一种基于Spark平台支持空间数据管理的图计算系统及方法与流程
本发明涉及一种基于Spark平台支持空间数据管理的图计算系统及方法。
背景技术:
随着信息的普及,每时每刻都会有大量的包含位置属性的数据产生,而且这些数据已经逐渐成为我们数字化生活中必不可少的一部分。像这种依附着地理位置属性的数据被称为是空间数据,这些数据中隐藏着众多有价值的数据关系,而要展示数据中的关系,图是最直观最流行的工具。所以越来越多的研究人员开始关注空间数据的图计算和图分析的研究。由于现实生活中存在着众多像调查纽约大爆炸这样的场景需求,我们仅仅需要调查一个地区中局部区域的相关数据即可。对于大规模的局部空间数据的计算与分析,现有技术中已经有在Spark(大数据处理的快速通用引擎)的Graphx框架(图并行计算框架)的基础上提出了一个支持快速直接的区域子图构建与分析的框架SpatialGraphx。SpatialGraphx框架通过采用四叉树索引树和一种新型的图分区策略实现了区域子图的构建和子图分析的优化,该工作已在COMPSAC 2016会议上发表。
但是通过之后更深入的研究我们发现SpatialGraphx框架存在着下面两点比较重要的缺陷,正是这两点缺陷限制了它在处理空间图时的性能。
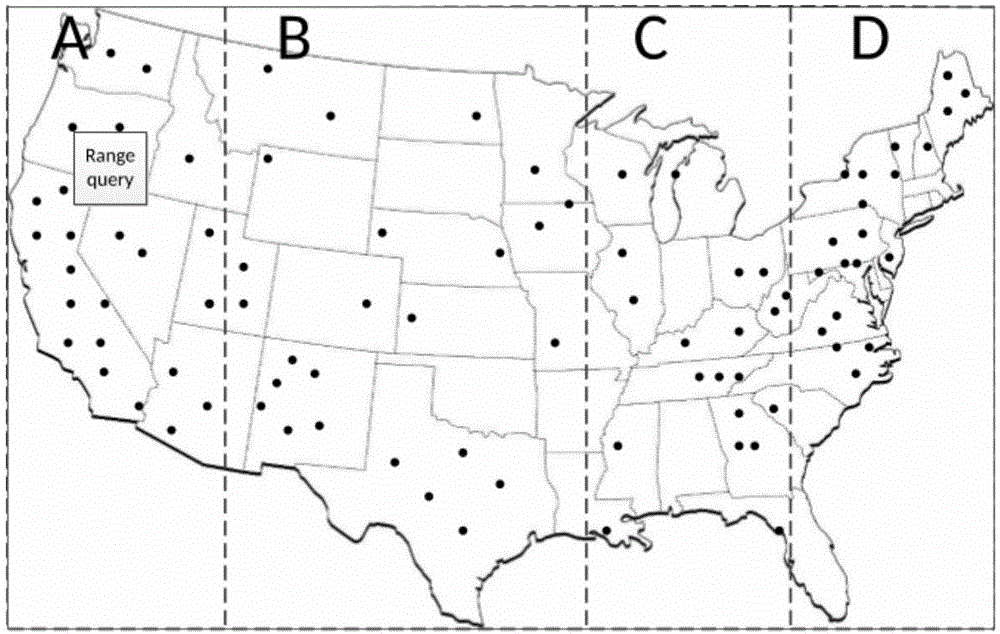
第一点:SpatialGraphx没有很好地考虑到在执行空间图查询时每个从节点维护的图的大小不同而造成的负载不平衡。这样的情况是由于在实际中由于不同地区的经济水平、交通发展等不同造成的不同地区的空间数据的产生量也不同,而SpatialGraphx对整体数据的分区是根据区域均匀划分的(如图1),每个区域内部的数据量大小不同,这就造成每台从节点维护的图的大小不同,而且当用户要查询图中所示左侧矩形部分的子图时,SpatialGraphx集群下只有从节点A是处于工作状态的,所以不管是在图的存储方面还是在图的查询操作方面都会给集群造成严重的负载不平衡,从而导致查询效率降低。
第二点:图的数据读入接口没有满足现实场景的需求,例如对于总体数据来说局部数据的分析以及两个空间数据集之间同一区域的交叉分析等。对应的现实场景如纽约大爆炸时间需要对于纽约市的整体相关数据进行范围的查询,然后对该范围内的数据进行分析;另外像IS恐怖分子在一个地区的袭击事件则需要使用不同时间内的数据对该区域进行交叉分析从而研究该地区的数据之间的连接关系。
在Spark集群中支持空间图操作相关的重要的组件包括Graphx和SparkSQL(Spark内部处理结构化数据的模块)。Graphx是用来进行大规模图计算与分析的图计算框架,对于图中的每个点以及每条边,Graphx是并行执行的。但实际的图中有的地方边比较稀疏有的地方边会比较密集,所以图中边的分布是不均匀的。对于网络数据而言,每次通信连接了两个顶点,相对距离较近的点之间通信会比较频繁,在集群中点被分配到不同的分区,所以两个点之间的距离在一定程度上决定了通信的代价。GraphX采用的是Hadoop的HDFS(Hadoop的弹性分布式文件系统)来存储数据,所有的数据都以RDD(弹性分布式数据集)的形式存储。Graphx提供了图上面的subgraph子图查询、map、reduceByKey等很多操作,这些操作都是针对一个完整的大图并且要遍历图中的每一条边、每一个点,所以对于局部图的操作都是在子图查询的基础上进行的,也就是说要想对一个大图的局部图进行相关操作都需要先遍历大图将需要的小图查询出来。
Graphx框架中对于图的分区有4中策略,GraphxLab 2.0提出并且证明点切割算法存储图的性能比边切割存储图要好,点切割能够最小化边之间的通信。Graphx的4中图分区策略采取的是点切割的方式,分别是RandomVertexCut、CanonicalRandomVertexCut、EdgePartition1D和EdgePartition2D。第一种计算源顶点和目的顶点的id进行哈希,将哈希后的值作为源顶点与目的顶点所连接的边的分区id,第二种忽略掉边的方向,采用id更小的顶点进行哈希,哈希结果作为边的分区id,第三种只考虑源顶点对边进行分区,第四种最为复杂,通过将源顶点id和目的顶点id建立连接矩阵,从而确定边的分区id。这些分区方式都是将边分区配不同的机器节点中,即便是彼此通信相对频繁的那些边也会被分到不同机器中,这样就会造成跨节点之间的边的通信代价比较高。
