一种海量数据的清洗方法和系统与流程
本发明涉及数据处理技术领域,尤其涉及一种海量数据的清洗方法和系统。
背景技术:
随着计算机技术的飞速发展及企业业务量的增长,企业的用户数据越来越多,不可避免的,数据的错误率也相应增多,在对数据做统计分析之前,需要将这些错误数据清洗掉,以确保统计的准确性。现有数据清洗任务指的是过滤或修改不符合要求的数据,这些不符合要求的数据主要包括:不完整数据、错误数据和重复数据共三大类。其中,识别重复数据是数据清洗的核心,重复数据是指,同一实体在数据集合中用多条不完全相同的记录来表示,由于它们在格式、拼写上的差异,导致数据库管理系统不能正确识别。
但是,现有的数据清洗方法在面对海量数据时表现出来的清洗性能较低、清洗速度较慢,直接使用现有的数据清洗方法,会制约海量数据清洗的速度和效率。
技术实现要素:
本发明的目的在于提供一种海量数据的清洗方法和系统,用于提高数据清洗的速度和效率。
为了实现上述目的,本发明提供如下技术方案:
一种海量数据的清洗方法,包括:
步骤S1:根据预设数据块个数N,将映射归约并行计算框架内映射函数的个数设置为N,将归约函数的个数设为1;
步骤S2:利用映射归约并行计算框架内N个映射函数将海量数据分成N个数据块,对每个数据块中的数据进行清洗,得到多个清洗的数据块;
步骤S3:利用归约函数整合多个清洗的数据块,得到整合数据;对整合数据进行清洗,完成海量数据的清洗。
与现有技术相比,本发明提供的海量数据的清洗方法具有如下有益效果:
本发明提供的海量数据的清洗方法,根据预设数据块个数N,将映射归约并行计算框架内映射函数的个数设置为N,将归约函数的个数设为1,然后利用映射归约并行计算框架内N个映射函数将海量数据分成N个数据块,这样即可对每个数据块中的数据同时进行清洗,实现整个清洗过程的并行化,从而提高海量数据清洗的速度和效率,然后,利用归约函数将多个清洗后的数据块进行整合,得到整合数据,通过最终对整合数据的清洗,即可完成海量数据的清洗;因此,本发明提供的海量数据的清洗方法能够避免直接在清洗范围较大的海量信息数据库中对数据执行清洗操作,极大的提升了海量数据的清洗速度和效率;并且,因为本发明实施例利用映射归约并行计算框架内N个映射函数将海量数据分成N个数据块,所以在向海量数据中增加新的数据时,对原来已经清洗过的数据就不用再次进行清洗,仅需令新增加的数据组成一个新的数据块对其进行清洗即可,也就是说,本发明实施例能够实现清洗过程的增量化,保证清洗过程在实际应用过程中的连续性,进一步提升了海量数据的清洗速度和效率。
本发明提供一种海量数据的清洗系统,包括:
映射归约并行计算单元和清洗单元;所述映射归约并行计算单元包括分块单元和整合单元;所述清洗单元包括第一清洗单元和第二清洗单元;所述分块单元的输出端与第一清洗单元的输入端相连,所述第一清洗单元的输出端与整合单元的输入端相连,所述整合单元的输出端与第二清洗单元的输入端相连;
所述分块单元用于根据预设数据块个数N,将映射归约并行计算框架内映射函数的个数设置为N,将归约函数的个数设为1,以及利用映射归约并行计算框架内N个映射函数将海量数据分成N个数据块;
所述第一清洗单元用于对每个数据块中的数据进行清洗,得到多个清洗的数据块;
所述整合单元用于利用归约函数整合多个清洗的数据块,得到整合数据;
所述第二清洗单元用于对整合数据进行清洗,完成海量数据的清洗。
与现有技术相比,本发明提供的海量数据的清洗系统的有益效果与上述技术方案提供的海量数据的清洗方法的有益效果相同,在此不做赘述。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明实施例一提供的海量数据的清洗方法的流程图一;
图2为本发明实施例一提供的海量数据的清洗方法的流程图二;
图3为本发明实施例一提供的海量数据的清洗方法的流程图三;
图4为本发明实施例一提供的海量数据的清洗方法的流程图四;
图5为本发明实施例二提供的海量数据的清洗系统的结构示意图一;
图6为本发明实施例二提供的海量数据的清洗系统的结构示意图二;
