用于构建产品画像的方法和装置与流程
本公开涉及计算机领域,具体地,涉及一种用于构建产品画像的方法和装置。
背景技术:
产品画像是一种对产品的定位,可以包括产品自身属性的画像和产品用户的群体画像。通过产品画像,可以在产品推广时,分析产品的用户群体的特征数据,挖掘潜在客户群体,进行有针对性的产品改进,达到企业的长期稳定高速发展的需求。
目前常用的用于构建产品画像的方法包括简单过滤法和人工评分法。
在简单过滤法中,如果用户有一个条件不符合,很就被过滤掉。例如,在招聘行业,通常通过输入用户的属性来过滤用户。比如公司招聘条件为:专业为软件,学历为硕士,工作经验大于五年,并且简历的关键字包括大数据。这样过滤出来的用户群体范围小,很多用户只有其中一条规则不符合(例如,学历为本科)。对于这种简历,通过简单过滤法就完全被过滤掉了。
在人工评分的方法中,对用户的各个维度进行人工打分,比如地域、年龄、关键字、兴趣等各维度来打分。这种方法凭人工经验打分,构建的产品画像往往不准确。
技术实现要素:
本公开的目的是提供一种简单易行的用于构建产品画像的方法和装置。
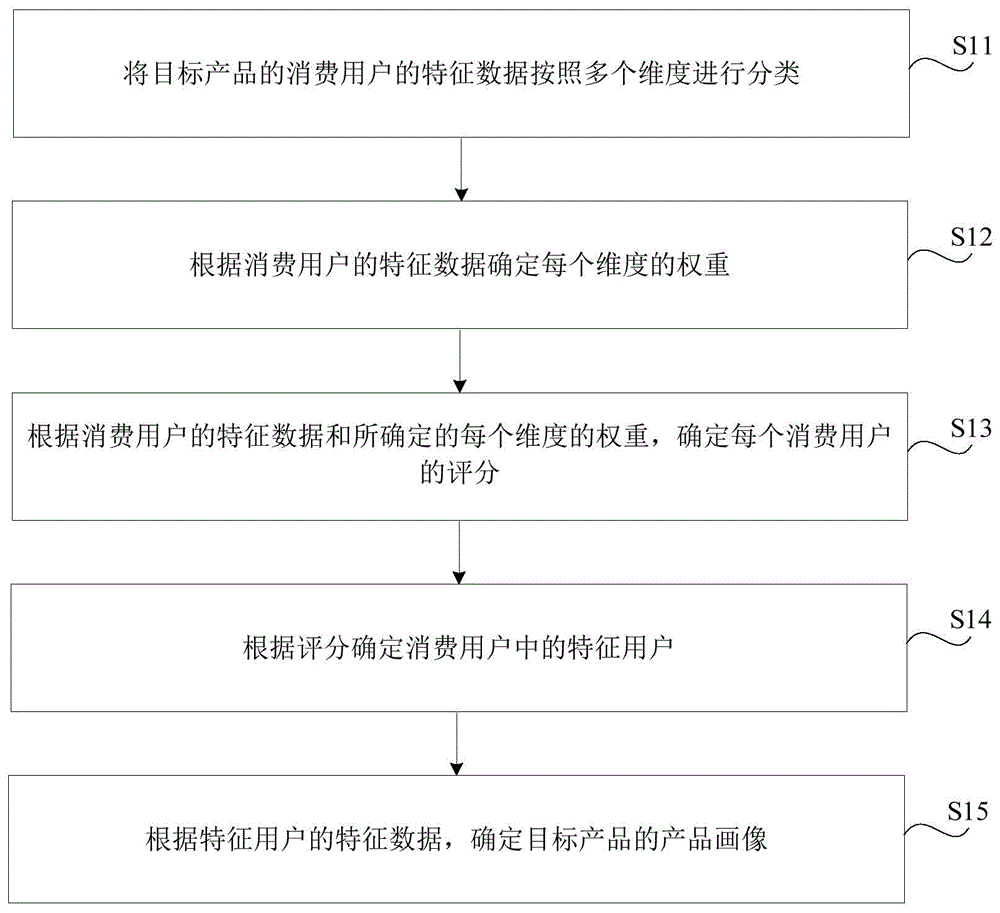
为了实现上述目的,本公开提供一种用于构建产品画像的方法。所述方法包括:将目标产品的消费用户的特征数据按照多个维度进行分类;根据所述消费用户的特征数据确定每个维度的权重;根据所述消费用户的特征数据和所确定的每个维度的权重,确定每个消费用户的评分;根据所述评分确定所述消费用户中的特征用户;根据所述特征用户的特征数据,确定所述目标产品的产品画像。
可选地,所述根据所述消费用户的特征数据确定每个维度的权重的步骤包括:分别计算其特征数据中包括与每个维度对应的特征数据的消费用户的数目与所述消费用户的总数目的比值,得到对应维度的数据频率;分别计算整体用户的总数目与其特征数据中包括与每个维度对应的特征数据的整体用户的数目的比值的对数,得到对应维度的逆向频率,其中,所述整体用户包括所述消费用户和非消费用户;分别将每个维度的数据频率乘以逆向频率,得到对应维度的权重。
可选地,所述根据所述消费用户的特征数据确定每个维度的权重的步骤包括:周期性地根据所述消费用户的特征数据确定每个维度在当前周期内的区间权重;根据每个维度的历史区间权重和当前区间权重,确定每个维度的权重。
可选地,所述根据所述消费用户的特征数据和所确定的每个维度的权重,确定每个消费用户的评分的步骤包括:根据所述消费用户的特征数据确定每个特征数据的权重;根据每个特征数据的权重和所确定的每个维度的权重,确定每个消费用户的评分。
可选地,所述根据所述消费用户的特征数据确定每个特征数据的权重的步骤包括:计算其特征数据中包括第一特征数据的消费用户的数目与所述消费用户的总数目的比值,得到所述第一特征数据的数据频率;计算整体用户的总数目与其特征数据中包括所述第一特征数据的整体用户的数目的比值的对数,得到所述第一特征数据的逆向频率,其中,所述整体用户包括所述消费用户和非消费用户;将所述第一特征数据的数据频率乘以所述第一特征数据的逆向频率,得到所述第一特征数据的权重。
可选地,在所述将目标产品的消费用户的特征数据按照多个维度进行分类的步骤之前,所述方法还包括:确定与所述目标产品相似的相似产品;将所述相似产品的消费用户确定为所述目标产品的消费用户。
本公开还提供一种用于构建产品画像的装置。所述装置包括:分类模块,用于将目标产品的消费用户的特征数据按照多个维度进行分类;权重确定模块,用于根据所述消费用户的特征数据确定每个维度的权重;评分确定模块,用于根据所述消费用户的特征数据和所确定的每个维度的权重,确定每个消费用户的评分;特征用户确定模块,用于根据所述评分确定所述消费用户中的特征用户;产品画像确定模块,用于根据所述特征用户的特征数据,确定所述目标产品的产品画像。
