一种客户信息处理方法和系统与流程
本发明涉及计算机技术领域,具体涉及一种客户信息处理方法和系统。
背景技术:
客户信息对企业的重要性不言而喻,如果能够充分利用客户信息,向客户提供创新、个性化的客户服务,势必能够提高企业的核心竞争力和市场份额。然而,现有技术中,如果想要获取满足条件的客户信息,都是由人工定期梳理、组织的,不能及时根据业务有效调整目标客户群,无法调动用户的工作积极性,同时由人工梳理组织客户信息也存在过于主观,随意挑选,以及信息遗漏和浪费等问题,严重影响公司业务的发展。
技术实现要素:
本发明提供了一种客户信息处理方法和系统,以解决现有客户信息处理技术中,由人工梳理组织客户信息导致信息处理的主观性、信息容易遗漏和浪费,严重影响公司业务发展的问题。
根据本发明的一个方面,提供了一种客户信息处理方法,其特征在于,获取包含客户信息的客户信息数据库和包含用户信息的用户数据库,所述客户信息至少包括客户唯一标识,客户名称和历史订单信息,所述用户信息至少包括用户唯一标识和用户姓名;
方法包括:
根据业务特性从客户信息数据库中获取多条客户信息得到一个或多个客户信息集,以及从用户数据库中获取多条用户信息;
按照预设分配规则将每一客户信息集中的客户信息分配给获取到的用户,建立客户信息与用户之间的对应关系;
将用户对应的客户信息展示在交互界面上,供用户查看和/或操作。
根据本发明的另一个方面,提供了一种客户信息处理系统,该系统包括客户信息数据库、用户数据库和客户信息处理装置;
所述客户信息数据库,用于存储客户信息,所述客户信息至少包括客户唯一标识,客户名称和历史订单信息;
所述用户数据库,用于存储用户信息,所述用户信息至少包括用户唯一标识和用户姓名;
所述客户信息处理装置包括:
数据库访问模块,用于根据业务特性从客户信息数据库中获取多条客户信息得到一个或多个客户信息集,以及用于从用户数据库中获取多条用户信息;
关系建立模块,用于按照预设分配规则将每一客户信息集中的客户信息分配给获取到的用户,建立客户信息与用户之间的对应关系;
展示模块,用于将用户对应的客户信息展示在交互界面上,供用户查看和/或操作。
本发明的有益效果是:相对现有技术,本发明实施例的技术方案通过获取客户信息数据库和用户数据库,然后根据业务特性从客户信息数据库中获取多条客户信息得到一个或多个客户信息集,以及从用户数据库中获取多条用户信息,再按照分配规则将每一客户信息集中的客户信息分配给获取到的用户,建立客户信息与用户之间的对应关系,最后,将用户对应的客户信息显示在交互界面上供用户查看和/或操作,一方面,能够根据业务特性选取客户信息,从而能够把具有相同或相似特征的客户信息聚集在一起,作为目标客户群,提高客户信息的利用率。另一方面,避免了人工梳理和组织客户信息导致的主观性强、数据遗漏和浪费等问题,有效提高客户服务水平和企业的经济效益。
附图说明
图1是本发明一个实施例的一种客户信息处理方法的流程图;
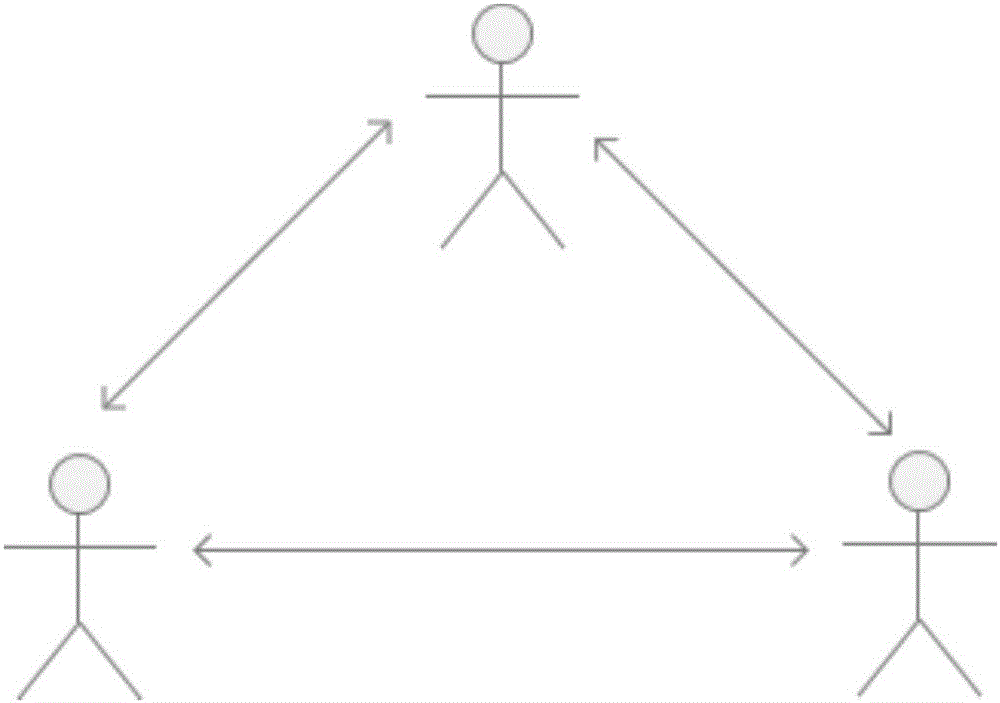
图2是本发明一个实施例的一种用户网状关系结构示意图;
图3是本发明一个实施例的一种客户信息处理系统的结构框图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
实施例一
图1是本发明一个实施例的一种客户信息处理方法的流程图,参见图1,该客户信息处理方法包括如下步骤:
