一种基于数据挖掘的源代码注释自动生成方法与流程
本发明涉及函数注释自动生成技术,特别涉及文本处理技术和数据挖掘中信息采集领域的web数据爬取技术,提出了一种基于数据挖掘的源代码注释自动生成方法。
背景技术:
注释是为了提高源码可读性而编写的对应源代码的自然语言文本描述,主要目的是为了辅助程序员进行代码理解,提高软件系统的可维护性。优秀的软件项目需要有高质量的代码和准确、全面的注释及文档。由于目前大部分开源项目软件周期短,例如Linux内核作为优秀的开源项目,其应用和影响都非常广泛,但其注释的覆盖程度远不能满足学习及初级开发人员的需求。同时目前大部分开源软件版本更新迅速,而且版本更新有越来越快的趋势,对应的注释不能随版本更迭及时更新。因此,开源软件的代码和注释之间存在注释覆盖低等数量方面的问题,同时也存在由于版本更新导致注释信息更新滞后而不准确、不完整等质量方面的问题。然而互联网上相关开源软件的开发和维护的公开信息庞大且繁杂、良莠不齐、难于区分,对于学习和开发辅助作用有限且资料的搜集和甄别工作量较大。
源代码注释一般由有经验的程序员手工编写,人工注释的困难促进了自动注释方法的研究。目前自动注释技术的研究多致力于利用源码语义自动生成自然语言注释,其多数针对面向对象语言,涉及语法分析、语义分析等十分复杂的技术,还有一些技术致力于构建复杂的模型,技术难度大,实现困难。
技术实现要素:
针对上述问题,本发明的目的在于提供一种基于数据挖掘的源代码注释自动生成方法。通过这种方法可以快捷的自动生成Linux内核函数的整体注释,注释涉及函数功能、设计场景、使用方式、或针对不同版本的特性。所述方法填补了linux内核自动注释技术的空白,为Linux内核学习和开发人员提供更多的参考信息,有效降低初级开发人员的工作量和难度。
为了实现上述目的,本发明采用以下技术方案:
一种基于数据挖掘的源代码注释自动生成方法,包括以下步骤:
1)分别从三种数据源中爬取与Linux内核函数相关的描述信息,所述三种数据源为Stack Overflow网站、Linux kernel邮件和Linuxkernel Commit-log;
2)对步骤1)中得到的描述信息进行预处理,获取可能作为注释的文本,所述预处理包括文本格式处理及剔除无关Linux内核描述的噪声信息;
3)概括函数注释自然文本关键的特性作为提取规则,对步骤2)预处理后获取到的文本进行提取,自动生成函数整体注释。
进一步地,步骤1)中使用数据挖掘信息采集领域的web数据爬取技术分别从三种数据源中爬取与Linux内核函数相关的描述信息。web数据爬取指根据URL下载网页内容,针对不同网页的HTML结构特征,利用正则表达式或者其他的方式进行文本分析,提取所需的目标文本。
进一步地,步骤1)包括:从Stack Overflow网站获取编程人员对指定函数讨论的信息、从Linux kernel邮件获取内核开发人员的开发过程邮件信息、从Linux kernel Commit-log获取开发人员提交代码的Commit-log信息,将全部数据分类存储于数据库。
进一步地,从Stack Overflow网站获取编程人员对指定函数讨论的信息的具体步骤如下:
1-1-1)在Stack Overflow网站的搜索页面输入“Linux+目标函数名称”搜索,得到目标函数话题列表的URL,爬取此页的HTML文件内容;
1-1-2)对步骤1-1-1)爬取的HTML文件内容进行解析,获取该网页中多个问题的URL链接并爬取其子HTML文件内容;
1-1-3)对步骤1-1-2)爬取的多个问题的子HTML文件内容,提取出网页中的问题标题、问题标号、投票数、问题描述和答案分类存储于数据库中。
进一步地,按照时间段分隔的邮件服务器http://lkml.iu.edu/hypermail/linux/kernel进行邮件的爬取,从Linux kernel邮件获取内核开发人员的开发过程邮件信息,具体步骤如下:
1-2-1)选取某一时间段为目标,得到的该时间段邮件列表的URL,爬取此页的HTML文件;
