一种用于恶意软件检测的样本类别判定方法与流程
本发明涉及信息安全
技术领域:
,具体涉及一种用于恶意软件检测的样本类别判定方法。
背景技术:
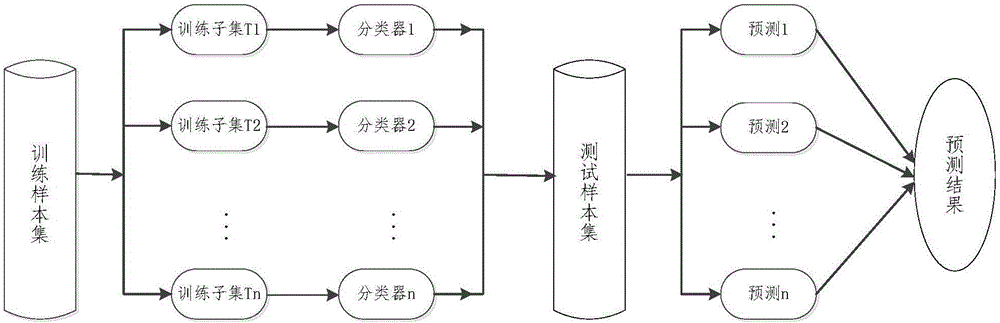
:随着当今互联网、个人计算机和移动计算平台的迅速发展,各种各样的恶意软件也层出不穷,并以极快的速度传播,严重威胁了终端用户的信息安全。同时,恶意代码的数量和种类日趋增多,加上代码迷惑技术的兴起,使得检测恶意软件的工作变得越来越困难。恶意软件的全面研究比较困难。在进行逆向工程和构建时间轴之前,研究人员需要从恶意软件的多个发展阶段获取大量样本,并通过静态及动态等检测方法,研究分析样本程序的恶意行为以及不同恶意软件之间的关联度。由于统计的花费巨大而收获常常有限,因此寻找相似样本的工作非常困难。所有这些传统的方法,使得对恶意软件的检测效率较低。技术实现要素:本发明的目的在于提供一种用于恶意软件检测的样本类别判定方法,用以解决现有恶意软件自动检测中很难寻找近似样本,检测效率低的问题。为实现上述目的,本发明提供一种用于恶意软件检测的样本类别判定方法,该方法包括如下步骤:步骤1、收集样本程序集,由人对程序集进行分类判断标记分为恶意程序集和正常程序集,分别组成样本库;步骤2、将所述样本库中的所述恶意程序集和正常程序集提交至虚拟沙箱环境运行,所述样本程序集中每一个样本程序在所述模拟沙箱环境运行后生成相应的样本分析报告;步骤3、解析所述样本分析报告,提取特有特征组合信息,生成特征向量集;步骤4、将所述特征向量集输入分类器进行训练,得到最佳模型;步骤5、将待测程序输入所述最佳模型,得到所述待测程序是恶意程序或正常程序的判别结果。进一步地,所述步骤2中所述分析报告为JSON格式(JavaScriptObjectNotation),所述分析报告包括所述每一样本程序在执行过程中对不同API(ApplicationProgrammingInterface,应用程序编程接口)的调用信息、以及所述每一样本程序触发的不同规则的信息。进一步地,所述规则信息包括API行为规则,文件操作行为规则,网络行为规则,注册表行为规则以及上述行为的混合行为规则。进一步地,所述步骤3中提取的特有特征为:所述样本程序调用特有的API(应用程序编程接口),以及所述样本程序是否触发可疑规则两种,将所述样本程序对可疑规则的触发情况,以及对特有API调用进行统计组合后,形成多维度特征向量集。进一步地,所述步骤4中分类器生成过程如下:将所述样本集分为训练样本集和测试样本集;将所述训练样本集的特征向量分别输入到n个不同的分类器进行训练,得到训练后的n个分类器;将所述测试样本集的特征向量分别输入到所述n个训练后的分类器,得到预测结果;比较所述预测结果与所述训练样本集的实际类别标记值,生成最佳分类器。进一步地,所述步骤4中所述得到最佳模型过程如下:将所述步骤3得到的所述特征向量和所述样本集的实际类别标记值组合;将所述组合划分为训练样本集和测试样本集;将所述训练集输入到所述最佳分类器进行训练;调整所述最佳分类器参数并进行交叉验证;选择最佳参数并对所述测试集进行预测;通过比较所述测试集预测结果与所述测试集实际类别标记值,得出最佳模型。进一步地,将所述带有标记的恶意程序集拆分,使得每堆恶意程序数量和所述正常程序数量近似相同,形成多份训练样本集;将所述多份训练样本集输入所述分类器,训练生成多个模型;将所有所述训练样本集分别输入至所述每个模型,得到所述每个模型对所有所述训练样本集的预测结果矩阵;将所述预测结果矩阵与所述训练样本集的实际类别标记值组成特征向量;将所述特征向量集输入机器学习分类器进行训练,得到所述每个模型计算未知程序分类结果的权值;将待测样本程序输入至所述每个模型得出预测值,然后再根据所述每个模型的权值对上述预测再进行加权求和,得出所述待测样本程序的最终分类结果。进一步地,所述机器学习分类器训练目标函数为其中r为所述模型的个数,训练时,调整所述目标函数J(θ)的参数向量θ,使得所述目标函数J(θ)取极值,生成的参数向量θ(θ1,θ2,...,θr)即为所述模型的权值。进一步地,所述模型权值加权求和具体方法为:其中,r为所述模型的个数,θi为第i个模型的权值,Ci则为第i个模型对待测样本程序的预测值。本发明具有如下优点:本发明提高了恶意软件检测的效率和准确率,具有简单、高效的特点,避免了动态检测技术中繁杂的操作和较大的能耗,在保证准确率的基础上大幅提高了检测的速度。附图说明图1为本发明一较佳实施例的样本类别判定方法流程示意图。图2为本发明一较佳实施例的分类器产生过程示意图。图3为本发明一较佳实施例的最佳模型产生过程示意图。图4是本发明一较佳实施例的多模型加权原理示意图。具体实施方式以下实施例用于说明本发明,但不用来限制本发明的范围。实施例1一种用于恶意软件检测的样本类别判定方法,通过对标记样本集的训练和学习,得到一种最佳模型,用于判断待测程序是否恶意程序,具体流程如图1所示,包括如下步骤:步骤1收集样本程序集,由人工对程序集进行分类判断标记,分为恶意程序集和正常程序集,分别组成样本库。