一种WEB页面数据的采集分析方法及装置与流程
本发明涉及数据挖掘领域,尤其涉及WEB数据的分析领域,具体的讲是一种WEB页面数据的采集分析方法及装置。
背景技术:
本部分旨在为权利要求书中陈述的本发明的实施方式提供背景或上下文。此处的描述不因为包括在本部分中就承认是现有技术。
WEB的迅速发展使其成为世界上规模最大的公共数据源,同时各行业也在大力发展本领域的WEB端渠道业务,方便客户进行线上业务的自助办理,比如银行业推出的网上银行和手机银行等业务,零售业推出的各类电子商务网站以及广告营销业推出的广告投标平台等。
为了满足不同客户群体业务办理环境的复杂性、交易平台多样性等现实需求,这些领域的线上业务系统大多数采用B/S(即浏览器-服务端模式)模式进行开发和维护。但是这些业务系统页面上的功能设置、显示布局等一般是固定的,会导致客户使用不便,体验较差。然而,因为缺乏用户的使用反馈,对页面的优化只能依靠开发人员的经验或针对固定人群的访问结果,并没有可靠的依据。
后台系统通过对WEB日志的结构化、非结构化数据进行采集、归纳、分析和建模等操作,最终提炼出客户的交易行为分析模型、对客户层级的划分以及完善渠道业务指标等操作,具有十分重要的意义。
技术实现要素:
本发明的目的是提出一种WEB页面数据的采集分析方法及装置,对WEB日志的结构化、非结构化数据进行采集、归纳、分析和建模等操作,最终提炼出客户的交易行为分析模型。
为了达到上述目的,本发明实施例提供一种WEB页面数据的采集分析方法,包括:接收用户的访问请求,并对访问的WEB文件进行记录标记,生成WEB访问日志;对所述WEB访问日志进行去噪处理,生成结构化之后的日志数据;对所述结构化之后的日志数据按照不同的维度信息进行存储,生成数据库日志数据;对所述数据库日志数据进行建模分析,生成WEB页面数据的分析结果。
进一步地,在一实施例中,所述对所述WEB访问日志进行去噪处理,生成结构化之后的日志数据,包括:对所述WEB访问日志进行数据融合、无效信息的删除以及具体业务功能记录的归类和提取。
进一步地,在一实施例中,所述对所述结构化之后的日志数据按照不同的维度信息进行存储,生成数据库日志数据,包括:对所述结构化之后的日志数据进行用户访问识别存储,存储的信息至少包括用户的ID,IP地址,访问时间戳,访问页面路径,session访问信息。
进一步地,在一实施例中,所述存储的信息以键-值方式存储在数据库中。
进一步地,在一实施例中,对所述数据库日志数据进行建模分析,生成WEB页面数据的分析结果,包括:
利用协同过滤kNN算法、k-均值算法或者朴素贝叶斯算法进行建模分析。
为了达到上述目的,本发明实施例还提供一种WEB页面数据的采集分析装置,包括:访问记录单元,用于接收用户的访问请求,并对访问的WEB文件进行记录标记,生成WEB访问日志;数据处理单元,用于对所述WEB访问日志进行去噪处理,生成结构化之后的日志数据;日志存储单元,用于对所述结构化之后的日志数据按照不同的维度信息进行存储,生成数据库日志数据;日志分析单元,用于对所述数据库日志数据进行建模分析,生成WEB页面数据的分析结果。
进一步地,在一实施例中,所述数据处理单元用于对所述WEB访问日志进行去噪处理,生成结构化之后的日志数据,具体包括:对所述WEB访问日志进行数据融合、无效信息的删除以及具体业务功能记录的归类和提取。