步骤S101,获取包含客户信息的客户信息数据库和包含用户信息的用户数据库,所述客户信息至少包括客户唯一标识,客户名称和历史订单信息,所述用户信息至少包括用户唯一标识和用户姓名;
步骤S102,根据业务特性从客户信息数据库中获取多条客户信息得到一个或多个客户信息集,以及从用户数据库中获取多条用户信息;
步骤S103,按照预设分配规则将每一客户信息集中的客户信息分配给获取到的用户,建立客户信息与用户之间的对应关系;
步骤S104,将用户对应的客户信息展示在交互界面上,供用户查看和/或操作。
由图1所示的方法可知,本实施例中按照业务特性从至少包括客户的客户唯一标识,客户名称和历史订单信息的客户信息数据库中筛选得到一批客户信息,将这些客户信息分配给从用户数据库中筛选出来的用户,建立用户和客户信息之间的对应关系,然后将用户对应的客户信息展示出来供用户查看和/或操作,从而能够根据实际应用中的业务特性需要组织客户信息,将客户信息分配给筛选出的用户,充分提高客户信息的利用率以及用户的工作积极性,提高企业对客户的服务水平,提升企业竞争力。
实施例二
本实施例中以外呼业务为例对本发明客户信息处理方法的实现步骤进行说明。
外呼是企业员工借助企业客户管理服务系统主动发起对客户的呼叫,以达到预定目标。
现有技术中,外呼业务的实现是人工去梳理、组织客户信息形成客户信息集,数据在员工之间是线性分配,主观性较大,容易导致客户信息遗漏和浪费,客户信息利用率低,严重影响公司业务的发展。
为了解决上述技术问题,本发明实施例提供了新的客户信息信息处理方法,该客户信息处理方法主要包括四个步骤:
步骤(一)获取客户信息,形成客户信息集;
步骤(二)获取用户信息;
步骤(三)将客户信息分配给用户;
步骤(四)解除客户信息和用户的分配关系;
以下分别进行说明。
步骤(一)获取客户信息,形成客户信息集;
本实施例中,根据业务特性从客户信息数据库中获取多条客户信息得到一个或多个客户信息集,这里的客户信息数据库中的数据来源于企业系统数据库如数据库DB1(企业在生产经营活动中会记录一些客户历史信息保存到数据库DB1里)。具体实现时,客户信息数据库与企业系统数据库做数据库关联DBlink,在客户信息数据库中通过DBlink,操作系统数据库DB1,例如以客户编号为关联关系取出客户信息、客户订购商品信息及客户所属区域信息,存放于客户信息数据库中。此做法的目的是减少对系统数据库的频繁操作,减轻系统数据库的压力,由于客户信息数据库专用于当前系统,所以压力较小,同时提高数据筛选和展示的效率。
将所需的客户信息保存到客户信息数据库中之后,本实施例的方法可以在客户信息数据库中筛选客户信息,用于分配。
具体的筛选方式示意如下:在客户信息数据库操作页面,输入查询条件,按条件查询需要的数据。例如,查询条件为:客户编号、年龄(N岁至M岁)、性别、区域(省、市、县)、购买商品名称、购买商品品类、订单金额、购买次数等。查询结果即为符合条件的客户信息数量。
本实施例中,在根据业务特性在客户信息库中筛选满足查询条件的客户信息,得到当前客户信息集后,进一步判断当前客户信息集中是否存在与已有客户信息集中客户信息重复的客户信息,如果存在,则将重复的客户信息从当前客户信息集中删除。具体的,若部分客户信息与已有客户信息集中的客户信息数据重复,则列出该客户信息集名称、重复客户信息数量,可分配客户数量(若客户信息部分数据已被分配给用户,且用户对数据已使用,则可分配数量=重复客户信息数量-已被使用客户数量);将剩余不重复客户信息虚拟到一个临时客户信息集,列出该客户信息集名称、重复客户信息数量,可分配数量。用户可以根据情况把相关客户信息集中的客户信息分配到新的客户信息集,并且当分配了上述重复客户数据后,也可以把此客户信息从已有客户信息集中删除。
