基于拟牛顿法在线训练神经网络的FPGA系统及实现方法与流程
本发明涉及FPGA的加速设计领域,具体涉及一种基于拟牛顿法在线训练神经网络的FPGA系统及实现方法。
背景技术:
神经网络是一种信息处理系统,其具有从一组数据中学习任意输入输出关系的能力。训练是确立神经网络结构的关键一步。传统的离线训练方式存在以下问题:1)如果样本数据是时变的,则无法准确捕捉输入输出间关系。2)如果对全部样本进行训练,则训练速度迟缓并且可能陷入局部最优(如文献[1])。因此近年来神经网络与在线训练方式结合,已在信号处理、语音识别、序列预测(如文献[2])等领域获得了广泛的应用。
目前,神经网络的在线训练主要在软件平台实现。但软件实现方法速度慢且并行度低,从而无法满足神经网络在线训练的要求,导致理论研究与实际应用相脱节(如文献[3])。除此之外,软件实现需要庞大的计算机作支持,所以不适合嵌入式场合。所以,必须寻求一种硬件实现的方法,提高处理速度。
GPU是广泛认可的可选择的加速器之一,然而它的高功耗是嵌入式应用的致命弱点(如文献[4])。而FPGA器件具有可重配置、高并行度、设计灵活(相对于ASIC)、能耗低(相对于GPU)的特性(如文献[5]),更适宜实现应用于嵌入式场合的神经网络。目前已有一些基于FPGA实现神经网络的研究。如文献[6],基于FPGA实现递归神经网络(RNN)算法变体的优化和加速,并用于分析服务器上的语言模式分类任务。如文献[7],基于FPGA实现了多层感知神经网络(MLP-NN)的加速,其采用简单的反向传播学习算法。
技术实现要素:
本发明的目的在于克服上述现有技术的不足,从神经网络的训练方法—拟牛 顿法出发,通过FPGA实现来提高神经网络训练的速度,满足神经网络在线训练的实时性要求。
本发明的技术方案:基于拟牛顿法在线训练神经网络的FPGA系统,包括计算控制模块CSC、随机数产生模块PNG、线性搜索模块LS、梯度计算模块GC、矩阵更新模块HU和神经网络评估模块NNE六大模块;
所述计算控制模块CSC采用有限状态机的形式来安排上述各模块的操作顺序及内存与相对应模块的数据传递;
所述线性搜索模块LS、梯度计算模块GC、矩阵更新模块HU对应于拟牛顿优化算法的计算过程,神经网络评估模块NNE将被线性搜索模块LS调用;
所述矩阵更新模块HU以BFGS方式更新矩阵并决定搜索方向,所述线性搜索模块LS采用黄金分割法在搜索方向上确定搜索步长,所述梯度计算模块GC完成目标函数梯度的计算,所述随机数产生模块PNG基于32位线性移位寄存器产生神经网络的初始权重值。
本发明的另一技术方案:基于拟牛顿法在线训练神经网络的FPGA实现方法,包括以下步骤:
1)、分析拟牛顿法的c++代码,将算法划分为三个计算模块,分别为梯度计算模块GC、矩阵更新模块HU和线性搜索模块LS,通过编写Verilog,将每个计算模块实现为硬件块;
2)、根据神经网络的拓扑结构、训练方式和激励函数,通过编写Verilog确立神经网络评估模块NNE的硬件结构;
3)、基于32位线性移位寄存器实现随机数产生模块PNG,该模块用于产生神经网络的初始权重值;
4)、将FPGA片上存储器用作缓冲器以链接上述五个硬件模块,并存储中间的计算结果,采用有限状态机的形式安排上述五个模块的操作顺序及内存与相对应 模块的数据传递;该模块被命名为计算控制模块CSC;
5)、将上述硬件设计在Net-FPGA SUME(xc7vx690t)开发板上综合实现,就资源利用率、运行时间和功率消耗这三方面,对该硬件设计进行性能测试。
所述步骤1)矩阵更新模块HU以BFGS方式更新矩阵并决定搜索方向,线性搜索模块LS采用黄金分割法在搜索方向上确定搜索步长,梯度计算模块GC完成目标函数梯度的计算。
所述步骤1)每个模块内,采用流水线技术和模块复用技术。
所述步骤1)硬件块架构根据模块中涉及的操作来定制。
