基于人工智能的命名实体识别方法及装置与流程
本申请涉及自然语言技术领域,尤其涉及一种基于人工智能的命名实体识别方法及装置。
背景技术:
人工智能(Artificial Intelligence,简称AI)。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语音识别、图像识别、自然语言处理和专家系统等。
自然语言处理是人工智能的一个重要方向,而命名实体识别(Name Entity Recognition,NER)是其研究中重要且不可缺少的一步。
随着互联网信息量的迅速增长和网络文化的发展,网络用语中新词层出不穷,旧词语义日新月异,例如“小苹果”、“亲爱的”、“饿了么”等。其中,绝大部份新词、新意都是实体词汇、词义,即描述现实世界中存在的人、事物以及概念的词。大量的新词和不断变化的语义使得自然语言处理中命名实体的识别十分困难。
相关技术中,提出监督的机器学习模型或者是简单词典、规则匹配的命名实体识别方法。然而,有监督的机器学习模型虽然准确率高,但是需要大量人工标注的训练语料,使得模型的更新成本高,更新频率低,从而模型的时效性差,简单词典、规则匹配的命名实体识别方法准确率较低。
技术实现要素:
本申请的目的旨在至少在一定程度上解决上述的技术问题之一。
为此,本申请的第一个目的在于提出一种基于人工智能的命名实体识别方法,该方法通过利用条件随机场模型和根据预设时间段内的检索日志生成的功能模型,同时对待识别文本进行识别,能够保证对时效性较高的待识别文本进行准确识别,提高了命名实体识别的时效性、准确性和准确率。
本申请的第二个目的在于提出了一种基于人工智能的命名实体识别装置。
本申请的第三个目的在于提出了另一种基于人工智能的命名实体识别装置。
本申请的第四个目的在于提出了一种非临时性计算机可读存储介质。
本申请的第五个目的在于提出了一种计算机程序产品。
为达上述目的,根据本申请第一方面实施例提出的一种基于人工智能的命名实体识别方法,包括以下步骤:
根据条件随机场模型(Conditional Random Field,简称CRF),对待识别文本进行命名实体识别,确定第一识别结果;
根据预设的实体词汇功能模型,对待识别文本进行命名实体识别,确定第二识别结果,其中所述预设的实体词汇功能模型为基于预设时间段内的检索日志生成的功能模型;
判断所述第一识别结果和第二识别结果是否一致;
若否,则选择置信度高的识别结果作为所述待识别文本的命名实体识别结果。
本申请实施例的基于人工智能的命名实体识别方法,首先根据条件随机场模型,对待识别文本进行命名实体识别,确定第一识别结果,然后根据预设的实体词汇功能模型,对待识别文本进行命名实体识别,确定第二识别结果,并判断第一识别结果和第二识别结果是否一致,最后在第一识别结果和第二识别结果一致时选择置信度高的识别结果作为待识别文本的命名实体识别结果。由此,通过利用条件随机场模型和根据预设时间段内的检索日志生成的功能模型,同时对待识别文本进行识别,能够保证对时效性较高的待识别文本进行准确识别,提高了命名实体识别的时效性、准确性和准确率。
为达上述目的,根据本申请的第二方面实施例提出的一种基于人工智能的命名实体识别装置,包括:
第一确定模块,用于根据条件随机场模型,对待识别文本进行命名实体识别,确定第一识别结果;
第二确定模块,用于根据预设的实体词汇功能模型,对待识别文本进行命名实体识别,确定第二识别结果,其中所述预设的实体词汇功能模型为基于预设时间段内的检索日志生成的功能模型;
