一种基于贝叶斯模型的视觉人体行为识别方法与流程
本发明涉及计算机视觉领域,特别涉及一种基于贝叶斯模型的视觉人体行为识别方法。
背景技术:
视觉人体行为识别是计算机视觉领域中一个重要的研究问题,它在智能监控、高级人机交互、电影动画制作等场合都具有巨大的应用价值。通常视觉人体行为识别方法主要包括两个步骤:(1)将视频中的人体行为信息表达为向量或图等形式,得到视觉人体行为的表达;(2)利用得到的表达输入相关的分类方法,如支持向量机等,完成分类与识别。
在目前关于视觉人体行为分析的诸多研究工作中,多数方法是将这两个步骤分别独立完成,即按照先后顺序分步独立进行。这样的方法由于将表示与识别分别独立进行,因此既无法保证所得到的表达可以最优的适用于后一步骤中所设计的识别方法,也无法保证所选择的识别方法可以最佳的利用前一步骤中所得到的表达。
另一方面,贝叶斯类模型由于直接对数据之间的关系进行建模,从统计的角度表示出数据的分布情况,可以克服传统词包模型无法表达特征的潜在语义的不足,往往可以学习出关于数据的本质特征,因而在视觉人体行为分析领域中也得到了广泛应用。但目前的多数贝叶斯类方法纯粹从产生式模型的角度出发,忽略了对判别性信息的利用。
同时,目前在人体行为分析任务中,多是采用基于最大间隔准则的判别性方法,如支持向量机类方法,来实现分类与识别。该方法由于直接以衡量分类性能优劣的分类损失为优化目标,因此在包括许多行为分析的识别任务中都取得了较好的识别效果。另外,该类识别方法直接通过优化问题的求解来达到最终最优化分类性能的目的,实现方法成熟,因此得到了广泛应用。
当前的这些行为识别方法通常只侧重于表示或识别的某一个环节,而无法形成统一的学习框架,不能使表示结果与识别结果相互增强相互调节,使其适用范围受到了较大的限制。
技术实现要素:
本发明针对现有技术存在的上述问题,提出一种基于贝叶斯模型的视觉人体行为识别方法,其能够有效的应对复杂行为背景的情况,进而实现鲁棒的行为识别。
本发明的基于贝叶斯模型的视觉人体行为识别方法包括以下步骤:
步骤1:提取训练视频中的特征,形成对所述训练视频中人体行为的底层表达;
步骤2:从所述特征出发,构建分层贝叶斯模型,以提取所述训练视频中不同尺度下的人体行为模式,得到基于高层语义信息的人体行为表达;
步骤3:嵌入最大间隔机制,实现判别式的分层贝叶斯模型的学习;
步骤4:学习所述判别式的分层贝叶斯模型的参数,以确定所述参数。
进一步地,步骤1具体包括以下内容:
步骤1a:以所述训练视频中像素点的像素值变化为基础,检测所述训练视频中的人体行为的显著点;
步骤1b:以各所述显著点为中心,分别构建描述子,形成对各所述显著点为中心的局部区域的描述;
步骤1c:对所有所述描述子进行聚类,形成相应的视觉单词和视觉词典,进而构建基于词包模型的直方图向量,形成所述训练视频中人体行为的所述底层表达。
优选地,所述描述子为3DSIFT描述子。
进一步地,步骤2具体包括以下内容:
步骤2a:根据参数为M的先验分布Uniform(M)抽取训练视频d∈{1,...,M},其中,M为全部所述训练视频的数量;
步骤2b:根据参数为θd的全局行为模式分布,从被抽取的所述训练视频d抽取全局行为模式zd,n=k,k=1,...,K,其中K表示所有不同全局行为模式的数目;