1-2-2)对步骤1-2-1)爬取的HTML文件进行解析,获取该时间段内的所有邮件的URL链接并爬取其HTML文件;
1-2-3)对步骤1-2-2)爬取的所有邮件的HTML文件,提取出网页中邮件的标题和正文(即Body-of-Message标签中的内容)存储于数据库中。
进一步地,从Linux kernel Commit-log获取开发人员提交代码的Commit-log信息的具体步骤如下:
1-3-1)根据用户指定的起始版本获取第一个要爬取的show页面的URL;
1-3-2)爬取show页面的HTML文档,解析HTML文档获取commit log正文与标题存入数据库,并拼接next页面的URL;
1-3-3)在标题中查找终止版本的标识,如果找到则结束爬取,否则返回步骤1-3-2)继续next页面。
进一步地,步骤2)中所述文本格式处理包括:将从三种数据源中爬取的描述信息以空行为分隔符,将文本分成备选注释段落并去除HTML标签。
进一步地,步骤2)中分别针对三种数据源形成三种对应的过滤规则,从步骤1)中得到的描述信息中剔除无关Linux内核描述的噪声信息。
进一步地,针对Stack Overflow网站形成的过滤规则为:如果问题的投票小于1,删除问题及对应答案的所有段落;如果问题的投票大于1,删除对应答案中小于1的答案的所有段落;针对Linux kernel邮件形成的过滤规则为:以关键字"+"、"WARING"、"ERROR"、"#good"、"#bad"为条件剔除邮件中包含调用栈信息、告警、错误、补丁等的段落;针对Linux kernel Commit-log形成的过滤规则为:对于Commit-log正文以关键字"==="、"Fix"、"Signed-off-by"为条件剔除commit-log特有的无关函数注释的内容。
进一步地,从步骤1)中得到的描述信息中剔除无关Linux内核描述的噪声信息包括:按照针对Stack Overflow网站形成的过滤规则,剔除从Stack Overflow网站爬取的描述信息中投票小于1的段落;按照针对Linux kernel邮件形成的过滤规则,剔除邮件特有的不适注释的段落;按照针对Linux kernel Commit-log形成的过滤规则剔除Commit-log特有的不适注释的段落。
进一步地,步骤3)中所述提取规则具体包括:
提取规则1:对函数进行注释说明的文字,通常包含如下关键字中的一个或几个:
"函数名字+()"、"function"、"methord"、"return"、"call"、"execute"、"invoke";
提取规则2:对于函数的描述性语言中包含如下关键字的句子,一般不能作为函数的注释性文本:
no,not,error,bug,difficult,difficulty,problem,problems,fix,shouldn’t,doesn’t,can’t,couldn’t,don’t,isn’t,aren’t,wouldn’t,fail,why,what,null,bad,wrong,missing,lack,probably,likely,perhaps,think,may,maybe,unfortunately,unluckily。
进一步地,步骤3)具体包括:
3-1)按提取规则1提取段落。
3-2)将提取得到的段落分成句子。
3-3)按提取规则2过滤句子,如有剩余,自动生成的函数注释。
本发明提出的新方法涉及从三种各具特色的数据源提取文本,自动生成Linux内核函数注释,同理也可扩展形成其他开源软件的注释自动生成方法。所述方法以三种不同特性的资源:Stack Overflow网站、Linux kernel邮件、Linux kernel Commit-log为数据源(下文简称三种资源)自动生成注释。其中,StackOverflow是知名的编程问题问答网站,从中获取的信息能够在函数功能、设计场景、使用方式等多维度对函数进行注释说明;Linux内核邮件数据量巨大,每天可以达到200至400封,并且能够提供可靠、权威的信息;Linux内核Commit-log以版本的更迭为组织方式,其信息具有版本特性。注释自动生成的方式采取在研究大量注释的基础上,总结函数注释一般规则进行提取。以这三种数据为源提取的注释能够丰富传统函数注释,提供多维度的信息且关注版本的更迭,能够以相对小的代价提供可读性好且相对可靠的函数注释信息。为学习和开发者提供更多的参考信息,提升学习和开发效率。所述方法不需要进行代价较高的源码分析、复杂的模型构建,即可快速实现函数注释的自动生成,并支持持续的linux内核版本的更新中增量注释的自动生成。
