一种基于Storm分布式框架的食品安全网络舆情预警系统的制作方法
本发明涉及食品安全大数据处理技术领域,具体而言,提供了一种基于storm分布式框架的食品安全网络舆情预警系统,通过爬取网络媒体的新闻网页,然后从网页文件中提取食品相关舆情信息并将其进行分布式聚类;对每个聚类结果中的舆情信息进行进一步分析以得到每个事件,并获取事件的起源、发展、高潮、结束阶段的相关信息,以达到网络监控的目的。
背景技术:
随着互联网的飞速发展和计算机的广泛普及,世界变得越来越小,网络已经成为人们表达观点、宣泄情绪的一种重要的渠道,人们借助于网络所表达和传播对于事件的各种不同态度、认识和情感的集合便形成了网络舆情。网络舆情态势作为衡量社会舆情动态的实时晴雨表在管理实践和学术研究中显得尤为重要。对于网络舆情做出正确的分析与处理,给出预警阈值以及预警等级,将会给公共事务管理者带来极大的好处,进而对舆情引导和事件治理带来正面并且积极的作用。
网络舆情预警方面的研究主要包括以下三方面:建立预警指标体系。有学者认为网络舆情的发生、发展过程会通过一系列关键指标体现,并将这些指标按照一定的科学方法确定关键指标构成、指标维度、指标层次、指标量化方法等,从而建立预警指标体系。基于情感倾向性分析技术的预警。采用这种方式进行预警的学者认为网络舆情预警能力主要体现在是否能够从海量的网络言论中,发现潜在危机的隐患。这两种方法都在一定程度上解决了网络舆情预警的问题,显然也存在明显的不足之处。一是,在建立预警指标体系方面,确定指标的权重会使指标体系带有强烈的主观色彩,并且必须要等到所有末级指标的数据得到后,才能对目标进行评价,这就导致了研究有极大的主观性和不可靠性。二是,指标体系过于庞大,结果计算复杂导致了错过了最佳预警时机。三是,凭借在网络中搜集到的网民态度倾向性很难对事件做出准确的预警。到目前为止,对情感倾向性分析主要包括“赞同”、“反对”、“中立”三种态度。基于web数据挖掘的预警。web挖掘技术将数据挖掘、人工智能和自然语言处理等技术综合在一起,从网络中自动并且智能地抓取目标事件有关的数据,比如对网络数据进行网页特征提取、基于内容的网页聚类、网络间内容关联规则的发现等。然后构成目标数据集,并且利用相应的工具和技术对挖掘出的数据进行分析、解释,并通过分析结果对网络舆情进行危机预警。
俗话说“民以食为天”,物质生活的富裕,更加促进了人们对健康的追求,食品安全问题作为关系到公共卫生健康的重要问题之一也日益被关注。我国目前建立了相对较完备的食品质量安全技术标准,但对于食品安全的状态评价和安全预警研究并不多。食品安全预警是整个食品安全管理战略的重要组成部分,其主要功能在于对食品安全风险的预防预测。影响食品安全的要素复杂多变,食品安全监管的难度系数也逐年上升,建立有效的食品安全网络舆情预警机制,及时发现安全隐患,对重大安全事件防患于未然是一项迫切任务。
单遍法或单道法(single-pass算法)是流式数据聚类的经典算法,对于依次到达的数据流,该算法按数据输入顺序,每次处理一个数据,对其进行聚类,依据该数据与已有类的数据进行相似度相似度大小计算,将该数据判为已有类或者新形成一个新类。用来进行事件他的提取与追踪。但聚类结果依赖数据的输入顺序,且算法精度不高。