判断模块,用于判断所述第一识别结果和第二识别结果是否一致;
选择模块,用于在所述第一识别结果和第二识别结果不一致时,选择置信度高的识别结果作为所述待识别文本的命名实体识别结果。
本申请实施例的基于人工智能的命名实体识别装置,首先根据条件随机场模型,对待识别文本进行命名实体识别,确定第一识别结果,然后根据预设的实体词汇功能模型,对待识别文本进行命名实体识别,确定第二识别结果,并判断第一识别结果和第二识别结果是否一致,最后在第一识别结果和第二识别结果一致时选择置信度高的识别结果作为待识别文本的命名实体识别结果。由此,通过利用条件随机场模型和根据预设时间段内的检索日志生成的功能模型,同时对待识别文本进行识别,能够保证对时效性较高的待识别文本进行准确识别,提高了命名实体识别的时效性、准确性和准确率。
为达上述目的,根据本申请的第三方面实施例提出的一种基于人工智能的命名实体识别装置,包括:处理器;用于存储处理器可执行指令的存储器;其中,所述处理器被配置为:
根据条件随机场模型(Conditional Random Field,简称CRF),对待识别文本进行命名实体识别,确定第一识别结果;
根据预设的实体词汇功能模型,对待识别文本进行命名实体识别,确定第二识别结果,其中所述预设的实体词汇功能模型为基于预设时间段内的检索日志生成的功能模型;
判断所述第一识别结果和第二识别结果是否一致;
若否,则选择置信度高的识别结果作为所述待识别文本的命名实体识别结果。
为达上述目的,根据本申请的第四方面实施例提出的一种非临时性计算机可读存储介质,当所述存储介质中的指令由移动终端的处理器被执行时,使得移动终端能够执行一种基于人工智能的命名实体识别方法,所述方法包括:
根据条件随机场模型(Conditional Random Field,简称CRF),对待识别文本进行命名实体识别,确定第一识别结果;
根据预设的实体词汇功能模型,对待识别文本进行命名实体识别,确定第二识别结果,其中所述预设的实体词汇功能模型为基于预设时间段内的检索日志生成的功能模型;
判断所述第一识别结果和第二识别结果是否一致;
若否,则选择置信度高的识别结果作为所述待识别文本的命名实体识别结果。
为达上述目的,根据本申请的第五方面实施例提出的一种计算机程序产品,当所述计算机程序产品中的指令处理器执行时,执行一种基于人工智能的命名实体识别方法,所述方法包括:
根据条件随机场模型(Conditional Random Field,简称CRF),对待识别文本进行命名实体识别,确定第一识别结果;
根据预设的实体词汇功能模型,对待识别文本进行命名实体识别,确定第二识别结果,其中所述预设的实体词汇功能模型为基于预设时间段内的检索日志生成的功能模型;
判断所述第一识别结果和第二识别结果是否一致;
若否,则选择置信度高的识别结果作为所述待识别文本的命名实体识别结果。
本申请附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。
附图说明
本申请的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1是根据本申请一个实施例的基于人工智能的命名实体识别方法的流程图;
图2是根据本申请一个实施例的确定普通语义先验的示意图;
图3是根据本申请另一个实施例的基于人工智能的命名实体识别方法的流程图;
图4是根据本申请一个实施例的确定实体类别先验的示意图;