步骤2c:根据依赖于被抽取的所述全局行为模式zd,n=k、参数为τk的局部行为模式分布,抽取局部行为模式hd,n=r,r=1,...,R,其中R表示所有不同局部行为模式的数目;
根据依赖于被抽取的所述局部行为模式hd,n=r、参数为φr的所述视觉单词的分布,抽取视觉单词wd,n∈{1,...,V}。
优选地,对所述参数θd、τk和φr分别赋予参数为α的K维狄利克雷先验分布、参数为γ的R维狄利克雷先验分布和参数为β的V维狄利克雷先验分布。
优选地,所述全局行为模式分布和/或所述局部行为模式分布和/或所述视觉单词的分布为多项式分布。
进一步地,步骤3具体包括以下内容:
步骤3a:以各所述训练视频中所述全局行为模式出现频次的平均值作为对所述训练视频的表达;
步骤3b:将所述表达输送到系数参数为ηc的线性分类器中,得到判别函数的值其中c=1,…,C表示第c类,C表示类别数目;
步骤3c:计算基于最大间隔准则的损失其中当所述视频的真实类别是c时,否则
步骤3d:引入与所述损失ζd,c对应的隐变量λd,c,并将所述损失ζd,c表达为混合分布形式。
进一步地,步骤4具体包括以下内容:
步骤4a:对所述训练视频中的每个视觉单词所属的全局行为模式与局部行为模式分别赋予区间[1,K]和[1,R]内的随机整数值;
步骤4b:计算hd,n=r、zd,n=k、λd,c、ηd,c(ηd,c表示变量ηc的第d个元素)的后验分布,并分别进行轮流重复采样,直至收敛或达到一预定的采样次数;
步骤4c:以所述参数θd、τk和φr的后验分布均值联合采样后的各统计量得到对所述参数θd、τk和φr的估计;
步骤4d:记录相关统计量,以用于测试视频的推断过程。
进一步地,还包括对测试视频进行识别的步骤5,所述步骤5具体包括以下内容:
步骤5a:对测试视频中的每个视觉单词所属的全局行为模式与局部行为模式分别赋予区间[1,K]和[1,R]内的随机整数值;
步骤5b:联合在上述步骤4中得到的训练视频中的各参数值与统计量,对所述测试视频中各个视觉单词所属的全局行为模式zd,n与局部行为模式hd,n进行采样,直到达到收敛条件或达到一预定的采样次数;
步骤5c:计算所述测试视频中所有全局行为模式的出现频次的平均值作为对所述测试视频的表达;
步骤5d:利用学习得到的判别函数参数ηc,计算所述测试视频属于各类的分值并将所述测试视频划分到分值最大的那一类,完成识别。
优选地,步骤1中提取的所述特征为局部特征。
本发明的基于贝叶斯模型的视觉人体行为识别方法,通过引入最大间隔机制到识别模型中,与之前的识别模型统一起来形成一个统一的判别式的分层贝叶斯模型,从而实现了统一训练视频表示与识别模型的参数的目的,能够有效的应对复杂行为背景的情况,进而实现鲁棒的行为识别。
附图说明
图1是本发明的基于贝叶斯模型的视觉人体行为识别方法的流程图;
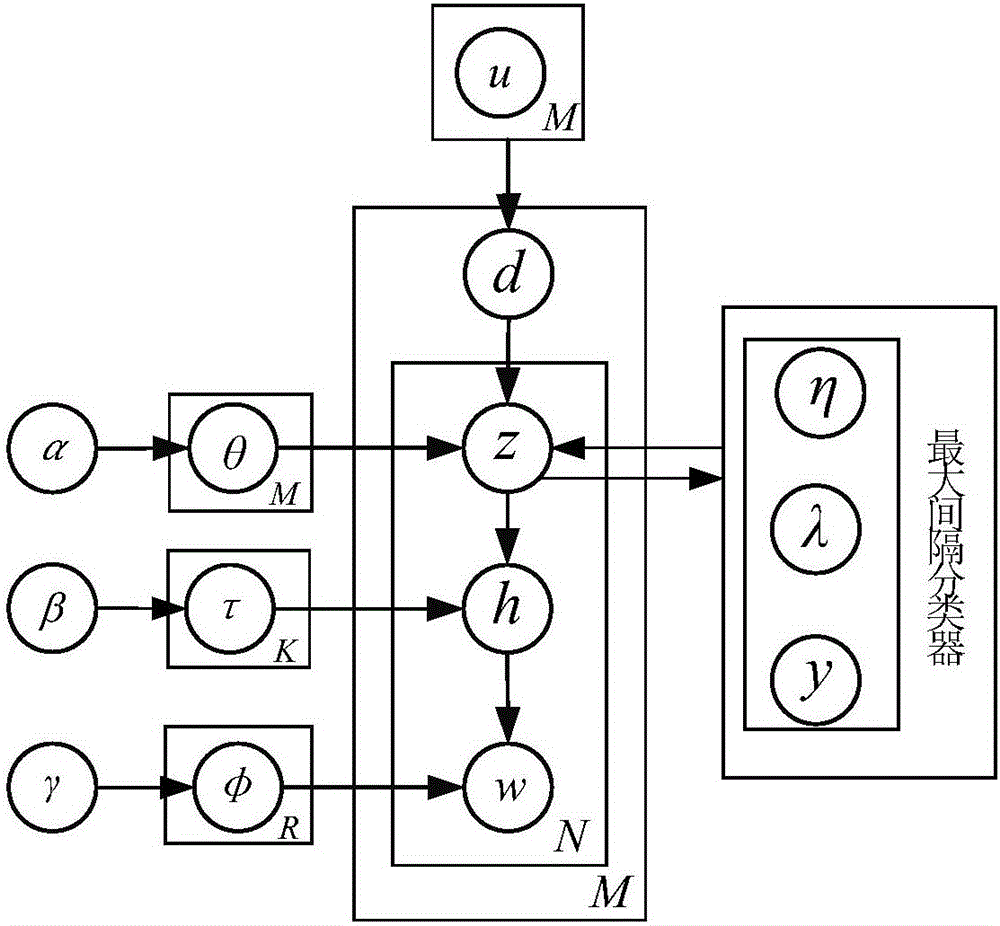
图2是本发明的分层贝叶斯模型示意图。
具体实施方式
下面参照附图来描述本发明的优选实施方式。本领域技术人员应当理解的是,这些实施方式仅仅用于解释本发明的技术原理,并非旨在限制本发明的保护范围。