图7为本发明实施例二提供的海量数据的清洗系统的结构示意图三;
图8为本发明实施例二提供的海量数据的清洗系统的结构示意图四。
附图标记:
1-映射归约并行计算单元, 2-清洗单元;
11-分块单元, 12-整合单元;
21-第一清洗单元, 22-第二清洗单元;
211-实体名称识别单元, 212-清洗执行单元;
2121-预处理单元, 2122-相似度计算单元;
2123-判断单元, 2124-第一标记单元;
221-合并单元, 222-第二标记单元。
具体实施方式
为了进一步说明本发明实施例提供的海量数据的清洗方法和系统,下面结合说明书附图进行详细描述。
实施例一
请参阅图1,本实施例提供一种海量数据的清洗方法,包括:
步骤S1:根据预设数据块个数N,将映射归约并行计算框架内映射函数的个数设置为N,将归约函数的个数设为1;
步骤S2:利用映射归约并行计算框架内N个映射函数将海量数据分成N个数据块,对每个数据块中的数据进行清洗,得到多个清洗的数据块;
步骤S3:利用归约函数整合多个清洗的数据块,得到整合数据;对整合数据进行清洗,完成海量数据的清洗。
通过上述海量数据的清洗方法可知,本实施例提供的海量数据的清洗方法,根据预设数据块个数N,将映射归约并行计算框架内映射函数的个数设置为N,将归约函数的个数设为1,然后利用映射归约并行计算框架内N个映射函数将海量数据分成N个数据块,这样即可对每个数据块中的数据同时进行清洗,实现整个清洗过程的并行化,从而提高海量数据清洗的速度和效率,然后,利用归约函数将多个清洗后的数据块进行整合,得到整合数据,通过最终对整合数据的清洗,即可完成海量数据的清洗;因此,本实施例提供的海量数据的清洗方法能够避免直接在清洗范围较大的海量信息数据库中对数据执行清洗操作,极大的提升了海量数据的清洗速度和效率;并且,因为本实施例利用映射归约并行计算框架内N个映射函数将海量数据分成N个数据块,所以在向海量数据中增加新的数据时,对原来已经清洗过的数据就不用再次进行清洗,仅需令新增加的数据组成一个新的数据块对其进行清洗即可,也就是说,本发明实施例能够实现清洗过程的增量化,保证清洗过程在实际应用过程中的连续性,进一步提升了海量数据的清洗速度和效率。
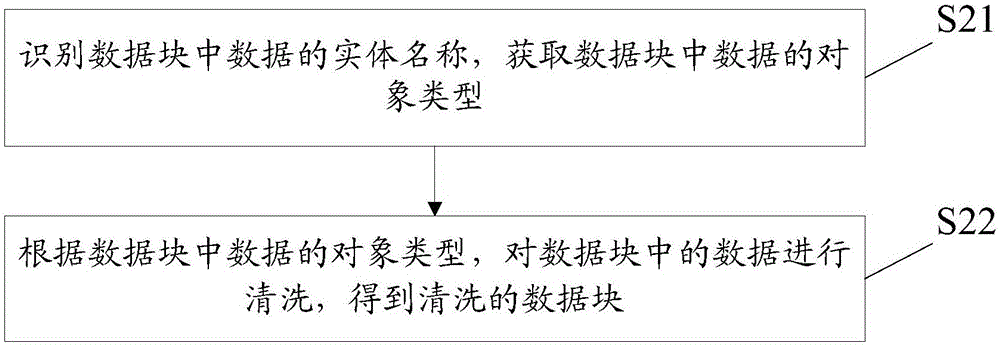
具体的,如图2所示,上述实施例的步骤S2中对每个数据块中的数据进行清洗,得到多个清洗的数据块的方法包括:
步骤S21:识别数据块中数据的实体名称,获取数据块中数据的对象类型;
步骤S22:根据数据块中数据的对象类型,对数据块中的数据进行清洗,得到清洗的数据块。
需要说明的是,上述步骤S21中识别数据块中数据的实体名称是通过对数据块中数据字段的解析来实现的,进一步地,本实施例通过对数据块中数据字段的解析,获取数据块中数据的对象类型,然后根据数据的对象类型,自动触发与数据块中数据的对象类型相对应的数据清洗模型对数据块中的数据进行清洗,得到清洗的数据块,即本发明实施例通过建立一个包含结构化、半结构化和非结构化的统一海量数据清洗模型,这样在获取数据块中数据的不同对象类型后,即可根据数据的对象类型,自动触发包含结构化、半结构化和非结构化的统一海量数据清洗模型中,与数据块中数据的对象类型相对应的数据清洗模型进行清洗,以实现统一清洗结构化、半结构化和非结构化的海量数据的效果。
可以理解的是,上述实体名称包括:时间、姓名、组织机构名、地名中的一种或多种,相应的,数据清洗模型包括:时间类、字符串类数据清洗模型、姓名清洗模型、组织机构名清洗模型、地名清洗模型中的一种或多种。
需要说明的是,对于姓名清洗模型、地名清洗模型和组织机构名清洗模型,上述实施例可以利用条件随机场算法(Conditional Random Fields,以下简称CRFS)对数据块中数据的对象类型(姓名、地名和组织机构名)进行识别,并触发相应的清洗模型(姓名清洗模型、地名清洗模型和组织机构名清洗模型)完成数据清洗。
