一种驾驶员情绪识别方法和装置与流程
本发明涉及汽车智能交互技术领域,尤其涉及一种驾驶员情绪识别方法和装置。
背景技术:
随着汽车的全球化普及以及汽车智能化的起步,人类对于汽车良好体验的需求,使得人们希望汽车越来越懂自己,并且可以根据自己的性格与状态定制对应的服务内容,人们希望汽车知道自己是谁,懂得自己的情感与需求,希望汽车在自己需要服务的时候主动提供服务。这样对于车内人员的情绪识别与身份识别将会起到一个非常重要的作用,让车可以更好的理解人以及提供更人性化与准确的服务。
在汽车驾驶中,行驶安全最为重要,但大多数的交通事故都是人为因素导致的,而车内人员的情绪则是导致人为交通事故的重要原因。在行车过程中,由于长途的驾驶容易导致驾驶员疲劳困倦,而堵车、糟糕的路况以及其它的车辆也会导致车内人员的愤怒等不良情绪。因此有必要对车内人员的情绪进行识别,以便防止可能出现的交通事故。
现阶段的车内人员的情绪识别一般是通过单一的方式进行识别,然而,单一的情绪识别方法无法达到准确识别车内人员情绪以及身份的效果,且单一方法在情绪识别所获取的数据有限,判断机制单一,故存在识别的准确度低、误差大和容易受外界因素影响等问题。
技术实现要素:
鉴于上述问题,提出了本发明以便提供一种至少解决上述问题的驾驶员情绪识别方法和装置。
依据本发明的一个方面,提供一种驾驶员情绪识别方法,包括:
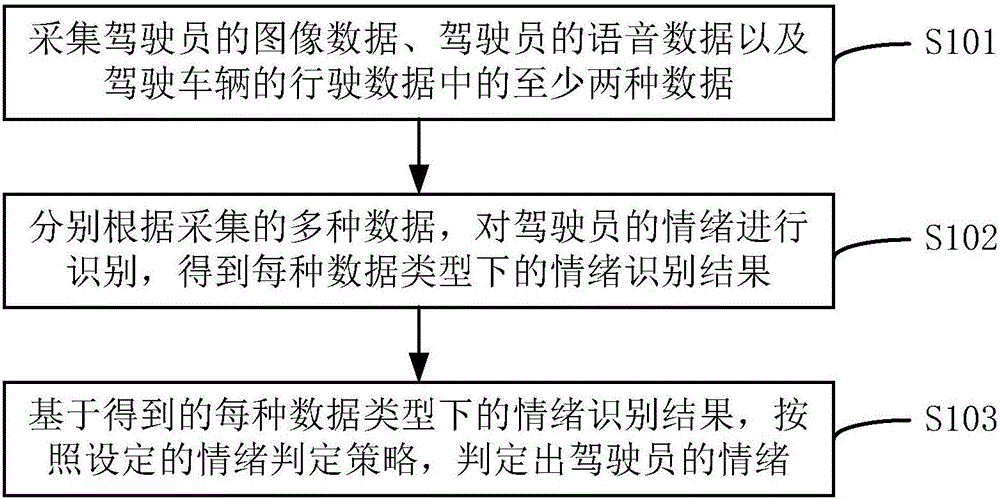
采集驾驶员的图像数据、驾驶员的语音数据以及驾驶车辆的行驶数据中的至少两种数据;
分别根据采集的多种数据,对驾驶员的情绪进行识别,得到每种数据类型下的情绪识别结果;
基于得到的每种数据类型下的情绪识别结果,按照设定的情绪判定策略,判定出驾驶员的情绪。
可选地,本发明所述方法中,所述情绪识别结果包括:识别出的情绪类型及识别出该情绪类型的置信度。
可选地,本发明所述方法中,所述基于得到的每种数据类型下的情绪识别结果,按照设定的情绪判定策略,判定出驾驶员的情绪,包括:
当至少两个情绪识别结果中的情绪类型相同且置信度分别大于等于设定的对应数据类型的第一情绪置信度阈值时,将所述至少两个情绪识别结果中的情绪类型作为最终识别出的驾驶员的情绪;
当各情绪识别结果中存在一个情绪识别结果的情绪类型的置信度大于等于设定的对应数据类型的第二情绪置信度阈值时,将该情绪识别结果中的情绪类型作为最终识别出的驾驶员的情绪;
其中,同一数据类型下的第一情绪置信度阈值小于第二情绪置信度阈值。
可选地,本发明所述方法中,所述判定出驾驶员的情绪之后,还包括:根据预设的情绪类型的置信度与情绪类型级别的对应关系,得到最终识别出的驾驶员的情绪的情绪级别。
可选地,本发明所述方法中,所述根据语音数据,对驾驶员的情绪进行识别,具体包括:提取语音数据中的声纹特征、以及识别所述语音数据中的语义,根据所述声纹特征和所述语义,对驾驶员的情绪进行识别。
可选地,本发明所述方法还包括:
当采集到图像数据或者语音数据时,根据所述图像数据或者语音数据,识别出驾驶员的身份;当采集到图像数据和语音数据时,分别根据所述图像数据和语音数据,对驾驶员的身份进行识别,得到两种数据类型下的两个身份识别结果,并基于得到的两个身份识别结果,按照设定的身份判定策略,判定出驾驶员的身份。
