一种基于规则的敏感文本过滤方法与流程
本发明涉及信息过滤技术领域,尤其涉及一种基于规则的敏感文本过滤方法。
背景技术:
每年因为垃圾邮件、诈骗信息、个人信息泄露等内容安全问题,导致我国网民严重的经济损失。究其原因,多数垃圾广告来源于论坛,博客,微博等UGC平台上,这违反了国家的相关法律法规,并且降低了用户体验。对于垃圾信息,必须在源头上遏制垃圾信息的发布。有些UGC平台商为了应付垃圾内容,研发了审核系统,方便人工审核,并让该板块的管理员来进行人工审核,通过了才让内容发布到互联网上。另外也存在基于语义理解的反垃圾系统,系统可以分析上下文的语义,并判断是否垃圾信息的概率有多大;
审核模块可以方便管理员审核,而且人工审核会比较准确,但是很难做到覆盖到100%的UGC内容,特别是产生大量UGC内容的平台,并且需要花费大量的人力;对于基于语义的反垃圾系统,可以克服上面的缺点,但是也存在一些缺点:一、机器学习需要大量的学习语料,二、系统容易误杀一些正常的文本,三、学习新的垃圾规则需要一定的时间,所以对于出现的新的垃圾内容的反垃圾需要一定的学习时间才能识别出来,四、对于误杀的内容比较难进行干预去除。
另外也有些系统使用了更简单的方案,就是大量使用正则表达式,但是配置起来很不方便,针对上述的一些缺点,上述的技术方案还需要其他可以互补的方案,可以更快速智能的识别垃圾信息。
因此,本领域技术人员亟需开发出一种添加规则简单并且可快速识别敏感文本,一般管理人员就能提炼并添加规则,添加的规则马上生效,可以智能识别缩小规则库,只需要完善词库即可,不需要添加大量的规则,匹配速度快的基于规则的敏感文本过滤方法。
技术实现要素:
本发明要解决的技术问题是提供一种基于规则的敏感文本过滤方法,该基于规则的敏感文本过滤方法添加规则简单并且可快速识别敏感文本,一般管理人员就能提炼并添加规则,添加的规则马上生效,可以智能识别缩小规则库,匹配字符时,只需要完善词库即可,不需要添加大量的规则,匹配速度快。
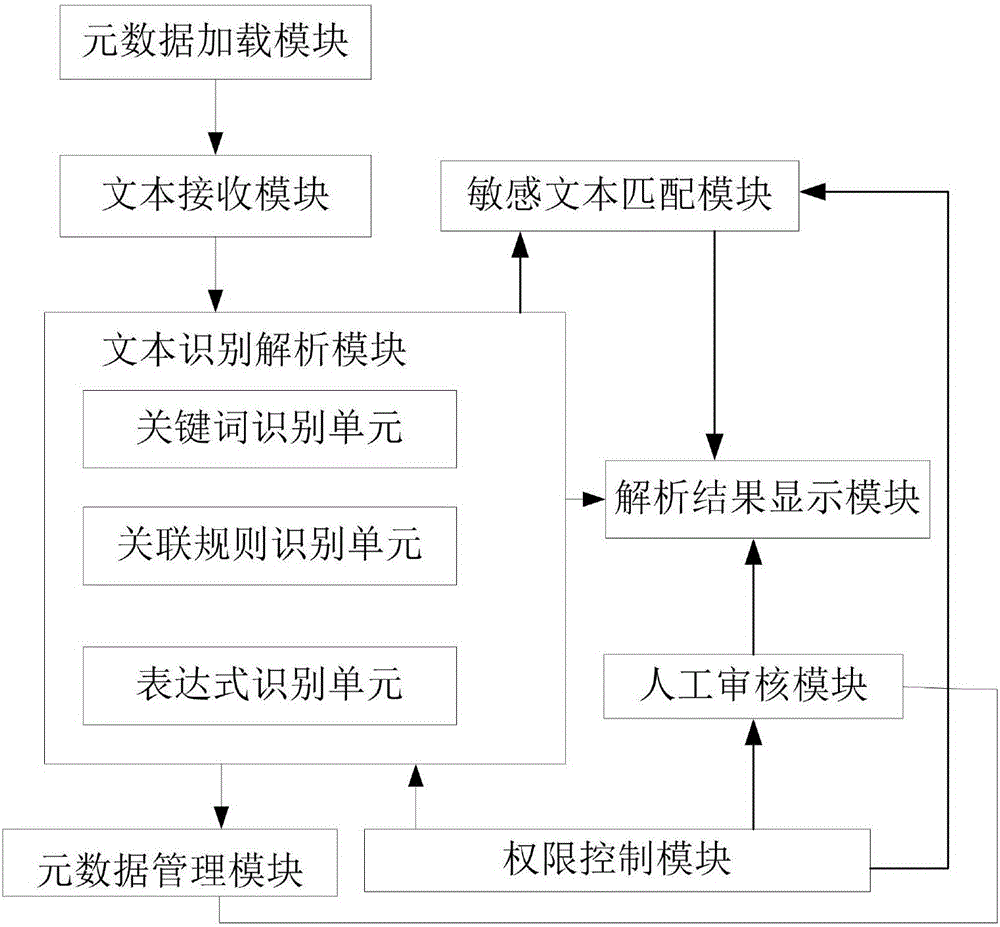
为解决上述技术问题,本发明提供了一种基于规则的敏感文本过滤方法,提供文本接收模块、文本识别解析模块、元数据加载模块、基础数据存储模块、元数据管理模块、权限控制模块、解析结果显示模块及人工审核模块,所述文本识别解析模块包括关键词识别单元、关联规则识别单元、表达式识别单元;所述元数据加载模块与所述文本接收模块连接,所述文本识别解析模块与所述文本接收模块连接,所述文本识别解析模块与所述解析结果显示模块、所述权限控制模块与所述文本识别解析模块及人工审核模块连接,所述人工审核模块与所述解析结果显示模块连接;
所述基于规则的敏感文本过滤方法包括以下步骤:所述元数据加载模块把元数据加载到系统内存中并形成数据结构,所述元数据加载模块将待过滤的文本传输给所述文本接收模块,所述元数据管理模块配置有敏感的关键词、关联规则及待识别的表达式,所述文本接收模块接收待过滤的文本并传输给所述文本识别解析模块,所述文本识别解析模块采用AC自动机算法构建trie树对文本进行解析;
所述关键词识别单元将所述文本识别解析模块中的待过滤的文本与元数据管理模块中的关键词进行解析识别;
所述关联规则识别单元将所述文本识别解析模块中的待过滤的文本根据元数据管理模块中的关联规则进行解析识别,所述关联规则为若干词组成违反设置的规则;
所述表达式识别单元将所述文本识别解析模块中的待过滤的文本根据元数据管理模块中的表达式进行解析识别;
