可同时挖掘视觉和语义相似性的图像标注方法与流程
本发明涉及一种图像标注技术,特别是一种可同时挖掘视觉和语义相似性的基于KNN的图像标注方法。
背景技术:
随着网络图片呈现出爆炸式的增长,媒体数据库的规模也不断扩大。现如今,许多搜索引擎利用关键词检索图像,因此,如何为图像分配相关关键词成为了一个重要研究课题。然而,图像标注是一项具有挑战的任务。首先,在底层视觉特征和高层语义之间存在的语义鸿沟问题使得该任务变得十分困难。其次,早先所使用的人工标注是费时费力的,在大数据时代,利用人工标注显然是不现实的。
近年来,为解决上述问题,研究者提出了各种各样的方法,如稀疏编码法、图学习法、决策树法等。然而,这些方法都不能解决由于人工标注的训练数据不足,导致不能完全利用图像的视觉和语义相似性的问题。而本发明所提出的方法可以很好地解决上述问题。
技术实现要素:
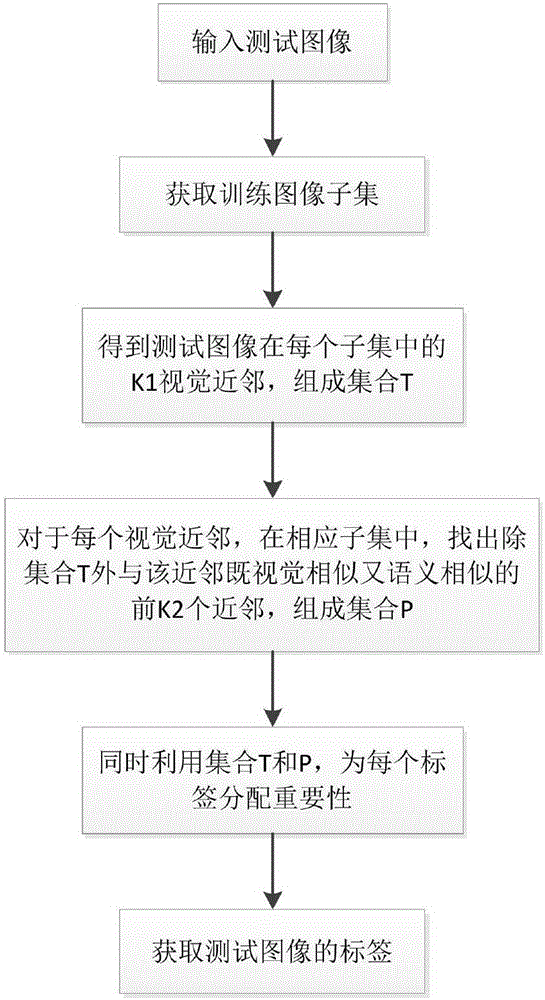
本发明的目的在于提供一种可同时挖掘视觉和语义相似性的基于KNN的图像标注方法,该方法包括以下步骤:
从图像集中获取训练图像子集;
对测试图像在每个训练图像子集中获取K1各视觉近邻的图像并组成集合T;
对测试图像的每个视觉近邻图像在其相应的训练图像子集中,获取除集合T外与其既视觉相似又语义相似的K2个近邻图像并组合成集合P;
利用集合T和P,为每个标签在标注测试图像过程中分配其重要性。
本发明与现有技术相比,具有以下优点:(1)本发明可以同时挖掘出图像的视觉和语义相似性,从而可以获取图像更全面的信息;(2)本发明可以使得网上下载的图像标签具有完整性且噪声小。
下面结合说明书附图对本发明做进一步描述。
附图说明
图1是本发明方法流程图。
图2是本发明一种典型的图像集合的示意图。
具体实施方式
一种可同时挖掘视觉和语义相似性的基于KNN的图像标注方法,包括以下步骤:
步骤1,输入测试图像(如图2所示);
步骤2,从测试图像的图像集中获取训练图像子集;
步骤3,对测试图像在每个训练图像子集中获取K1各视觉近邻的图像并组成集合T;
步骤4,对测试图像的每个视觉近邻图像在其相应的训练图像子集中,获取除集合T外与其既视觉相似又语义相似的K2个近邻图像并组合成集合P;
步骤5,利用集合T和P,为每个标签在标注测试图像过程中分配其重要性。
步骤2的具体过程为:
步骤S101,建立图像集X={x1,x2,...,xn}∈Rn×d,其中xi∈Rd(1≤i≤n)为第i张图像,d为图像维数;
步骤S102,建立一个包括c个标签的词典L={l1,l2,...,lc}∈{0,1}n×c;
步骤S103,建立训练集T={(x1,y1),(x2,y2),...,(xn,yn)}用于表示成对的图像xi和该图像相应标签集yi,其中yi∈{0,1}c;
步骤S104,若图像xi被第k个标签标记,则yi(k)=1,否则yi(k)=0;
步骤S105,建立包含所有被同一标签li'标记的图像集合为训练图像子集。
步骤3的具体过程为:
步骤S201,对测试图像I,获取其与每个训练图像子集中的每一幅图像间的视觉距离;
步骤S202,选取每一训练子集中与测试图像I最近邻的K1个图像形成集合TI,i”,i”∈[1,...,c];
步骤S203,将测试图像I的所有最近邻图像合并为集合T,T={TI,1∪TI,2∪...∪TI,c}=∪i”∈[1,...,c]TI,i″。