所述步骤2)硬件结构分为前端和后端两个部分;前端用于计算神经网络的实际输出,后端用于计算神经网络的训练误差。
所述步骤2)神经网络评估模块NNE被线性搜索模块LS和梯度计算模块GC调用。
本发明相对于现有技术有以下有益效果:
本发明提出了一种基于拟牛顿法在线训练神经网络的FPGA实现方法,通过Xilinx Vivado 2014.04,将提出的硬件设计在Net-FPGA SUME(xc7vx690t)开发板上综合实现,优点如下:
1)该设计可达到的最高频率为250MHz;2)除Block Ram外,FPGA上的FF、LUT和DSP资源不受神经网络结构影响;而现在的FPGA包含大量片上存储资源,使设计具有可扩展性;3)相比于软件实现,该设计可达到105倍的加速,可满足神经网络在线训练的实时需求;4)相比于软件实现,该设计的动态功耗可减小12倍。
附图说明
图1是本发明基于拟牛顿法在线训练神经网络的FPGA的硬件架构框图;
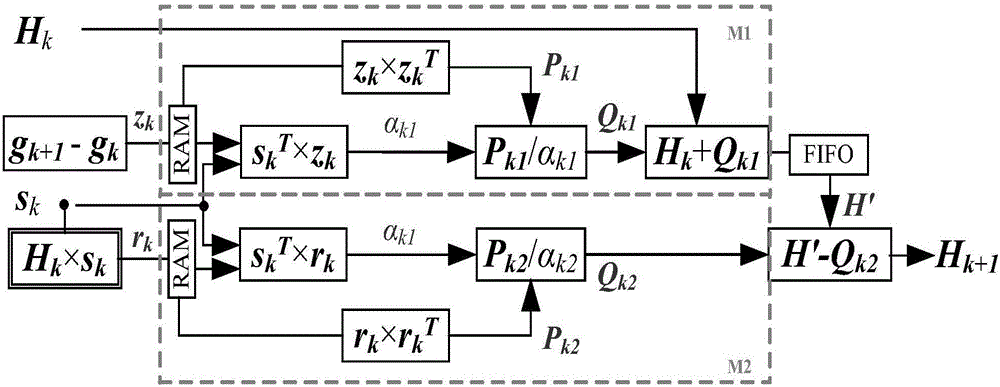
图2是本发明矩阵更新模块(HU)的内部数据流;
图3是本发明梯度计算模块(GC)的硬件结构图;
图4是本发明线性搜索模块(LS)的内部结构图;
图5是本发明神经网络评估模块(NNE)的硬件结构图。
图6是本发明的方法流程图。
具体实施方式
下面通过具体实施例和附图对本发明作进一步的说明。本发明的实施例是为了更好地使本领域的技术人员更好地理解本发明,并不对本发明作任何的限制。
如图1所示,基于拟牛顿法在线训练神经网络的FPGA系统,包括计算控制模块CSC、随机数产生模块PNG、线性搜索模块LS、梯度计算模块GC、矩阵更新模块HU和神经网络模块NNE六大模块;
所述计算控制模块CSC采用有限状态机的形式来安排上述各模块的操作顺序及内存与相对应模块的数据传递;
所述线性搜索模块LS、梯度计算模块GC、矩阵更新模块HU对应于拟牛顿优化算法的计算过程,神经网络评估模块NNE将被线性搜索模块LS调用;
所述矩阵更新模块HU以BFGS方式更新矩阵并决定搜索方向,所述线性搜索模块LS采用黄金分割法在搜索方向上确定搜索步长,所述梯度计算模块GC完成目标函数梯度的计算,所述随机数产生模块PNG基于32位线性移位寄存器产生神经网络的初始权重值。
如图6所示,基于拟牛顿法在线训练神经网络的FPGA实现方法,包括以下步骤:
1)、分析拟牛顿法的c++代码,将算法划分为三个计算模块,分别为梯度计算模块GC、矩阵更新模块HU和线性搜索模块LS,通过编写Verilog,将每个计算模块实现为硬件块;矩阵更新模块HU以BFGS方式更新矩阵并决定搜索方向,线性搜索模块LS采用黄金分割法在搜索方向上确定搜索步长,梯度计算模块GC完成目标函数梯度的计算;每个模块内,采用流水线技术和模块复用技术;硬 件块架构根据模块中涉及的操作来定制;
2)、根据神经网络的拓扑结构、训练方式和激励函数,通过编写Verilog确立神经网络评估模块NNE的硬件结构;硬件结构分为前端和后端两个部分;前端用于计算神经网络的实际输出,后端用于计算神经网络的训练误差;
3)、基于32位线性移位寄存器实现随机数产生模块PNG,该模块用于产生神经网络的初始权重值;
4)、将FPGA片上存储器用作缓冲器以链接上述五个硬件模块,并存储中间的计算结果,采用有限状态机的形式安排上述五个模块的操作顺序及内存与相对应模块的数据传递;该模块被命名为计算控制模块CSC;
5)、将上述硬件设计在Net-FPGA SUME(xc7vx690t)开发板上综合实现,就资源利用率、运行时间和功率消耗这三方面,对该硬件设计进行性能测试。
本发明采用经典的三层神经网络。该网络的结构参数如下:输入层有N1个神经元,向量为x=[x1,…,xi,…,xN1],隐含层有N2个神经元,隐含层向量为h=[h1,…,hj,…,hN2],输出层有N3个神经元,输出层向量为z=[z1,…,zl,…,zN3],其中i,j,l分别为第i个输入神经元,第j个隐含层神经元和第l个输出层神经元;输入层与隐含层之间的权值向量为隐含层与输出层之间的权值向量为则该神经网络的权值向量为
