一种从课件文本自动抽取知识单元间学习依赖关系的方法与流程
本发明涉及学习依赖关系的方法,具体涉及一种从课件文本自动抽取知识单元间学习依赖关系的方法。
背景技术:
随着人类科学技术的迅猛发展,人类知识总量呈现出爆炸式增长。根据联合国教科文组织的统计,人类近30年所积累的知识占有史以来知识总量的90%,并且知识的倍增周期仍在不断缩短,目前已减至5-7年。知识总量的快速增长为知识的有效获取和表达带来了严重挑战。传统解决方案是通过搜索引擎为用户反馈出相关文档。这种方式不能直接反馈用户感兴趣的知识,需要用户花费很大精力从大量相关文档中进行筛选。知识图谱技术采用RDF三元组表示的语义网络,旨在实现搜索引擎从“机械罗列”向“网络集知”发展,为用户提供语义化、关联式信息检索,在一定程度上缓解了上述问题。但是知识图谱不是为了面向主题的认知学习,无法体现各主题间的认知关系,容易导致学习迷航问题。知识地图依据人类认知学习的特点,将知识与知识间的关系组织成图的形式,形成了一种高效的表示知识及知识间组织结构的方式,为缓解学习迷航问题提供了有效的方法。
学习依赖关系描述了知识单元之间在认知过程中互相依赖的关系。判定两个知识单元是否有关系,是知识地图构建中的一项基本但非常重要的工作。目前,高质量的知识地图,仍需要领域专家根据领域知识来标注知识单元之间的学习依赖关系,构建过程比较缓慢。因此,设计有效的学习依赖关系挖掘算法,将大大提高知识地图构建速度,减少人力消耗,有助于推动以知识地图为基础的导航学习的研究与应用。
针对知识单元之间学习依赖关系挖掘的方法,专利号为ZL201110312882.1,名称为一种面向文本的知识单元关联关系挖掘方法,提出的方法包括如下步骤:(1)文本关联挖掘:对文本集合进行聚类,找到具有相似主题的文本对,并利用核心术语分布的不对称性,挖掘文本间的线性关联关系;(2)生成候选知识单元对:利用知识单元关联关系的局部性,产生候选的知识单元对;(3)特征选择及知识单元关联关系挖掘:基于知识单元对的术语词频、距离和语义类型特征,使用SVM分类器将候选的知识单元对进行二值分类,挖掘知识单元间的关联关系。该方法可大大减少候选知识单元个数,在保证精度的前提下,有效地降低了关系挖掘的时间复杂度。由于其利用了学习依赖关系的局部性,上述方法难以抽取距离较远的知识单元之间的学习依赖关系。
技术实现要素:
为了解决现有技术中的问题,本发明提出一种从课件文本自动抽取知识单元间学习依赖关系的方法,能够对课件文本进行自动分析,识别出文本中的术语并计算出术语对知识单元的关键程度,并通过最优化术语之间的关系得到学习依赖关系挖掘的模型,过程不依赖于学习依赖关系的局部性,能够用来挖掘主题关联较远的知识单元之间的学习依赖关系,为学习者提供更为完整的知识导航服务。
为了实现以上目的,本发明所采用的技术方案为:包括以下步骤:
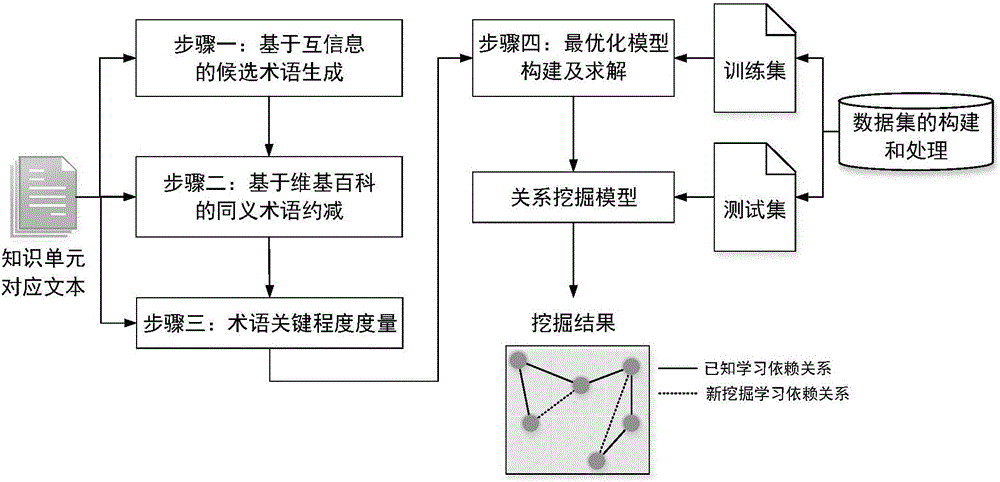
1)基于互信息的候选术语生成:首先将课件文档转换成文本格式,并进行分词处理;然后利用互信息衡量相邻词汇结合的紧密程度,并对结合紧密的词汇进行合并处理,从而得到候选术语集合;
2)基于维基百科的同义术语约减:爬取术语对应的维基百科页面,利用维基百科页面中的重定向标志和多语言链接,对同义术语进行约减处理;