本发明的基于贝叶斯模型的视觉人体行为识别方法的具体运行的硬件和编程语言并不受限制,用任何语言编写都可以实现本发明的方法。例如采用一台具有2.83G赫兹中央处理器和4G字节内存的计算机,并用Matlab语言与VC++相结合编制基于互补性表达与嵌入多重随机性的工作程序,就能实现本发明的方法。
图1是本发明的基于贝叶斯模型的视觉人体行为识别方法的流程图,图2是本发明的分层贝叶斯模型示意图。该方法包括以下步骤:
步骤1:提取训练视频中的特征,形成对所述训练视频中人体行为的底层表达;
步骤2:从所述特征出发,构建分层贝叶斯模型,以提取所述训练视频中不同尺度下的人体行为模式,得到基于高层语义信息的人体行为表达;
步骤3:嵌入最大间隔机制,实现判别式的分层贝叶斯模型的学习;
步骤4:学习所述判别式的分层贝叶斯模型的参数,以确定所述参数。
在步骤1中,所提取的特征优选为训练视频中人体行为的局部特征。此外,也可以使用全局特征,但与全局特征相比,局部特征一般对噪声不敏感,鲁棒性更好,所以这里优先选择局部特征。
具体地,步骤1包括如下步骤:
步骤1a:以所述训练视频中像素点的像素值变化为基础,检测所述训练视频中的人体行为的显著点;
步骤1b:以各所述显著点为中心,分别构建描述子,形成对各所述显著点为中心的局部区域的描述;
步骤1c:对所有所述描述子进行聚类,形成相应的视觉单词和视觉词典,进而构建基于词包模型的直方图向量,形成所述训练视频中人体行为的所述底层表达。
在基于词包模型的直方图向量的人体行为表达中,每个训练视频因包含多个视觉单词而被视为一个视觉文档d,其中d∈{1,...,M},M表示总的视觉文档个数,也即总的视频数目,视觉单词记为wd,n,n∈{1,...,Nd},其中Nd表示整个训练视频中的视觉单词总数。
本发明中,优选使用3DSIFT描述子作为所述描述子。
普通的SIFT(尺度不变特征变换)描述子是在图像的空间维求梯度进行计算最后的特征值,这里的3DSIFT是将一般的2DSIFT描述子从图像扩展到视频,涵盖空间维和时间维一共三维XYT,能较好地体现表观特性。因此本发明中3DSIFT描述子最好,优于2DSIFT和其他描述子。
具体地,步骤2包括如下步骤:
步骤2a:根据参数为M的先验分布Uniform(M)抽取练视频d∈{1,...,M},其中,M为全部所述训练视频的数量。
步骤2b:根据参数为θd的全局行为模式分布,从被抽取的所述训练视频d抽取全局行为模式zd,n=k,k=1,...,K,其中K表示所有不同全局行为模式的数目。
步骤2c:根据依赖于被抽取的所述全局行为模式zd,n=k、参数为τk的局部行为模式分布,抽取局部行为模式hd,n=r,r=1,...,R,其中R表示所有不同局部行为模式的数目。
步骤2d:根据依赖于被抽取的所述局部行为模式hd,n=r、参数为φr的所述视觉单词的分布,抽取视觉单词wd,n∈{1,...,V}。
重复Nd次步骤2b~步骤2d,直至生成训练视频d中的每一个视觉单词,其中Nd表示训练视频d中的视觉单词个数。
优选地,采用均匀分布作为先验分布Uniform(M),使得每个训练视频在初始时都有同样被抽中的机会。此外也可以用其它分布,但用均匀分布表示事先对所有训练视频“一视同仁”,没有偏向信息,通常更加具有合理性。
优选地,对所述参数θd、τk和φr分别赋予参数为α的K维狄利克雷先验分布、参数为γ的R维狄利克雷先验分布和参数为β的V维狄利克雷先验分布。