综合各类已有的程序检测工具对程序的扫描结果,以及针对程序进行的人工分析结果判定,作为对恶意程序集和正常程序集的分类标准,由人工对程序集进行标记。步骤2将样本库中的恶意程序集和正常程序集提交至虚拟沙箱环境运行,样本程序集中每一样本程序运行后生成相应的样本分析报告。分析报告为JSON格式(JavaScriptObjectNotation),分析报告包括每一样本程序在执行过程中对不同API(ApplicationProgrammingInterface,应用程序编程接口)的调用信息、以及每一样本程序触发的不同规则的信息,其中,不同的规则包括API行为规则,文件操作行为规则,网络行为规则,注册表行为规则以及上述行为的混合行为规则。步骤3解析所述样本分析报告,提取特有特征组合信息,生成特征向量。本实施例选择两个特征:样本程序调用特有的API次数统计,以及样本程序是否触发可疑规则。根据样本分析报告,统计出每一个程序样本对不同API的调用次数,以及该程序样本是否触发了不同的规则。这些统计信息作为不同的特征并组合后,形成多维度特征向量集例如某个程序样本假设API以及规则触发情况调用情况如下表所示:Api001Api002Api003Api004Api005规则001规则002规则003规则00412481011001则生成的特征向量为[124810111001]。多个程序样本的特征向量构成特征向量集。步骤4将特征向量集输入分类器进行训练,得到最佳模型。分类器生成过程如图2所示,具体过程如下:将多维度样本特征向量集与样本类别标记值组合,得到新的样本特征向量集其中为样本类别标记值向量,将组合后的样本集的分为训练样本集和测试样本集;将训练样本集按照分类器个数n分成n个训练子集T1,T2,...,Tn,将n个训练子集的特征向量分别输入到n个不同的分类器进行训练,得到训练后的n个分类器;将测试样本集的特征向量分别输入到n个训练后的分类器,得到预测结果;比较预测结果与测试样本集的实际类别标记值,生成最佳分类器。最佳模型训练流程如图3所示,具体步骤如下:将步骤3得到的特征向量集和样本集的实际类别标记值组合;将该组合划分为训练样本集和测试样本集;将训练集输入到最佳分类器进行训练;调整最佳分类器参数并进行交叉验证;选择最佳参数并对所述测试集进行预测;通过比较测试集预测结果与测试集实际类别标记值,得出最佳模型。步骤5将待测程序输入最佳模型,得到该待测程序是恶意程序或正常程序的判别结果。本实施例通过对带有标记的恶意程序集和正常程序集样本库的学习,得到判断待测程序是否是恶意程序的最佳模型,提高了恶意软件检测的效率和准确率。实施例2一种用于恶意软件检测的样本类别判定方法,采集到的已标记恶意程序数量远远大于正常程序数量,具体步骤如下:步骤1收集带有标记的恶意程序集和正常程序集作为样本集,分别组成样本库。步骤2将样本库中的恶意程序集和正常程序集提交至虚拟沙箱环境运行,程序集中每一个程序运行后生成相应的样本分析报告。步骤3解析样本分析报告,提取特有特征组合信息,生成特征向量集;拆分恶意程序特征向量集,使得拆分后的每堆恶意程序数量和正常程序数量近似1:1,形成多份训练样本集。如图4所示,训练样本集为T(x),拆分后的训练样本集为{T1(X),T2(X),T3(X),...,Tr(X)},其中r为训练样本集的个数。步骤4将多份特征向量集分别输入分类器,训练生成多个模型。如图4所示,生成的模型为{模型1、模型2、....、模型r}。步骤5将所有训练样本集分别输入至生成的每个模型,得到每个模型对所有训练样本集的预测结果矩阵;将所述预测结果矩阵与所述训练样本集的实际类别标记值组成特征向量;将所述特征向量输入机器学习分类器进行训练,得到所述每个模型计算未知程序分类结果的权值。如图4所示,{模型1、模型2、....、模型r}对训练样本集{T1(X),T2(X),T3(X),...,Tr(X)}的预测结果矩阵与所述训练样本集的实际类别标记值组成特征向量为将该特征向量输入分类器训练,得到每个模型的权值。机器学习分类器训练目标函数为其中r为所述模型的个数,训练时,调整目标函数J(θ)的参数向量θ,使得所述目标函数J(θ)取极值,生成的参数向量θ(θ1,θ2,...,θr)即为模型的权值。步骤6将待测样本程序输入至每个模型得出预测值,然后再根据所述模型的权值对上述预测进行加权求和,得出所述待测样本程序的最终分类结果。模型加权求和具体方法为:其中,r为所述模型的个数,θi为第i个模型的权值,Ci则为第i个模型对待测样本程序的预测值。本实施例根据采集到的恶意程序数量远远大于正常程序数量这一事实,采用欠采样的手段,拆分恶意程序特征向量集,训练得到多个模型,通过加权求和得出最终的分类结果。虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1