需要注意的是,基于CRFS的命名实体识别可用的特征很多,特征选取的优劣直接影响系统的性能。在本实施例中,姓名清洗模型、地名清洗模型和组织机构名清洗模型分别使用以下特征:相同字段名、时间信息、来源是否为同一文件。
另外,对于时间类、字符串类数据清洗模型,本实施例建立包括阿拉伯数字半角、全角符号、数字大写符号、英文字母大小写的全角以及半角符号、特殊量度单位符号(如@、吨、克)等的专家知识库集合,通过配置有限状态自动机实现对不同来源的数字和字符串记录进行规范化表达。
具体清洗时,如图3所示,步骤S22中对数据块中的数据进行清洗,得到清洗的数据块的方法包括:步骤S221:将数据块中的数据进行预处理,使数据块中的数据格式统一;步骤S222:计算实体名称相同的数据的内容相似度。
示例性的,计算实体名称相同的数据的内容前,还包括:按照预设实体关键字对数据块中的数据进行排序,这样即可在进行相似度计算之前尽可能的将潜在的可能的重复数据调整到相邻的位置区域内,从而提高后续的相似度计算速度,节省了在数据量较大的数据块中去查找相同实体名称数据的时间。
其中,预设实体关键字可以根据实际情况进行选取,具体可以通过对数据包含的实体名称赋予不同的权重来表示,将权重大的作为当前排序的预设实体关键字,这是考虑到数据中不同实体名称对反映数据特征的贡献是不同的,因此在衡量两条数据的相似度时,不同的实体名称应赋予不同的权重,通过所赋予的权重表明一个实体在决定两条数据相似性中的重要程度,重要程度大的,分配的权重就大。例如:在进行客户资料的数据清洗中,通过识别数据块中数据的实体名称,可以得到如姓名、地址、邮箱等对象类型,而因为此时姓名要比地址和邮箱更能反映该条数据的特征,因此,就可以考虑给姓名赋予的权重为0.5,地址赋予的权重为0.3,邮箱赋予的权重为0.2,在这里对于不同实体名称的权重,可以根据实际情况由用户提供,在重复数据的清洗过程中,可以对权重进行调整,以便找出更多的重复数据。
在计算出相似度后,进入步骤S223:判断相似度值是否大于预设阈值,当相似度值大于预设阈值时,标记实体名称相同的数据为重复数据,并给相应数据打上重复数据标签,得到清洗的数据块。
映射阶段的清洗完毕后,如图1所示,进入步骤S3:利用归约函数整合多个清洗的数据块,得到整合数据,然后对整合数据进行清洗,完成海量数据的清洗,具体的,如图4所示,步骤S3中对整合数据进行清洗,完成海量数据的清洗的方法包括:
步骤S31:合并多个清洗的数据块中具有重复数据标签的数据,得到合并数据;这样就能够保留重复数据中最完整的那条数据而删除其他的数据,使得数据库中每条数据都表示不同的实体名称,进而得到准确的数据。
步骤S32:将合并数据打上清洗标记,这样可以使得用户在后续对数据进行检索分析时,能够清楚的区分合并数据与原始数据,并对合并次数较多的数据,也就是容易出现重复的数据提高注意,从而在后续的数据收集和录入时尽量避免重复数据的出现;将合并数据打上清洗标记后,将清洗后的数据放入目标数据库,结束清洗。
需要说明的是,本实施例步骤S223中的在判断出相似度值大于预设阈值时,标记实体名称相同的数据为重复数据,与步骤S32中将合并数据打上清洗标记的作用不同,因为步骤S223中将实体名称相同的数据标记为重复数据,所以在进入步骤S31时,可以直接将具有重复数据标签的数据进行合并以完成清洗,而步骤S32中的将合并数据打上清洗标记是在清洗完成之后进行的。
实施例二
请参阅图1和图5,本实施例提供的海量数据的清洗系统,包括:映射归约并行计算单元1和清洗单元2;映射归约并行计算单元1包括分块单元11和整合单元12;清洗单元2包括第一清洗单元21和第二清洗单元22;分块单元11的输出端与第一清洗单元21的输入端相连,第一清洗单元21的输出端与整合单元12的输入端相连,整合单元12的输出端与第二清洗单元22的输入端相连;
分块单元11用于根据预设数据块个数N,将映射归约并行计算框架内映射函数的个数设置为N,将归约函数的个数设为1,以及利用映射归约并行计算框架内N个映射函数将海量数据分成N个数据块;
第一清洗单元21用于对每个数据块中的数据进行清洗,得到多个清洗的数据块;