优选地,在步骤2b中,在给定的当前训练视频的条件下,全局行为模式的分布为参数为θ的多项式分布Mult(zd,n|θ)。
在步骤2c中,在每个全局行为模式下的局部行为模式分布为多项式分布Mult(hd,n|τ,zd,n)。
优选地,在步骤2d中,视觉单词的条件分布为多项式分布,简记为Mult(wd,n|hd,n,φ)。
本发明中,可如下地求得上述参数θd、τk和φr:
根据被抽取的当前训练视频d中的全局行为模式分布的参数θ的先验分布p(θ|α,d),抽取当前训练视频d的全局行为模式分布变量θd,其中θd是一个M×K的矩阵,每一行代表了每一个训练视频中全局行为模式的分布,α是一个K维的向量,表示θ所服从的狄利克雷先验分布的参数,K是所有全局行为模式的数目;
根据在给定全局行为模式分布时局部行为模式的分布参数τ的先验分布p(τ|γ,z=k),抽取当前训练视频d的局部行为模式分布变量τk,其中τk是一个K×R的矩阵,每一行代表了每一个全局行为模式中局部行为模式的分布,γ是一个R维的向量,表示τ所服从的狄利克雷先验分布的参数,R是所有局部行为模式的数目;
根据在给定局部行为模式下视觉单词的分布参数φ的先验分布p(φ|β,h=r),抽取当前局部行为模式下的视觉单词的分布变量φr,其中h=r用以表示当前的局部行为模式取值为r,φr是一个R×V的矩阵,每一行代表了在每个局部行为模式下的视觉单词的分布,β是一个V维的向量,表示φr所服从的狄利克雷先验分布的参数,V是视觉单词组成的词典大小。
具体地,步骤3包括如下步骤:
步骤3a:以各所述训练视频中所述全局行为模式出现频次的平均值作为对所述训练视频的表达;
步骤3b:将所述表达输送到系数参数为ηc的线性分类器中,得到判别函数的值其中c=1,…,C表示第c类,C表示类别数目;
步骤3c:计算基于最大间隔准则的损失其中当所述视频的真实类别是c时,否则
步骤3d:引入与所述损失ζd,c对应的隐变量λd,c,并将所述损失ζd,c表达为混合分布形式。
具体地,步骤4包括如下步骤:
步骤4a:对所述训练视频中的每个视觉单词所属的全局行为模式与局部行为模式分别赋予区间[1,K]和[1,R]内的随机整数值;
步骤4b:计算hd,n=r、zd,n=k、λd,c、ηd,c的后验分布,并分别进行轮流重复采样,直至收敛或达到一预定的采样次数;
其中,如下地计算hd,n=r的后验概率分布,并对其进行采样:
式中的上标“-”表示在统计时不计算当前第n个的视觉单词,D表示整体训练集,表示除当前视觉单词以外,全局行为模式取值为k的视觉单词数目,表示除当前视觉单词以外,局部行为模式取值为r的视觉单词数目,表示除当前视觉单词外,全局行为模式为k同时局部行为模式为r的视觉单词数目,表示除当前视觉单词外,局部行为模式为r同时视觉单词本身取值为w的视觉单词数目。
如下地计算zd,n=k的后验概率分布如下,并对其进行采样:
其中,表示在文档d中除了当前单词以外全局行为模式为k的单词数目,表示在训练视频d中除了当前视觉单词以外的全部视觉单词的数目,ηc,k表示向量的第k个元素。
计算λd,c的后验概率如下,并对其进行采样:
其中表示变量x服从以q,b,g为参数的广义逆高斯分布。
如下地计算变量η的后验分布,并对进行采样:
其中,