通过上述技术方案,基于消费用户自身的特征数据来确定每个维度的权重,使得维度的权重更准确地体现了消费用户的特征。因此,本公开在综合考虑用户特征数据的各个维度的权重的基础上,构建出更加准确的产品画像,有利于对消费用户的准确定位和产品的改进,增大产品效益。
本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本公开的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本公开,但并不构成对本公开的限制。在附图中:
图1是一示例性实施例提供的用于构建产品画像的方法的流程图;
图2是一示例性实施例提供的确定每个维度的权重的流程图;
图3是另一示例性实施例提供的确定每个维度的权重的流程图;
图4是另一示例性实施例提供的用于构建产品画像的方法的流程图;
图5是一示例性实施例提供的用于构建产品画像的装置的框图。
具体实施方式
以下结合附图对本公开的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本公开,并不用于限制本公开。
如上所述,使用简单的过滤方法时,用户的特征数据中即使只有其中一条不符合预设规则,也被完全被过滤掉了。但实际上,对于其中一条不符合,但是其他方面特别突出的简历,很多公司也是愿意考虑的。鉴于上述问题,发明人想到,在构建产品画像时,可以从消费用户自身的特征数据出发,来确定特征数据所分成的各个维度的权重,从而使根据权重确定的特征用户更准确,最终使产品画像更准确。
图1是一示例性实施例提供的用于构建产品画像的方法的流程图。如图1所示,所述方法可以包括以下步骤。
在步骤S11中,将目标产品的消费用户的特征数据按照多个维度进行分类。
其中,消费用户可以是已经对目标产品进行消费(例如,已购买目标产品)的用户。消费用户的特征数据可以包括多个维度(或种类)的特征数据。例如,可以包括用于描述人口属性、行为、兴趣爱好、业务等方面的:年龄、性别、职业、地域、收藏、点赞等维度。
在步骤S12中,根据消费用户的特征数据确定每个维度的权重。
在一消费用户的特征数据中,并不一定是在每个维度上都有的。某一维度的特征数据在消费用户中出现得越多,表明该维度对于特征用户的描述越重要,该维度的权值就越高。
简单地,可以分别计算其特征数据中包括与每个维度对应的特征数据的消费用户的数目与消费用户的总数目的比值,得到对应维度的权重。例如,消费用户的总数目为100,其特征数据中包括男或女(与性别维度对应的特征数据)的消费用户的数目为20,则性别维度的权重为0.2(20/100)。
在步骤S13中,根据消费用户的特征数据和所确定的每个维度的权重,确定每个消费用户的评分。
简单地,可以将每个维度所包括的各个特征数据赋予预定的值,该预定的值例如可以由用户根据自身意愿的倾向性来设定,也可以根据实验或经验来设定。在对一消费用户进行评分的时候,可以将该消费用户在各个维度上的特征数据的值进行加权(所在维度的权重)求和,得到该消费用户的评分。该评分体现了消费用户的特征与目标产品的关联程度。
在步骤S14中,根据评分确定消费用户中的特征用户。
