一种基于自适应线程束的GPU并行粒子群优化方法与流程
本发明涉及一种粒子群优化方法,属于计算机数据处理领域,具体涉及一种基于自适应线程束的GPU并行粒子群优化方法。
背景技术:
粒子群优化(Particle Swarm Optimization,PSO)算法是一种演化计算技术,由于其概念简单、易于实现,同时又具备较强的全局搜索及收敛能力等特点,而得到了快速的发展和广泛的应用。目前已出现各种并行PSO算法版本,这其中,针对CUDA并行架构,对线程的分配方案主要有两种:1)一个线程对应一个粒子;2)一个线程对应一个维度,一个Block对应一个粒子。第一种粗粒度并行方法,虽然已经取得了不错的加速比,但由于每个线程中粒子所对应的每个维度仍然是串行执行的,并行程度并不高。第二种细粒度并行方式在第一种的前提下做了改进,将每个粒子对应到每个Block,再将每个Blcok中的线程对应到每个粒子中的一个维度。这样无疑加大了
并行程度,但值得注意的是,在CUDA并行程序中,所有的Block是被串行的分配到每一个流多处理器上的,还可以继续提高并行度。
GPU是一种专用的图形渲染设备。最初GPU是专用于图形处理的硬件,然而自从2006年以来,越来越多的研究人员研究了利用GPU进行通用计算的GPGPU领域,各大厂商也推出了专用的GPGPU语言,比如CUDA、OPENCL等。
技术实现要素:
本发明的目的是优化原有基于GPU的计算方法,调整其并行架构使之并行效率更高,设计出一套改进的CUDA并行架构方式,利用图像处理器(GPU)加速执行,使得粒子群算法在单个主机上的并行度进一步的提高,相比前两种方法在CPU加速比的倍数上提高了40之多。
为了解决上述问题,本发明的方案是:
一种基于自适应线程束的GPU并行粒子群优化方法,
将每个粒子的维度划分为若干个线程束,使用线程块来包含所述线程束,使得一个线程块中对应一个或多个粒子;
其中,所述线程束是SM调度和执行的基本单位。
优化的,上述的一种基于自适应线程束的GPU并行粒子群优化方法,基于以下公式调整粒子所对应的线程束的个数WarpNum以及线程块所对应的粒子数ParticleNum:
WarpNum=DivUp(D,WarpSize) (8)
ThreadNum=WarpNum*WarpSize (9)
ParticleNum=
DivDown(BlockSize,ThreadNum) (10)
式中,D表示求解问题的维度,WarpSize表示CUDA架构中一个线程束的大小;DivUp函数的功能是将D除以WarpSize得到的商做向上取整,以得到粒子所对应Warp的个数WarpNum;ThreadNum用来表示每个粒子实际用到的线程总数;BlockSize表示CUDA架构中一个Block的大小,DivDown函数的功能是将BlockSize除以ThreadNum得到的商做向下取整,以得到Block所对应的粒子数ParticleNum。
优化的,上述的一种基于自适应线程束的GPU并行粒子群优化方法,在调用核函数之前,
基于自适应线程束算法,利用以下公式计算并初始化每个核函数的线程块的个数BlockNum以及网格的个数GridNum:
BlockNum=TreadNum*ParticleNum;
GridNum=DivUp(N,ParticleNum);
式中,ThreadNum用来表示每个粒子实际用到的线程总数;ParticleNum为线程块所对应的粒子数;N为粒子群中粒子的总个数。
优化的,上述的一种基于自适应线程束的GPU并行粒子群优化方法,
定义三个CUDA核函数,分别用于并行计算粒子的速度和位置、粒子的适应度值及下一代粒子自身所找到的最好适应度值及其对应的解、整个粒子群到目前为止找到的最好适应度值及其对应的解。
优化的,上述的一种基于自适应线程束的GPU并行粒子群优化方法,具体包括以下步骤:
步骤2.1:计算粒子的速度和位置内核,每个GPU线程按照分配好的线程块个数BlockNum和网格个数GridNum,通过粒子群算法的计算公式对应的计算每个问题某一维度对应的速度和位置;
步骤2.2:计算粒子的适应度值及下一代粒子自身所找到的最好适应度值及其对应的解内核,按照分配好的BlockNum和GridNum并行计算每个粒子每个维度的适应度值,再根据每个维度的适应度值通过并行规约算法,得到每个粒子的适应度值,最后根据得到的适应度值,更新粒子的适应度值及其所对应的解;
步骤2.3:计算整个粒子群到目前为止找到的最好适应度值及其对应的解内核,通过使用CUBLAS的cublasI<t>amin()函数(t为操作对象的数据类型)在GPU上求得整个粒子群到目前为止找到的最好适应度值及其对应的解。
优化的,上述的一种基于自适应线程束的GPU并行粒子群优化方法,基于以下公式初始化问题函数:
其中,fSphere为问题函数Sphere的求解公式,fRastrigrin为问题函数Rastrigrin的求解公式,fRosenbrock为问题函数Rosenbrock的求解公式,x为问题函数变量,D为问题函数的维度。
优化的,上述的一种基于自适应线程束的GPU并行粒子群优化方法,基于以下公式更新粒子群的公式:
Xid(t+1)=Xid(t)+Vid(t); (5)
其中,Vid表示每个粒子的速度,t表示当前的迭代代数,w表示粒子群的惯性权重系数,c1和c2表示粒子群的加速因子,r1和r2是[0,1]区间中均匀分布的随机数,表示该粒子的个体极值,表示整个粒子群的全局极值,Xid表示该粒子的当前位置(解)。基于以下公式更新粒子群参数w和C1/C2:
w=1/(2*ln(2)); (6)
c1=c2=0.5+ln(2); (7)
因此,本发明具有如下优点:
(1)使用本发明提供的方法,可以大幅缩短PSO算法求解问题时间,提高相关应用软件响应速度;
(2)用本发明提供的方法,可以选用低端CPU用于主机,中高端GPU用于计算,达到多CPU甚至集群的性能,从而减少功耗,节约硬件成本。
附图说明
图1为本发明实施例的粒子群算法优化方法流程图。
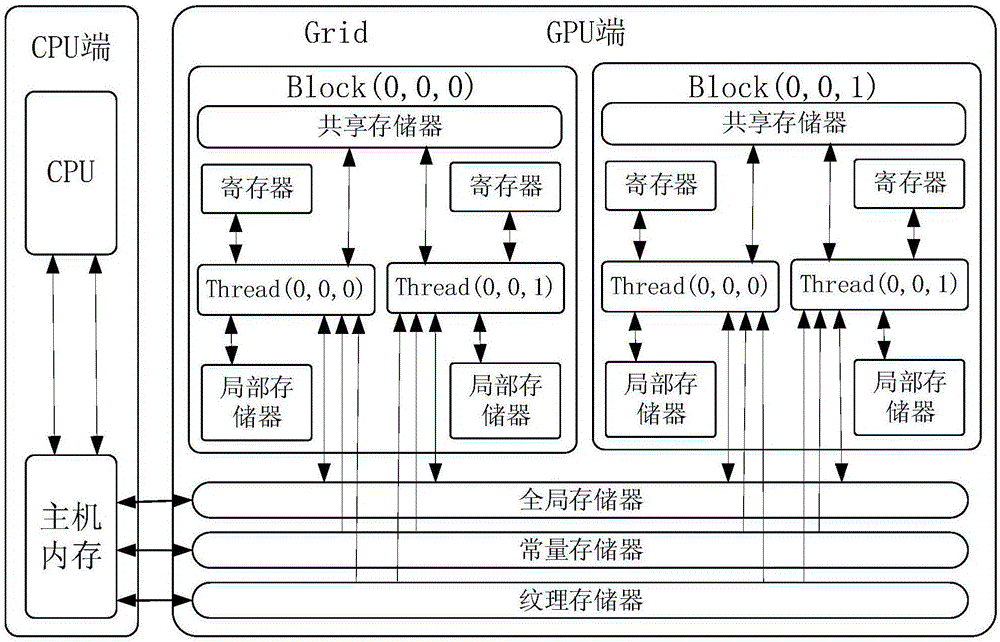
图2为CUDA并行计算模型。
图3为本发明实施例的GPU端更新架构图。
图4为本发明实施例的包含GPU端更新架构图的粒子群算法优化方法流程图。
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
实施例:
如图1所示,为本实施例的一种基于自适应线程束的GPU并行粒子群优化方法,包括以下步骤:
步骤1:初始化问题函数参数,初始化粒子群参数;
步骤2:定义三个CUDA核函数,分别用于并行计算粒子的速度和位置、粒子的适应度值及下一代粒子自身所找到的最好适应度值及其对应的解、整个粒子群到目前为止找到的最好适应度值及其对应的解;
步骤3:根据自适应线程束算法计算并初始化每个核函数的BlockNum及GridNum;
步骤4:调用核函数并行迭代更新粒子群的速度和位置,并求出当前最好适应度值及其对应的解;
步骤5:重复执行步骤4直到达到设定的结束条件,GPU输出计算结果。
其中,步骤1中的问题函数基于如下公式(1)-(3)定义:
其中,fSphere为问题函数Sphere的求解公式,fRastrigrin为问题函数Rastrigrin的求解公式,fRosenbrock为问题函数Rosenbrock的求解公式,x为问题函数变量,D为问题函数的维度。
粒子群的更新公式如下公式(4)-(5)所示:
Xid(t+1)=Xid(t)+Vid(t); (5)