3)术语关键程度度量:首先计算每个术语对应的TF-IDF参数值,然后利用知识单元名称特征和格式特征对TF-IDF参数值进行加权处理,以此衡量每个术语对知识单元的关键程度;
4)最优化模型构建及求解:建立知识单元之间学习依赖关系与术语关系之间的定量表示,将模型求解问题转化为最优化问题,构建出最优化的目标函数,并利用梯度下降算法进行模型求解,完成从课件文本自动抽取知识单元间学习依赖关系。
所述步骤1)包括以下步骤:
1.1)使用poi工具包将知识单元对应课件中的文本抽取出来,并进行分词、去除停用词处理;
1.2)设分词之后,原有的字符串c被分成了两个词a和b,将字符串c在语料中的共现频率记为f(c),将字符串c在语料中的共现概率记为p(c),依据最大似然估计法则,在数据量足够大的情况下,认为p(c)等于f(c),将每个词视为事件,对于字符串c=ab,其互信息公式为:利用互信息来衡量字符串的内部结合紧密程度,得到候选术语集合。
所述步骤2)包括以下步骤:
2.1)同义词典扩充:以同义词典为基础,利用维基百科页面中的重定向标志和多语言链接,对同义词典进行扩充;
2.2)同义术语约减:利用经过维基百科扩充的同义词典,对候选术语集合中的同义术语进行约减处理。
所述步骤2.2)中约减处理的方式为:对于含有同义词项的术语A,找到与术语A具有相同含义并且出现频率最高的术语B,在候选术语集合中用术语B替换术语A。
所述步骤3)包括以下步骤:
3.1)对候选术语集合CT'中的每一个术语,通过TF-IDF指标计算其对每个知识单元的基本关键程度,TF-IDF指标计算公式为:式中:fij表示术语i在文档dj中的词频;dfi表示术语i的文档词频;N表示文档总数;ni表示文档中出现术语i的文档数;
3.2)基于知识单元名称的加权:通过考察术语是否出现在知识单元名称中对原始的TF-IDF参数进行加权,加权公式为:Namei,j=wname×bi,j,式中:wname表示知识单元名称加权权重;bi,j表示术语i是否出现在知识单元j的名称中;
3.3)基于格式特征的加权:通过术语所在位置的字体大小,对术语的关键程度进行加权处理,加权公式如下:式中:wfont表示字体大小加权权重;k表示知识单元j对应课件中所有不同字体大小;fi,k表示术语i是否以字体大小k出现;rankk表示所有字体大小逆序排序后,字体大小k的排序值;
3.4)通过知识单元名称以及课件字体对原始TF-IDF参数进行综合加权,得到术语关键程度,加权的公式为:scorei,j=wi,j×(1+Namei,j+Fonti,j),式中:scorei,j表示术语i对知识单元j的关键程度。
所述步骤4)包括以下步骤:
4.1)目标函数构建:对于知识单元i和知识单元j,通过下式衡量它们之间存在学习依赖关系的可能性:式中:xi是由所有术语对知识单元i的关键程度构成的向量,向量中每一个元素代表相应术语对知识单元i的关键程度;A矩阵代表模型的参数;
对知识单元i,设集合Ωi={(i,j)|yij=1,j=1,2,...,n}是所有与知识单元i存在学习依赖关系的知识单元与知识单元i组成的节点对,集合为所有与知识单元i不存在学习依赖关系的知识单元与知识单元i组成的节点对,令定义如下最优化问题:
式中:X是一个矩阵,矩阵中第i行由构成;(1-v)+代表hinge损失函数;||A||F代表矩阵A的弗罗贝尼乌斯范数;