所述关键词识别单元将所述文本识别解析模块中的待过滤的文本根据元数据管理模块中的关键词进行解析识别;
当字符匹配,从当前节点沿着树边有一条路径到达目标字符,沿该路径走向下一个节点继续匹配,目标字符串指针移向下个字符继续匹配;当字符不匹配,则去掉当前节点失败指针所指向的字符继续匹配,匹配过程随着指针指向root结束;重复“字符匹配”或“字符不匹配”中的任意一个过程,直到模式串走到结尾为止。
优选地,所述元数据管理模块对所述基础数据管理模块的基本数据做管理,根据板块设置添加词库和规则,如果没有设置则为默认板块。
优选地,还提供敏感文本匹配模块,所述敏感文本匹配模块与文本识别解析模块及解析结果显示模块连接,所述敏感文本匹配模块采用SWDT-IFA算法设计定位敏感词,定位到敏感词出现的位置后,判断敏感词是否直接是禁止词,根据距离和敏感词关联的规则或者正则表达式来判断是否满足了敏感规则。
优选地,所述步骤“所述敏感文本匹配模块采用SWDT-IFA算法设计定位敏感词”的实现步骤包括:所述敏感文本匹配模块将文本进行去停用词预处理,将敏感词通过敏感词决策树构建算法建立成一棵分流树,将预处理过的文本,以文本数据流方式检索敏感词决策树,记录文本中对应敏感词的频率和区域信息,通过敏感度计算公式,得出文本整体敏感度,对应网页划分为敏感、非敏感网页。
优选地,所述敏感度计算公式为:Aford={a0,a1,…,ai,…,an-1},(0≤i<n),n为敏感词个数,ai表示敏感词;ai={ai,0,…,ai,j,…,ai,m-1},(0≤j<m),
其中,ai,j表示第i个敏感词的第j个敏感字,m表示敏感词长度。
优选地,所述敏感文本匹配模块采用所述敏感度计算公式的执行步骤为:
(1)初始化i=0,j=0,k=0,k记录孩子节点序号;
(2)输入敏感词ai,获取其中文长度为m,并提取首字母s;
(3)进入s子树查询,将ai,j与s的第k个孩子节点childk比较;
(4)若ai,j=childk节点的值,若j<m,s=childk,k=0,返回步骤(3);若j≥m,i<n,则返回步骤(2);若j≥m,i≥n,执行步骤(5);
(5)否则,若ai,j≠childk节点值,查询childk的兄弟节点是否为空,若childk兄弟节点为空,则执行步骤(6),若childk兄弟节点为空,则执行步骤(8);
(6)创建新节点childk+1,值为ai,j,记录ai,j的拼音;
(7)若j<m,创建子节点,并赋值ai,j,记录ai,j拼音;若j≥m,最后一个节点记录敏感词级别,并初始化频率为0,区域信息为默认值1,
(8)判断i的取值,若i<n,返回步骤(2);若i≥n,所述敏感文本匹配模块将敏感度解析识别结果传输给所述解析结果显示模块进行显示。
优选地,还提供权限控制模块及人工审核模块,所述权限控制模块与所述人工审核模块及文本识别解析模块连接,所述人工审核模块在文本识别解析模块及敏感文本匹配模块审核之后再做抽查审核,判断信息是否误判漏判,对于误判的信息添加规则到所述元数据管理模块。
