基于聚类分析和实时校正的洪水预报方法与流程
本发明属于水流预报技术领域,特别涉及一种基于聚类分析和实时校正的洪水预报方法。
背景技术:
山洪是山丘区中小河流由降雨引起的突发性、暴涨暴落的洪水,而我国中小河流众多,且大部分中小河流站网偏稀,缺少必要的应急监测手段,预报方案不健全。近年来,由于极端天气事件增多,局地强降雨、突发性暴雨时常发生,而山丘区山高坡陡、河流源短流急,在暴雨天气下极易发生山洪、泥石流、滑坡等山地灾害,造成人民生命财产的损失。因此基于中小河流的洪水预报得到国家的高度重视。
随着水文数据获取能力和计算机快速计算能力的发展,基于数据挖掘的洪水预报模型得到了快速发展。如何利用智能算法从历史水文数据中提取洪水特征,挖掘出水文数据中蕴含的有用信息,提高对未来洪水预报的准确率,是一个重要的研究方向。文献[王丽萍,张明新,李继伟,等.BP网络激活函数选择及在径流预报模型中的应用[J].水利发电学报,2014,33(1):29-36]对神经网络内部激活函数进行了研究,发现BP网络激活函数的选择对预报结果产生重要影响。然而神经网络模型有其固有的缺陷,就是网络结构复杂、收敛速度慢、易陷入局部极值等问题。文献[张楠,夏自强,江红.基于多因子量化指标的支持向量机径流预测[J].水利学报,2010,41(11):1318-1323]利用最小二乘支持向量方法,构建了基于多因子量化指标的径流预测模型。但是由于历史洪水数据蕴含多种不同数据分布特点的样本,单个模型不能同时很好的刻画各个模型的特点。文献[闫月新,包为民,等.组合预报方法在洪水预报模型中的应用[J].水电能源科学,2013,31(10)]采用简单平均、最优线性组合、最优非线性组合等三种组合方法,构建了新安江模型、垂向混合产流模型和Tank模型相结合的组合模型,选出最稳定的组合方法。组合模型虽然解决了历史洪水数据中蕴含的多模型问题,但是数据驱动模型对洪峰时刻预报结果普遍偏差的问题没有得到很好的解决。
技术实现要素:
发明目的:针对现有技术中存在的问题,本发明提供基于聚类分析和实时校正的洪水预报方法,通过聚类分析将原始水文数据分为几类,分别训练模型,实现多模型预报;然后通过BP神经网络实现实时校正提高了洪峰时刻预报准确率,很好的解决了上述缺陷,确保了准确性。
技术方案:为解决上述技术问题,本发明提供基于聚类分析和实时校正的洪水预报方法,步骤如下:
第一步:采集实际河流的历史降雨量数据、历史流量数据以及对应的时间数据,并建立数据模型;
第二步:对数据模型中的原始数据利用主成分分析进行降维处理,得到有效数据,将有效数据前2/3的数据作为训练样本,后1/3的数据作为测试样本;
第三步:利用K-means聚类方法对得到的训练样本进行聚类分析,将训练样本划分为k个不同类别等级;
第四步:利用聚类后得到的k个类别的训练样本训练不同的SVM模型,利用交叉验证方法搜寻这k个类别的训练样本所对应的支持向量机模型中的惩罚因子c和核函数参数g,使每个支持向量机模型都达到最优,然后输入测试样本并对该测试样本进行判断其所属的类别,并用对应的SVM模型对测试样本进行预测,得到模型预测值q;
第五步:计算测试样本中预测值与真实值的误差序列,利用该误差序列前2/3的数据训练BP神经网络误差校正模型,后1/3的数据测试误差矫正值,,得到误差校正值qe,最终预报结果为模型预测值q加上误差校正值qe。
第二步中主成分分析方法步骤如下:
步骤2.1:将数据模型中多场次洪水数据作为样本,选择p个变量作为特征值,构成n个样本矩阵,
其中xij为第i个样本的第j个特征值;
步骤2.2:将样本矩阵进行标准化处理,得到标准化矩阵Y=(yij)n×p;