其中,Vid表示每个粒子的速度,t表示当前的迭代代数,w表示粒子群的惯性权重系数,c1和c2表示粒子群的加速因子,r1和r2是[0,1]区间中均匀分布的随机数,表示该粒子的个体极值,表示整个粒子群的全局极值,Xid表示该粒子的当前位置(解)。参数w和C1/C2的的更新公式如下如下公式(6)-(7)所示:
w=1/(2*ln(2)); (6)
c1=c2=0.5+ln(2); (7)
本实施例的步骤2中定义三个CUDA核函数,分别用于并行计算粒子的速度和位置、粒子的适应度值及下一代粒子自身所找到的最好适应度值及其对应的解、整个粒子群到目前为止找到的最好适应度值及其对应的解;
GPU并行计算,本算法在CUDA平台上实现。详见图2,CUDA并行计算模型是一种SIMD(单指令多数据)的并行化计算模型,其中GPU作为一个协处理器产生大量线程,可以帮助CPU完成高度并行化的大量简单计算工作。CUDA采用多层存储器的架构模型,共有三个不同的层次:线程(Thread),线程块(Block)以及块网格(Grid)。Thread运行在SP(StreamingProcessor,流处理器)上,是其中最基本的执行单元,每个Thread拥有一个私有的寄存器,多个执行相同指令的Thread可以组成一个Block。Block运行在SM(StreamingMultiprocessor,流多处理器)上,一个Block内所有的Thread可以通过Block内的共享内存(ShareMemory)进行数据通信和共享,并实现同步,多个完成相同功能的Block可以组成一个Grid。Grid运行在SPA(ScalableStreamingProcessorArray,流处理器阵列)上,同一个Grid中的Block之间不需要通讯,且Gird间的执行是串行的。即当程序加载时,Grid加载到GPU上之后,所有的的Block被串行的分配到每一个流多处理器上。因此,必须合理的分配每个Block中的线程数,以便能更好的提高并行度。
实际运行中,Block会被分割为更小的线程束Warp。在一个SM上,每个Block中的线程按照其唯一的ID进行顺序分组,相邻的32个线程组成一个Warp。逻辑上所有的thread都是并行的,但是从硬件的角度来讲,并不是所有的thread能够在同一时刻执行,Warp才是SM调度和执行的基本单位。在CUDA编程模型之中并没有抽象出Warp的定义,Warp是由GPU的硬件结构决定的,但却对性能影响很大。同一Warp内的线程可以认为是“同时”执行的,不需要进行同步也能通过sharedmemory进行通信,可以进一步的节省调用__syncthreads()函数对线程进行同步所消耗的时间。综上所述,增加每个Block中线程的使用量,并以Warp为单位考虑对Block中线程数分配的优化,可以获得更高性能。
步骤2具体实现包括以下子步骤:
步骤2.1:计算粒子的速度和位置内核,按照分配好的Block数量BlockNum和Grid数量GridNum通过粒子群算法的计算公式,每个GPU线程对应的计算每个问题某一维度对应的速度和位置;其中该核函数的定义如下:
__global__voidParticleFly_VP_kernel(float*Particle_X,float*P article_V,int*GBestIndex,float*Particle_XBest,float*Particle_Fit Best,curandState*s)
函数中的参数依次分别表示所有粒子的位置数组(长度为粒子数*维度)、所有粒子的速度数组(长度为粒子数*维度)、最好粒子下标、最好适应度、最好适应度对应的解的数组(长度为问题函数的维度);
步骤2.2:计算粒子的适应度值及下一代粒子自身所找到的最好适应度值及其对应的解内核,按照分配好的BlockNum和GridNum并行计算每个粒子每个维度的适应度值,再根据每个维度的适应度值通过并行规约(Reduction)算法,得到每个粒子的适应度值。最后根据得到的适应度值,更新粒子的适应度值及其所对应的解;其中该核函数的定义如下:
__global__voidParticleFly_Fit_kernel(float*Particle_X,float*Particle_XBest,float*Particle_Fit,float*Particle_FitBest)
函数中的参数依次分别表示所有粒子的位置数组(长度为粒子数*维度)、最好适应度对应的解的数组(长度为问题函数的维度),所有粒子的适应度数组(长度为粒子数),最好适应度;
需要注意的是,该核函数中需要使用到并行缩减以求取最好适应度值,所以需要为该核函数分配共享内存,需要分配的共享内存大小为Block_Size*sizeof(float),其中Block_Size为每个Block中的线程数;
步骤2.3:计算整个粒子群到目前为止找到的最好适应度值及其对应的解内核,通过使用CUBLAS的cublasI<t>amin()函数(t为操作对象的数据类型)在GPU上求得整个粒子群到目前为止找到的最好适应度值及其对应的解;
步骤3的示意图如图3所示,根据自适应线程束算法计算并初始化每个核函数的BlockNum及GridNum;
其具体实现包括以下子步骤:
步骤3.1:本方法基于CUDA计算模型的特点,将每个粒子的维度划分为一个或多个Warp,然后使用Blcok来包含这些Warp,使得一个Block中对应一个或多个粒子,从而增加每个Block中线程的使用量,达到Warp级别并行的效果。
步骤3.2:粒子所对应Warp的个数及Block所对应的粒子数都会根据粒子维度的大小进行自适应的调整。具体的自适应过程遵循如下公式(8)-(10)所示:
WarpNum=DivUp(D,WarpSize) (8)
ThreadNum=WarpNum*WarpSize (9)
ParticleNum=
DivDown(BlockSize,ThreadNum) (10)
步骤3.3:D表示求解问题的维度,WarpSize表示CUDA架构中一个Warp的大小。DivUp函数的功能是将D除以WarpSize得到的商做向上取整,以得到粒子所对应Warp的个数WarpNum。ThreadNum用来表示每个粒子实际用到的线程总数。BlockSize表示CUDA架构中一个Block的大小。DivDown函数的功能是将BlockSize除以ThreadNum得到的商做向下取整,以得到Block所对应的粒子数ParticleNum。
步骤3.4:在调用核函数之前,首先需要确定CUDA的Block的大小BlockNum及Grid的大小GridNum,以体现自适应线程束方法的特点,具体如下公式(11)-(12)所示:
BlockNum=TreadNum*ParticleNum (11)
GridNum=DivUp(N,ParticleNum) (12)
本算法优化原有基于GPU的计算方法,调整期并行架构使之并行效率更高,设计出一套改进的CUDA并行架构方式,利用图像处理器(GPU)加速执行。将一个线程对应一个维度,一个或多个Warp对应一个粒子,一个或多个粒子对应一个Block,使得粒子群算法在单个主机上的并行度进一步的提高,相比前两种方法在CPU加速比的倍数上提高了40之多。
从以上描述可知,本实施例具有如下优点:
(1)使用本发明提供的方法,可以大幅缩短PSO算法求解问题时间,提高相关应用软件响应速度;(2)用本发明提供的方法,可以选用低端CPU用于主机,中高端GPU用于计算,达到多CPU甚至集群的性能,从而减少功耗,节约硬件成本。
本实施例所描述的方法可用于游戏中的自动寻路、图像处理等领域。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!