采用了上述方法之后,所述元数据加载模块把元数据加载到系统内存中并形成数据结构,所述元数据加载模块将待过滤的文本传输给所述文本接收模块,所述元数据管理模块配置有敏感的关键词、关联规则及待识别的表达式,所述文本接收模块接收待过滤的文本并传输给所述文本识别解析模块,所述文本识别解析模块采用AC自动机算法构建trie树对文本进行解析;所述敏感文本匹配模块将文本进行去停用词预处理,将敏感词通过敏感词决策树构建算法建立成一棵分流树,将预处理过的文本,以文本数据流方式检索敏感词决策树,记录文本中对应敏感词的频率和区域信息,通过敏感度计算公式,得出文本整体敏感度,对应网页划分为敏感、非敏感网页;该基于规则的敏感文本过滤方法添加规则简单并且可快速识别敏感文本,一般管理人员就能提炼并添加规则,添加的规则马上生效,可以智能识别缩小规则库,匹配字符时,只需要完善词库即可,不需要添加大量的规则,匹配速度快,不依赖词典与分词进行敏感度匹配计算,通过构建敏感词决策树,将网页文本内容以数据流形式检索决策树,记录敏感词词频、区域信息以及敏感词级别,计算文本整体敏感度,过滤敏感文本,查准率和查全率高。
附图说明
图1是本发明的一种基于规则的敏感文本过滤方法的步骤流程图;
图2是与图1的步骤流程图对应的整体模型示意图;
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明。
实施例1
请参阅图1至图2,图1是本发明的一种基于规则的敏感文本过滤方法的步骤流程图,图2是与图1的步骤流程图对应的整体模型示意图。
本发明公开了一种基于规则的敏感文本过滤方法,提供文本接收模块、文本识别解析模块、元数据加载模块、基础数据存储模块、元数据管理模块、权限控制模块、解析结果显示模块及人工审核模块,所述文本识别解析模块包括关键词识别单元、关联规则识别单元、表达式识别单元;所述元数据加载模块与所述文本接收模块连接,所述文本识别解析模块与所述文本接收模块连接,所述文本识别解析模块与所述解析结果显示模块、所述权限控制模块与所述文本识别解析模块及人工审核模块连接,所述人工审核模块与所述解析结果显示模块连接;
所述基于规则的敏感文本过滤方法包括以下步骤:所述元数据加载模块把元数据加载到系统内存中并形成数据结构,所述元数据加载模块将待过滤的文本传输给所述文本接收模块,所述元数据管理模块配置有敏感的关键词、关联规则及待识别的表达式,所述文本接收模块接收待过滤的文本并传输给所述文本识别解析模块,所述文本识别解析模块采用AC自动机算法构建trie树对文本进行解析;
所述关键词识别单元将所述文本识别解析模块中的待过滤的文本与元数据管理模块中的关键词进行解析识别;
所述关联规则识别单元将所述文本识别解析模块中的待过滤的文本根据元数据管理模块中的关联规则进行解析识别,所述关联规则为若干词组成违反设置的规则;
所述表达式识别单元将所述文本识别解析模块中的待过滤的文本根据元数据管理模块中的表达式进行解析识别;
所述关键词识别单元将所述文本识别解析模块中的待过滤的文本根据元数据管理模块中的关键词进行解析识别;
当字符匹配,从当前节点沿着树边有一条路径到达目标字符,沿该路径走向下一个节点继续匹配,目标字符串指针移向下个字符继续匹配;当字符不匹配,则去掉当前节点失败指针所指向的字符继续匹配,匹配过程随着指针指向root结束;重复“字符匹配”或“字符不匹配”中的任意一个过程,直到模式串走到结尾为止。
所述元数据管理模块对所述基础数据管理模块的基本数据做管理,根据板块设置添加词库和规则,如果没有设置则为默认板块。
实施例2
在本实施例中,还提供敏感文本匹配模块,所述敏感文本匹配模块与文本识别解析模块及解析结果显示模块连接,所述敏感文本匹配模块采用SWDT-IFA算法设计定位敏感词,定位到敏感词出现的位置后,判断敏感词是否直接是禁止词,根据距离和敏感词关联的规则或者正则表达式来判断是否满足了敏感规则。