神经网络训练是指从足够多的输入样本,通过一定算法调整网络权值,使网络的实际输出z与预期值相符。神经网络的标准误差函数为:
其中,
其中,|ST|指训练数据对的个数,xm和分别指第m组元素个数为N1和N2的向量,分别代表神经网络输入值和理想输出值。是的第l个元素,zl(xm,w)是神经网络对应于输入xm的第l个输出,和分别是训练数据中理想输出的最大值和最小值,F(hj)为隐含层神经元的激励函数。神经网络的训练问题可转化为求解最优化问题,形式如下:
求解该问题的流行算法有最速下降法、共轭梯度法、拟牛顿法和信赖域方法等。其中拟牛顿法以收敛速度快的特点而倍受欢迎。BFGS算法是目前求解无约束优化问题的最流行的也是最有效的拟牛顿算法,其步骤如下:
算法1(BFGS算法)设函数ET由(1)给出,选取初始点w0∈Rn,若||g0||=0,算法终止;否则,选取初始矩阵B0(B0=I),I为单位矩阵,置k:=0。
步骤1由黄金分割法f(wk+λkdk)=minλ≥0f(wk+λkdk),计算搜索步长λk,其中dk为搜索方向;
步骤2置wk+1:=wk+λkdk,若||gk+1||=0,算法终止;否则,转步骤3;
步骤3置sk:=wk+1-wk,yk:=gk+1-gk,dk:=-Bkgk;
步骤4置k:=k+1,转步骤1。
其中,wk为神经网络权重值,λk为搜索步长,dk为搜索方向,gk是训练误差ET关于wk的导数,Bk是BFGS算法的更新矩阵,sk为两次迭代权重的差值,yk为两次迭代梯度的差值,k指第k次迭代。
上述算法1中的步骤2用于计算公式(1)关于wk的梯度,其计算过程具体如下:
输出神经元的梯度可表示为:
由等式(6)得到的输出误差δlm向后传播可得到隐含层神经元的梯度,隐含层神经元的梯度由下式推导得到:
其中c′是常数,δjm是隐含层神经元的误差,F′(hjm)是sigmoid函数F(hjm)的导数,可由F′(hjm)=F(hjm)(1-F(hjm))得到,其具有较少的计算量并利于硬件实现。黄金分割算法的步骤如下:
算法2(黄金分割法)给定初始搜索区间和精度要求ε>0,若b0-a0<ε,那么算法终止,输出
步骤1置u0=a0+0.382(b0-a0),v0=a0+0.618(b0-a0),计算ET(u0),ET(v0)。置k:=0;
步骤2若ET(uk)>ET(vk),则转步骤3;否则转步骤4;
步骤3若bk-uk<ε,则算法终止,输出λ*:=vk;否则置ak+1:=uk,bk+1:=bk,uk+1:=vk,ET(uk+1):=ET(vk),计算vk+1=ak+1+0.618(bk+1-ak+1)和ET(vk+1),转步骤5;
步骤4若vk-ak<ε,则算法终止,输出λ*:=uk;否则置ak+1:=ak,bk+1:=vk,vk+1:=uk,ET(vk+1):=ET(uk),计算uk+1=ak+1+0.382(bk+1-ak+1)和ET(uk+1),转步骤5;
步骤5置k:=k+1,转步骤2。
将上述BFGS拟牛顿算法映射为硬件架构,共六大模块,如图1所示。算法1中的步骤1、步骤2、步骤3分别对应于线性搜索模块(LS)、梯度计算模块(GC)、矩阵更新模块(HU)。公式(1)至公式(3)对应于神经网络评估模块(NNE), 该模块将被线性搜索模块(LS)调用。除上述计算模块外,还有随机数产生模块(PNG)和计算控制模块(CSC)。随机数产生模块(PNG)基于32位线性移位寄存器产生神经网络的初始权重值w0。计算控制模块(CSC)采用有限状态机的形式来安排所有模块的操作顺序及内存与相对应模块的数据传递。下文将结合附图对四大计算模块(HU、LS、GC、NNE)的设计做详细介绍。