过去的十年是数据处理变革的十年,mapreduce(映射归约)模型、hadoop(海杜普)模型以及一些相关的技术使得我们能处理的数据量比以前要大得多,hadoop已经成为批处理的标准,但是人们对于实时处理的要求越来越高,大规模的实时数据处理已经越来越成为一种业务需求了,数据处理整个生态系统缺少一个“实时版本的hadoop”,而storm的出现填补的这个缺失,所以出现了storm流式处理技术。采用storm分布式框架,完成对海量数据的实时处理,能够对网络舆情预警提供较好的数据支撑。因此从2011年开源以后,storm的高吞吐量、高时效性极大地提高了对大数据的处理。twitter曾经一度用storm实时处理每一个发布者的信息并对twitter发布者的跟随者提供分析,目前依然使用基于stormapi的框架heron。阿里使用storm实时分析用户的属性,并反馈给搜索引擎,每天能处理200万到15亿条日志。支付宝用storm实时统计交易数量、交易金额,每天处理超过6t的数据。
技术实现要素:
一种基于storm分布式框架的食品安全网络舆情预警系统,其特征在于,通过爬取食品相关舆情信息,并进行分布式聚类;分析聚类结果以得到事件信息,判断舆情变化趋势,进而进行监控和预警。
在所述基于storm分布式框架的食品安全网络舆情预警系统中,拓扑结构包括控制节点和工作节点,所述控制节点上包括nimbus组件,所述nimbus组件负责分配工作给工作节点并且监控状态;所述工作节点包括supervisor组件,所述supervisor组件负责监听所辖服务器的工作,根据需要启动/关闭工作进程。
在所述基于storm分布式框架的食品安全网络舆情预警系统中,spout节点从外部数据源读取数据并且随机分发给第一层bolt节点进行计算和处理,bolt节点向外继续发送本身处理后的结果给下一层bolt节点,从而将任务分成多个部分并行处理,任务拓扑在提交后会一直运行,除非显示终止。
在所述基于storm分布式框架的食品安全网络舆情预警系统中,第一层bolt节点对文本进行分词和向量化,采用nlpir汉语分词系统和食品类别表对文本进行分词处理,然后使用tf_idf算法和自编码神经网络进行向量化,实现食品类别判断,对标题和摘要分词后的结果与食品类别表中的词进行对比,对出现频率最高的食品词汇与食品类别表中的子类别进行关联匹配,得出文本在食品类别表中的父类别,作为文本的分类,其中,文本采用向量空间模型的形式来表示如表达式:
d={(t1,w1),(t2,w2),(t3,w3),…,(tn,wn),}
t1、t2、t3…tn为代表文本内容的特征项,w1、w2、w3…wn为对应特征项的权重值,特征项为通过nlpir汉语分词系将文本分词之后,出现在食品类别表中存在的词汇,通过tf-idf算法计算该词汇的权重值。
在所述基于storm分布式框架的食品安全网络舆情预警系统中,将分类后的文本发送到第二层bolt节点,使用余弦相似度算法计算文本之间的距离,形成节点微簇。
在所述基于storm分布式框架的食品安全网络舆情预警系统中,所述事件信息包括事件开始时间、事件地点、事件类别、事件中心内容、事件关键词、事件的舆情变化趋势。
在所述基于storm分布式框架的食品安全网络舆情预警系统中,所述舆情变化趋势包括文本的转发数、评论数、会员数量、非会员数量、文本倾向度、事件变化频率和热度。
在所述基于storm分布式框架的食品安全网络舆情预警系统中,所述文本倾向度通过对文本内容计算得到,其中,倾向度词库分为正向倾向词库、中立倾向词库、反向倾向词库,正向倾向库中的词汇舆情数值为1,个数为pos个;反向倾向库中的词汇舆情数值为-1,个数为neu个;中立倾向库中的词汇舆情数值为0,个数为neg个,则该文本的舆情倾向度y如表达式:
y=(pos*1)+(neu*-1)+(neg*0)
文本倾向判断依据公式:
当舆情倾向度y大于60时,该文本为正向舆情文本;当舆情度小于60时,该文本为负向舆情文本;当舆情度大于-60小于60时,该文本为中立舆情文本。
在所述基于storm分布式框架的食品安全网络舆情预警系统中,构建舆情预警指标体系,引入ahp分析模型,得出各项指标权重,计算每个事件的预警值,通过人工筛选的方法,确定预警等级。