附图说明
图1是基于数据挖掘的的源代码注释自动生成方法的整体流程图。
图2是数据获取与存储的流程图。
图3是数据预处理的流程图。
图4是按规则生成注释的流程图。
具体实施方式
本发明的基于数据挖掘的的源代码注释自动生成方法,包括三部分。如图1所示,第一部分是数据获取与存储,第二部分是数据预处理,第三部分按规则生成注释。具体描述如下:
1)数据的获取与存储
对于三种资源的不同数据特征,为获取所需目标文本,需要根据各自的特性制定不同的爬取策略。
1a)问答网站Stack Overflow
Stack Overflow是针对编程问题的专业问答网站,用户可以在网站提交问题、浏览问题、搜索相关问答内容。问题的内容涉及广泛,常包括函数的用法、设计背景等多个方面。本方法以Linux内核函数为关键字进行搜索,可以得到关于函数的功能、设计场景、使用等不同方面的问题和答案。这些问题和答案将作为生成注释的原材料存入数据库中。具体步骤如下:
i.在Stack Overflow网站的搜索页面输入“Linux+目标函数名称”搜索,得到目标函数话题列表的URL,爬取此页的HTML文件内容;
ii.对i步骤获取的HTML页面进行解析,获取该网页中多个问题的URL链接并爬取子HTML文件内容;
iii.对ii步骤爬取的多个问题的HTML页面,提取出网页中的问题标题、问题标号、投票数、问题描述和答案分类存于数据库中。
1b)Linux kernel邮件
Linux开发过程中的邮件按照不同的方式存于多个不同的服务器中,Linux kernel邮件是Linux内核开发人员的官方交流平台,邮件内容常包括补丁的提交、审查、版本发布、技术交流等内容,每日的数据量非常庞大。本方法选取按照时间段分隔的邮件服务器http://lkml.iu.edu/hypermail/linux/kernel进行邮件的爬取。具体步骤如下:
i.选取某一时间段为目标,得到的该时间段邮件列表的URL,爬取此页的HTML文件;
ii.对i步骤获取的HTML进行解析,获取该时间段内的所有邮件的URL链接并爬取HTML文件;
iii.对ii步骤爬取的邮件HTML页面,提取出网页中邮件正文即Body-of-Message标签中的内容存于数据库中。
1c)Linux kernel Commit-log
Linux kernel Commit-log是记录Linux内核开发人员每一次对内核代码提交的日志,通常包括两类补丁代码和对应的新特性代码说明、Bug修复代码说明等,其内容随内核版本的演进在持续的同步更新。存放于代码库中的Commit-log信息对应于不同的版本,本方法爬取任意两个版本之间的Commit-log信息为生成对应版本的函数注释提供原材料。具体步骤如下:
i.根据起始版本获取第一个要爬取show页面URL;
ii.爬取show页面HTML,解析HTML文档获取commit log正文与标题存入数据库,并拼接next页面的URL;
iii.在标题中查找终止版本的标识,如果找到则结束爬取,否则返回步骤ii继续next页面。
2)数据预处理
不同的数据源包含不同样式的信息和不同的组织形式,所述方法首先将三种资源爬取的数据库内容文本以空行为分隔符,将文本分成备选注释段落并去除HTML标签。然后在研究各数据源特性的基础上,对Stack Overflow网站数据、Linux kernel邮件数据和Linux kernel Commit-log数据制定特有的三种过滤规则,利用过滤规则剔除无关Linux内核函数描述的噪声信息。
2a)Stack Overflow网站数据