图5是根据本申请一个实施例的基于人工智能的命名实体识别装置的结构示意图;以及
图6是根据本申请另一个实施例的基于人工智能的命名实体识别装置的结构示意图。
具体实施方式
下面详细描述本申请的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本申请,而不能理解为对本申请的限制。
下面参考附图描述本申请实施例的基于人工智能的命名实体识别方法及装置。
图1是根据本申请一个实施例的基于人工智能的命名实体识别方法的流程图。
如图1所示,本申请实施例的基于人工智能的命名实体识别方法包括以下步骤:
步骤101,根据条件随机场模型,对待识别文本进行命名实体识别,确定第一识别结果。
其中,本实施例提供的基于人工智能的命名实体识别方法可以被配置在手机、电脑、智能佩戴设备等电子设备中。
通常,在语言文本中,命名实体是信息的主要载体,用来表达文本的主要内容。随着大量的新词和不断变化的语义使得命名实体识别十分困难,通过监督的机器学习模型或者是简单词典、规则匹配等命名实体识别方法的识别准确率低。
为了解决上述问题,本申请实施例提出一种基于人工智能的命名实体识别方法,能够保证模型具有较高的时效性,提升了命名实体识别的准确率。
首先,可以采用现有的条件随机场模型对待识别文本进行命名实体识别,确定第一识别结果。其中,待识别文本可以是用户通过查询输入法直接输入的文本、或者是用户通过查询语音进而语音识别系统转换的文本等。
步骤102,根据预设的实体词汇功能模型,对待识别文本进行命名实体识别,确定第二识别结果,其中预设的实体词汇功能模型为基于预设时间段内的检索日志生成的功能模型。
其中,预设时间段可以根据实际应用需要进行选择设置,比如为最近一周、最近一个月等,以预设时间段内的检索日志语料,生成预设的实体词汇功能模型,从而可以保证实体词汇功能模型的时效性较高。
其中,预设的实体词汇功能模型中可以包括实体词汇的切分歧义先验、普通语义先验和实体特征等中的一种或者多种。举例说明如下:
在本示例中,根据包括实体词汇的切分歧义先验、普通语义先验和实体特征库的预设的实体词汇功能模型,待识别文本进行命名实体识别,确定第二识别结果。具体地,首先可以通过词典、规则匹配等方法得到待识别文本中所有的候选命名实体词汇。
进而,通过候选命名实体词汇对应的切分歧义先验,判断其作为命名实体词汇的置信度的高低。其中,预设的实体词汇功能模型中各个实体词汇的切分歧义先验,是通过统计各实体词汇的边界在检索日志中与分词边界发生冲突的概率,以及在检索日志中被其他实体词汇覆盖的概率确定的。若实体词汇的边界与分词边界切分冲突概率大(例如大于百分之八十),或者是被其他实体词汇覆盖的概率大(例如大于百分之八十),则表明实体词汇对应的切分歧义大,即实体词汇通常是被切开的,从而其作为实体词汇的置信度就低。
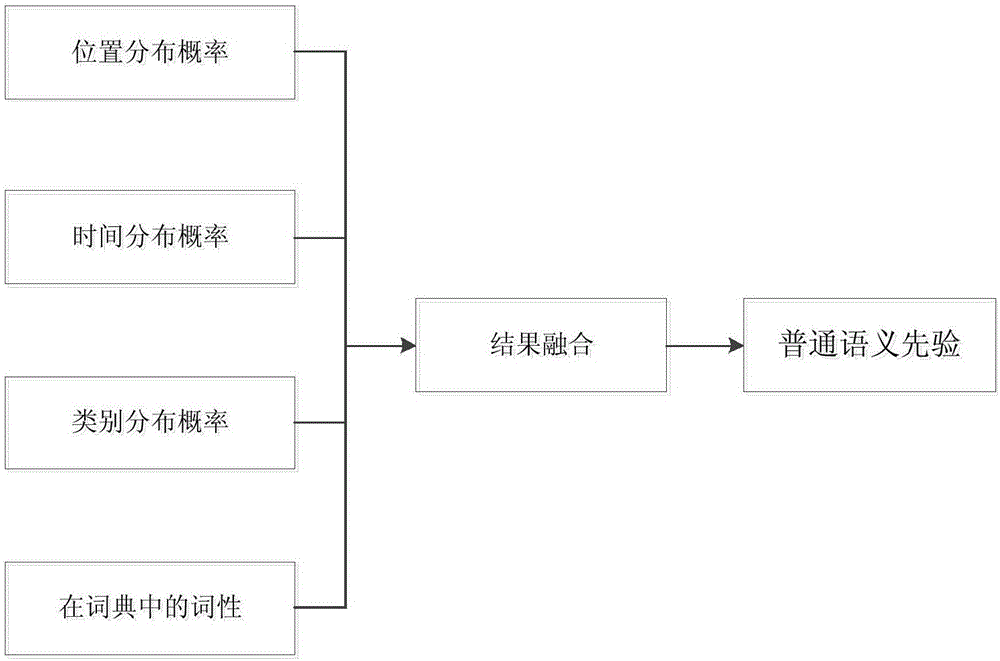
进而,通过候选命名实体词汇对应的普通语义先验,判断其作为命名实体词汇的置信度的高低。其中,预设的实体词汇功能模型中各个实体词汇的普通语义先验,是通过各命名实体词汇在检索日志中的位置分布概率、时间分布概率、类别分布概率及在词典中的词性确定的。
其中,普通语义是指作为非实体的语义,包括普通词、普通短语和普通句子。与实体词汇相比,普通词、普通短语和普通句子等使用的领域类别、时间范围更广。