如上所述,消费用户可以是已经对目标产品进行消费的用户。消费用户中,可以包括特征用户和其他用户。其中,特征用户可以是其特征与目标产品高度关联的用户,或者说,是目标产品的易消费人群。而特征用户之外的其他用户可以是与目标产品关联度不太高的用户,或者说,是目标产品的偶然消费群体。该群体只是由于偶然原因消费了目标产品,因此,在进行产品画像时,可以将其排除。也就是,本公开中,从消费用户中筛选出易消费人群,然后通过对该目标产品的易消费人群进行特征数据的分析,得到目标产品的产品画像。
例如,评分越高则表示该消费用户越容易消费该目标产品,可以将评分高于预定的评分阈值的消费用户确定为特征用户。
在步骤S15中,根据特征用户的特征数据,确定目标产品的产品画像。
确定特征用户后,可以采用多种方法对特征用户的特征数据进行分析。简单地,可以采用统计占比的方法。也就是,在每个维度上,其特征数据中包括某一特征数据的消费用户数目与其特征数据中包括该维度上任一特征数据的消费用户的数目的占比超过预定阈值或超过其他特征数据的占比,就可以将该特征数据作为产品画像的一部分。
例如,在全部100个消费用户中,有80个消费用户包括年龄维度的数据特征。其中,其特征数据中包括20-30岁数据特征的消费用户有50人,其特征数据中包括30-40岁数据特征的消费用户有20人,其特征数据中包括40-50岁数据特征的消费用户有10人。则其特征数据中包括20-30岁数据特征的消费用户与其特征数据中包括年龄维度中的任一数据特征的消费用户的数目的占比(50/80),大于30-40岁对应的占比(20/80),并大于40-50岁对应的占比(10/80),则可以将20-30岁的数据特征作为产品画像的一部分。
通过上述技术方案,基于消费用户自身的特征数据来确定每个维度的权重,使得维度的权重更准确地体现了消费用户的特征。因此,本公开在综合考虑用户特征数据的各个维度的权重的基础上,构建出更加准确的产品画像,有利于对消费用户的准确定位和产品的改进,增大产品效益。
词频-逆向文件频率(Term Frequency-Inverse Document Frequency,TF-IDF)算法,是一种可以用于信息检索与数据挖掘的加权技术。本公开的一实施例中,可以应用该算法的构思来确定每个维度的权重。
具体地,图2是一示例性实施例提供的确定每个维度的权重的流程图。如图2所示,根据消费用户的特征数据确定每个维度的权重的步骤(步骤S12)可以包括以下步骤。
在步骤S121中,分别计算其特征数据中包括与每个维度对应的特征数据的消费用户的数目与消费用户的总数目的比值,得到对应维度的数据频率。
其中,与每个维度对应的特征数据也就是这个维度上的数据值,与每个维度对应的特征数据可以包括多个特征数据。例如,与性别维度对应的特征数据可以包括男和女,与年龄维度对应的特征数据可以包括20-30岁、30-40岁和40-50岁。
在一消费用户的特征数据中,并不一定是在每个维度上都有的。某一维度的特征数据在消费用户中出现得越多,表明该维度对于特征用户的描述越重要,该维度的权值就越高。
例如,消费用户的总数目为100,其特征数据中包括与性别维度对应的特征数据(男或女)的消费用户的数目为20,则性别维度的数据频率为0.2(20/100)。
在步骤S122中,分别计算整体用户的总数目与其特征数据中包括每个维度对应的特征数据的整体用户的数目的比值的对数(例如,以十为底),得到对应维度的逆向频率。
其中,整体用户可以包括消费用户和非消费用户(未消费过目标产品的用户)。可以理解的是,其特征数据中包括与一维度对应的特征数据的整体用户的数目越多,则该维度的区别度越低,对应的权值就越低。
例如,整体用户的总数目为10,000,000,其特征数据中包括与性别维度对应的特征数据(男或女)的整体用户的数目为10,000,则性别维度的逆向频率为