过滤规则1:如果问题的投票小于1,删除问题及对应答案的所有段落;如果问题的投票大于1,删除对应答案中小于1的答案的所有段落。
2b)Linux kernel邮件数据
过滤规则2:以关键字"+"、"WARING"、"ERROR"、"#good"、"#bad"为条件剔除邮件中常包含的调用栈信息、告警、错误、补丁等段落。
2c)Linux kernel Commit-log数据
过滤规则3:对于Commit-log正文以关键字"==="、"Fix"、"Signed-off-by"为条件剔除commit-log特有的无关函数注释的内容;
3)按规则生成注释
所述方法在研究大量函数注释的基础上,概括人工函数注释自然文本关键的特性,以此特性制定生成函数注释的两种提取规则。具体包括:
3a)提取规则1:对函数进行注释说明的文字,通常包含如下关键字中的一个或几个:
"函数名字+()"、"function"、"methord"、"return"、"call"、"execute"、"invoke";
3b)提取规则2:对于函数的描述性语言中包含如下关键字的句子,一般不能作为函数的注释性文本:
no,not,error,bug,difficult,difficulty,problem,problems,fix,shouldn’t,doesn’t,can’t,couldn’t,don’t,isn’t,aren’t,wouldn’t,fail,why,what,null,bad,wrong,missing,lack,probably,likely,perhaps,think,may,maybe,unfortunately,unluckily。
本发明方案的具体的步骤如下:
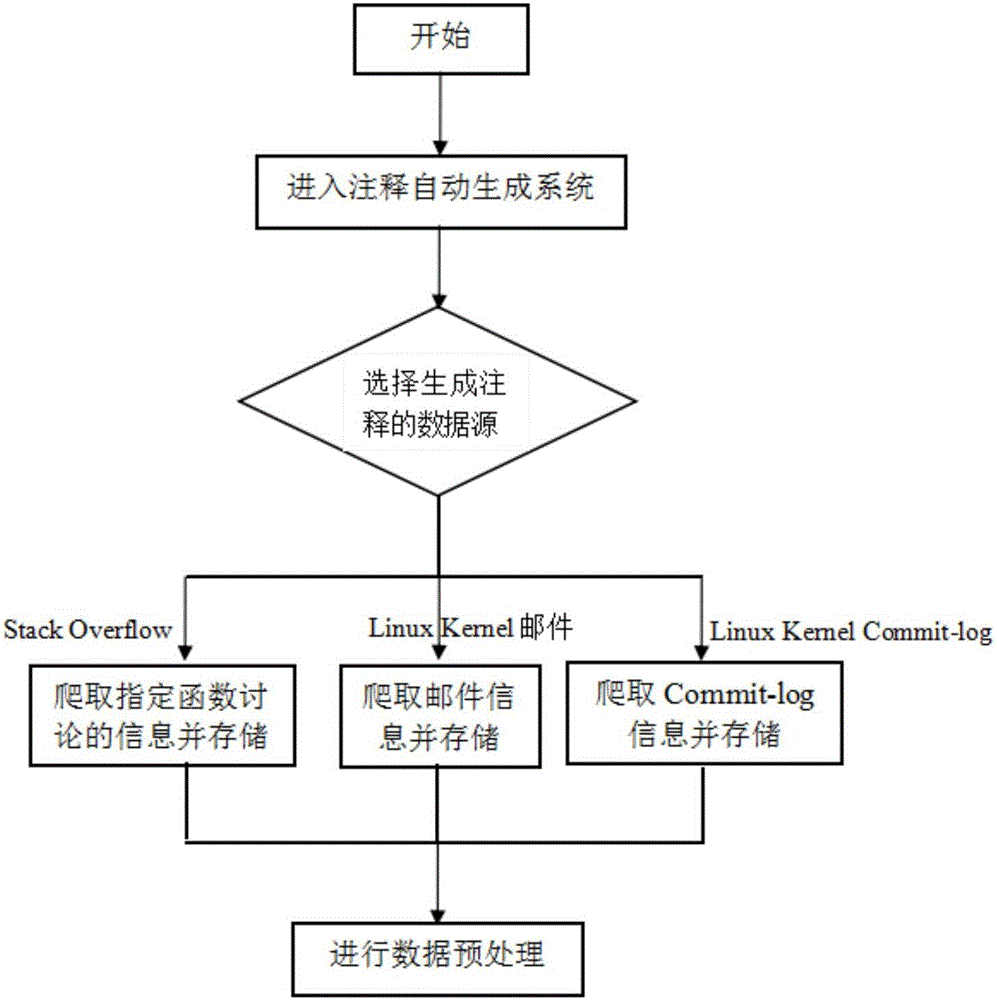
1)数据获取与存储,图2是数据获取与存储流程图,包括:
1a)进入注释自动生成系统,选择生成注释的数据源。
1b)如果选择Stack Overflow,则进入1c);选择Linux kernel邮件,则进入1d);选择Linux kernle Commit-log则进入1e)。
1c)按照对问答网站Stack Overflow制定的爬取策略,爬取指定函数讨论的信息并存储,进入1f)。
1d)按照对Linux kernel邮件制定的爬取策略,爬取邮件信息并存储,进入1f)。
1e)按照对Linux kernel Commit-log制定的爬取策略,爬取Commit-log信息并存储,进入1f)。
1f)进行数据预处理。
2)数据预处理,图3是数据预处理流程图,包括:
2a)进入数据预处理,以空行为分隔将数据分成段落,进入2b)。
2b)剔除数据中的HTML标签,进入2c)。
2c)判断数据源类型,如果是Stack Overflow网站数据源,则进入2d);如果是Linux kernel邮件数据源,则进入2e);如果是Linux kernle Commit-log数据源,则进入2f)。
2d)按照过滤规则1,剔除Stack Overflow数据中投票小于1的段落,进入2g)。
2e)按照过滤规则2,剔除邮件特有的不适注释的段落,进入2g)。
2f)按照过滤规则3,剔除Commit-log特有的不适注释的段落,进入2g)。
2g)进行注释提取。
3)按规则生成注释,图4是按规则生成注释流程图,包括:
3a)进入注释提取,按提取规则1提取段落,如果能提取出段落,进入3b),否则进入3e)。
3b)将段落分成句子,则进入3c)。
3c)按提取规则2过滤句子。如果剩余句子,进入3d),否则进入3e)。
3d)展示自动生成的函数注释并存储,进入3e)。
3e)结束。
下面通过实施例对本发明作进一步的说明,但不以任何方式限制本发明的范围。
实施例1
本实施例设定如下使用场景:
使用Stack Overflow网站数据源,应用本方法自动生成对fork()函数的注释。
1)进入注释自动生成系统,选取Stack Overflow数据源,对关键字"linux fork()"进行搜索,爬取所得网页的内容,获取15个话题的对应文本。其中一个话题内容如下:
问题标号:12881111
问题标题:Output offock()calls
问题描述:
What would be the output offollowing fork()call?
fork(){
fork();
fork();
fork()&&fork()||fork();
fork();
Print(“Saikacollection\n”);
Can anyone help me in getting the answer to this code as well as some explanations as i am newto OS?I have found several questions on fork()on SO,but couldn’t figure out.
问题投票数:1
回答1:On succeed execution of a fork()call,new child is created.The process creating the child is called parent process.Fork()call returns pid(process identifier)ofthe child to parent.Fork()returns 0to the child process.
回答1投票:16
回答2:If you want new process to be more independent,you might take a look at exec-*family of funcitons(POSIX)-so you can fork,and then immediately replace the fork process(you can do it,since newly forked process is controlled by you);Or possibly have a look at popen()as well.
回答2投票:0
2)对爬取的数据进行预处理,删除投票小于一的回答段落,得到文本如下:
文本1:What would be the output offollowing fork()call?
fork(){
fork();
fork();
fork()&&fork()||fork();
fork();
Print(“Saikacollection\n”);
Can anyone help me in getting the answer to this code as well as some explanations as i am newto OS?I have found several questions on fork()on SO,but couldn’t figure out.
文本2:On succeed execution of a fork()call,new child is created.The process creating the child is called parent process.Fork()call returns pid(process identifier)ofthe child to parent.Fork()returns 0to the child process.
3)经过规则1的应用,上述步骤中的两段文本将被提取出来作为注释的备选段落;经过规则2的应用,文本1中的句子将被滤除,生成注释如下:
On succeed execution of a fork()call,new child is created.The process creating the child is called parent process.Fork()call returns pid(process identifier)of the child to parent.Fork()returns 0to the child process.
