构示意图。
具体实施方式
下面详细描述本申请的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的模块或具有相同或类似功能的模块。下面通过参考附图描述的实施例是示例性的,仅用于解释本申请,而不能理解为对本申请的限制。相反,本申请的实施例包括落入所附加权利要求书的精神和内涵范围内的所有变化、修改和等同物。
图1是本申请一个实施例提出的基于人工智能的处理搜索结果的方法的流程示意图。
如图1所示,本实施例包括以下步骤:
S11:接收查询,并获取与所述查询对应的搜索结果。
例如,用户在搜索引擎中以文本、语音等形式输入查询(query),搜索引擎接收到用户输入的查询后,可以从数据库或者互联网上获取与query相关的文本、图片等内容作为查询对应的搜索结果。具体的获取与query相关的内容可以采用各种已有或者将来出现的技术实现。
S12:获取多个语言模型,其中,每个语言模型采用一种来源的数据进行训练后生成。
其中,语言模型可以是预先训练生成的,从而在接收到query后,获取已有的语言模型。
在训练语言模型时,可以收集各个来源的数据,每个来源的数据组成一个训练数据集,同一个来源的数据输入到同一个语言模型中训练,有几个搜索结果来源就对应几个语言模型,此处假设有n个数据来源,则训练生成n个语言模型。
上述的不同来源可以具体是指不同的门户网站,从而将来自不同门户网站的数据作为不同来源的数据。
语言模型可以具体是深度神经网络模型,针对每个语言模型,可以用收集的对应来源的训练数据集,得到深度神经网络的参数,从而确定对应的语言模型。具体的训练生成语言模型的流程可以参见后续描述。
S13:分别采用每个语言模型对所述搜索结果进行打分,以及根据打分结果确定所述搜索结果的来源。
对应每个搜索结果,可以获取该搜索结果中的预设内容,例如,可以获取搜索结果包含的整个文本。假设每个搜索结果包含的整个文本称为当前文本,如图2所示,对应每个当前文本,将当前文本分别输入到不同来源的数据训练生成的语言模型(假设共有n个语言模型)中,并分别采用每个语言模型对当前文本进行打分后,可以得到n个得分,将得分表明当前文本在语言模型上概率最高的语言模型对应的来源确定为搜索结果的来源。
进一步的,在确定出搜索结果的来源后,可以为搜索结果设置对应的来源标签,将来源标签作为搜索结果的一个特征,依据该来源标签对搜索结果进行相关处理,例如根据来源标签对搜索结果进行排序,以丰富搜索结果的多样性,使得同一个查询对应的搜索结果来自不同的网站等不同来源。
具体的,在上述根据语言模型对当前文本进行打分时,可以是先根据语言模型对当前文本包含的词进行打分,再根据词对应的得分计算出当前文本的得分。上述的语言模型可以具体是深度神经网络模型。以图3所示的语言模型为例,对应当前文本包含的每一个词,可以先确定该词对应的词向量,如图3所示,词向量分别用x1、x2、…、xT表示;再将词向量作为语言模型的输入,经过语言模型的处理后,可以得到语言模型的输出P1、P2、…、PT,这些输出P1、P2、…、PT即是当前文本包含的词的得分,之后可以根据这这些词的得分计算出当前文本的得分,再根据得分确定出相应的来源。具体的根据词的得分计算当前文本的得分的流程可以参见后续描述。
本实施例中,通过根据语言模型对搜索结果进行打分,并且语言模型是根据不同来源的数据训练生成的,可以根据打分结果确定搜索结果的来源,为满足搜索结果多样化等需求提供基础。
图4是本申请另一个实施例提出的基于人工智能的处理搜索结果的方法的流程示意图。
如图4所示,本实施例的方法包括:
S41:获取不同来源的数据,并将每个来源的数据组成一个训练数据集。
其中,可以从不同的门户网站收集数据,作为不同来源的数据,以及可以将来自同一个门户网站的数据组成一个训练数据集。
S42:采用同一个训练数据集的数据分别进行训练,生成多个语言模型。
不同来源的数据,其句法、语义构成不同,语言模型可以记录训练数据中的语法、句法、语义信息,因此可以训练出跟训练数据相关的不同的语言模型。原则上,有几个来源就训练几个语言模型,不同来源的数据用于训练不同的语言模型。
语言模型形式化的描述就是给定一个字符串,看它是自然语言的概率P(w1,w2,…,wt)。W1到Wt依次表示这句话中的各个词。P(w1,w2,…,wt)=P(w1)×P(w2|w1)×P(w3|w1,w2)×…×P(wt|w1,w2,…,wt_1)。常用的语言模型都是在近似地求P(wt|w1,w2,…,wt_1)。比如n-gram模型就是用P(wt|wt_n+1,…,wt-1)近似表示前者。神经网络语言模型就是将前面已出现的词表示到抽象空间中,然后用已出现的词的抽象表示预测下一个词出现的概率。此处,可以选择不同的深度神经网络,本发明以循环神经网络(recurrent neural network,RNN)为例,依次将文本串中的词输入到RNN网络中,可以得到包含当前词以及当前词之前所有词的抽象空间的语义表示向量。