4.2)模型求解:对最优化问题,使用加速梯度下降进行求解:
令则原目标函数写成:公式对A求导,得到梯度:
式中:ei、ej、ek都是单位向量;
4.3)学习依赖关系挖掘:通过步骤4.2)得到模型的最优化参数A矩阵,对于任意两个知识单元,通过最优化模型判断它们之间是否存在学习依赖关系。
与现有技术相比,本发明通过处理知识单元对应课件中的文本,得到候选术语集合,然后处理候选术语集合中的同义术语,并计算每个术语对知识单元的关键程度,构建出最优化模型,通过求解得到最优化的学习依赖关系抽取模型,能够对课件文本进行自动分析,识别出文本中的术语并计算出术语对知识单元的关键程度,并通过最优化术语之间的关系得到学习依赖关系挖掘的模型,该过程不依赖于学习依赖关系的局部性,能够用来挖掘主题关联较远的知识单元之间的学习依赖关系,为学习者提供更为完整的知识导航服务。本发明能够利用知识单元对应课件中的文本自动抽取知识单元之间的学习依赖关系,减少了人工构建知识地图的成本,有助于推动以知识地图为基础的导航学习的研究与应用。
附图说明
图1为本发明的方法流程框架图;
图2为公式(6)的图形化示意图;
图3为《Java语言》学习依赖关系挖掘部分数据示例图。
具体实施方式
下面结合具体的实施例和说明书附图对本发明作进一步的解释说明。
参见图1,本发明具体包括以下步骤:
1)基于互信息的候选术语生成,主要包括2个步骤:
1.1)使用poi工具包将知识单元对应PPT课件中的文本抽取出来,并进行分词、去除停用词处理;
1.2)设分词之后,原来的字串c被分成了两个词a和b。将字符串c在语料中的共现频率记为f(c),将字符串c在语料中的共现概率记为p(c),那么,依据最大似然估计法则,在数据量足够大的情况下,可以认为p(c)等于f(c),如果将每个词视为事件,对于字符串c=ab,其互信息公式为:
利用互信息来衡量字符串的内部结合紧密程度,从而达到抽取候选术语的目的。基于互信息的候选术语生成算法具体步骤如下所示:
输入:分词结果集合Tokens={word1,word2,...,wordn},Tokens中词汇个数n,词频统计信息TF,阈值w
算法流程:
输出:候选术语集合CT
2)基于维基百科的同义术语约减,主要包括2个步骤:
2.1)同义词典扩充:以《同义词词林》为基础,利用维基百科页面中的重定向标志和多语言链接,对同义词词典进行扩充,同义词典扩充具体算法如下所示:
输入:候选术语集合CT={term1,term2,...,termn},CT中词汇个数n,同义词典D={(term1,...,termi)},其中(term1,...,termi)为i个具有相同含义的术语
算法流程:
输出:经过扩充的同义词典D
2.2)基于同义词典的同义术语约减:利用经过维基百科扩充的同义词典,本文对候选术语集合中的同义术语进行了统一处理,处理的基本方式是,对于含有同义词项的术语A,找到与术语A具有相同含义并且出现频率最高的术语B,在候选术语集中用术语B替换术语A,相应算法如下所示:
输入:候选术语集合CT={term1,term2,...,termn},CT中词汇个数n,同义词典D={(term1,...,termi)},其中(term1,...,termi)为i个具有相同含义的术语,词频统计信息TF