进一步地,在一实施例中,所述日志存储单元用于对所述结构化之后的日志数据按照不同的维度信息进行存储,生成数据库日志数据,具体包括:对所述结构化之后的日志数据进行用户访问识别存储,存储的信息至少包括用户的ID,IP地址,访问时间戳,访问页面路径,session访问信息。
进一步地,在一实施例中,所述日志存储单元中存储的信息以键-值方式存储在数据库中。
进一步地,在一实施例中,所述日志分析单元对所述数据库日志数据进行建模分析,生成WEB页面数据的分析结果,包括:利用协同过滤kNN算法、k-均值算法或者朴素贝叶斯算法进行建模分析。
本发明提出的WEB页面数据的采集分析方法及装置,通过对客户从访问网站进行业务办理,直到交易完成这个时间段内的一系列操作行为,将分散在页面超链接、网页内容及WEB访问记录中数据加以记录、分析和提取建模等,从而得到客户的访问行为记录、网页端的点击量等记录。通过对一些关键指标进行建模及分析,为优化界面布局结构、设计线上业务办理流程、按需营销和开发渠道产品等提供决策依据,增强了线上用户的使用体验和用户黏度、提升了网站功能的可用性以及提高了系统的开发效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例的WEB页面数据的采集分析方法的处理流程图;
图2为本发明实施例的WEB页面数据的采集分析装置的结构示意图;
图3为本发明另一实施例的WEB页面数据的采集分析装置的结构示意图;
图4为本发明的具体实施例一的处理流程图;
图5为本发明的具体实施例二的处理流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本领域技术技术人员知道,本发明的实施方式可以实现为一种系统、装置、设备、方法或计算机程序产品。因此,本公开可以具体实现为以下形式,即:完全的硬件、完全的软件(包括固件、驻留软件、微代码等),或者硬件和软件结合的形式。
下面参考本发明的若干代表性实施方式,详细阐释本发明的原理和精神。
本发明通过对客户从访问网站进行业务办理,直到交易完成这个时间段内的一系列操作行为,将分散在页面超链接、网页内容及WEB访问记录中数据加以记录、分析和提取建模等,从而得到客户的访问行为记录、网页端的点击量等记录。
图1为本发明实施例的WEB页面数据的采集分析方法的处理流程图。
如图1所示,本实施例的WEB页面数据的采集分析方法包括:
步骤S101,接收用户的访问请求,并对访问的WEB文件进行记录标记,生成WEB访问日志;
步骤S102,对所述WEB访问日志进行去噪处理,生成结构化之后的日志数据;
步骤S103,对所述结构化之后的日志数据按照不同的维度信息进行存储,生成数据库日志数据;
步骤S104,对所述数据库日志数据进行建模分析,生成WEB页面数据的分析结果。
具体实施时,在步骤S101中,访问请求可以由用户通过点击页面的链接、按钮等操作通过JS代码提交。访问请求同时发送给应用服务器,应用服务器接收到访问请求后返回访问的WEB文件。同时,根据访问请求访问的特殊文件进行记录标记,一般记录形式为WEB访问日志。
具体实施时,在步骤S102中,对所述WEB访问日志进行去噪处理,生成结构化之后的日志数据,包括:对所述WEB访问日志进行数据融合、无效信息的删除以及具体业务功能记录的归类和提取。一般情况下,大规模网站中提供给客户的内容来自多个WEB服务器或者应用服务器,所以需要将这些服务器中存储的信息进行合并和归类。将来自多个服务器的日志文件进行合并处理,即为数据融合过程。整个过程需要对整体架构的服务器集群进行全局同步。垃圾数据的清理过程主要针对页面的声音、图片、客户端文件等嵌入式文件的引用记录进行删除,同时视具体需要也可能对HTTP版本信息、传输字节数、CSS格式文件、公共的脚本文件的引用记录进行删除和整理。也就是说,本步骤中,根据给定的筛选逻辑、业务场景等需求进行WEB访问日志的关键字提取、格式整理等,形成可挖掘的结构化文件。