重复上述步骤,轮流采样变量、zd,n、λd,c、ηd,c直到收敛或达到一预定的采样次数。例如当采样变量的相对变化小于1e-7时就停止采样,或者通常可以设置当采样次数达到100次左右即停止。
步骤4c:以所述参数θd、τk和φr的后验分布均值联合采样后的各统计量得到对所述参数θd、τk和φr的估计;
步骤4d:记录相关统计量,以用于测试视频的推断过程。具体地,以θd、τk和φr的后验分布均值联合采样后的各统计量得到对参数θd、τk和φr的估计,并记录此时的各统计量,包括Nkr、Nrw、Nk和Nr,分别表示在全局行为模式k下局部行为模式为r的视觉单词数目、在局部行为模式r下视觉单词取值为w的单词数目、所有全局行为模式取值为k的视觉单词数和所有局部行为模式取值为r的单词数目。
本发明的方法还包括对测试视频进行识别的步骤,该步骤具体包括如下步骤:
步骤5a:对测试视频中的每个视觉单词所属的全局行为模式与局部行为模式分别赋予区间[1,K]和[1,R]内的随机整数值;
步骤5b:联合在上述步骤4中得到的训练视频中的各参数值与统计量,对所述测试视频中各个视觉单词所属的全局行为模式zd,n与局部行为模式hd,n进行采样,直到达到收敛条件或达到一预定的采样次数;其中,
(a)利用下式对测试视频中的全局行为模式进行采样:
其中表示测试视频d中的第n个视觉单词对应的全局行为模式,表示当前测试视频d所拥有的数据;表示测试视频d中的第n个视觉单词对应的局部行为模式,表示测试视频d中的第n个视觉单词,分别表示测试视频d中的视觉单词总数、测试视频d中全局行为模式取值为k的视觉单词总数、测试视频d中全局行为模式为k且局部行为模式为r的视觉单词总数和测试视频中所有全局行为模式为k的视觉单词总数,Nk,r和Nk则为步骤4中记录的训练集中的相关统计量。
(b)利用下式对测试视频中的局部行为模式进行采样:
其中和分别表示在测试视频中局部行为模式取值为r的视觉单词总数和在局部行为模式取值为r时单词本身取值w的单词数目;Nr和Nr,w分别表示在步骤4g中记录的训练集中的相关统计量。
重复步骤(a)(b),轮流对测试视频中的视觉单词所对应的全局行为模式与局部行为模式进行采样,直到达到收敛条件或达到一预定的采样次数。例如当采样变量的相对变化小于1e-7时就停止采样,或者通常可以设置当采样次数达到100次左右即停止。
步骤5c:计算所述测试视频中所有全局行为模式的出现频次的平均值作为对所述测试视频的表达;
步骤5d:利用学习得到的判别函数参数ηc,计算所述测试视频属于各类的分值并将所述测试视频划分到分值最大的那一类,完成识别。
通过对测试视频进行识别的步骤,能够评估通过前面的步骤建立的模型的识别性能,进而可以对模型进行改进。
本发明的基于贝叶斯模型的视觉人体行为识别方法,通过引入最大间隔机制到识别模型中,与之前的识别模型统一起来形成一个统一的判别式的分层贝叶斯模型,从而实现了统一训练视频表示与识别模型的参数的目的,能够有效的应对复杂行为背景的情况,进而实现鲁棒的行为识别。
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征作出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!