步骤4的具体过程为:
获取集合P的具体过程为:
步骤S301,将训练图像的每个子集Ti'中除测试图像I的最近邻图像集合TI,i”外的其它图像表示为TotherI,i”',i”'∈[1,...,c];
步骤S302,获取集合TotherI,i”'中的每幅图像与集合TI,i”中的每幅图像间的视觉和语义的相似性
S(j,k)=αD(xj,xk)+(1-α)dis(tag)
s.t.j∈TI,i
k∈TotherI,i
其中,D(xj,xk)为TI,i”中图像xj与TotherI,i”'中图像xk之间的视觉距离;dis(tag)=D(yj,yk)为TI,i”中图像xj的标签集yj与TotherI,i”'中图像xk的标签集yk之间的距离,dis(tag)用于表示图像xj与图像xk之间的语义距离;
步骤S303,选取TotherI,i”'中与图像xj最相似的前K2个图像形成子集PI,i,j;
步骤S304,执行步骤S302和S303直至集合TotherI,i”'和集合TI,i”中的每幅图像之间均计算完相似性且形成子集,将所有子集合并获得集合P。
步骤5的具体过程为:
为每个标签在标注测试图像过程中分配其重要性的具体过程为:
步骤S401,对于每一标签lm,获取测试图像I在集合T、P中的后验概率
其中,Y是测试图像I相应标签的集合,表示对于图像xi当用来预测标签lm时它所做的贡献;δ(lm∈Y)表示标签lm在测试图像I是否出现,如果出现,则δ(lm∈Y)=1,否则δ(lm∈Y)=0;
步骤S402,对于每一标签,获取测试图像I的后验概率
P(I|lm)=θ·PT(I|lm)+(1-θ)·PP(I|lm)
其中,θ为集合T在决策中的权重,则(1-θ)为集合P在决策中的权重;
步骤S403,根据贝叶斯公式获得测试图像I的标签lm的后验概率为
步骤S404,获得检测图像I的标签
实施例
步骤1:假设现有包括20幅图像的图像集Image={image1,...,image20},该图像集有包括15个标签的词典Label={label1,...,label15},则所获得的第1个子集为所有被标签label1标注的图像形成的集合subset1,以此类推,可以获得15个子集{subset1,...,subset15}。
步骤2:已知一个测试图像Test,在第一个子集subset1中,计算Test与subset1中每个图像之间的视觉距离,找到Test的K1视觉近邻,形成集合subset1_neighbor,以此类推,得到15个集合,将所有集合合并即可得到Test在所有子集上的视觉近邻
subset_neighbor={subset1_neighbor∪...∪subset15_neighbor}。
步骤3:对于第一个子集subset1,将其中没有出现在subset_neighbor中的图像作为集合subset1_neighbor_other,根据上步骤3中相似性公式计算出subset_neighbor中每幅图像在subset1_neighbor_other中的前K2个最相似图像,形成一个集合。以此类推,将所有子集所形成的集合进行合并即可获得相似集合similarity_subset。
步骤4:根据上步骤4中的公式,即可获得测试图像Test的预测标签。
- 还没有人留言评论。精彩留言会获得点赞!