在所述基于storm分布式框架的食品安全网络舆情预警系统中,舆情预警指标体系包括指标:微博数、评论数、转发数、独立用户数、变化活度、情感倾向性。
本发明所提供的基于storm分布式框架的食品安全网络舆情预警系统,实现了基于storm框架的single-pass算法,并对算法进行了改进,由于需要对数据分布式处理,本系统在处理的第一层先对数据先进行分类,将相同类别的数据传到相同的bolt节点,形成事件,大大提高了运算效率,提高了系统的时效性。
附图说明
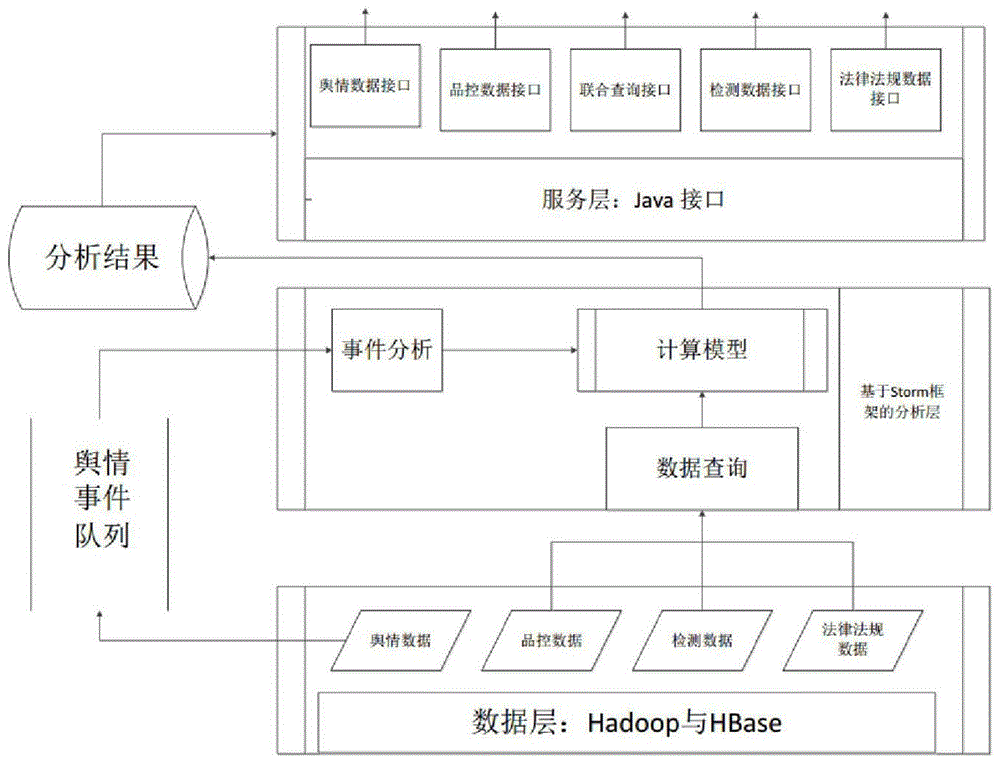
图1是基于storm分布式框架食品安全舆情分析系统设计流程图。
图2是分布式框架拓扑结构图。
图3是食品类别树状图。
图4是边缘文本重处理流程图。
图5是网络舆情预警指标体系图。
图6是网络舆情预警指标权重表。
图7是系统算法运算速度对比图。
图8是系统聚类精度对比图
具体实施方式
本发明提供了一种基于storm分布式框架的食品安全网络舆情预警系统,采用storm的框架与改进的sing-pass算法相结合的方法进行事件识别与追踪。storm是基于hadoop的分布式、高容错的实时计算系统,弥补了hadoop批处理所不能满足的实时要求。本发明实现了基于storm框架的single-pass算法,并对算法进行了适应性改进。为了实现对数据的分布式处理,本发明所提供的系统在处理的第一层先对数据先进行分类,将相同类别的数据传到相同的bolt(处理任务)节点,形成事件,大大提高了运算效率,提高了系统的时效性。所述系统的拓扑结构包括控制节点和工作节点,所述控制节点上包括nimbus组件,所述nimbus组件负责分配工作给工作节点并且监控状态;所述工作节点包括supervisor组件,所述supervisor组件负责监听所辖服务器的工作,根据需要启动/关闭工作进程。该通过spout节点从外部数据源读取数据并且随机分发给第一层bolt节点进行计算和处理,bolt节点向外继续发送本身处理后的结果给下一层bolt节点,从而将任务分成多个部分并行处理,任务拓扑在提交后会一直运行,除非显示终止。第一层bolt节点对文本进行分词和向量化,采用nlpir汉语分词系统和食品类别表对文本进行分词处理,然后使用tf_idf算法和自编码神经网络进行向量化,实现食品类别判断,对标题和摘要分词后的结果与食品类别表中的词进行对比,对出现频率最高的食品词汇与食品类别表中的子类别进行关联匹配,得出文本在食品类别表中的父类别,作为文本的分类。将分类后的文本发送到第二层bolt节点,使用余弦相似度算法计算文本之间的距离,形成节点微簇。将网络爬虫获取的数据进行指标提取,构建指标体系,并引入ahp分析模型,得出各项指标权重,从而计算每个事件的预警值,通过人工筛选的方法,确定预警等级。
具体实施如下:
基于数据开源,通过网络爬虫软件,通过对微博、贴吧、新浪新闻等网络媒体资源进行网络爬虫,将数据存入集群的开源数据库hbase中。通过搜索引擎,例如,elasticsearch从hbase中读取网络舆情文本数据发送给storm分布式舆情分析系统,并将分析结果存入关系型数据库管理系统,例如mysql中,与品控数据、检测数据、法律法规数据等进行关联匹配查询,如图1所示。
舆情数据分析系统采用storm分布式框架进行文本聚类,本系统采用的分布式框架共三层,分布式拓扑结构如图2所示。将从hbase中读取的数据通过第一层的spout(发射任务)节点shufflegrouping(随机分发)分发给第一层的bolt节点。