矩阵更新模块(HU)根据算法1中的步骤3得到一个新的矩阵并确定搜索方向,其内部数据流如图2所示。图中箭头上字母表示的是一个数值(αk1,αk2)/向量(rk,zk)/矩阵(Hk,Pk1,Pk2,Qk1,Qk2,H’),而这些值是由该箭头始端方框内的运算得到的。计算最密集的操作是矩阵向量乘(Hk×sk),如双线框所示。为实现可扩展性,矩阵向量乘以逐行的向量乘运算来实现。由图2可见,虚线框中的顶层块(M1)和底层块(M2)对称,因此两块共用同一个硬件资源。特别地,M1与矩阵向量乘同时运算,M2在M1与矩阵向量乘运算结束后开始操作。FIFO用于暂存顶层块(M1)的计算结果H′并等待底层块(M2)完成操作。该模块的电路设计采用IP复用技术,通过Xilinx Vivado软件中IP Catalog调用Float-Point(单浮点IP核,包括浮点加法器、减法器、乘法器、除法器)和Block Memory Generator(存储器IP核,选用双端口Ram)。电路内部采用有限状态机,通过状态的转换来控制每步数据的读入、读出和存储。
梯度计算模块(GC)对应于算法1中的步骤2,具体计算过程对应于公式(6)至公式(7),其结构如图3所示。每组训练集的输入值(hjm,F(hjm),ET_temp)由神经网络评估模块(NNE)计算得到。当新的输入值可用时,仅用一个减法器就可首先得到输出神经元的误差δlm,同时用一个减法器和一个乘法器计算隐含层神经元输出的梯度F’(hjm)。一旦得到输出神经元误差后,开始向后传播计算。左侧累加单元用于实现输出层权重与误差的乘累加,即其结果与对应的F’(hjm)依次相乘得到隐含神经元的误差δjm。右侧两个乘累加单元对不同训练集对产生的神经元误差进行乘累加,分别得到等式(6)中的和 等式(7)中的
线性搜索模块(LS)对应于算法1中的步骤1,采用黄金分割法计算迭代步长。黄金分割法的具体操作对应于算法2,该模块的结构图如图4所示,其由一系列算数操作和比较操作组成。该模块计算量小但控制复杂,通过sel0-1信号来确定数据的传输通路。为减少资源,该模块的乘法器和加法器采用复用技术。该模块在计算过程中,会多次调用神经网络评估模块(NNE)。
神经网络评估模块(NNE)计算人工神经网络的训练误差,分为前端和后端两部分。前端用于计算神经网络的实际输出,对应于公式(2)至公式(4),结构如图5(b)所示。两个累加单元分别用于得到输出层和隐含层神经元的输出。在加法器的输入和输出端口间添加一个由若干个触发器组成的可变移位寄存器,以确保神经元间的正确累加。为加速神经网络的计算过程,前端结构采用若干组处理单元。后端用于计算训练误差,对应于公式(1),结构如图5(a)所示。来自前端模块的结果得到后,后端模块开始计算。一个多路选择器逐次选择每组神经网络实际输出,与对应神经网络理论输出相减。然后通过点积运算实现平方和的操作。
下面对该硬件架构进行测试,下文对测试方法进行介绍:
根据设计的硬件结构,在Xilinx Vivado 2014.04上编写RTL代码并综合实现,再下载到Net-FPGA SUME(xc7vx690tffg1761-3)开发板上进行板级调试。该硬件设计可达到的最高时钟频率为250MHz,关键路径为指数浮点IP核的最高时钟频率。就硬件设计的资源利用率、加速比和功耗三方面,本发明进行了性能评估。
资源利用率:由Xilinx Vivado综合实现后得到。
运行时间:软件实现选用来自于CSDN的开源的拟牛顿C++算法,在i5-4590 CPU的Microsoft Visual studio 2013上编译。对于不同的神经网络结构和训练集数,采用拟牛顿优化算法的单次迭代平均时间作为软硬件运行时间的衡量标准。将软件实现时间与硬件实现时间相除可得到加速比。