SparkSQL是Spark内部的结构化数据处理模型,它提供了DataFrame编程抽象,DataFrame在一定程度上和RDD类似,两者的不同之处在于DataFrame所表示的数据集是以列来组织的,而RDD是以行组织的。DataFrame的操作与SQL类似,包括“where”、“select”等。SparkSQl的查询操作也是需要遍历所有的DataFrame数据,与相关字段进行比较从而查询出想要的数据结果,这个过程也存在许多与无用数据的比较,影响了查询性能。SparkSQL在Apache Spark的顶端,它提供了一个数据框的API用以执行关系操作,以及简化Spark中的大规模数据处理。SparkSQL提供了为用户提供了一个语言层,用以交互式的sql查询操作。当运行查询,SparkSQL将SQL查询转化成RDD操作。然后SparkSQL运行RDD的文件查询。当数据是成规模时,这需要很长的时间。此外,SparkSQL并不支持空间数据类型和空间操作,所以当数据是空间数据时,它会像对待普通数据一样进行处理,并不会利用其空间属性。
技术实现要素:
本发明为了解决上述问题,提出了一种基于Spark平台支持空间数据管理的图计算系统及方法,本方法能够平衡集群对于图的存储负载和运行负载。
为了实现上述目的,本发明采用如下技术方案:
一种基于Spark平台支持空间数据管理的图计算系统,包括数据存储层、空间查询层和图计算层,其中:
所述数据存储层,接收空间数据,按照地理位置信息将其空间范围划分为多块矩形区域,将每个矩形内的数据分配到不同的分区,并将其划分为网格,对网格进行排序,并进行数据的空间映射,建立四叉树索引;
所述空间查询层,接收图计算层的图的查询请求,将其转换为数据查询,在该请求的图的范围内,在数据存储层的索引中进行查找,并将查询结果上传;
所述图计算层,发送空间操作请求,并接收反馈的查询结果,基于位置的图分区策略将查询结果中距离在设定范围内的边分配到同一分区中,实现局部图构建。
一种基于Spark平台支持空间数据管理的图计算方法,包括以下步骤:
(1)接收空间数据,按照地理位置信息将其空间范围划分为多块矩形区域,将每个矩形内的数据分配到不同的分区,并将其划分为网格,对网格进行排序,并进行数据的空间映射,建立四叉树索引;
(2)接收图的查询请求,将其转换为数据查询,在该请求的图的范围内,在数据存储层的索引中进行查找;
(3)根据反馈的查询结果,如果有多个图数据,进行多图的空间连接,基于位置的图分区策略将查询结果中距离在设定范围内的边分配到同一分区中,实现局部图构建。
所述步骤(1)中,对空间数据集按照地理位置信息将其空间范围划分为n块矩形区域,为n的大小由集群节点数确定,根据空间数据的密度进行调整区域的划分,保证每块区域内所包含的数据量尽量均匀。
所述步骤(1)中,根据数据集中的空间范围进行不均等矩形划分,矩形区域的大小随着数据量的变化而变化。
所述步骤(1)中,将每个矩形区域中的数据划分为n*n网格,使用Z-order Curve对网格进行排序,依次进行标注,将矩形区域中包含位置信息的二维空间数据映射到一维空间,将映射到一维空间后的数据保存到文件中,并同时用数组同步记录每一个网格中的数据在文件中的所属网格位置。
所述步骤(1)中,对每个网格内的数据建立四叉树索引,基于Voronoi图的密度切割方法对最底层叶子所维护的数据量进行均匀化平衡化。
所述步骤(2)中,接收图查询请求,并将其转化成点、线或多边形数据的数据类型,确定数据类型之间的关系。