具体实施时,在步骤S103中,所述对所述结构化之后的日志数据按照不同的维度信息进行存储,生成数据库日志数据,包括:对所述结构化之后的日志数据进行用户访问识别存储,存储的信息至少包括用户的ID(或其他用于标识客户身份的参数,如cookie等),IP地址,访问时间戳,访问页面路径(或者其他用于唯一标识页面的属性参数),session访问信息等。这些信息以“键-值”的方式存储在数据库中。
并且,将整理后的记录文件按照多个维度在数据库中保存,具体形式可以是某关系型数据库,例如ORACLE等。
具体实施时,在步骤S104中,所述日志分析单元对所述数据库日志数据进行建模分析,生成WEB页面数据的分析结果,包括:提取服务器存储的结构化之后的数据库日志文件,并将文件原始数据进行翻译、转义和可视化处理;然后对提取出的文件进行建模分析和评估,最终形成WEB页面数据的分析结果。
其中,翻译和转义是将数据从原始数据转换为后续处理所需的基础数据。可视化处理是利用计算机图形学和图像处理技术,将数据转换成图形或者在屏幕上显示出来,并进行交互处理。实现数据可视化的技术手段,可根据数据信息的图形、一般信息可视化的技术以及科学可视化或是统计图形设计技术等进行柔和使用。
在步骤S104中,对数据库数据进行建模分析前需用到以上步骤对文件原始数据进行处理,用于建模前的数据准备。
具体的,在本实施例中,可以利用协同过滤kNN算法、k-均值算法或者朴素贝叶斯算法进行建模分析。kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该杨贝也属于这个类别,并具有这个类别上样本的特性。k-均值算法是基于距离的聚类算法,采用距离作为相似性的评价指标。朴素贝叶斯算法是最广泛的两种分类模型之一,基于一个简单的假定:给定目标值数据行之间相互条件独立。
以上算法的使用都是在步骤S104中,对数据进行建模分析,具体作用是对数据进行分类,分析数据属性,不同算法具有不同的优缺点,具体分场景使用或者同时使用。
应当注意,尽管在附图中以特定顺序描述了本发明方法的操作,但是,这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
在介绍了本发明示例性实施方式的方法之后,接下来,参考图2对本发明示例性实施方式的WEB页面数据的采集分析装置进行介绍。该装置的实施可以参见上述方法的实施,重复之处不再赘述。以下所使用的术语“模块”和“单元”,可以是实现预定功能的软件和/或硬件。尽管以下实施例所描述的模块较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。
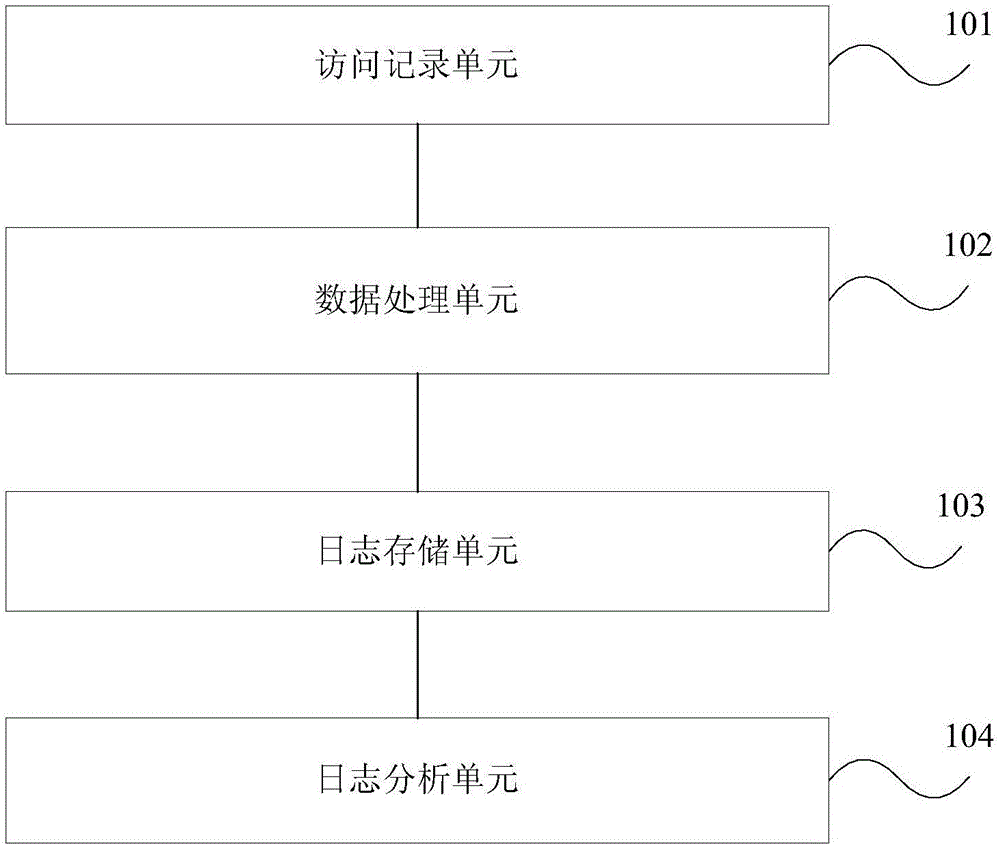
图2为本发明实施例的WEB页面数据的采集分析装置的结构示意图。如图2所示,包括:访问记录单元101,用于接收用户的访问请求,并对访问的WEB文件进行记录标记,生成WEB访问日志;数据处理单元102,用于对所述WEB访问日志进行去噪处理,生成结构化之后的日志数据;日志存储单元103,用于对所述结构化之后的日志数据按照不同的维度信息进行存储,生成数据库日志数据;日志分析单元104,用于对所述数据库日志数据进行建模分析,生成WEB页面数据的分析结果。