举例而言,按客户等级条件查询后得到客户数量为10000条,将这一批客户信息和已有客户信息集进行比较,如果有5000条重复的客户信息,则可导入的客户信息只有10000-5000=5000(条),形成虚拟客户信息集A。并且,重复的这5000条客户信息也可能分布在不同的客户信息集中,例如,与客户信息集B中重复的数据量为3000条,与客户信息集C中重复的数据量为2000条,其中100条已被用户使用。其查询的结果是A、B、C三个客户信息集,本实施例中以列表形式列出。A、B的重复客户数分别为5000、3000,可导入数量分别为5000、3000。C重复客户数为2000,可导入数量为1900=2000-100。对这三个客户信息集进行导入操作后,形成新的客户信息集,客户信息数量为9900。B客户信息集删除掉3000客户信息,C客户信息集删除掉1900客户信息,完成本次客户筛选操作。另外,本实施例的方法还可以将查询出的结果以列表的形式展现,例如,展现如下字段:客户信息集名称、总客户信息数量、可分配的客户信息数量。
步骤(二)获取用户信息;
本步骤中主要介绍用户信息的获取,本实施例的方法还需要维护用户数据库,用户数据库中存储用户信息,用户信息至少包括用户唯一标识和用户姓名。
本实施例中,用户数据库按照树形结构存储用户信息,每个用户节点既可作为父节点又可作为子节点。即,以树形结构组织用户关系,每个用户可以归属于多个结点,各用户之间产生网状结构关系。
图2是本发明一个实施例的一种用户网状关系结构示意图,参见图2,不同与现有技术的用户线状关系结构,本实施例的方法中提供了一种用户网状关系结构,网状关系结构是客户信息分配的基础,为达到客户信息在用户之间纵向分配与横向流动,同一个用户可以同时属于多结点下,形成用户关系网。用户信息采用父子关系存放于用户数据库,以便有规则地取出及展现。
步骤(三)将客户信息分配给用户;
本实施例中按照预设分配规则将每一客户信息集中的客户信息分配给获取到的用户,建立客户信息与用户之间的对应关系包括:
按照如下分配规则中的一种或多种组合将每一客户信息集中的客户信息分配给获取到的用户:平均分配规则;补足分配规则;奖励分配规则。注,在分配客户信息时,可同步形成分配历史记录。
对每个客户信息集或客户信息集中每个客户信息分配时,可指定本次客户信息分配数量(例如,小于等于未分配客户信息总数量)、分配方式(平均分配、补足分配、奖励分配)、接收分配的用户,进行客户信息均衡分配。
接收分配用户按树形结构组织,可以逐级分配或跳级选择用户进行分配,以达到灵活分配的目的。例如,为当前用户分配了对应的客户信息后,当前用户可以把自己名下全部或部分客户信息下分到下属用户,也可以全部或部分转分给平级用户,以供下属用户或平级用户查看和/或操作。
逐级分配,用户在接收到分配的客户信息后,自动形成工作任务,工作任务下是接下到的客户信息。当前用户结点下还有子结点,该用户可以再行分配。例如,将当前客户信息集中的500条客户信息分配给层级较高的用户(如,张一),由该层级较高的用户将500条客户信息分配给该用户下一级的用户(如,张二、张三、张四),进一步的,下一级用户还可以将分到自己名下的客户信息逐级分配。跳级选择用户分配,例如,将当前客户信息集中的500条客户信息不分配给层级较高的用户,而是直接分配给层级较高的用户的下一级用户,或下下一级用户,或者同级的其他用户,以达到灵活分配客户信息。将现有固化的线性数据流动方式转变为灵活的网状流动方式,客户信息在用户之间以网状方式流动,且网结点可随时配置,灵活、可控,提高了用户工作的积极性。