在步骤S123中,分别将每个维度的数据频率乘以逆向频率,得到对应维度的权重。
本公开中,数据频率和逆向频率分别相当于词频-逆向文件频率算法中的词频和逆向文件频率。按照该算法的构思,各个维度的权重可以为该维度的数据频率乘以逆向频率。在上述示例的基础上,性别维度的权重可以为0.2×3=0.6。
至此,对于每个维度,都可以计算出其对应的权重。该实施例中,根据词频-逆向文件频率算法计算出各个维度的权重,准确地体现了各个维度对于特征用户的重要性,简单易行,可用性好。
随着时间的推移,数据量的大量累积,可能会对结果的准确性造成影响。并且,特定的时间段很可能对一些用户的特征数据和目标产品之间的关联性有较大影响。例如,在欧洲杯足球赛期间,出现大量伪球迷,消费了大量足球产品。而比赛过后,这些伪球迷对于之前消费过的足球产品的兴趣会极大地减弱,甚至消失。鉴于此,在本公开的又一实施例中,可以考虑各维度上权重的历史演变,来确定其权重。
图3是另一示例性实施例提供的确定每个维度的权重的流程图。如图3所示,根据消费用户的特征数据确定每个维度的权重的步骤(步骤S12)可以包括以下步骤。
在步骤S124中,周期性地根据消费用户的特征数据确定每个维度在当前周期内的区间权重。
也就是,可以根据每个周期(例如,一个月)内的消费用户,确定出各个维度在该周期内的权重,即区间权重。区间权重由周期内的数据获得,体现了特定周期内该维度与目标产品的关联程度。
在步骤S125中,根据每个维度的历史区间权重和当前区间权重,确定每个维度的权重。
在确定一维度的区间权重后,可以据此得出该维度的权重,应用于之后的步骤。考虑到在通常情况下,时间越近的数据更能体现当前发展的趋势,例如可以对历史区间权重和当前区间权重分别赋予预定的较小和较大的权重,将历史区间权重和当前区间权重二者加权求和得到该维度的权重。
举例来说,由最近的一个月的特征数据可得到,性别维度对应的区间权重为0.6(当前区间权重)。而根据一个月之前的特征数据可得到,性别维度的权重为0.4(历史区间权重)。可以对当前区间权重和历史区间权重分别赋予预定的0.8和0.2的权重,则性别维度的权重可以为0.6×0.8+0.4×0.2=0.56。
又如,由欧洲杯足球赛的一个月期间的特征数据可得到,性别维度对应的区间权重为0.6(当前区间权重)。而根据一个月之前的特征数据可得到,性别维度的权重为0.9(历史区间权重)。考虑到在足球比赛期间,由于宣传力度强,跟风现象严重,涌现出大量伪球迷。所以,当前区间权重的权重可以设置为较小,历史区间权重的权重可以设置为较大。例如,可以对当前区间权重和历史区间权重分别赋予预定的0.1和0.9的权重,则性别维度的权重可以为0.6×0.1+0.9×0.9=0.87。
该实施例中,考虑了维度权重的历史演变,以增量的方式来确定维度的权重,使得所确定的维度的权重更符合当前实际情况,从而使产品画像更加准确。
如前所述,用于给消费用户打分的每个特征数据的值(以下也叫特征数据的权重),可以是根据经验或试验确定的。特征数据的权重也可以根据用户的特征数据自身来确定。在本公开的一实施例中,根据消费用户的特征数据和所确定的每个维度的权重,确定每个消费用户的评分的步骤(步骤S13)可以包括步骤S131和步骤S132。
在步骤S131中,根据所述消费用户的特征数据确定每个特征数据的权重。
该步骤可以根据词频-逆向文件频率算法的构思来实施,具体地,可以按照以下步骤实施。
(1)计算其特征数据中包括第一特征数据的消费用户的数目与消费用户的总数目的比值,得到第一特征数据的数据频率。
其中,第一特征数据可以为消费用户的任一特征数据。某一特征数据在消费用户中出现得越多,表明该特征数据对于特征用户的描述越重要,该特征数据的权值就越高。