图2是根据本申请一个实施例的确定普通语义先验的示意图。如图2所示,通过位置分布概率、时间分布概率、类别分布概率及在词典中的词性后经过结果融合得到普通语义先验。
其中,位置分布概率具体是指由于用户的使用习惯,在检索日志中,被检索的实体词汇通常单独出现,或与限定词用空格分开;反之,普通词、短语通常与上下文连成一体。由此,根据各实体词汇独立或分割检索的概率,即可估算其普通语义先验。
其中,时间分布概率,是指根据实体词汇在检索日志中的变化趋势。其中,普通词、短语在检索日志中的分布随时间的变化趋势相对平缓,而实体词汇在时间维度上的分布一般存在明显的上升期和衰退期。由此,根据变化趋势显著性可估算普通语义先验。
其中,类别分布概率,是指实体词汇在检索日志中的各个类别中分布的概率。通常,实体词汇多集中分布在特定的类别检索日志中,而普通词、短语一般均匀分布在各个类别检索日志中,领域相关的普通词则均匀分布在领域内的各个检索日志中。由此,根据类间分布或类内分布的均匀性可估算普通语义先验。
其中,在词典中的词性具体是指现有词典中记载的高频动词、副词、形容词等可作为普通语义的高优候选。由此,可以根据词性估算普通语义先验。
由此,实体词汇的普通词先验越高,表明它作为普通义项概率越高,作为实体词汇的置信度越低。
另外,还可以通过候选命名实体词汇对应的实体特征匹配结果,判断其作为命名实体词汇的置信度的高低。其中,预设的实体词汇功能模型中各个实体词汇的实体特征库中,包括的是与各实体词汇在检索日志中的所有关联特征。如果实体特征匹配越多,表明匹配到的特征权重越高,从而其作为实体词汇的置信度越高。
由此,可以通过上述方式得到候选命名实体词汇分别对应的切分歧义先验、普通语义先验和实体特征匹配结果,从而确定各候选命名实体词汇分别对应的置信度,从候选命名实体词汇中,将置信度最高的第一命名实体词汇确定为第二识别结果。
为了本领域人员更加清楚上述实施例的具体过程,以“陈可辛亲爱的小孩适合看吗”作为待识别文本为例进行详细说明。
首先,通过词典匹配得到冲突的候选命名实体词汇为“亲爱”、“亲爱的”和“亲爱的小孩”。
进而,从切分歧义先验上看三个候选命名实体词汇边界与分词边界没有发生冲突。
进而,从普通语义先验上看候选命名实体词汇“亲爱”作为普通语义的概率最高,候选命名实体词汇“亲爱的”在特定时间段(电影上映时间)作为普通语义的概率不高。
进而,从实体特征匹配结果上看候选命名实体词汇“亲爱”(电视剧)匹配特征“看”,候选命名实体词汇“亲爱的”匹配特征“陈可辛”和“看”,候选命名实体词汇“亲爱的小孩”没有匹配到实体特征,
由此,根据切分歧义先验可以确定候选命名实体词汇为“亲爱”、“亲爱的”和“亲爱的小孩”置信度高,例如均为0.95。根据普通语义先验可以确定候选命名实体词汇“亲爱”置信度低,例如为0.1,候选命名实体词汇“亲爱的”置信度不低,例如为0.6。根据实体特征匹配结果可以确定“亲爱的小孩”置信度最低,例如为0.05,“亲爱”置信度低,例如为“0.5”,“亲爱的”置信度最高,例如为“0.9”。从而可以确定“亲爱的”置信度最高,作为第二识别结果。
步骤103,判断第一识别结果和第二识别结果是否一致。
步骤104,若否,则选择置信度高的识别结果作为待识别文本的命名实体识别结果。
具体地,继续以上述例子为例进行说明,根据条件随机场对上述“陈可辛亲爱的小孩适合看吗”进行命名实体识别,其中,第一识别结果和第二识别结果是否一致的情况有很多种。举例说明如下:
第一种示例,根据条件随机场中的一种模型对上述“陈可辛亲爱的小孩适合看吗”进行命名实体识别,得到的第一识别结果为“陈可辛”、“亲爱的”、“小孩”和“看”。根据预设的实体词汇功能模型,对待识别文本进行命名实体识别,确定第二识别结果也为“陈可辛”、“亲爱的”、“小孩”和“看”。
由此,第一识别结果和第二识别结果一致,可以将其中任一结果作为待识别文本“陈可辛亲爱的小孩适合看吗”的命名实体识别结果。
第二种示例,根据条件随机场中的一种模型对上述“陈可辛亲爱的小孩适合看吗”进行命名实体识别,得到的第一识别结果为“陈可辛”、“亲爱”、“小孩”和“看”。根据预设的实体词汇功能模型,对待识别文本进行命名实体识别,确定第二识别结果也为“陈可辛”、“亲爱的”、“小孩”和“看”。
由此,第一识别结果和第二识别结果不一致,将置信度高的第二识别结果作为待识别文本“陈可辛亲爱的小孩适合看吗”的命名实体识别结果。
需要说明的是,如果第一识别结果和第二识别结果的置信度一致,可以选择“长”的识别结果作为最终结果。例如,“羽泉亲爱的”的查询对应的两个识别结果分别是第一识别结果“羽泉演唱的亲爱的”和第二识别结果“羽泉所唱的歌曲亲爱的”,选择第二识别结果作为“羽泉亲爱的”的命名实体识别结果。
本申请实施例的基于人工智能的命名实体识别方法,首先根据条件随机场模型,对待识别文本进行命名实体识别,确定第一识别结果,然后根据预设的实体词汇功能模型,对待识别文本进行命名实体识别,确定第二识别结果,并判断第一识别结果和第二识别结果是否一致,最后在第一识别结果和第二识别结果一致时选择置信度高的识别结果作为待识别文本的命名实体识别结果。由此,通过利用条件随机场模型和根据预设时间段内的检索日志生成的功能模型,同时对待识别文本进行识别,能够保证对时效性较高的待识别文本进行准确识别,提高了命名实体识别的时效性、准确性和准确率。
图3是根据本申请另一个实施例的基于人工智能的命名实体识别方法的流程图。
如图3所示,本申请实施例的基于人工智能的命名实体识别方法包括以下步骤:
步骤201,根据条件随机场模型,对待识别文本进行命名实体识别,确定第一识别结果。
步骤202,确定待识别文本中包括的候选命名实体词汇。
步骤203,确定候选命名实体词汇分别对应的切分歧义先验、普通语义先验和实体特征匹配结果。
步骤204,根据候选命名实体词汇分别对应的切分歧义先验、普通语义先验和实体特征匹配结果,确定候选命名实体词汇分别对应的置信度。
需要说明的是,步骤S201-S204的描述与上述步骤S101-S102相对应,因此对的步骤S201-S204的描述参考上述步骤S101-S102的描述,在此不再赘述。
步骤205,确定候选命名实体词汇中,包括的置信度最高的第一命名实体词汇。
步骤206,判断第一命名实体词汇,是否对应至少两个实体类别或者实体。
步骤207,若是,则判断待识别文本的上下文特征是否完整,若是,则执行步骤208,否则,执行步骤209。
步骤208,根据待识别文本上下文特征,确定与第一命名实体词汇对应的至少两个实体类别或者实体,分别对应的置信度。
可以理解的是,第一命名实体词汇可能对应多个实体类别、或者是实体,例如“亲爱的”对应的实体类别可能为电影,也可能为歌曲,或者“李娜”对应的实体,可能为网球运动员,也可能为歌星。
由此,为了进一步提高命名实体识别的准确率,在将置信度最高的命名实体词汇确定为第二识别结果之前,需要判断第一命名实体词汇,是否对应至少两个实体类别或者实体。