所述步骤(2)中,集群中的master节点会将其转换为数据查询并发送给每一个slave节点,通过多边形的数据范围在每个slave节点的本地索引树中同步并行查找,直到找到叶子节点,在查找过程中将多边形范围内的数据点取出来即得出查询范围。
所述步骤(3)中,空间连接的步骤包括:
(3-1)计算RDD文件两个空间数据集中每条空间记录所属的网格id;
(3-2)用Li表示节点i中的计算负载,在图计算的初始时刻Li均为0;
(3-3)对于每一个网格计算位置处于其中的数据的数量,如果进行连接操作的两个分区的负载相同,则将量较小的数据集传送到量较大的数据集所在的分区中;
(3-4)在同一分区中对两个数据集进行连接。
所述步骤(3-3)中,如果进行连接操作的两个分区不同,则计算两个分区之间进行通信需要花费的时间并通过比较时间来决定如何传递两个分区中的数据集。
所述步骤(3)中,图分区策略,是将查询结果中距离在设定范围内的边分配到同一分区中。
本发明的有益效果为:
(1)本发明基于Spark系统,通过在内存中迭代计算实现高度分布式计算,从而可以对大规模的图进行计算与分析,提高计算速度;
(2)本发明通过采用一种新的数据分区策略Z Curve Hashing将不同分区中的数据负载平衡化,并利用Voronoi基于密度的切分方式对图数据在每个节点分别建立本地索引,为图数据建立起良好的QuadTree索引结构来管理数据,实现了图存储的负载平衡以及最大化了图计算时的系统并行化,提高了图处理的速度;
(3)本发明通过使用新的基于区域的图分区策略将距离密集较近的通信频繁的边尽可能分配到同一个分区中,从而减少分区之间的边通信,加快了图构造的时间并为后期的图处理降低了通信开销;
(4)本发明可以在图数据的基础上搜索QuadTree索引结构查找到要查询的图数据,避免了遍历整个图,实现了快速直接的子图构建;
(5)本发明通过对图查询的扩展,实现了图上直接的空间范围查询以及空间连接操作,满足众多场景的需求。
附图说明
图1为本发明的系统架构图;
图2为本发明的数据区域划分示意图;
图3(a)为本发明的ZCH分区策略示意图;
图3(b)为本发明的集群空间数据分区示意图;
图4为本发明的Voronoi基于密度的数据切分示意图;
图5为本发明的空间操作树示意图;
图6为本发明的空间连接操作过程示意图;
图7为本发明的基于区域的图分区策略示意图。
具体实施方式:
下面结合附图与实施例对本发明作进一步说明。
一种基于SpatialGraphx平台支持空间数据管理的图计算框架,该框架中除了最底层的数据源之外包括三层:
1)数据管理层,利用ZCH(Z Curve Hashing)数据分区方式以及通过对底层的空间数据建立QuadTree索引来提供良好的空间数据管理机制,实现数据的负责平衡;
2)空间操作层,改成通过扩展SparkSQL的DataFrame增加对空间数据的范围查询、空间连接等操作;
3)图计算层,改成采用基于位置的图分区策略将距离较近的边尽可能分配到同一分区中,实现了局部图构建以及图计算效率的提升。
GeoGraphx框架系统从顶层到底层的实现如下:
1.图计算层
首先将数据源在读入系统中时构建出一个完整大图,在该大图的基础上进行空间操作,如图的范围查询、多图的空间连接等;
将空间操作请求传递到下层的空间查询层进行业务逻辑处理,并将空间操作的结果返回到图计算层;
针对返回的空间操作结果利用基于位置的图分区策略(将空间数据地理位置较近的数据分配到同一分区中进行构建图)进行子图的构建;
在构建的子图基础上进行其他空间操作与图分析;
2.空间查询层
空间查询层接收来自图计算层的空间查询请求,利用DataFrame自动将图查询请求类型转换为Point、Line、Polygon数据类型和数据类型之间的“in”、“overlaps”和“intersect”等关系。
范围查询是点Point数据类型与Polygon数据类型的关系,查询位于多边形Polygon中的数据点。当图计算层提交一个图的范围查询请求时,集群中的master节点会将其转换为数据查询并发送给每一个slave节点,通过多边形的数据范围在每个slave节点的本地索引树中同步并行查找,直到找到叶子节点。在查找过程中将多边形Polygon范围内的数据点取出来即可得出查询范围。