所述步骤“所述敏感文本匹配模块采用SWDT-IFA算法设计定位敏感词”的实现步骤包括:所述敏感文本匹配模块将文本进行去停用词预处理,将敏感词通过敏感词决策树构建算法建立成一棵分流树,将预处理过的文本,以文本数据流方式检索敏感词决策树,记录文本中对应敏感词的频率和区域信息,通过敏感度计算公式,得出文本整体敏感度,对应网页划分为敏感、非敏感网页。
所述敏感度计算公式为:Aford={a0,a1,…,ai,…,an-1},(0≤i<n),n为敏感词个数,ai表示敏感词;
ai={ai,0,…,ai,j,…,ai,m-1},(0≤j<m),
其中,ai,j表示第i个敏感词的第j个敏感字,m表示敏感词长度。
所述敏感文本匹配模块采用所述敏感度计算公式的执行步骤为:
(1)初始化i=0,j=0,k=0,k记录孩子节点序号;
(2)输入敏感词ai,获取其中文长度为m,并提取首字母s;
(3)进入s子树查询,将ai,j与s的第k个孩子节点childk比较;
(4)若ai,j=childk节点的值,若j<m,s=childk,k=0,返回步骤(3);若j≥m,i<n,则返回步骤(2);若j≥m,i≥n,执行步骤(5);
(5)否则,若ai,j≠childk节点值,查询childk的兄弟节点是否为空,若childk兄弟节点为空,则执行步骤(6),若childk兄弟节点为空,则执行步骤(8);
(6)创建新节点childk+1,值为ai,j,记录ai,j的拼音;
(7)若j<m,创建子节点,并赋值ai,j,记录ai,j拼音;若j≥m,最后一个节点记录敏感词级别,并初始化频率为0,区域信息为默认值1,
(8)判断i的取值,若i<n,返回步骤(2);若i≥n,所述敏感文本匹配模块将敏感度解析识别结果传输给所述解析结果显示模块进行显示。
实施例3
在本实施例,还提供权限控制模块及人工审核模块,所述权限控制模块与所述人工审核模块及文本识别解析模块连接,所述人工审核模块在文本识别解析模块及敏感文本匹配模块审核之后再做抽查审核,判断信息是否误判漏判,对于误判的信息添加规则到所述元数据管理模块。
采用了上述方法之后,所述元数据加载模块把元数据加载到系统内存中并形成数据结构,所述元数据加载模块将待过滤的文本传输给所述文本接收模块,所述元数据管理模块配置有敏感的关键词、关联规则及待识别的表达式,所述文本接收模块接收待过滤的文本并传输给所述文本识别解析模块,所述文本识别解析模块采用AC自动机算法构建trie树对文本进行解析;所述敏感文本匹配模块将文本进行去停用词预处理,将敏感词通过敏感词决策树构建算法建立成一棵分流树,将预处理过的文本,以文本数据流方式检索敏感词决策树,记录文本中对应敏感词的频率和区域信息,通过敏感度计算公式,得出文本整体敏感度,对应网页划分为敏感、非敏感网页;该基于规则的敏感文本过滤方法添加规则简单并且可快速识别敏感文本,一般管理人员就能提炼并添加规则,添加的规则马上生效,可以智能识别缩小规则库,匹配字符时,只需要完善词库即可,不需要添加大量的规则,匹配速度快,不依赖词典与分词进行敏感度匹配计算,通过构建敏感词决策树,将网页文本内容以数据流形式检索决策树,记录敏感词词频、区域信息以及敏感词级别,计算文本整体敏感度,过滤敏感文本,查准率和查全率高。
同时,应当理解的是,以上仅为本发明的优选实施例,不能因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效实现方法,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!