进而,在获知第一命名实体词汇对应多个实体时,根据待识别文本上下文特征,例如“陈可辛亲爱的”,识别为“陈可辛”所导电影“亲爱的”,并赋予较高的置信度。再例如,“羽泉亲爱的”识别为“羽泉”所唱歌曲“亲爱的”,并赋予较高的置信度。由此,具有较高的消歧能力,进一步提高命名实体识别的准确率。
需要说明的是,上述第一方面实施例中,如果不通过候选命名实体词汇对应的实体特征匹配结果,判断其作为命名实体词汇的置信度的高低。本示例中可以通过第一实体词汇对应的实体特征匹配结果,判断其作为命名实体词汇的置信度的高低。
具体地,实体特征是上下文中能反映候选词汇倾向于作为实体、特定实体类别甚至特定实体义项的特征词汇。用户检索命名实体时通常采用空格的方式来附加一些限制条件,如“亲爱的黄渤”,“亲爱的在线观看”等等,这些限制条件多数可以作为实体的候选特征。再根据用户点击百科实体义项页面的行为日志,可以将部分候选特征与特定的实体义项建立关联,从而达到帮助实体消歧的目的。
步骤209,根据预设的实体词汇功能模型中的实体类别先验和实体需求度,确定与第一命名实体词汇对应的至少两个实体类别或者实体,分别对应的置信度。
步骤2010,从候选命名实体词汇中,将置信度最高的第一命名实体词汇确定为第二识别结果。
具体地,可能存在上下文特征缺失即上下文特征不完整的情况下,此时,可以通过预设的实体词汇功能模型中的实体类别先验和实体需求度,确定与第一命名实体词汇对应的至少两个实体类别或者实体,分别对应的置信度。
其中,通过第一实体词汇对应的实体类别先验,判断其作为命名实体词汇的置信度的高低。其中,预设的实体词汇功能模型中各个实体词汇的实体类别先验,是通过各实体词汇的构词成分分类,及在检索日志中的所有关联特征的分类比例、对应的检索结果的分类比例三种结果融合确定的。
图4是根据本申请一个实施例的确定实体类别先验的示意图。如图4所示,通过第一实体词汇的构词成分分类,及在检索日志中的所有关联特征的分类比例、对应的检索结果的分类比例后经过结果融合得到实体类别先验。
其中,构词成分分类具体是指部分类别的实体词汇存在明显的构词特征,如公司名、菜名等,利用构词成份特征可以实现对部分类别实体的准确分类。
其中,在检索日志中的所有关联特征的分类比例具体是指利用用户检索日志中的并列特征信息进行分类,分类结果一定程度上反映了用户主观认知中被检索实体词汇的实体类别先验。
其中,对应的检索结果的分类比例具体是指搜索引擎返回结果体现了实体词汇在互联网中使用形式的客观分布,通过对每条检索结果进行分类进而估算出实体类别先验。
需要说明的是,为避免干扰,可以从检索结果中清除推广信息,并同时引入例如百度贴吧、百度知道等的检索结果。
其中,通过第一实体词汇对应的实体用户需求度,判断其作为命名实体词汇的置信度的高低。其中,预设的实体词汇功能模型中各个实体词汇的实体用户需求度,是通过第一实体词汇的不同实体义项即不同意义在检索日志中所占的比例,确定第一实体词汇的实体用户需求度。
可以理解的是,在特定时间内用户对同一实体词汇的多个义项需求度通常会存在显著差异,根据检索日志中用户对不同百科页面(一个百科页面对应一个实体义项)的点击行为,即可统计出用户对不同实体义项的需求程度。
步骤2011,判断第一识别结果和第二识别结果是否一致。
步骤2012,若否,则选择置信度高的识别结果作为待识别文本的命名实体识别结果。
需要说明的是,步骤S2010-S2011的描述与上述步骤S103-S104相对应,因此对的步骤S2010-S2011的描述参考上述步骤S103-S104的描述,在此不再赘述。