在训练时,上述收集的各个来源的数据可以具体是历史数据中的各个来源的搜索结果,将这些历史搜索结果中的文本作为训练样本进行RNN训练,一种RNN网络如图3所示,对应图3所示的语言模型,需要在训练阶段确定其中的参数:W、Wh、Wrec。
训练目标是使得序列样本中,每个词在当前序列中出现的概率最大。
具体的,可以采用随机梯度下降法(Stochastic Gradient Descent,SGD)和反向传播算法(BackPropagation)学习出RNN网络的参数W,Wh,Wrec。SGD与反向传播算法属于本领域技术人员的公知知识,在此仅做概要说明。
SGD算法的思想是通过计算某一组(称为mini-batch size)训练样本的梯度(参数W,Wh,Wrec的偏导数),来迭代更新随机初始化过的参数W,Wh,Wrec;更新的方法是每次让W,Wh,Wrec减去所设置的一个学习率(learning rate)乘以计算出的梯度,从而在多次迭代之后可以让深度学习网络根据参数W,Wh,Wrec所计算出的值,与实际值之间的差最小化。
反向传播算法是在深度学习网络中的一种有效的计算参数的梯度的方法。
S43:接收查询,并获取与所述查询对应的搜索结果。
例如,用户在搜索引擎中以文本、语音等形式输入查询(query),搜索引擎接收到用户输入的查询后,可以从数据库或者互联网上获取与query相关的文本、图片等内容作为查询对应的搜索结果。具体的获取与query相关的内容可以采用各种已有或者将来出现的技术实现。
S44:对应当前的一个搜索结果,分别计算所述一个搜索结果在每个语言模型上的困惑度(perplexity,PPL)得分,将PPL得分最低的语言模型对应的来源,作为所述一个搜索结果的来源。
其中,对应每个搜索结果,可以获取该搜索结果包含的预设内容(如搜索结果包含的整个文本),并获取预设内容包含的词,以及采用每个语言模型对词进行打分,根据词对应的得分计算搜索结果在每个语言模型上的PPL得分。
PPL得分与词对应的得分成反比关系,具体计算公式可以为:
其中,ppl是一个搜索结果在一个语言模型上的PPL得分,N是该搜索结果的预设内容中包含的词的总数,Pi是采用该语言模型对每个词进行打分后得到的每个词对应的得分。
每个词对应的得分的计算流程可以包括:将词对应的词向量作为语言模型的输入层,经过语言模型的计算后得到输出,将语言模型的输出作为词对应的得分。
具体的,以图3所示的语言模型为例,在计算词对应的得分时,可以分为前向计算和分类计算。
如图5所示,是某个语言模型中针对当前文本的前向计算的结构图。最下层是输入层,输入层输入的是当前文本中包含的词的词向量,隐藏层是通过下述的循环单元(Recurrent Unit)的计算,逐步得到的。每个词输入后得到的rnn的隐层向量即为包括当前词之前所有词的向量表示。
更具体的,输入层是按照时间序列(i=1到i=T)逐次输入到网络的当前文本中包含的词的词向量。对应某个词Wi,词向量(Word Embedding)是一个长度为EMBEDDING_SIZE的列向量C(Wi);例如,假设词表中词的大小为1000000,那么系统中输入层的输入就是一个1000000维的向量(EMBEDDING_SIZE=1000000),其中当前词对应的位置为1,词典中其他词所对应的位置为0。网络的隐藏层表示所设计的RNN网络在每个时间点i时的状态,是一个长度为HIDDEN_SIZE的列向量hi。
hi的计算公式为:
hi=f(Wh*xi+Wrec*hi-1)
其中f()为非线性激活函数sigmoid,其函数定义如下所示,以及函数曲线如图6所示:
经过上述步骤,可以得到每个词输入后的隐层向量表示,用这个表示可以预测下一个词出现的概率,如图7所示。在语言模型中,预测下一个词出现的概率实际上是一个分类问题,类别的大小等于词表的大小。在上一步骤中得到的隐层向量hi,乘以一个hidden_size*voc_num大小的矩阵(hidden_size为隐层大小,voc_num为词表大小),得到维度为voc_num的向量即为预测词在词表中的log概率分布。由于全联通(full connect,FC)层(对应图3的W)的输出范围不一定在[0,1],所以需要增加softmax层对全联通层的输出做归一化,使得概率分布范围在[0,1],softmax计算如下所示:
其中,向量y(j)是softmax层的输入,在本实施例中具体为全联通层的输出,k为向量y(j)的维度大小。
经过上述步骤可以计算出每个语言模型对每个词的得分,再采用PPL得分的计算公式可以根据每个词的得分计算得到当前文本在该语言模型上的PPL得分,假设共有n个语言模型,则每个搜索结果可以得到n个PPL得分,则将PPL得分最低的语言模型对应的来源确定为每个搜索结果的来源。
在确定出搜索结果的来源后,可以为该搜索结果设置对应的来源标签(如来自某个门户网站)。之后可以将来源标签作为搜索结果的一个特征,在后续的搜索结果排序等算法中考虑。例如,在排序时前面的预设个数的搜索结果分别是不同来源的搜索结果,以及展示这预设个数的搜索结果,使得展示的搜索结果尽量多样化。
本实施例中,通过根据语言模型对搜索结果进行打分,并且语言模型是根据不同来源的数据训练生成的,可以根据打分结果确定搜索结果的来源,为满足搜索结果多样化等需求提供基础。进一步的,采用深度神经网络训练语言模型可以使得语言模型更准确,从而使得来源确定更准确。
图8是本申请一个实施例提出的基于人工智能的处理搜索结果的装置的结构示意图。
如图8所示,本实施例的装置包括:第一获取模块81、第二获取模块82和来源确定模块83。
第一获取模块81,用于接收查询,并获取与所述查询对应的搜索结果;
第二获取模块82,用于获取多个语言模型,其中,每个语言模型采用一种来源的数据进行训练后生成;
来源确定模块83,用于分别采用每个语言模型对所述搜索结果进行打分,以及根据打分结果确定所述搜索结果的来源。
一些实施例中,参见图9,本实施例的装置80还包括:
第三获取模块84,用于获取不同来源的数据,并将每个来源的数据组成一个训练数据集;
训练模块85,用于采用同一个训练数据集的数据分别进行训练,生成多个语言模型。
一些实施例中,参见图9,所述来源确定模块83包括:
打分子模块831,用于对应当前的一个搜索结果,分别计算所述一个搜索结果在每个语言模型上的PPL得分;
确定子模块832,用于将PPL得分最低的语言模型对应的来源,作为所述一个搜索结果的来源。
一些实施例中,所述打分子模块831具体用于:
获取当前的一个搜索结果中预设内容包含的词;
采用每个语言模型对所述词进行打分,得到词对应的得分;
根据词对应的得分计算所述PPL得分。
一些实施例中,所述语言模型为深度神经网络模型。
可以理解的是,本实施例的装置与上述方法实施例对应,具体内容可以参见方法实施例的相关描述,在此不再详细说明。
本实施例中,通过根据语言模型对搜索结果进行打分,并且语言模型是根据不同来源的数据训练生成的,可以根据打分结果确定搜索结果的来源,为满足搜索结果多样化等需求提供基础。
可以理解的是,上述各实施例中相同或相似部分可以相互参考,在一些实施例中未详细说明的内容可以参见其他实施例中相同或相似的内容。
需要说明的是,在本申请的描述中,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本申请的描述中,除非另有说明,“多个”的含义是指至少两个。
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本申请的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本申请的实施例所属技术领域的技术人员所理解。
应当理解,本申请的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(PGA),现场可编程门阵列(FPGA)等。
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
此外,在本申请各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
上述提到的存储介质可以是只读存储器,磁盘或光盘等。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本申请的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管上面已经示出和描述了本申请的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本申请的限制,本领域的普通技术人员在本申请的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!