整合单元12用于利用归约函数整合多个清洗的数据块,得到整合数据;
第二清洗单元22用于对整合数据进行清洗,完成海量数据的清洗。
具体实施时,下面结合图1对本发明实施例提供的海量数据的清洗系统完成海量数据清洗的过程进行详细说明。
步骤S1:分块单元11根据预设数据块个数N,将映射归约并行计算框架内映射函数的个数设置为N,将归约函数的个数设为1;
步骤S2:利用映射归约并行计算框架内N个映射函数将海量数据分成N个数据块;然后利用第一清洗单元21对每个数据块中的数据进行清洗,得到多个清洗的数据块;
步骤S3:通过整合单元12利用归约函数整合多个清洗的数据块,得到整合数据,然后利用第二清洗单元22对整合数据晶型清洗,完成海量数据的清洗。
与现有技术相比,本实施例提供的海量数据的清洗系统与上述实施例一提供的海量数据的清洗方法的有益效果相同,在此不做赘述。
需要说明的是,分块单元11和整合单元12属于映射归约并行计算单元1的一部分。
具体的,如图6所示,本实施例中第一清洗单元21具体包括:实体名称识别单元211和清洗执行单元212;分块单元11的输出端与实体名称识别单元211的输入端相连,实体名称识别单元211的输出端与清洗执行单元212的输入端相连,清洗执行单元212的输出端与整合单元12的输入端相连;
实体名称识别单元211用于识别数据块中数据的实体名称,获取数据块中数据的对象类型;例如:利用实体名称识别单元211对数据块中数据字段进行解析,以识别数据块中数据的实体名称。
清洗执行单元212用于根据数据块中数据的对象类型,对数据块中的数据进行清洗,得到清洗的数据块。
可选的,本发明实施例提供的海量数据的清洗系统,能够根据数据的对象类型,自动触发与数据块中数据的对象类型相对应的数据清洗模型,然后利用清洗执行单元212对数据块中的数据进行清洗,得到清洗的数据块;具体如何触发与数据块中数据的对象类型相对应的数据清洗模型,可以参阅上述实施例一中相关部分的描述。
具体的,请参阅图7,本实施例中的清洗执行单元212包括:预处理单元2121、相似度计算单元2122、判断单元2123和第一标记单元2124;实体名称识别单元211的输出端与预处理单元2121的输入端相连,预处理单元2121的输出端与相似度计算单元2122的输入端相连,相似度计算单元2122的输出端与判断单元2123的输入端相连,判断单元2123的输出端与第一标记单元2124的输入端相连,第一标记单元2124的输出端与整合单元12的输入端相连。
在具体实施时,利用预处理单元2121对数据块中的数据进行预处理,使数据块中的数据格式统一;利用相似度计算单元2122计算实体名称相同的数据的内容相似度;利用判断单元2123判断相似度值是否大于预设阈值;在判断出相似度值大于预设阈值时,利用第一标记单元2124标记相同实体数据为重复数据,并给相应数据打上重复数据标签,得到清洗的数据块。
并且,如图8所示,本实施例提供的第二清洗单元22包括合并单元221和第二标记单元222;整合单元12的输出端与合并单元221的输入端相连,合并单元221的输出端与第二标记单元222的输入端相连;
具体实施时,利用合并单元221合并多个清洗的数据块中具有重复数据标签的数据,得到合并数据;这样就能够保留重复数据中最完整的那条数据而删除其他的数据,使得数据库中每条数据都表示不同的实体,进而得到准确的数据,然后利用第二标记单元222将合并数据打上清洗标记,结束清洗。
需要说明的是,本实施例中的第一标记单元2124在判断出相似度值大于预设阈值时,标记实体名称相同的数据为重复数据,与第二标记单元222将合并数据打上清洗标记的作用是不同的,因为第一标记单元2124将实体名称相同的数据标记为重复数据,所以在进入步骤S31时,可以直接利用合并单元221将具有重复数据标签的数据进行合并以完成清洗,而第二标记单元222是用于在步骤S32中将合并数据打上清洗标记,是在清洗完成之后进行的。
在上述实施方式的描述中,具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!