具体实施时,所述数据处理单元102用于对所述WEB访问日志进行去噪处理,生成结构化之后的日志数据,具体包括:对所述WEB访问日志进行数据融合、无效信息的删除以及具体业务功能记录的归类和提取。
具体实施时,所述日志存储单元103用于对所述结构化之后的日志数据按照不同的维度信息进行存储,生成数据库日志数据,具体包括:对所述结构化之后的日志数据进行用户访问识别存储,存储的信息至少包括用户的ID,IP地址,访问时间戳,访问页面路径,session访问信息。
具体实施时,所述日志存储单元103中存储的信息以键-值方式存储在数据库中。
具体实施时,所述日志分析单元104对所述数据库日志数据进行建模分析,生成WEB页面数据的分析结果,包括:利用协同过滤kNN算法、k-均值算法或者朴素贝叶斯算法进行建模分析。
在本实施例中,访问记录单元101、数据处理单元102以及日志存储单元103可以视情况单独部署或者与应用服务器共用,而日志分析单元104可以部署在系统分析人员的客户端上。
此外,尽管在上文详细描述中提及了WEB页面数据的采集分析装置的若干单元,但是这种划分仅仅并非强制性的。实际上,根据本发明的实施方式,上文描述的两个或更多单元的特征和功能可以在一个单元中具体化。同样,上文描述的一个单元的特征和功能也可以进一步划分为由多个单元来具体化。
图3为本发明另一实施例的WEB页面数据的采集分析装置的结构示意图。如图所示,本实施例中,访问发起终端1可以部署在用户使用的PC机上,用以发送访问请求;同时,日志服务器2包括图2所示的访问记录单元101、数据处理单元102以及日志存储单元103,其可以单独部署或者与应用服务器共用,日志分析终端3即为图2所示实施例中的日志分析单元104,其可以部署在系统分析人员的客户端上。
在本实施例中,访问发起终端1包括请求发起单元105,用于向日志服务器2发送访问请求,同时对当前访问页面位置进行打点标记以便在日志服务器2中进行记录。
在本实施例中,日志分析终端3包括数据接收单元301和模型分析单元302。其中,数据接收单元301用于提取日志服务器存储的结构化文件,并将文件原始数据在终端进行翻译、转义和可视化处理;模型分析单元302用于对导出的文件数据进行建模分析和评估,最终形成数据分析结论。
结合图2和图3,该WEB页面数据的采集分析装置的整体运作流程及各单元彼此协作关系描述如下:客户在页面进行业务办理,访问发起终端1同时向应用服务器和日志服务器2提交访问请求。日志服务器2将访问请求记录进行原始存储,同时对日志进行去噪处理等二次加工后在数据库中按照不同的维度信息进行存储。日志分析终端3提取数据库记录数据后进行翻译及可视化处理,同时对日志数据进行建模分析,建模分析可以利用协同过滤kNN算法、k-均值算法、朴素贝叶斯算法等业界通用的算法,并形成最终的,WEB数据分析结果,数据分析师或产品经理根据相关分析结论对该产品进行有针对性的持续改进和优化。
根据图3所示实施例的WEB页面数据的采集分析装置,以下通过两个典型的实施例来具体阐述本发明的WEB页面数据的采集分析方法的处理过程。
实施例一:
利用本发明的WEB页面数据的采集分析装置,来帮助网站分析客户的交易行为,例如页面访问顺序、页面停留时间、业务转化率等,最终通过模型分析结果来定位相关产品在交易流程方面的优化方向。处理过程如图4所示:
步骤S401,客户通过访问发起终端1使用网银的理财交易功能,通过请求发起单元105(通常是点击页面的链接、按钮等操作通过JS代码提交)将WEB页面的访问请求提交至日志服务器2。页面端的程序利用JS代码配置日志服务器2的访问路径,通过引用日志服务器2下空白图片的方式在服务器端进行访问记录。
步骤S402,日志服务器2接收到访问请求后,通过记录访问单元101以原始的WEB服务器日志或应用服务器日志格式记录下来,并对日志记录内容进行必要的配置操作。此过程的一般方法如下:
a.定位WEB服务器安装路径下的conf/server.xml文件,首先检查该文件的如下配置信息是否已被注释:
<!--
<Valve className="org.apache.catalina.valves.AccessLogValve"
directory="logs"prefix="localhost_access_log."suffix=".txt"
pattern="common"resolveHosts="false"/>
-->
若已被注释,则去除注释标记(<!---->)。其中,className属性为apache开发的自带生成日志的java类文件;directory属性为WEB日志默认存放的文件夹目录;prefix属性为默认的日志文件名称;suffix属性为文件扩展名;pattern属性代表日志记录的具体格式。
b.调整pattern属性的参数,以便使WEB日志记录的内容更加贴合业务的需要。该属性的默认值为common,其蕴含的表达式为:%h%l%u%t"%r"%s%b。全量的日志产生格式表达式及说明如下:
%a-远端IP地址
%A-本地IP地址
%b-发送的字节数,不包括HTTP头,如果为0,使用"-"
%B-发送的字节数,不包括HTTP头
%h-远端主机名(如果resolveHost=false,远端的IP地址)
%H-传输协议
%l-从identd返回的远端逻辑用户名(总是返回'-')
%m-请求的方法(GET,POST,等)
%p-收到请求的本地端口号
%q-查询字符串(如果存在,以'?'开始)
%r-请求的第一行,包含了请求的方法和URI
%s-响应的状态码
%S-用户的session ID
%t-日志和时间,使用通常的Log格式
%u-认证以后的远端用户(如果存在的话,否则为'-')
%U-请求的URI路径
%v-本地服务器的名称
%D-处理请求的时间,以毫秒为单位
%T-处理请求的时间,以秒为单位
选取其中符合需要的表达式进行设置后的配置信息举例如下:
<Valve className="org.apache.catalina.valves.AccessLogValve"
directory="logs"prefix="localhost_access_log."suffix=".txt"
pattern="%h%l%u%t";%r";%s%b%T%S"resolveHosts="true"/>
步骤S403,数据处理单元102对原始服务器日志进行去噪处理,例如数据融合、无效信息的删除(比如等)、具体业务功能记录的归类和提取等。一般情况下,大规模网站中提供给客户的内容来自多个WEB服务器或者应用服务器,所以需要将这些服务器中存储的信息进行合并和归类。将来自多个服务器的日志文件进行合并处理,即为数据融合过程。整个过程需要对整体架构的服务器集群进行全局同步。垃圾数据的清理过程主要针对页面的声音、图片、客户端文件等嵌入式文件的引用记录进行删除,同时视具体需要也可能对HTTP版本信息、传输字节数、CSS格式文件、公共的脚本文件的引用记录进行删除和整理。