例如,消费用户的总数目为100,特征数据中包括男性的消费用户的数目为80,则男性特征数据的数据频率为0.8(80/100)。
(2)计算整体用户的总数目与特征数据中包括第一特征数据的整体用户的数目的比值的对数,得到第一特征数据的逆向频率。其中,整体用户包括消费用户和非消费用户。
可以理解的是,特征数据中包括第一特征数据的整体用户的数目越多,则该特征数据的区别度越低,对应的权值就越低。
例如,整体用户的总数目为10,000,000,特征数据中包括男性的整体用户的数目为10,000,则逆向频率为
(3)将第一特征数据的数据频率乘以第一特征数据的逆向频率,得到第一特征数据的权重。
如上所述,根据词频-逆向文件频率算法的构思,各个特征数据的权重为该特征数据的数据频率乘以逆向频率。在上述示例的基础上,男性特征数据的权重可以为0.8×3=2.4。
此处,特征数据的权重相当于图1所示的实施例中所述的特征数据的值,与图1的实施例相比,该实施例中,根据特征数据自身和词频-逆向文件频率算法确定出特征数据的权重(即特征数据的值),准确地体现了特征用户的特征,简单易行,可用性好。
在步骤S132中,根据每个特征数据的权重和所确定的每个维度的权重,确定每个消费用户的评分。
具体地,可以将一消费用户在各个维度上的特征数据的权重进行加权(维度的权重)求和,得到该消费用户的评分。该评分体现了消费用户的特征与目标产品的关联程度。
与上述图3中的实施例相似地,对于特征数据的权重,也可以周期性地确定出特征数据的区间权重,考虑权重的历史演变,以增量的方式来确定特征数据的权重,使得所确定的特征数据的权重更符合当前实际情况,从而使产品画像更加准确。该实施例将不再赘述。
在实际当中,每个产品都是从新上市开始的。考虑到在最初的时候,目标产品还没有消费用户或消费用户的数据量较少,此时可以找到与其相似的相似产品,来模仿新产品的消费用户,进一步得到新产品的产品画像。
图4是另一示例性实施例提供的用于构建产品画像的方法的流程图。如图4所示,在图1的基础上,在将目标产品的消费用户的特征数据按照多个维度进行分类的步骤(步骤11)之前,所述方法还可以包括以下步骤。
在步骤S110中,确定与目标产品相似的相似产品。
可以根据经验来寻找相似产品,或者可以应用一些算法来确定相似产品。在一实施例中,该步骤S110可以包括以下步骤:
根据杰卡德系数算法和皮尔森相似度算法中的任意一者或多者,确定目标产品和其他产品的相似度;根据所确定的相似度确定与目标产品相似的相似产品。
例如,在根据皮尔森相似度算法的实施例中,可以应用以下公式计算相似度:
其中,r表示目标产品和另一产品的相似度,X和Y分别表示目标产品和另一产品的第i维度的权重,n表示维度数目。其中,目标产品的维度的权重例如可以由经验获得。
又如,在根据杰卡德系数算法和皮尔森相似度算法的实施例中,可以先据杰卡德系数算法进行筛选,在筛选后得到的多个产品中,再利用皮尔森相似度算法得到相似度。
接下来,根据相似度确定与目标产品相似的相似产品后,可以将相似度大于预定的相似度阈值的产品确定为相似产品。
在步骤S111中,将相似产品的消费用户确定为目标产品的消费用户。
在该实施例中,能够在消费用户的数据量不足的情况下,通过相似产品预估得到目标产品的产品画像,从而解决了产品“冷启动”数据不足的问题。
图5是一示例性实施例提供的用于构建产品画像的装置的框图。如图5所示,所述用于构建产品画像的装置10可以包括分类模块11、权重确定模块12、评分确定模块13、特征用户确定模块14、产品画像确定模块15。