这里的平均分配规则是指:指定用户,把一定量的客户信息平均分配给指定的用户。平均分配时采用随机读取客户信息,并把客户信息随机分配给用户,具体读取策略是在客户信息数据库的数据表中从上而下读取,不进行任何条件的排序。同时用户同样是在用户数据库的数据表中从上而下的读取。
若遇到客户信息数量无法整除以用户数量时,本实施例提供了一种优化算法,即:设待分配的客户量为C,用户数为S,C除以S值为R,C模S值为N,则前(S-N)个用户接收客户信息数量为R,后N个用户接收客户信息数量为R+1。本实施例中为每个用户设置可接收客户信息数量的最大值,若用户已有客户信息数量+R大于设定的最大值,多出的客户信息数量可分配分到其它用户名下,因此,优选地,本实施例中先处理当前已分配客户信息数量达到设定的最大值的用户的情况,超出最大值的剩余客户信息按照上述算法再继续分配给其他用户。
补足分配规则是指:指定接收信息的用户,当未分配的客户信息数量不足时,展示提示信息给用户,并补足分配客户信息给用户。也就是说,每个用户对应设定有客户信息拥有量最大值,当用户的客户信息拥有量不足上限时,补足分配规则即填充差量,若当前待分配客户信息数量不足以填充所有用户差量时,提示用户并不与分配。若当前待分配客户量大于所有用户差量总和时,多出的客户信息不与分配。具体算法如下:差量=最大值-当前值,需分配量=差量*用户数,如果需分配量小于待分配客户信息数量时,提示用户待分配客户信息数量不足,停止分配。如果待分配量大于等于需分配量时,每个用户补足差量,多余的待分配客户信息不与分配。
奖励分配规则是指:设置用户接收客户信息的数量,如果没有设置客户信息数量,则将按照平均分配规则,将一批客户信息分配给用户。
注:当同一个客户信息被多次分配给当前用户时,可只形成一条工作任务,而形成多条分配历史。客户信息一旦分给下一个用户,当前用户名下不再拥有此客户信息,即,解除客户信息与当前用户的对应关系。
需要说明的是,本实施例中,在建立客户信息与用户之间对应关系时会同步生成分配历史,客户信息分配后产生分配痕迹,即,分配历史供查找已分配客户信息,若遇到错误分配的情况,可以在从分配历史中找到错误发生的结点,进行回溯追踪,将已分配的客户信息从被分配用户名下解除到上一用户结点。
此外,本实施例,还可以按照优先拔打规则分配常规客户信息,分配后,该客户信息集客户信息排在拔打队列的最前面,进行优先拔打。优先拨打是对以上三种分配规则的补充,只需在分配时为客户信息添加“优先拨打”标记。
步骤(四)解除客户信息和用户的分配关系;
本实施例中,还可根据用户输入的解除指令解除客户信息与用户之间的对应关系;或,根据已分配给用户的客户信息的状态与预设解除条件的比较结果,当客户信息的状态满足预设解除条件时解除客户信息与用户之间的对应关系;将解除关系后的客户信息保存到客户信息解除集中;记录关系解除之前客户信息所属的客户信息集以及关系解除时间,得到关系解除历史记录。这里的,客户信息解除集包括用户指定的客户信息集(包括原客户信息集)或预设客户信息集。
具体的,解除客户信息和用户的分配关系分为根据用户指令的解除和自动解除。