步骤S404,日志存储单元103对格式化之后的日志数据进行用户访问识别存储,存储内容为客户的ID(或其他用于标识客户身份的参数,如cookie等),IP地址,访问时间戳,访问页面路径(或者其他用于唯一标识页面的属性参数),session访问信息。这些信息以“键-值”的方式存储在数据库中。
步骤S405,日志分析终端3通过数据接收单元301对格式化之后的日志数据进行提取后形成可视化结果。具体包括:
a.以“功能-页面”和“客户-页面”两个维度建立两张关系表,表中字段包括页面点击次数、时间、不同session对应的页面访问次数等信息。
b.根据步骤a中记录的信息绘制漏斗模型。例如调用EXCEL表格作为绘图工具进行处理:将客户访问的每个步骤对应页面记录的访问次数统计出来后设置占位数据,利用条形堆栈图展示数据,并将占位数据的数据条颜色去除,以得到每个数据条都居中的显示效果,占位数据=(进入人数-当前人数)/2。这样就可以按照访问步骤得到一个漏斗型的图形模型。
步骤S406,模型分析单元302对统计结果进行建模分析。可通过页面访问识别、用户识别以及会话识别等过程。
页面访问识别,即将每个页面访问视为特定的用户事件WEB对象或资源的集合(比如浏览某一个HTML页面、将货品加入购物车等),并在更细的粒度上对页面访问进行聚合分析,比如一个电子商务网站的页面可能包含多个用户操作事件,如货品信息介绍、付款、加入购物车、登录/注册等。将每一类事件单独作为页面访问识别的独立要素。
用户识别,即网站用户的身份划分。根据不同网站的自身机制可以按照cookie或者登录用户名来进行识别。
会话识别是通过将客户的操作记录分割成若干会话过程,每个会话代表了一次访问行为。对于采取登录认证机制(包括内嵌会话)的网站,可以通过记录当前客户的sessionID来唯一区分每次会话;而对于其他类型的网站,可以通过求解最佳“探索访问序列”来进行会话识别。所谓探索访问序列,就是将客户实际的操作访问记录归类为一个集合A,一个探索f将A映射到一个建立好的目标会话集合中,记为f(A)。如果一个探索f可以使得A=f(A),即实际访问记录与目标会话集合吻合,那么此f即为最佳探索方式。一般来讲,可以通过时间和页面结构两个维度进行探索,前者是根据服务器通讯时间超时来区分连续的会话,而后者则使用静态站点结构或在服务器日志中被调用域中包含的隐式链接。
通过以上这些方法对关键技术指标(如功能页面的跳出率、退出率、功能转化效率、页面停留时间、功能点击量等)得出该功能的流程合理性、入口位置合理性及页面布局合理性等结论,数据分析师或产品经理根据相关分析结论对该产品进行有针对性的持续改进和优化。
实施例二:
利用本发明的WEB页面数据的采集分析装置,帮助网站细分客户群,以便进行商品推销。
处理过程如图5所示,其中步骤S501-步骤S504与实施例一中的步骤S401-步骤S404类似,此处不再赘述,其后续步骤如下:
步骤S405,日志分析终端3通过数据接收单元301对格式化之后的日志数据进行提取后进行数据建模。采用如下方法:
a.根据提取的数据记录建立两个集合:包含n个访问页面集合P={p1,p2,p3,...,pn},包含m个用户事务特征的集合T={t1,t2,t3,...,tm}。同时定义n维事务向量其中t属于事务集合T中的某个元素,表示页面集合P中的某个页面pi与事务功能t的关系权重值,代表二者的相关度。根据实际需要,拟定一个规则来定义的权重值。一般的,可以将定义为一个二元数,若页面pi与t按照拟定的规则有关联,则值大于0,否则的值等于0。
b.统计所有m个用户的事务向量集合,形成一个m×n的“客户事务-页面”事务矩阵(UPM)。UPM的行代表不同客户身份,列代表不同的访问页面,而每个元素的值则代表每个客户对特定页面的访问权重,即:
其中每个矩阵元素即为权重值。
c.对于n个访问页面集合P,对齐抽取页面语义信息,根据不同信息集U={u1,u2,u3,...,ul}对这n个页面进行属性划分形成l个结果,形成页面特征集合。由此定义n维特征向量其中u属于页面特征集合U中的某个元素,表示页面集合P中的某个页面pi与事务功能u的关系权重值,代表二者的相关度。类似于事务矩阵UPM的建立方法,得到l×n的“功能特征-页面”页面特征矩阵(PMF)。PMF的行代表不同的页面特点划分,比如转账汇款类业务、投资理财类业务、账户管理类业务、安全认证类业务等,可以根据实际需要进行粒度细分;PMF的列代表不同的功能页面。即:
其中每个矩阵元素即为权重值。这里可以按照实际需要改变“0-1”二元赋值的布尔矩阵,可以通过设置0.3、0.5、0.8等小数来表示不同页面与功能间的相关程度大小。比如,对于“实物黄金交易”功能,“查询实物黄金持仓页面”的值设置为1,则“投资账户列表页面”的值可以设置为0.5,因为后者与实物黄金交易的相关度相对于前者要小一些。
d.通过UPM与PMF的转置矩阵相乘得到新的矩阵:内容事务矩阵TFM(=UPM×PMFT),该矩阵的行向量表示不同的客户身份,列向量表示不同的页面特点划分。即:
其中每个矩阵元素vij为UPM与PMF转置的实际乘积。
通过上述各步骤得到TMF事务矩阵,该矩阵代表所有用户与各业务功能的使用关系分布情况。
步骤S406,模型分析单元302按照对统计结果进行建模分析,并根据不同客户的TFM矩阵分析每个客户的交易偏好,并结合不同的分类指标(比如客户年龄层、业务办理地点、办理时间段等)对存量客户进行归类处理,由此得到客户群细分结果。
本发明实施例提出的WEB页面数据的采集分析方法及装置,通过对客户从访问网站进行业务办理,直到交易完成这个时间段内的一系列操作行为,将分散在页面超链接、网页内容及WEB访问记录中数据加以记录、分析和提取建模等,从而得到客户的访问行为记录、网页端的点击量等记录。通过对一些关键指标进行建模及分析,可以提升基于B/S架构网站功能的功能可用性,同时对于系统后台客户资源的管理、业务未来的发展方向起到了关键的决策支持作用。通过对客户群的细分,可以找到不同业务价值的客户,并在后续的网站业务发展中有针对性的保持优质客户的资源,同时提高其他客户的黏性。对客户使用过程的分析结果可以有效地帮助业务流程改进、页面布局调整等网站优化工程;同时通过分析每个业务功能的转化率,来对现有功能进行细分,有选择性的发展重点业务。通过分析网站流量及功能使用频率的分布情况,可以有针对性的进行系统性能优化,提高系统服务可用性和持续性,降低运营成本。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
本发明中应用了具体实施例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!