分类模块11用于将目标产品的消费用户的特征数据按照多个维度进行分类。
权重确定模块12用于根据所述消费用户的特征数据确定每个维度的权重。
评分确定模块13用于根据所述消费用户的特征数据和所确定的每个维度的权重,确定每个消费用户的评分。
特征用户确定模块14用于根据所述评分确定所述消费用户中的特征用户。
产品画像确定模块15用于根据所述特征用户的特征数据,确定所述目标产品的产品画像。
可选地,所述权重确定模块12可以包括第一数据频率计算子模块、第一逆向频率计算子模块和第一权重确定子模块。
第一数据频率计算子模块,用于分别计算其特征数据中包括与每个维度对应的特征数据的消费用户的数目与所述消费用户的总数目的比值,得到对应维度的数据频率。
第一逆向频率计算子模块,用于分别计算整体用户的总数目与其特征数据中包括与每个维度对应的特征数据的整体用户的数目的比值的对数,得到对应维度的逆向频率,其中,所述整体用户包括所述消费用户和非消费用户。
第一权重确定子模块,用于分别将每个维度的数据频率乘以逆向频率,得到对应维度的权重。
可选地,所述权重确定模块12可以包括区间权重确定子模块和第二权重确定子模块。
区间权重确定子模块用于周期性地根据所述消费用户的特征数据确定每个维度在当前周期内的区间权重。
第二权重确定子模块用于根据每个维度的历史区间权重和当前区间权重,确定每个维度的权重。
可选地,所述评分确定模块13可以包括数据权重确定子模块和评分确定子模块。
数据权重确定子模块用于根据所述消费用户的特征数据确定每个特征数据的权重。
评分确定子模块用于根据每个特征数据的权重和所确定的每个维度的权重,确定每个消费用户的评分。
可选地,所述数据权重确定子模块包括第二数据频率计算子模块、第二逆向频率计算子模块和第三权重确定子模块。
第二数据频率计算子模块用于计算其特征数据中包括第一特征数据的消费用户的数目与所述消费用户的总数目的比值,得到所述第一特征数据的数据频率。
第二逆向频率计算子模块用于计算整体用户的总数目与其特征数据中包括所述第一特征数据的整体用户的数目的比值的对数,得到所述第一特征数据的逆向频率,其中,所述整体用户包括所述消费用户和非消费用户。
第三权重确定子模块用于将所述第一特征数据的数据频率乘以所述第一特征数据的逆向频率,得到所述第一特征数据的权重。
可选地,所述装置10还可以包括相似产品确定模块和消费用户确定模块。
相似产品确定模块用于确定与所述目标产品相似的相似产品。
消费用户确定模块用于将所述相似产品的消费用户确定为所述目标产品的消费用户。
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
通过上述技术方案,基于消费用户自身的特征数据来确定每个维度的权重,使得维度的权重更准确地体现了消费用户的特征。因此,本公开在综合考虑用户特征数据的各个维度的权重的基础上,构建出更加准确的产品画像,有利于对消费用户的准确定位和产品的改进,增大产品效益。
以上结合附图详细描述了本公开的优选实施方式,但是,本公开并不限于上述实施方式中的具体细节,在本公开的技术构思范围内,可以对本公开的技术方案进行多种简单变型,这些简单变型均属于本公开的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合。为了避免不必要的重复,本公开对各种可能的组合方式不再另行说明。
此外,本公开的各种不同的实施方式之间也可以进行任意组合,只要其不违背本公开的思想,其同样应当视为本公开所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!