一种面向异构网页的数据收集与标注方法与流程
本发明涉及互联网信息检索和挖掘技术领域,尤其涉及一种面向异构网页的数据收集与标注方法。
背景技术:
网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。网络爬虫一般驻留在服务器上,通过给定的一些 URL(Uniform Resource Locator,统一资源定位符),利用 HTTP(Hyper Text Transfer Protocol,超文本传输协议 ) 等标准协议读取相应文档,然后以文档中包括的所有未访问 URL 作为新的起点,继续进行漫游,直到没有满足条件的新URL为止。互联网作为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。
传统的网络爬虫技术的通常做法是,在已获得的网页中,抽取出所有的URL,并根据这些新的URL链接获取新的网页。然而,随着互联网信息的爆炸式增长,传统的网络爬虫采集系统已经逐渐显示出劣势。传统网络爬虫系统的目标是尽可能高速、全面地将网络上的网页爬取到本地存储中,在收集数据时并不会对数据进行相应的划分工作。因此,传统的爬虫技术只会漫无目的地爬取网页,从而导致了资源的浪费。在数据挖掘等领域的后续工作中,无法得以良好的应用。除此之外,虽然网页的数据量是极其庞大的,但是实际上用户所关心的在页面上数据只是页面中的一块内容。例如,在新闻页面中,可能会存在广告栏,导航栏等等文本信息,这些都不是用户所关心的部分,而传统的网络爬虫技术无法准确识别页面的内容,只会单纯地将整个页面下载下来,而不会根据一定的要求,将网页上的文本,图片等数据下载下来,形成结构化数据。
此外,对于带有AJAX请求的页面,传统的网络爬虫在执行方式上就需要一个模拟的浏览器加载该网页的页面并且执行该网页需要执行的 JavaScript 脚本(其中包括异步请求),并且在加载完成之后,还支持通过该AJAX抓取配置来模拟用户操作,例如点击按钮、提交表单等,然后再根据元素路径提取该网页的页面中的元素所需要的值,例如内容、链接、图像识别结果等。这种方式通常要等待JavaScript脚本在页面的运行,需要同步地去获取信息,获取效率慢。因此,现有技术还有待改进与发展。
技术实现要素:
本发明的目的是针对现有技术存在的问题而提供的一种面向异构网页的数据收集与标注方法,旨在解决数据收集与分类的整合问题,使得下一步工作的应用得以良好的进行。
本发明的目的是这样实现的:
一种面向异构网页的数据收集与标注方法,特点是该方法包括以下具体步骤:
步骤1:从初始的URL中获取网页;
步骤2:向所获取的网页的服务器发送HTTP请求,并将请求的内容返回到客户端;
步骤3:客户端接到请求后,使用解析器对HTML页面进行解析;
步骤4:使用正则表达式匹配所需的信息,并获取其中的超链接,筛选出数据库中重复的超链接后,将该超链接加入到爬虫队列中;
步骤5:重复上述步骤2-4,依次完成并添加结构化的数据到数据库中;
步骤6:对数据库中获取到的数据进行数据清洗工作;
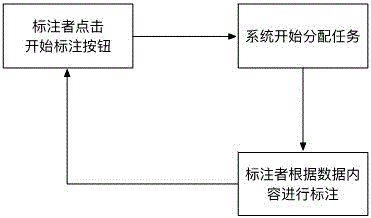
步骤7:标注人使用标注系统,从数据库中分配相应的标注任务开始标注;
步骤8:标注人完成一个标注任务后,重复请求服务器进行分配任务;
步骤9:重复标注步骤7、步骤8直至数据已标注完毕。
所述步骤3中,使用解析器对HTML页面进行解析:针对AJAX请求进行解析,对请求的参数进行自定义,遍历参数进行多次请求,从而得到更多的链接,并存储到文本中。
所述步骤4具体包括:
对于不同的网站内容会有不同的网页页面结构,通过采用Xpath与正则表达式的方式解析当前页面是否存在特定页面DOM节点,从而判定属于哪类网页页面结构,以便于下面步骤中解析数据的工作,同时,在解析数据的同时,采用正则表达式对URL链接进行匹配,用以判断该页面内容是否属于所需内容,从而给下面的分类工作提供一个先验知识,简化标注人的工作量。
所述步骤7中,所述开始标注:在数据收集过程中的初始分类信息会自动地在分类中默认勾选,从而标注人只需要判断默认标注是否正确、标注小类和数据是否有误即可。
本发明的方法,在数据收集上解决了传统网络爬虫无法收集含有AJAX动态技术的页面。
同时,本发明还将数据的收集与分类一体化整合,在数据收集后能直接通过标注对数据进行分类,形成流水线式的工作,增加了工作效率,以便于下面数据挖掘等工作的开展。
与现有技术相比,本发明通过将数据的收集与分类一体化整合,在数据收集上解决了传统网络爬虫无法收集含有AJAX动态技术的页面,提高了工作效率,节约了CPU资源,大大节约了服务器的存储空间。同时,在分类上,给出一个默认的分类信息,并具有一定的准确性,用户只需判别这个默认的分类信息是否准确并细分小类即可,提高了识别效率。