根据用户指令的解除,分为管理员解除和非管理员解除,管理员解除可以指定解除到当前客户信息集中,可以指定解除到其它已存在客户信息集中,也可以指定解除到新建的客户信息解除集中(填写客户信息解除集名称)。若在客户信息集展现列表页面中作解除操作,可以指定需要解除的客户信息。一旦解除到其它客户信息集中,当前客户信息集中不再包括此条客户信息。非管理员解除的权限比管理员解除的权限小。客户信息与用户的分配关系解除后,被解除的用户名下不再有被解除的客户信息。解除属性可包括:解除类型(如,解除到已存在客户信息集或新客户信息集)、客户信息集名称、解除方式等。
需要强调的是,本实施例中在执行解除操作时,可将被解除客户信息回流到解除用户名下。
自动解除是指:定时监测已分配客户信息的状态,将这些状态预设解除条件进行比较,如果满足解除条件,则自动解除客户信息和用户的对应关系。
举例而言,可以自客户信息分配到用户名下起开始计时,当累计时间达到预设时间阈值时该条客户信息的状态仍为未处理,则自动解除该条客户信息和当前用户的对应关系。或者,判断用户是否离职,当用户已离职时,自动解除将该离职用户名下所有的客户信息的对应关系。或者,判断当前客户信息的状态是否被标记为预约解除,是则,自动解除将该条客户信息与用户的对应关系。
注,自动解除操作可定期执行,如每月执行五次,则可在每月的第一天创建新的客户信息集,新客户信息集的名称为指定内容+当前时间(年月日,格式为yyyy-MM-dd)。然后每月执行自动解除时,查找是否存在本周期内的待解除客户信息,如果存在,则将该客户信息存放到新建的以指定内容+时间命名的客户信息集中。另外,解除操作可以当前客户信息集主键值与被解除用户主键值为联合条件进行查找,或以被解除用户作为主键值,查找被解除客户信息,然后将解除后的客户信息更新到其他用户名下或新客户信息集中。
本实施例中,在解除时可形成解除历史记录。解除历史记录可包括如下字段:客户信息集名称、分配数量、分配时间、解除数量、解除时间。并且可通过解除历史列表展示当前用户名下的客户信息的分配历史,解除历史记录的作用在于解除客户信息后,能够通过解除历史记录再次有针对性将客户信息分配给最合适的用户。
至此,本实施例的客户信息处理方法,按照业务特性从客户信息数据库中筛选得到一批客户信息得到客户信息集,并从用户数据库中筛选得到多条用户信息,将这些客户信息分配给筛选出的用户,建立用户和客户信息之间的对应关系,由于,客户信息数据库中存储的客户信息中,都记录有客户的历史订单信息,因此,可以按照商品品类进行查询,将具有相同或相近购物偏好的客户信息筛选出来,并把筛选出来的客户信息作为一个客户信息集合。
举例而言,在客户信息数据库中,以化妆品这一商品品类为查询条件,可将购买过化妆品的客户的信息筛选出来,更具体的,可以某一品牌的化妆品为查询关键词,从而缩小查询范围,实现客户信息的精准查找和聚类。
然后,将查找到的目标客户信息,展示给用户,方便用户对客户信息进行查看和/或操作,这里的操作,例如,可以按照客户信息进行拨打电话,并针对该条客户信息,记录拨打电话后的反馈信息。如此,实现了对相同或相近购物偏好的客户信息进行聚类,提高了客户信息的利用率和服务水平,提升企业的竞争力。
实施例三
图3是本发明一个实施例的一种客户信息处理系统的结构框图,参见图3,客户信息处理系统300,包括客户信息数据库301、用户数据库303和客户信息处理装置302;
所述客户信息数据库301,用于存储客户信息,所述客户信息至少包括客户唯一标识,客户名称和历史订单信息;