功率消耗:该实验中FPGA开发板和PC主板的供电电压均为12V。两个实现平台的供电电流由Tektronix TCP0030电流钳测得,并通过MS04054混合信号示波器观察。将电压乘以电流即可得到功耗。
应当理解的是,这里所讨论的实施方案及实例只是为了说明,对本领域技术人员来说,可以加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
相关文献:
[1]王健伟,宋执环.基于嵌入式系统的神经网络在线训练平台实现[J].传感器与微系统,2010,29(8):100-103.
[2]P.Antonik;F.Duport;M.Hermans;A.Smerieri;M.Haelterman;S.Massar,"Online Training of an Opto-Electronic Reservoir Computer Applied to Real-Time Channel Equalization,"in IEEE Transactions on Neural Networks and Learning Systems,vol.PP,no.99,pp.1-13
[3]Kim C M,Choi K H,Cho Y B.Hardware design of CMAC neural network for control applications[C]//International Joint Conference on Neural Networks.IEEE,2003:953-958vol.2.
[4]Y.Ma,N.Suda,Y.Cao,J.s.Seo,and S.Vrudhula,“Scalable and modularized rtl compilation of convolutional neural networks onto fpga,”in 2016 26th International Conference on Field Programmable Logic and Applications(FPL),Aug 2016,pp.1–8.
[5]E.Nurvitadhi,J.Sim,D.Sheffield,A.Mishra,S.Krishnan,and D.Marr,“Accelerating recurrent neural networks in analytics servers:Comparison of fpga,cpu,gpu,and asic,”in 2016 26th International Conference on Field Programmable Logic and Applications(FPL),Aug 2016,pp.1–4.
[6]E.Nurvitadhi,J.Sim,D.Sheffield,A.Mishra,S.Krishnan,and D. Marr,“Accelerating recurrent neural networks in analytics servers:Comparison of fpga,cpu,gpu,and asic,”in 2016 26th International Conference on Field Programmable Logic and Applications(FPL),Aug 2016,pp.1–4.
[7]F.Ortega-Zamorano,J.M.Jerez,and L.Franco,“FPGA implementation of the C-mantec neural network constructive algorithm,”IEEE Transactions on Industrial Informatics,vol.10,no.2,pp.1154–1161,May 2014.
- 还没有人留言评论。精彩留言会获得点赞!