在第一层bolt节点中,首先要对文本数据进行向量化,即通过对文本数据进行分词和计算权重,将文本形成一个一维的向量,依此来进行文本的聚类。本发明通过中科院分词系统对文本标题和摘要进行分词,对文本数据进行食品类别判断。根据食品分类规则,建立食品类别表,共分为粮食加工品,食用油、油脂及其制品、调味品、肉制品等共28个父类别和小麦粉、大米、酱油、西瓜等共600多子类,如图3所示。对标题和摘要分词后的结果与食品词库中的词进行对比,对确定为食品词汇的词统计其频率n,对出现频率最高的的食品词汇做类别判断。首先将词汇与600多子类别进行关联匹配,在通过子类依次推测出文本的父类别,作为文本的分类。之后对文本用tf_idf算法向量化。在本发明中,文本采用向量空间模型(vsm)的形式来表示,一个文本可以有如下表示形式:
d={(t1,w1),(t2,w2),(t3,w3),…,(t4,w4),}(1)
其中t1、t2、t3…tn为代表文本内容的特征项,w1、w2、w3…wn为对应特征项的权值,特征项为通nlpir汉语分词系将文本分词之后,如果在词库中出现,计算该词权重,权重通过tf-idf算法进行计算,其中,tf为特征词在文本中出现的频率,idf是指逆向文件频率。一个特征词在文本中出现的频率越高,tf数值越大,说明该词的重要性比较大,出现这个特征词在所有文本中占得比重越低,说明该特征词越能代表该文本。因此特征项的权重可以用w=tf*idf来表示:
将第一层bolt节点文本向量化后的数据按照父类别进行modulegrouping(聚类分发)分发到第二层bolt,即相同类别的文本发送到一起,使用余弦相似度算法进行文本聚类,形成事件。使用余弦相似度算法计算文本之间的距离,公式如下;
公式中a、b为两个文本向量,通过计算两个文本向量的夹角余弦值,当余弦值越接近1证明两个文本的距离越小,即说明两个文本属于同一类的可能性越大,当余弦值越接近0,说明两个文本距离越大,即说明两个文本属于同一类的可能性越小。由于计算文本两两之间相似度计算量太大,导致消耗的时间很长,因此在形成的每个类中选择一个与其他文本平均相似度最高的文本作为一个中心文本,之后进入的每个文本都与各类中的中心文本进行相似计算来确定是否属于该类,如果与所有中心文本都达不到阈值t,将会形成新类,并且在类中加入新文本时将会重新计算中心文本。
本发明中提出边缘文本,所谓边缘文本是指在一个类中距离中心文本最远的文本,伴随中心文本的更新变动而变动。本发明通过对边缘文本进行标记,一旦在聚类过程中,边缘文本与中心文本的距离小于阈值t,说明该边缘文本有极大的可能性不属于该类,将对其从原类中删除,并看作一篇新文本重新进行聚类,以此来减少聚类出现错误的概率,如图4所示。
在文本聚类之后,形成事件的过程中,需要提取事件的相关信息。包括事件开始时间、事件地点、事件类别、事件中心内容、事件关键词、事件的舆情变化趋势等。其中事件开始时间为该事件最早文本的时间。事件地点为该事件中所有文本的地点的集合。事件类别为该事件所有文本在第一层bolt节点中文本类别判断后的食品类别。事件中心内容为该事件中心文本的标题和内容。事件的舆情变化趋势包括文本的转发数、评论数、会员数量、非会员数量、文本倾向度、事件变化频率和热度。
本发明文本倾向度需通过对文本内容计算得到。倾向度词库共有三个,分为正向倾向词库、中立倾向词库、反向倾向词库。正向倾向库中的pos词的舆情数值为1,个数为pos个。反向倾向库中的词的舆情数值为-1,个数为neu。中立倾向库中的词舆情倾向为0,个数为neg,则该文本的舆情倾向度为:
y=(pos*1)+(neu*-1)+(neg*0)(5)
文本倾向判断公式
当舆情度大于60时,该文本为正向舆情文本。当舆情度小于60时,该文本为负向舆情文本。当舆情度大于-60小于60时,该文本为中立舆情文本。
舆情预警指标体系:
建立一套完善的舆情指标体系来评估网路舆情预警等级,是一项非常复杂的工作。针对网络舆情产生和发展过程中的各种特点,选取合理的特征变量作为预警指标,这是搭建网络舆情预警系统的基础,所以在创建指标体系时应遵循以下原则:
(1)科学性和完整性:网络舆情跨越情报学、舆论学、计算机科学和传播学等多门学科,选取指标必须反映网络舆情预警的各个方面,符合实际情况,并与所涉及各专业原则相一致;
(2)定量为主,定性为辅:所选择的指标应该尽可能易于量化,因为定量指标比较客观,能反映网络舆情的真实特征,但有些特征也很难量化,只能根据人的经验来判断,通过专家评分来获得定性指标数值,定性和定量相结合,预警指标才更科学合理;
(3)实用性和指导性:各指标为了实际应用的需要应该含义明确、简单适用,能通过有效地途径获得,并且能够反映舆情,给政府和公共事务管理者提供技术支持和决策支持;
(4)最优性和经济性:网络舆情的产生原因和表达方式多种多样,相应指标的选取也会有多种,有些指标之间能够相互替换,所以获取指标的代价应该在适当的范围内,选择最优指标。
在遵循以上原则的基础上,构建的网络舆情预警指标体系如图5所示,且各项指标说明如下:
(1)微博数(weibonum):每个微博用户都可以看做传感器,对事件进行监测[9]。微博数的多少在一定程度上能够反映事件热度。
(2)评论数(commentnum):就如微博数一样,评论数越多代表该事件的事件热度越高、讨论热度越强。
(3)转发数(repostnum):跟评论数类似,转发数越多代表该事件的事件热度越高、讨论热度越强。
(4)独立用户数(uniqueusernum):某些用户可能通过发表评论的形式参与话题的讨论,虽然他发了很多条评论,但这些评论都来自于同一个用户,所以在计算总的微博用户数时,只能够计算独立用户数的多少。
(5)变化活度(activitydegree):舆情事件的讨论活度,以及该活度的变化。
(6)情感倾向性(sentimenttendency):用户本身所包含的情感的分析。微博评论所对应的情感分析均值。
ahp预警模型:
采用传统的层次分析法进行网络舆情预警,步骤如下:
(1)建立层次结构模型
在深入分析问题的基础上,将相关的各个因素从上到下按照不同属性分成若干层次,处在同一层的诸多因素从属于上一层的因素,同时又支配下一层因素。最上层为目标层,在本文中,最下层为对象层有微博数、评论数等6个初级指标,中间为指标层,指的是舆情热度、舆情状态和舆情趋势;
(2)构造成两两比较判断矩阵
首先,根据1-9标度法,对处在同一层指标之间的重要程度进行两两比较,得到量化的判断矩阵a,
aij要素i与要素j重要性比较结果,并且有如下关系:
aij有9种取值,分别为1/9,1/7,1/5,1/3,1/1,3/1,5/1,7/1,9/1,分别表示i要素对于j要素的重要程度由轻到重;
其次,进行一致性检验,如果检验通过,最大特征值对应的特征向量就是权向量,否则需要重新构造判断矩阵;
(3)计算权向量并做一致性检验
计算每一个成对比较矩阵的最大特征根以及对应特向,用一致性指标、随机一致性指标和一致性比率做一致性检验,若通过,则特向归一化后就是权重,否则,重新进行步骤(2);
(4)计算组合权向量并做组合一致性检验
计算6个初级指标的组合权向量,并根据公式做组合一致性检验,若通过,则可按照其结果进行下一步的研究,否则,重新构造一致性比率较大的成对比较阵。
利用ahp方法计算出各项指标权重结果如图6所示。通过公式可以得出每个事件的预警值v。
(其中i=1…6,分别对应weibonum,commentnum,repostnum,uniqueusernum,activitydegree,sentimenttendency)