本申请实施例的基于人工智能的命名实体识别方法,进一步通过判断第一命名实体词汇,是否对应至少两个实体类别或者实体,在是的情况下,根据待识别文本上下文特征,确定与第一命名实体词汇对应的至少两个实体类别或者实体,分别对应的置信度,以及判断待识别文本的上下文特征是否完整,在不完整的情况下,根据预设的实体词汇功能模型中的实体类别先验和实体需求度,确定与第一命名实体词汇对应的至少两个实体类别或者实体,分别对应的置信度。由此,在根据预设的实体词汇功能模型确定的识别结果又歧义时,通过根据命名实体对应的不同类的别先验及实体需求度,对识别结果进行进一步消歧,从而进一步提高了命名实体识别的准确性和准确率。
为了实现上述实施例,本申请还提出了一种基于人工智能的命名实体识别装置。
图5是根据本申请一个实施例的基于人工智能的命名实体识别装置的结构示意图。
如图5所示,该基于人工智能的命名实体识别装置包括:第一确定模块51、第二确定模块52、判断模块53、选择模块54和第三确定模块55。
其中,第一确定模块51用于根据条件随机场模型,对待识别文本进行命名实体识别,确定第一识别结果。
第二确定模块52用于根据预设的实体词汇功能模型,对待识别文本进行命名实体识别,确定第二识别结果,其中预设的实体词汇功能模型为基于预设时间段内的检索日志生成的功能模型。
判断模块53用于判断第一识别结果和第二识别结果是否一致。
选择模块54用于在第一识别结果和第二识别结果不一致时,选择置信度高的识别结果作为待识别文本的命名实体识别结果。
首先,可以采用现有的条件随机场模型对待识别文本进行命名实体识别,确定第一识别结果。
在本示例中,根据包括实体词汇的切分歧义先验、普通语义先验和实体特征库的预设的实体词汇功能模型,待识别文本进行命名实体识别,确定第二识别结果。
第二确定模块52包括:第一确定单元521、第二确定单元522、第三确定单元523和第四确定单元524。
其中,第一确定单元521用于确定待识别文本中包括的候选命名实体词汇。
第二确定单元522用于确定候选命名实体词汇分别对应的切分歧义先验、普通语义先验和实体特征匹配结果。
第三确定单元523用于根据候选命名实体词汇分别对应的切分歧义先验、普通语义先验和实体特征匹配结果,确定候选命名实体词汇分别对应的置信度。
第四确定单元524用于从候选命名实体词汇中,将置信度最高的第一命名实体词汇确定为第二识别结果。
其中,确定检索日志中包括的第一实体词汇的切分歧义先验,第三确定模块55用于:统计检索日志中,第一实体词汇的边界与分词边界发生冲突的概率、及第一实体词汇的边界被其他实体词汇覆盖的概率。根据第一实体词汇的边界与分词边界发生冲突的概率、和/或第一实体词汇的边界被其他实体词汇覆盖的概率,确定第一实体词汇的切分歧义。
其中,确定检索日志中包括的第一实体词汇的普通语义先验,第三确定模块55用于:根据第一实体词汇,在检索日志中的位置分布概率、时间分布概率、类别分布概率及在词典中的词性,确定第一实体词汇的普通语义先验。
其中,确定检索日志中包括的第一实体词汇的实体特征库,第三确定模块用于:根据第一实体词汇,在检索日志中的所有关联特征,确定第一实体词汇的实体特征库。
需要说明的是,前述对基于人工智能的命名实体识别方法实施例的解释说明也适用于该实施例的基于人工智能的命名实体识别装置,其实现原理类似,此处不再赘述。