空间连接是接收两个空间数据集R和S,并接收来自图计算层的操作将其转换为数据集之间的关系θ(θ包括in、overlaps和intersect),然后返回一个数据对集<a,b>,其中a∈R,b∈S,a和b的类型可以是Point点、Line边或者Polygon多边形。
空间连接实现的主要步骤为:
1)计算RDD文件R与S中每条空间记录所属的网格id;
2)用Li表示节点i中的计算负载,在图计算的初始时刻Li均为0;
3)对于每一个网格计算位置处于其中的数据的数量,如果进行连接操作的两个分区的负载相同,则将量较小的数据集传送到量较大的数据集所在的分区中,如果进行连接操作的两个分区不同,则计算两个分区之间进行通信需要花费的时间并通过比较时间来决定如何传递两个分区中的数据集;
4)在同一分区中对两个数据集进行连接。
3.空间数据的管理层
在配置有GeoGraphx框架的Spark集群中利用SparkConfText读取要处理的空间数据集;
对空间数据集按照地理位置信息将其空间范围划分为n块矩形区域(集群节点数为n),对于矩形区域的划分是根据空间数据的密度进行调整的,尽量保证每块区域内所包含的数据量均匀;
之后将每个矩形内的数据分配到不同的分区中,即n个节点分别对n块矩形区域内的数据进行维护管理;
在每个salve节点内部各自建立空间数据的本地索引。每个节点针对矩形中的数据集进行数据分区,将其划分为n*n的网格,利用Z Curve Hashing对网格进行排序,将包含位置信息的二维空间数据映射到一维空间;将映射到一维空间后的数据保存到文件中,并同时用数组同步记录每一个网格中的数据在文件中的位置(第几条至第几条记录是位于哪一个网格的);针对小网格中的数据建立QuadTree索引,基于Voronoi图的密度切割方法对最底层叶子所维护的数据量进行均匀化平衡化。
实施例以移动通话数据为对象进行说明,Spark集群节点以4个节点为例。
首先图1展示的是GeoGraphx系统的整体框架图,底层是源数据,之后自下而上为数据存储、空间查询以及图计算。
1.数据存储层:
(1)当有时空数据传入系统时,要对其根据数据集中的空间范围进行不均等矩形划分,在该实施例中由于集群节点为4,则将数据集划分为4块矩形区域,其中矩形块的大小随着数据量的变化而变化。该过程如图2所示,数据量稀疏的矩形块面积相对较大,尽量保持每个矩形区域中的数据量相等。
(2)使用Z Curve Hashing数据分区方式对矩形块中的数据集进行分区。
首先将矩形块中的数据划分为n*n网格,如图3(a),然后使用Z-order Curve对细分后的网格进行排序,如图3(a)中所示,排序结果用标号标出,从而将矩形中二维空间数据映射到一维。将所有划分的网格进行从0到n*(n-1)排序编号。
之后利用哈希函数对网格id进行取模运算,H(key)=key mod(p),其中key表示网格id,p表示集群中节点数目,在该实施例中p=4。则H(key)表示id为key的网格中的数据被分配到节点H(key)中,H(key)取值为0,1,2,3。经过哈希映射后,图3(b)所示处于id为0,4,8和12的网格中的数据将会被分配到集群节点0中。
(3)对于每一个已经分配到数据的节点,使用基于Voronoi密度切分的方式将机器本地所管理的数据集建立本地QuadTree四叉树索引。
在实施例中所采用的移动通话数据,数据记录中的位置信息是基于基站确定的,可通过基站的位置分布得到数据的Voronoi图。图4中每个多边形代表一个基站所能覆盖的区域,基站的分布与经济发展相关,是非均匀分布的。
之后建立本地索引树,在Voronoi图中每一个多边形是树中的一个叶子节点,上层维护着更大范围的数据位置。在本地索引树中几乎每个叶子节点所维护的数据量的大小是均匀的。
2.空间查询层