步骤2.3:计算标准化矩阵Y的协方差矩阵R,
步骤2.4:求协方差矩阵R的p个非负的特征值,并从大到小进行排列λ1>λ2>…>λp,对应特征向量也进行排序,其中对应λi的特征向量为Ci=(c1i,c2i,…,cpi)T;
步骤2.5:确定主成分,并计算主成分下的样本矩阵Z,按特征值的累计贡献率大于95%为准则选取前m个主成分,得到样本矩阵为Z=(zij)n×m,其中
第三步中从有效数据提取N个水文时间序列样本为{(xi,yi),i=1,2,…,N},其中xi(xi∈Rp)是第i个样本的输入向量,p为特征值个数,yi∈R为对应输出值,第三步中给出的聚类分析步骤具体如下:
步骤3.1:从N个水文时间序列样本中随机地选择自然数k个样本,每个样本初始地代表了一个簇的平均值或中心;
步骤3.2:分别计算剩余的样本到k个簇中心的相异度,将这些样本分别划归到相异度最低的簇;其中样本之间的相异度通过欧氏距离计算,已知两个p维向量的样本a(x11,x12,…,x1p)与b(x21,x22,…,x2p)之间的欧氏距离公式为
步骤3.3:根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有样本各自维度的算术平均数;
步骤3.4:不断重复步3.2和步骤3.3,直到准则函数收敛,之后将样本聚为k类,得到k个聚类质心,其中准则函数采用平方误差,其定义如下:
其中P为所有样本,mi为第i个簇的平均值;
步骤3.5:根据k个聚类质心,得到水文时间序列样本聚类后形成的k个训练样本集。
第四步中训练模型并预测步骤如下:
步骤4.1:利用聚类后得到的k个类别等级的训练样本训练不同的SVM模型,利用交叉验证方法搜寻这k个类别等级的训练样本所对应的支持向量机模型中的惩罚因子c和核函数参数g,使每个支持向量机模型都达到最优;
步骤4.2:输入测试样本并对该测试样本进行判断其所属的类别,并用对应的SVM模型对测试样本进行预测,得到模型预测值q;
第五步中,假设当前时段为t,数据模型预见期为h,通过BP神经网络实现时段t+h处误差校正值的步骤为:
步骤5.1:将N个训练样本前2/3的样本训练SVM模型,并对剩余1/3的样本预测结果,得到预报值q;
步骤5.2:计算实际值与预报值之间的差值,得到预报误差时间序列用于样本整理的历史资料;
步骤5.3:对预报误差时间序列ei进行样本整理,选择当前时段t未来h小时误差值et+h作为输出值,当前时段前面k(2<k<10)个误差值(et,et-1,…et-k+1)作为输入值,建立当前时段h小时后误差值与历史误差值之间的对应关系(et,et-1,…et-k+1)∝et+h,并对历史资料库中所有样本进行依次整理。
步骤5.4:训练模型,利用步骤5.3历史资料库中整理的样本训练BP神经网络模型,通过调整参数使得模型尽可能与训练数据吻合;
步骤5.5:模型预测,将当前误差样本(et,et-1,…et-k)∝et+h作为模型输入得到预测结果;
步骤5.6:校正预报值,将模型预报值qt加上误差预报值et得到校正后预报值Qt;
步骤5.7:到时段t+1时,将时段i处未校正前预报误差加入历史资料库,实时更新资料库后,再返回步骤5.3,实现递归的实时校正。
与现有技术相比,本发明的优点在于:
本发明提出的基于聚类分析和实时校正的中小河流智能洪水预报方法,首先通过聚类分析将原始水文数据分为几类,分别训练模型,实现多模型预报;然后通过BP神经网络实现实时校正提高了洪峰时刻预报准确率。
附图说明
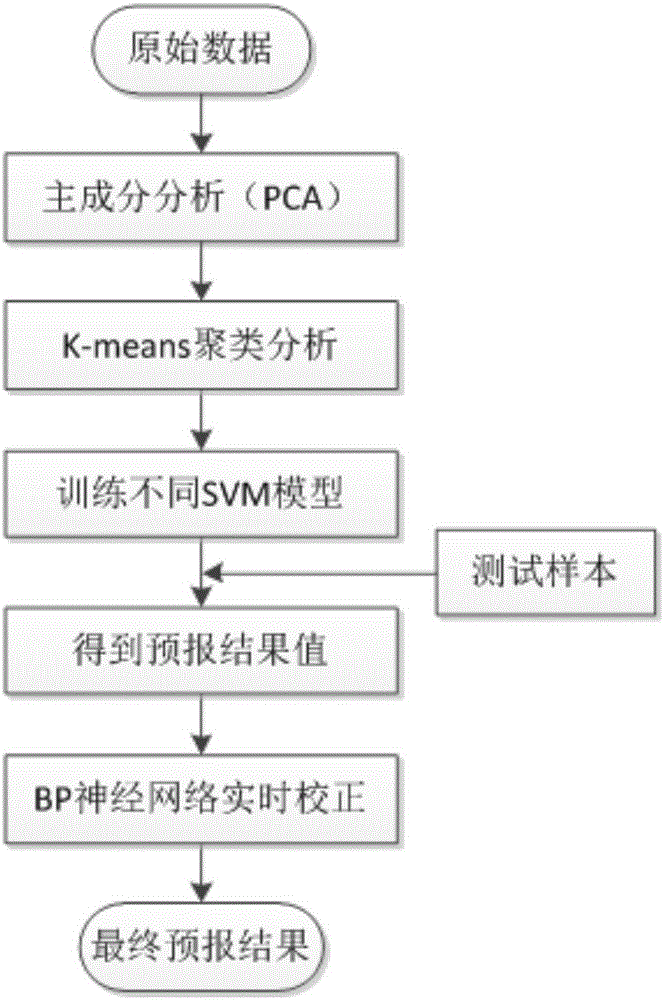
图1是本发明的流程图;