本申请实施例的基于人工智能的命名实体识别装置,首先根据条件随机场模型,对待识别文本进行命名实体识别,确定第一识别结果,然后根据预设的实体词汇功能模型,对待识别文本进行命名实体识别,确定第二识别结果,并判断第一识别结果和第二识别结果是否一致,最后在第一识别结果和第二识别结果一致时选择置信度高的识别结果作为待识别文本的命名实体识别结果。由此,通过利用条件随机场模型和根据预设时间段内的检索日志生成的功能模型,同时对待识别文本进行识别,能够保证对时效性较高的待识别文本进行准确识别,提高了命名实体识别的时效性、准确性和准确率。
图6是根据本申请另一个实施例的基于人工智能的命名实体识别装置的结构示意图。
如图6所示,在如图5所示的基础上,该基于人工智能的命名实体识别装置还包括:获取模块56。
获取模块56用于获取预设时间段内的检索日志。
第二确定模块52还包括第一判断单元525、第五确定单元526、第二判断单元527和第六确定单元528。
其中,第一判断单元525用于判断第一命名实体词汇,是否对应至少两个实体类别或者实体。
第五确定单元526用于第一命名实体词汇对应至少两个实体类别或者实体时,根据待识别文本上下文特征,确定与第一命名实体词汇对应的至少两个实体类别或者实体,分别对应的置信度。
第二判断单元527用于判断待识别文本的上下文特征是否完整。
第六确定单元528用于在待识别文本的上下文特征完整时,根据预设的实体词汇功能模型中的实体类别先验和实体需求度,确定与第一命名实体词汇对应的至少两个实体类别或者实体,分别对应的置信度。
其中,确定检索日志中包括的第一实体词汇的实体类别先验,第三确定模块55用于根据第一实体词汇的构词成分分类,及在检索日志中的所有关联特征的分类比例、对应的检索结果的分类比例,确定第一实体词汇的实体类别先验。
其中,确定检索日志中包括的第一实体词汇的实体用户需求度,第三确定模块55用于根据第一实体词汇的不同实体义项,在检索日志中所占的比例,确定第一实体词汇的实体用户需求度。
需要说明的是,前述对基于人工智能的命名实体识别方法实施例的解释说明也适用于该实施例的基于人工智能的命名实体识别装置,其实现原理类似,此处不再赘述。
本申请实施例的基于人工智能的命名实体识别装置,进一步通过判断第一命名实体词汇,是否对应至少两个实体类别或者实体,在是的情况下,根据待识别文本上下文特征,确定与第一命名实体词汇对应的至少两个实体类别或者实体,分别对应的置信度,以及判断待识别文本的上下文特征是否完整,在不完整的情况下,根据预设的实体词汇功能模型中的实体类别先验和实体需求度,确定与第一命名实体词汇对应的至少两个实体类别或者实体,分别对应的置信度。由此,在根据预设的实体词汇功能模型确定的识别结果又歧义时,通过根据命名实体对应的不同类的别先验及实体需求度,对识别结果进行进一步消歧,从而进一步提高了命名实体识别的准确性和准确率。
在本申请的描述中,需要理解的是,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本申请的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本申请的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本申请的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本申请的限制,本领域的普通技术人员在本申请的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!