该注释对fork函数的功能、返回值进行了比较全面的描述。
实施例2
本实施例设定如下使用场景:
使用Linux内核邮件为数据源,选取2016年7月16至7月23一段时间的邮件,应用本方法自动生成函数注释。
1)进入注释自动生成系统,选取Linux内核邮件为数据源,爬取该段时间内4493封邮邮件。其中一封标题和正文文本如下:
标题:timer_list:print_tickdevice():calculate->min_delta_ns dynamically
正文:print_tickdevice(),assembling the per-tick device sections in/proc/timer_list,is the last user ofstruct clock_event_device's->min_delta_ns member.
In order to make this one fully obsolete while retaining userspace ABI,calculate the displayed value of'min_delta_ns'on the fly from->min_delta_ticks_adjusted.
Signed-off-by:Nicolai Stange<nicstange@xxxxxxxxx>
---
kernel/time/timer_list.c|5+++--
1file changed,3insertions(+),2deletions(-)
...
2)其中一封邮件经过预处理后得到两段文本,如下:
文本1:print_tickdevice(),assembling the per-tick device sections in/proc/timer_list,is the last user of struct clock_event_device's->min_delta_ns member.
文本2:In order to make this one fully obsolete while retaining userspace ABI,calculate the displayed value of'min_delta_ns'on the fly from->min_delta_ticks_adjusted.
3)经过规则1的应用,上述步骤中的文本1将被提取出来作为注释的备选段落;经过规则2的应用,生成的自动注释如下:
print_tickdevice(),assembling the per-tick device sections in/proc/timer_list,is the last user of struct clock_event_device's->min_delta_ns member.
该注释说明了print_tickdevice()函数的功能和该函数使用了何种数据。
实施例3
本实施例设定如下使用场景:
使用Linux内核Commit-log作为数据源,选取v4.8-rc3与v4.8-rc2两个版本之间的log信息,应用本方自动生成函数注释。
1)进入注释自动生成系统,选取Linux kernel Commit-log为数据源,共爬取136个Commit-log信息。其中一个Commit-log标题和正文的文本如下:
标题:dm raid:enhance attempt_restore_of_faulty_devices()to support more devices
正文:dm raid:enhance attempt_restore_of_faulty_devices()to support more devices
attempt_restore_of_faulty_devices()is limited to 64when it should support the new maximum of 253when identifying any failed devices.It clears any revivable devices via an MD personality hot remove and add cylce to allow for their recovery.
Address by using existing functions to retrieve and update all failed devices'bitfield members in the dm raid superblocks on all RAID devices and check for any devices to clear in it.
Whilst on it,don't call attempt_restore_of_faulty_devices()for any MD personality not providing disk hot add/remove methods(i.e.raid0now),because such personalities don't support reviving offailed disks.
Signed-off-by:Heinz Mauelshagen<heinzm@redhat.com>
Signed-off-by:Mike Snitzer<snitzer@redhat.com>
...
2)上述Commit-log预处理后得到四段文本:
文本1:dmraid:enhance attempt_restore_of_faulty_devices()to support more devices
文本2:attempt_restore_of_faulty_devices()is limited to 64when it should support the new maximum of 253when identifying any failed devices.It clears any revivable devices via an MD personality hot remove and add cylce to allow for their recovery.
文本3:Address by using existing functions to retrieve and update all failed devices'bitfield members in the dm raid superblocks on allRAID devices and check for any devices to clear in it.
文本:4:Whilst on it,don't call attempt_restore_of_faulty_devices()for any MD personality not providing disk hot add/remove methods(i.e.raid0now),because such personalities don't support reviving offailed disks.
3)经过规则1的应用,上述步骤中的文本1、2、3、4将被提取出来作为注释的备选段落;经过规则2的应用,文本4中的句子将被滤除,生成的自动注释如下:
dm raid:enhance attempt_restore_of_faulty_devices()to support more devices
attempt_restore_of_faulty_devices()is limited to 64when it should support the new maximum of 253when identifying any failed devices.It clears any revivable devices via an MD personality hot remove and add cylce to allow for their recovery.
Address by using existing functions to retrieve and update all failed devices'bitfield members in the dm raid superblocks on all RAID devices and check for any devices to clear in it.
该注释说明了attempt_restore_of_faulty_devices()函数在v4.8-rc2升级到v4.8-rc3与版本之后会支持更多的设备。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求所述为准。
- 还没有人留言评论。精彩留言会获得点赞!