图2是实施例中洪水发生时不同方案预报结果的对比图。
具体实施方式
下面结合附图和具体实施方式,进一步阐明本发明。
如图1所示,主要包括以下几步:
一是利用主成分分析(PCA)对模型的输入做降维处理。目的是提高数据间的独立性,防止数据的冗余,减少运算量;二是利用K-means聚类方法对训练样本进行聚类分析。将洪水数据划分为k个不同的类别,然后训练不同的SVM模型,利用交叉验证方法搜寻这k个类别的训练样本所对应的支持向量机模型中的惩罚因子c和核函数参数g,使每个支持向量机模型都达到最优。当输入测试样本,利用聚类质心判断该测试样本所属的类别,并用对应的模型对其进行预测,得到预测值q;三是BP神经网络实时校正。计算测试样本中预测值与真实值的误差序列,利用该误差序列前2/3的数据训练BP神经网络误差校正模型,后1/3的数据测试误差矫正值,得到误差校正值qe,最终预报结果为模型预测值q加上误差校正值qe。qeqe。
由于历史洪水数据具有复杂性、非线性、不确定性等特点,如何从水文资料中提取更多的有效信息,去除有害信息,受到越来越多的重视。本发明首先利用主成分分析将多个相关的特征指标简化为少数几个彼此独立的主成分。以这些主成分为基础对洪水进行预报,主成分分析不仅可以尽可能多的保留原始信息,而且可以提高数据间的独立性,防止数据的冗余,减少运算量。以下为主成分分析算法步骤:
步骤1.1:将多场次洪水数据作为样本,选择p个变量作为特征值,构成n个样本矩阵。
其中xij为第i个样本的第j个特征值。
步骤1.2:将样本矩阵进行标准化处理,得到标准化矩阵Y=(yij)n×p。
步骤1.3:计算标准化矩阵Y的协方差矩阵R。
步骤1.4:求协方差矩阵R的p个非负的特征值,并从大到小进行排列λ1>λ2>…>λp,对应特征向量也进行排序,其中对应λi的特征向量为Ci=(c1i,c2i,…,cpi)T。
步骤1.5:确定主成分,并计算主成分下的样本矩阵Z。按特征值的累计贡献率大于某一特定值为准则选取前m个主成分,得到样本矩阵为Z=(zij)n×m。其中
由于历史水文数据中蕴含了多种不同数据分布特点的样本,其中高流量和低流量数据中输入输出之间的映射关系就不同。所以需要通过聚类分析将水文时间序列样本划分为多种类别,例如k取值为4,将训练样本划分为低流量、中流量、中高流量和高流量四个类别。
同时训练多个适应不同数据分布特点的模型。最后当输入一个测试样本,通过聚类质心计算测试样本属于哪一个类别,相应这个类别的模型对其进行预测。
已知N个水文时间序列样本为{(xi,yi),i=1,2,…,N},其中xi(xi∈Rp)是第i个样本的输入向量,p为特征值个数,yi∈R对应输出值。给出聚类分析步骤:
步骤2.1:从原始水文时间序列样本中随机地选择k(k为自然数)个样本,每个样本初始地代表了一个簇的平均值或中心。
步骤2.2:分别计算剩余的样本到k个簇中心的相异度,将这些样本分别划归到相异度最低的簇。其中样本之间的相异度通过欧氏距离计算,已知两个p维向量的样本a{x11,x12,…,x1p)与b(x21,x22,…,x2p)之间的欧氏距离公式为:
步骤2.3:根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有样本各自维度的算术平均数。
步骤2.4:不断重复步骤2和3,直到准则函数收敛,将样本聚为k类,得到k个聚类质心。其中准则函数采用平方误差,其定义如下:
其中P为所有样本,mi为第i个簇的平均值
步骤2.5:得到水文时间序列样本聚类后形成的k个训练样本集。