本发明提出的一种面向异构网页的数据收集与标注方法,能够有效地整合数据的收集与数据的分类操作,使得接下来工作(例如数据挖掘)的进展能够高效地进行。相比传统的数据收集方法,本发明收集质量更高,垃圾数据收集率低,数据分类准确。
附图说明
图1为本发明实施例的流程图;
图2为本发明网页数据标注的流程图。
具体实施方式
下面结合附图及实施例对本发明进一步说明,但并不因此将本发明限制在所述的实施例范围之中。本实施例提供一种以教育与非教育数据为例的面向异构网页的数据收集与标注方法,如图1所示,包括以下步骤:
在本实施例的数据收集阶段,采用了基于Python的一款网络爬虫框架Scrapy,用于收集互联网的教育与非教育数据。Scrapy提供了一个快速,高层次的屏幕抓取和WEB抓取框架,用于抓取WEB站点并从页面中提取结构化的数据。通过这款框架简单快速地开发爬虫应用,并抽取相应的数据到数据库中,从而用于各式各样的用途,例如:数据挖掘,信息处理等等。
在本实例的数据标注阶段,将数据分为教育类与非教育类。在教育类下又细分学前教育、小学教育、初中教育、高中教育、大学教育、留学教育和其他教育。数据同时又分为文本型数据、图片型数据和混合型数据。
以腾讯教育网为例,2015年后的页面与2015年之前的页面有着结构上的不同。因此需要在数据收集前对网站的结构进行匹配,从而进一步选择对应的收集算法来抽取页面上的数据。一种互联网资源的收集方法包括以下步骤:
S1、客户端将一预设URL(Uniform Resource Locator,统一资源定位符)链接的请求发送至服务器;
S2、该服务器根据该预设URL链接的请求响应相应的HTML代码,并返回客户端;
S3、客户端根据相应的HTML代码,通过使用XPath将其进行解析网页上的超链接,使用正则表达式匹配期望链接的URL,过滤URL并加入到请求队列;
S4、客户端通过解析到不同的代码,判断是否存在对应页面的特征DOM节点,从而采用不同的爬虫算法抽取数据;
S5、使用对应的抓取算法收集到网页数据后,通过采用正则表达式对获取的HTML代码进行去除标签代码的工作,从而获得更为干净的数据,将数据结构化;
S6、将结构化的数据存入数据库。数据收集阶段结束,接下来进行数据的标注阶段;
S7、标注开始前,先为每位标注用户注册一个账号用于登录与记录标注;
S8、标注用户登录系统开始进行标注,系统开始分配标注任务;
S9、该系统会采用按文档收集时间顺序抽取一些未标注的数据,并对数据进行预标注,然后标注者根据页面上数据显示的内容进行标注修正;
S10、重复上述步骤S8、S9直至标注阶段完成。
在本实施例中,客户端预设了一个URL的去重操作,在每次请求前可以到数据库中与已经获取的数据进行比对。若该URL已在数据库中已经存在,则抛弃该数据而无需进一步解析。大大节约了服务器的存储空间,又减少了后续工作展开的复杂性。
在步骤S4中,判断页面结构的代码案例如下:
def create_strategy(response, site=None):
if site is Site.tencent: # 腾讯新闻
current_sel = response.xpath("//div[@id='Cnt-Main-Article-QQ']")
outdated_sel = response.xpath("//div[@id='cntL']")
if current_sel: # http://edu.qq.com/a/20160323/013157.htm
return CurrentStrategy(response, current_sel)
if outdated_sel: # http://edu.qq.com/a/20081231/000007.htm
return OutdatedStrategy(response, outdated_sel)
return None
步骤S5中,使用正则表达式去除标签代码的实例代码如下:
content = re.sub(r'<\s*script[^>]*>[^<]*<\s*/\s*script\s*>', '', content)
content = re.sub(r'<\s*style[^>]*>[^<]*<\s*/\s*style\s*>', '', content)
content = re.sub(r'<[^>]*>', '', content)
在步骤S9中,标注任务的具体步骤如下:
1)、根据数据收集时获得的初始数据标注信息,在教育与非教育类下分别抽取10条数据,并以时间顺序进行排序。
2)、在用户标注界面,前十条默认选中教育类,后十条默认选中非教育类。标注者需要点击相应的链接查看数据的来源是否正确,是否存在问题,修改所收集数据的内容,修改标注信息。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这些仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!