用户在图上面所提交的空间操作在空间查询层会转化为针对RDD的操作,所有的数据结构以及操作均是RDD层面的。在这个转化过程中我们在该发明中扩展了多项新的空间数据类型和空间关系。
空间数据类型
通过扩展SparkSQL框架中的用户自定义类型增加了三种数据类型,如点Point、线Line和多边形Polygon等。
空间数据关系
针对新增的三种数据类型,在该发明中通过扩展SparkSQL框架中的用户自定义方法UDF添加了三种新的数据关系,如in、overlaps和intersect等。其中in是指Point位于Line或者Polygon中,overlaps指两个Point、两个Line、两个Polygon有重叠,intersect指交叉。
空间操作转换
对于图计算层传递的空间查询请求,在空间查询层首先将空间操作转换为针对RDD的操作。
针对空间操作,自下而上建立对应的操作树,如图5所示;
SparkSQL使用模式匹配函数递归树中的所有节点,将每个数据框函数转换为对应的RDD操作,即将SQL语言树转换为RDD实现树;
最后SparkSQL后序遍历RDD实现树,得到空间操作请求对应的RDD操作请求。
为将范围查询和空间连接两种空间操作加入到SparkSQL,需要在logical抽象类中添加相对应的抽象类,同时在execution中添加对应的实现类,并在模式匹配函数中添加相应的case。如此,更多的空间操作也可按照上面的方式添加到API层。
(2)空间范围查询
在得到上层的图计算层传递来的范围查询请求后,GeoGraphx集群中的master节点讲请求发送给所有的slave节点;
每个slave节点接收到master发放的查询信号之后从本地存储的数据RDD中取出索引部分,对索引的QuadTree进行搜索,通过将树节点维护的空间范围与查询条件进行比较,从根节点向叶子节点搜索,知道得出所有符合查询条件的叶子节点;
根据得到的索引结果,从数据RDD中取出与索引相对应的数据,并将数据传递回图计算层。
(3)空间连接操作
①对于要进行空间连接操作的两个数据RDD记录为rdd1和rdd2,首先获取他们的索引index1和index2;
②得到两组索引的部分索引对<n1,n2>满足以下条件:n1属于index1索引的叶子节点,n2属于index2索引的叶子节点,并且同时n1和n2满足join条件。记录下n1和n2索引对所对应的数据的大小;
③将索引对中对应数据量较大的索引记为ni,另一个对应数据量较小的索引记为nj,ni对应数据所在的分区为pi,则针对这样一对索引对得出一条记录<pi,nj>;
④对rdd1和rdd2的数据进行filter过滤操作,过滤出位于②所得出的节点对中的数据,并对这些数据根据③中得出的<pi,nj>进行重新分配,得到rdd3和rdd4;
⑤对得到的rdd3和rdd4进行join操作,得到最终的join操作的结果。
3.图计算层
图计算层主要与空间查询层进行交互,用户在图计算层对图进行一系列的操作。当空间数据进入GeoGraphx框架时除了要对数据进行管理还要对其构建一个大图G。
首先利用我们新的图分区策略进行构建图,在构建过程中将数据根据地理位置进行切分成多个网格,如图7所示。实施例中集群有4个节点,则基于位置的图分区策略根据RDD数据中的位置范围平均切分为4块区域,则标号为0的区域位于节点0,标号为1的区域位于节点1,以此类推,得到的大图中距离较近的边位于同一个分区节点中。
用户在大图G的基础上针对局部图进行空间操作以及其他操作,当用户选择对局部图进行范围查询时,将请求传递给空间查询层,由空间查询层负责进行业务逻辑的处理,并将处理结果返回到图计算层;
系统中有两个RDD数据构建对应的两个大图,要对两个大图进行空间join操作时,将请求传递给空间查询层,将图上的join操作转换为RDD数据的join操作,并将操作结果返回到图计算层;
图计算层获取操作结果后将数据再次利用基于区域的图分区策略构建结果小图,并将结果图展示给用户。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!