步骤2.6:利用聚类后得到的四个类别的训练样本训练不同的SVM模型,利用交叉验证方法搜寻这四个支持向量机模型中的惩罚因子c和核函数参数g,使每个支持向量机模型都达到最优。输入一个测试样本,通过计算该测试样本与k个聚类质心的相异度,将该样本划分为相异度较低的类别,并用这一类别的模型对其进行预测,得到预测结果值q。
数据驱动模型在水文预报中得到广泛应用,但是数据驱动模型完全依赖输入与输出之间的映射关系。由于历史水文资料大都通过水文观测站获得,难免会有检测误差。因此洪峰时刻流量和降雨量的检测偏差,对洪峰时刻预报误差影响较大。我们采用神经网络方法对预报误差进行再次预报,以期达到校正预报结果的目的。最终的预报结果为模型预报值加上误差预报值,通过实验验证该方法能显著提高洪峰时刻预报准确率。
假设当前时段为t,模型预见期为h,通过BP神经网络实现时段t+h处误差校正值的步骤为:
步骤3.1:将N个训练样本前2/3的样本训练SVM模型,并对剩余1/3的样本预测结果,得到预报值q。
步骤3.2:计算实际值与预报值之间的差值,得到预报误差时间序列用于样本整理的历史资料。
步骤3.3:对预报误差时间序列ei进行样本整理。选择当前时段t未来h小时误差值et+h作为输出值,当前时段前面k(2<k<10)个误差值(et,et-1,…et-k+1)作为输入值,建立当前时段h小时后误差值与历史误差值之间的对应关系(et,et-1,…et-k+1)∝et+h。对历史资料库中所有样本依次整理。
步骤3.4:训练模型,利用历史资料库中整理的样本训练BP神经网络模型,通过调整参数使得模型尽可能与训练数据吻合。
步骤3.5:模型预测,将当前误差样本(et,et-1,…et-k)∝et+h作为模型输入得到预测结果。
步骤3.6:校正预报值,将模型预报值qt加上误差预报值et得到校正后预报值Qt。
步骤3.7:到时段t+1,将时段i处未校正前预报误差加入历史资料库,这样实时更新资料库后,再返回步骤3,实现递归的实时校正。
为了验证本发明的效果,选取昌化汛期数据作为研究对象,昌化流域位于浙江省分水江流域上游,地势西北高东南低,属浙西山丘区,典型的中小河流水系。选取1998-2010年每年汛期场次洪水数据,数据时间间隔为1小时,其中1998年-2009年共6790个数据作为训练样本,2010年共671个数据作为测试样本。首先对样本进行主成分分析,去除噪声影响,保留有效信息,然后将单个支持向量机模型预测结果与K-means聚类后多个模型预测结果以及BP神经网络校正后的结果分别进行比较。实验结果如下表所示:
表一为三种不同方案预测结果比较
实验结果表明:基于聚类分析的多模型预报,能较好的提高预报准确率,这是因为洪水数据受到流域下垫面、土壤含水量以及季节等不同因素的影响,导致不同流量范围的洪水数据具有不同的数据分布特点,高流量与低流量数据输入输出之间的映射关系不同,所以通过聚类分析将相同分布特点的数据划分为同一类,这样很好解决了其他数据的干扰。
图2洪水发生时预报结果表明:单模型预报结果最差,预报值超过实际值,容易造成谎报;聚类后预报值明显提高了预报准确率,但是与实际值还是存在一定偏差;最后通过BP网络实时校正后预报值与实际值基本吻合,这是因为训练样本中含有洪峰时刻预报误差的信息,BP神经网络模型能够很好的学习到这种误差信息,这样前面出现的误差对后面预报值起到很好的修正作用,所以很好的提高了预报准确率。
以上所述仅为本发明的实施例子而已,并不用于限制本发明,本发明对于数值计算中研究对象的精确显示尤其适用。凡在本发明的原则之内,所作的等同替换,均应包含在本发明的保护范围之内。本发明未作详细阐述的内容属于本专业领域技术人员公知的已有技术。
- 还没有人留言评论。精彩留言会获得点赞!