根据抓取事件的所有预警值分布情况,采用人工筛选的方法,大致设定了五个预警等级。当预警值小于25(v<25)时不达到预警标准,显示星标为灰色;当预警值为25到40之间(25<=v<40)时得到一级预警,图标显示为一颗星;当预警值为40到55之间(40<=v<55)时得到二级预警,图标显示为二颗星;当预警值为55到65之间(55<=v<65)时得到三级预警,图标显示为三颗星;当预警值为65到75之间(65<=v<75)时得到四星预警,图标显示为四颗星;当预警值大于75(v>=75)时得到五星预警,图标显示为五颗星。星级越高表示预警等级越高。
基于以上技术方案,进行实施例和评价分析:
实验环境:硬件环境:集群中共五台服务器,一台nimbus节点,四个supervisor节点。
软件环境:jdk1.7.0_67,apache--0.9.5,apache-maven-3.3.9,myeclipse10,hadoop
2.5.0-cdh5.3.9,zookeeper-3.4.6
操作系统:开发系统为windows7,集群为linux系统。
数据集为贵州大数据研究中心提供的舆情文本数据,共4千万余条,取其中1万条数据进行测试,集群共五台服务器,一台nimbus节点,四个supervisor节点,共16个节点。单机采用传统single-pass算法、集群采用s-single-pass算法测试聚类精度和运算速度。其中集群s-single-pass算法第一层采用spout节点1个,第二层和第三层分别采用等个数的bolt节点,如1、3、5、7个bolt节点进行测试。微簇的数量阈值设为2000,话题数量的阈值设为1000,数量超出后,将最久未更新事件从微簇中删除。spout发送队列等待数量最大10000,计算速度对比如图4所示。
图7所示:节点数为1时,平均运行速度比单机算法速度提高了66%左右,这是因为,此时集群中已启用spout节点一个,第二、三层bolt节点数为1个,实际在3台电脑上启动3个节点。随着第二、三层节点数增加,程序的运行速度越来越快,当第二、三层节点数为5时,实际在4台电脑上启用11个节点,此时程序运行速度最快,较单机运行速度提升了151%左右。程序运行速度整体明显提高。当第二、三层节点数为7时,此时在4台电脑上启用15个节点,此时速度较之前有所降低,吞吐量减少。这是因为当节点启用较多时,电脑负荷过大,服务器之间信息传递缓慢,导致运行速度降低。
为了测试其聚类精度,我们采用nist为tdt建立了完整的评测体系进行评测。该标准综合了系统漏检和误检的性能,评测公式如下:
cdet=cmiss×pmiss×ptarget+cfa×pnon-target(11)
其中cmiss为漏检率代价系数;cfa为误检率代价系数,目前tdt评测分别取1.0和0.1,即漏检率更为重要;pmiss为漏检率,即系统没有检测出关于某的新闻报道数量与该总数的百分比;pfa为误检率,即系统多检测出关于某的新闻报道数量与该总数的百分比;ptarget和pnon-target为先验目标概率,ptarget=0.02,pnon-target=0.98。
为了进一步评价tdt系统性能时常采用cdet的范化表示,即归一化错误识别代价(cdet)nom,其定义如下。
文本相似度计算的阈值t设为0.05时,本发明算法数据如图8所示:这是设置聚类阈值t=0.05时,不同节点数量的s-single-pass算法和单机single-pass算法pmiss、pfa、(cdet)nom三部分数据的比较。可以看出不同节点数量的s-single-pass算法精度几乎相同,虽较单机版single-pass算法精度有所下降,但相差不是很大,在可接受范围内。
应当理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!