算法流程:
输出:CT'
3)术语关键程度度量,主要包括4个步骤:
3.1)对候选术语集合CT'中的每一个术语,通过TF-IDF指标计算其对每个知识单元的基本关键程度,TF-IDF指标计算公式如下:
式中:fij表示术语i在文档dj中的词频;dfi表示术语i的文档词频;N表示文档总数;ni表示文档中出现术语i的文档数;
3.2)基于知识单元名称的加权:出现在知识单元名称中的术语很有可能是该知识单元的关键术语,可以通过考察术语是否出现在知识单元名称中对原始的TF-IDF参数进行加权,加权公式如下:
Namei,j=wname×bi,j (3)
式中:wname表示知识单元名称加权权重;bi,j表示术语i是否出现在知识单元j的名称中;
3.3)基于PPT格式特征的加权:在PPT的分级展示中,层级越高,字体一般越大,其所表达的内容越重要,因此,可通过术语所在位置的字体大小,对术语的关键程度进行加权处理,加权公式如下:
式中:wfont表示字体大小加权权重;k表示知识单元j对应课件中所有不同字体大小;fi,k表示术语i是否以字体大小k出现;rankk表示所有字体大小逆序排序后,字体大小k的排序值;
3.4)通过知识单元名称以及课件字体对原始TF-IDF参数进行综合加权的公式为:
scorei,j=wi,j×(1+Namei,j+Fonti,j) (5)
式中:scorei,j表示术语i对知识单元j的关键程度;
4)最优化模型构建及求解,主要包括3个步骤:
4.1)目标函数构建:首先,对于知识单元i和知识单元j,通过下式衡量它们之间存在学习依赖关系的可能性:
式中:xi是由所有术语对知识单元i的关键程度构成的向量,向量中每一个元素代表相应术语对知识单元i的关键程度;A矩阵代表模型的参数,如图2所示,公式(6)可理解为从知识单元i到知识单元j之间所有路径的权重之和;
对知识单元i,设集合Ωi={(i,j)|yij=1,j=1,2,...,n},即该集合是所有与知识单元i存在学习依赖关系的知识单元与知识单元i组成的节点对,集合即该集合是所有与知识单元i不存在学习依赖关系的知识单元与知识单元i组成的节点对,对于一个合理的模型参数A,希望在集合Ωi中的每对知识单元所对应的公式的分值都要大于集合中每对知识单元的分值,令定义如下最优化问题:
式中:X是一个矩阵,矩阵中第i行由构成;(1-v)+代表hinge损失函数;||A||F代表矩阵A的弗罗贝尼乌斯范数;
4.2)模型求解:对于公式(7)所示的最优化问题,可以使用加速梯度下降(AcceleratedGradient Descent)进行求解:
令则原目标函数可以写成:
公式(8)对A求导,得到梯度:
式中:ei、ej、ek都是单位向量,具体计算方法如下所示:
输入:X,T,λ,η,最大迭代次数N
算法流程:
输出:A
4.3)学习依赖关系挖掘:通过步骤4.2),可以得到模型的最优化参数A矩阵,此时,对于任意两个知识单元,都可以通过该最优化模型判断它们之间是否存在学习依赖关系,如图3展示了《Java语言》课程学习依赖关系挖掘结果的部分示例,图中实线代表已知的学习依赖关系,虚线代表需要判断的知识单元对,虚线上的数字代表该知识单元对具有学习依赖关系的可能性。
- 还没有人留言评论。精彩留言会获得点赞!