一种多元数据微融合的方法与流程
本发明涉及数据挖掘领域,具体地,涉及一种数据匿名保护的方法。
背景技术:
现实生活中,有很多数据需要公开作为人们的参考,常见的有医疗数据,人们的部分日常健康数据,地理位置数据等等,而这些数据本身可能与用户的信息相关,比如有研究表明人们日常活动的地理信息直接与其身份相关。不加保护的直接公布用户的信息会导致严重的隐私泄露,危害用户的隐私安全。
基于用户隐私的考虑,Latanya Sweeney在2002年International Journal of Uncertainty,Fuzziness and Knowledge-Based Systems上发表了k-ANONYMITY:A MODEL FOR PROTECTING PRIVACY(k匿名:保护数据隐私的一个模型)提出了k匿名的概念。k匿名要求将用户的某种数据与其他至少k-1个人的数据组合在一起发表,这样恶意用户就不能分别其中一个数据和剩余的k-1个数据的区别,实现了用户隐私数据的保护。然而,在隐私保护的同时,会带来数据信息损失,以地理位置的隐私保护来说,关于地理位置的k匿名保护包含位置隐藏,提交噪声,信息存储等等,这些在LBS系统中和群智系统中都有研究。为了保护用户的地理位置隐私,地理位置常常会被过度处理,使得处理后的位置与原本的位置相差很大,处理后的位置保护的隐私但是不能传递该有的信息。因此,在保护数据k匿名隐私的同时减少处理带来的信息损失是非常必要的。
对现有技术进行检索发现,Josep Domingo-Ferrer等在2002年IEEE Transactions on Knowledge and Data Engineering上发表的Practical data-oriented microaggregation for statistical disclosure control(实际数据导向的微融合以控制统计泄露)中提出了一种保护k匿名的微融合技术,并表明多元数据的微融合是NP-hard,最优的结果中每个分组的大小在k与2k-1之间,基于该文的结果,文章作者在后续的研究中提出了MDAV方法微融合多元数据,该方法因为固定的分组大小和简单的分组机制,使得分组带来的信息损失仍然较大。Agusti Solanas等在2006年COMPSTAT Symposium of the IASC上发表的V-MDAV:a multivariate microaggregation with variable group size(V-MDAV:一种多元变量的微融合并允许可变组大小)中基于MDAV提出了可变分组的思想,但是该分组方式较为简单只能一定程度上减少信息损失。George Kokolakis等在2009年在Computational Statistics Data Analysis中发表的Importance partitioning in microaggregation中提出了IP方法以分组中心决定加入的下一个数据,但是仍然是固定的分组大小,只能在一定程度上降低信息损失。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提出一种多元数据微融合方法,通过可变分组大小与比较数据与分组中心距离,实现信息损失的降低。
为达到上述目的,本发明所采用的技术方案如下:
一种多元数据微融合的方法,多元数据X={x1,x2,...,xN},每一个数据元素可以表示为xi={yi1,yi2,...,yin}:包括如下步骤:
步骤一,为了匿名保护,需要将数据集X分组,每一组的数据数量不小于k,在完成分组的同时需要尽量减少因为分组带来的信息损失:
步骤二,计算数据集的全局中心以及各个数据之间的欧式距离;
步骤三,判断数据集中剩余数据的数量,如果小于k,转到步骤六,否则计算距离全局中心最远的数据,并生成一个新的分组;
步骤四,依次选择距离分组数据中心最近的数据加入到分组,新的数据加入后重新计算分组中心,直至分组数据数量为k;
第五步,对分组进行扩展,使用分组的中心判断新的数据是否加入,并保证每每一个分组的数量不超过2k-1,转至步骤二;
步骤六,将剩余的数据分别添加到信息损失增加最小的分组,并输出分组结果。
步骤一包括:
步骤1.1,数据集大小N远大于k,分组的目的为了保护匿名隐私,信息损失衡量分组带来的数据信息丢失程度,信息损失越小数据的保真度越高;
步骤1.2,假设得到Nk个分组对于分组gi,其组内平方和为:
其中ni为数据数量,T是转置,xij与分别为gi中第j个元素和中心。所有的组内平方和为:
SSE描述了数据分组后的一致性。
步骤1.3,数据集X的所有平方和为:
其中为数据集的全局中心,可以知道SST与数据的分组无关,当数据集给定后SST也就确定了;
步骤1.4,分组的信息损失定义为SSE与SST的比值:
可以知道IL仅与SSE相关,最小化IL只需要最小SSE。
步骤二包括:
步骤2.1,对于数据集X,其全局中心为:
即:
步骤2.2,对于数据集X中的任意两个元素xi,xj其欧式距离定义为:
步骤三,计算数据集中剩余的数据数量,如果数量小于k则转到步骤六,否则选取距离最远的数据xi,并生成新的分组。
步骤四包括:
步骤4.1,对于分组gi,假设已经有ni个数据,则该分组的中心为:
选择选择距离最近的数据加入到分组gi中,并跟新直至gi的数据数量为k;
步骤4.2,对于分组gi,其中心的更新按照如下方式:
其中x′是新加入的数据;
步骤4.3,选择距离分组中心最近的数据元素加入是为了减少信息损失的增加量,假设x′需要加入到分组gi中,原组内平方和ssei为:
当x′加入时,组内平方和变为:
这里将x′看做是第(ni+1)个元素,那么组内平方和的增加为:
这就是说选择距离分组中心最近的数据加入可以减少组内平方和的增加,也就是减少信息损失的增加。
步骤五包括:
步骤5.1,在每个分组数据数量不小k时,最优分组大小应该在k与2k-1之间,因此在扩展分组的大小不能超过2k-1;
步骤5.2,假设距离gi中心最近的数据为xout,其距离为在没有被加入分组的数据集中,距离xout最近距离为dout,如果满足:
则将xout加入到gi;
步骤5.3,当上式不满足或者分组大小到达2k-1则终止。
步骤六包括:
步骤6.1,对于剩余的数据,比较其距离已有的分组的中心,选择最小的分组加入;
步骤6.2,其中是数据加入分组时组内平方和增加的系数,加入后更新该分组的中心。
与现有技术相比,本发明具有如下有益效果:
第一,每一个分组的数据数量不小于k保证了数据匿名的需求,同时可以在多项式时间内得到结果;
第二,相比较已有方法,本发明可以进一步减少因数据保护带来的信息损失。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明的工作流程图;
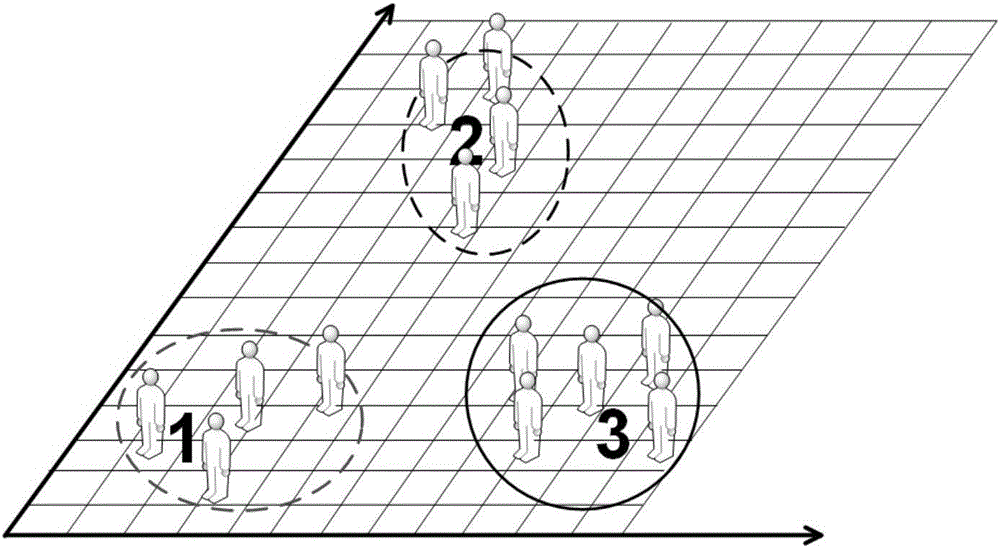
图2为本发明的微融合地理位置的实例;
图3是本发明的伪码;
图4是本发明的部分结果演示。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
本发明利用可变分组大小和以分组中心为参考点选择新的加入数据实现了数据匿名保护的同时尽量降低信息损失租车的智能调度。
参见图1,图2,和图3,下面更详细地将本发明的实施过程进行阐述。
第一步,为了匿名保护,需要将数据集X分组,每一组的数据数量不小于k,在完成分组的同时需要尽量减少因为分组带来的信息损失,对于分组gi,其组内平方和为:
其中ni为数据数量,T是转置,xij与分别为gi中第j个元素和中心。所有的组内平方和为:
第二步,计算数据集的全局中心与以及任意两个元素xi,xj其欧式距离
第三步,判断数据集中剩余数据的数量,如果小于k,转到第六步,否则计算距离全局中心最远的数据,并生成一个新的分组;计算数据集中剩余的数据数量,如果数量小于k则转到步骤六,否则选取距离最远的数据xi,并生成新的分组。
第四步,依次选择距离分组数据中心最近的数据加入到分组,新的数据加入后重新计算分组中心,直至分组数据数量为k;对于分组gi,假设已经有ni个数据,则该分组的中心为假设x′需要加入到分组gi中,原组内平方和ssei为:
当x′加入时,组内平方和变为:
这里将x′看做是第(ni+1)个元素,那么组内平方和的增加为:
这就是说选择距离分组中心最近的数据加入可以减少组内平方和的增加,也就是减少信息损失的增加。
第五步,对分组进行扩展,使用分组的中心判断新的数据是否加入,并保证每每一个分组的数量不超过2k-1,转至第二步;假设距离gi中心最近的数据为xout,其距离为在没有被加入分组的数据集中,距离xout最近距离为dout,如果满足:
则将xout加入到gi;当上式不满足或者分组大小到达2k-1则终止。
步骤六,将剩余的数据分别添加到信息损失增加最小的分组,并输出分组结果,选择最小的分组加入。
图4所示,本发明一个实施例具体地展示系统的工作流程和实际效果。本实施例采用http://crawdad.org/cmu/supermarket/20140527中的数据集,该数据集包含有室内定位的两个坐标,为了保留大量重复的数据,对原有数据添加小的噪声。此外合成一个在50*50范围内的地理位置数据集,并对数据实现k=3,4,5的匿名保护,计算匿名保护后的组内平方和,并与MDAV,V-MMAD以及IP做对比。该数据的结果是在一天配置32G内存i7处理器的Windows电脑上得到的。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!