所述用户数据库303,用于存储用户信息,所述用户信息至少包括用户唯一标识和用户姓名;
所述客户信息处理装置302包括:
数据库访问模块,用于根据业务特性从客户信息数据库中获取多条客户信息得到一个或多个客户信息集,以及用于从用户数据库中获取多条用户信息;
关系建立模块,用于按照预设分配规则将每一客户信息集中的客户信息分配给获取到的用户,建立客户信息与用户之间的对应关系;
展示模块,用于将用户对应的客户信息展示在交互界面上,供用户查看和/或操作。
在本发明的一个实施例中,客户信息处理装置302还包括:关系解除模块,用于根据用户输入的解除指令解除客户信息与用户之间的对应关系;
或,根据已分配给用户的客户信息的状态与预设解除条件的比较结果,当客户信息的状态满足预设解除条件时解除客户信息与用户之间的对应关系;将解除关系后的客户信息保存到客户信息解除集中。这里的,客户信息解除集包括用户指定的客户信息集(包括原客户信息集)或预设客户信息集。
本实施例中,关系解除模块,还用于记录关系解除之前客户信息所属的客户信息集以及关系解除时间,得到关系解除历史记录。
本实施例中,数据库访问模块,具体用于根据业务特性在客户信息库中筛选满足查询条件的客户信息,得到当前客户信息集,判断当前客户信息集中是否存在与已有客户信息集中客户信息重复的客户信息,如果存在,则将重复的客户信息从当前客户信息集中删除。
具体的,若部分客户信息与已有客户信息集中的客户信息数据重复,则列出该客户信息集名称、重复客户信息数量,可分配客户数量(若客户信息部分数据已被分配给用户,且用户对数据已使用,则可分配数量=重复客户信息数量-已被使用客户数量);将剩余不重复客户信息虚拟到一个临时客户信息集,列出该客户信息集名称、重复客户信息数量,可分配数量。用户可以根据情况把相关客户信息集中的客户信息分配到新的客户信息集,并且当分配了上述重复客户数据后,也可以把此客户信息从已有客户信息集中删除。
本实施例中,关系建立模块具体用于按照如下分配规则中的一种或多种组合将每一客户信息集中的客户信息分配给获取到的用户:
平均分配规则;
补足分配规则;
奖励分配规则。
另外,本实施例中,用户数据库按照树形结构存储用户信息,每个用户既作为父节点又作为子节点。
需要说明的是,本实施例中客户信息处理装置的各个功能模块的工作过程是和前述客户信息处理方法实施例中的步骤相对应的,因此,本实施例中对客户信息处理装置的工作过程的未尽事项可参见前述方法实施例的描述,这里不再重复说明。
综上所述,本发明实施例的客户信息处理方法和系统,通过获取客户信息数据库和用户数据库,然后根据业务特性从客户信息数据库中获取多条客户信息得到一个或多个客户信息集以及从用户数据库中获取多条用户信息,再按照分配规则将每一客户信息集中的客户信息分配给用户,建立客户信息与用户之间的对应关系,最后,将用户对应的客户信息显示在交互界面上供用户查看和/或操作。与现有技术相比:一方面,能够根据业务特性选取客户信息,从而能够对具有相同或相似特征的客户信息聚类作为目标客户群,提高客户信息的利用率。另一方面,避免了人工梳理和组织客户信息导致的主观性强、数据遗漏和浪费等问题,有效提高了服务水平。
以上所述,仅为本发明的具体实施方式,在本发明的上述教导下,本领域技术人员可以在上述实施例的基础上进行其他的改进或变形。本领域技术人员应该明白,上述的具体描述只是更好的解释本发明的目的,本发明的保护范围以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!