可选地,本发明所述方法中,所述身份识别结果包括:识别出的用户及识别出该用户的置信度;
所述基于得到的两个身份识别结果,按照设定的身份判定策略,判定出驾驶员的身份,包括:
当两个身份识别结果中识别出的用户相同且置信度分别大于等于设定的对应数据类型的第一身份置信度阈值时,以共同识别出的用户作为最终的用户身份识别结果;
当两个身份识别结果中有一个身份识别结果中识别出的用户的置信度大于等于设定的对应数据类型的第二身份置信度阈值时,以用户的置信度大于等于第二置信度身份阈值对应的用户,作为最终的用户身份识别结果;
其中,同一数据类型下的第一身份置信度阈值小于第二身份置信度阈值。
可选地,本发明所述方法还包括:
利用得到的驾驶员的身份,在预先建立的各用户行为习惯模型中匹配出与该驾驶员对应的用户行为习惯模型,并将驾驶员的情绪信息输入到匹配的用户行为习惯模型中,以对驾驶员的状态和/或行为进行预判,并根据预判结果,主动提供与预判结果相匹配的服务。
可选地,本发明所述方法中,所述根据预判结果,主动提供与预判结果相匹配的服务,具体包括:
确定与所述预判结果相匹配的服务,向用户发出是否需要所述服务的询问,并在确定出用户需要时,向用户提供所述服务。
可选地,本发明所述方法中,向用户提供的与预判结果相匹配的服务,包括:内容服务和/或设备状态控制服务;所述设备状态控制服务包括:控制所述智能语音设备和/或与所述智能语音设备连接的设备到目标状态。
依据本发明的一个方面,提供一种驾驶员情绪识别装置,包括:
信息采集模块,用于采集驾驶员的图像数据、驾驶员的语音数据以及驾驶车辆的行驶数据中的至少两种数据;
情绪识别模块,用于分别根据采集的多种数据,对驾驶员的情绪进行识别,得到每种数据类型下的情绪识别结果;
情绪判定模块,用于基于得到的每种数据类型下的情绪识别结果,按照设定的情绪判定策略,判定出驾驶员的情绪。
可选地,本发明所述装置中,所述情绪识别结果包括:识别出的情绪类型及识别出该情绪类型的置信度。
可选地,本发明所述装置中,所述情绪判定模块,具体用于当至少两个情绪识别结果中的情绪类型相同且置信度分别大于等于设定的对应数据类型的第一情绪置信度阈值时,将所述至少两个情绪识别结果中的情绪类型作为最终识别出的驾驶员的情绪;当各情绪识别结果中存在一个情绪识别结果的情绪类型的置信度大于等于设定的对应数据类型的第二情绪置信度阈值时,将该情绪识别结果中的情绪类型作为最终识别出的驾驶员的情绪;其中,同一数据类型下的第一情绪置信度阈值小于第二情绪置信度阈值。
可选地,本发明所述装置中,情绪判定模块,还用于在判定出驾驶员的情绪之后,根据预设的情绪类型的置信度与情绪类型级别的对应关系,得到最终识别出的驾驶员的情绪的情绪级别。
可选地,本发明所述装置中,所述情绪识别模块,具体用于在根据采集的语音数据对驾驶员的情绪进行识别时,提取语音数据中的声纹特征、以及识别所述语音数据中的语义,根据所述声纹特征和所述语义,对驾驶员的情绪进行识别。
可选地,本发明所述装置,还包括:
身份识别模块,用于当所述信息采集模块采集到图像数据或者语音数据时,根据所述图像数据或者语音数据,识别出驾驶员的身份;当所述信息采集模块采集到图像数据和语音数据时,分别根据所述图像数据和语音数据,对驾驶员的身份进行识别,得到两种数据类型下的两个身份识别结果;
身份判定模块,用于当所述身份识别模块得到一种数据类型下的身份识别结果时,直接以该结果作为识别出的驾驶员的身份;当所述身份识别模块得到两种数据类型下的两个身份识别结果时,基于得到的两个身份识别结果,按照设定的身份判定策略,判定出驾驶员的身份。
可选地,本发明所述装置中,所述身份识别结果包括:识别出的用户及识别出该用户的置信度;
所述身份判定模块,具体用于当两个身份识别结果中识别出的用户相同且置信度分别大于等于设定的对应数据类型的第一身份置信度阈值时,以共同识别出的用户作为最终的用户身份识别结果;当两个身份识别结果中有一个身份识别结果中识别出的用户的置信度大于等于设定的对应数据类型的第二身份置信度阈值时,以用户的置信度大于等于第二置信度身份阈值对应的用户,作为最终的用户身份识别结果,其中,同一数据类型下的第一身份置信度阈值小于第二身份置信度阈值。
可选地,本发明所述装置还包括:
服务推荐模块,用于利用得到的驾驶员的身份,在预先建立的各用户行为习惯模型中匹配出与该驾驶员对应的用户行为习惯模型,并将驾驶员的情绪信息输入到匹配的用户行为习惯模型中,以对驾驶员的状态和/或行为进行预判,并根据预判结果,主动提供与预判结果相匹配的服务。
可选地,本发明所述装置中,所述服务推荐模块,具体用于确定与所述预判结果相匹配的服务,向用户发出是否需要所述服务的询问,并在确定出用户需要时,向用户提供所述服务。
可选地,本发明所述装置中,向用户提供的与预判结果相匹配的服务,包括:内容服务和/或设备状态控制服务;所述设备状态控制服务包括:控制所述智能语音设备和/或与所述智能语音设备连接的设备到目标状态。
本发明有益效果如下:
首先,本发明可分别根据图像数据、语音数据和车辆行驶数据中的至少两种进行情绪识别,并根据得到的多个情绪识别结果综合判断驾驶员的情绪状态,这种情绪状态识别方式不会受单一的道路状况、车辆状况、面部特征和语音特征等影响,识别出的驾驶员的情绪更加符合实际的驾驶员情绪状态,提高了情绪识别的准确性及环境适应性。
其次,本发明还可以分别根据图像数据和语音数据进行驾驶员的身份识别,并根据得到的两个身份识别结果综合判断驾驶员的身份,提高了身份识别的准确性和环境适应性;
第三,本发明还可以根据识别的驾驶员的情绪和身份,进行主动的服务推荐,提高了用户的使用体验。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1为本发明第一实施例提供的一种驾驶员情绪识别方法的流程图;
图2为本发明第三实施例提供的一种驾驶员情绪识别装置的结构框图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
本发明实施例提供一种驾驶员情绪识别方法和装置,本发明通过语音数据、图像数据和驾驶车辆的行驶数据中的至少两种,对驾驶员的情绪进行识别,并根据识别的多个结果进行综合性的判断,使得识别的驾驶员的情绪更加符合实际的驾驶员的情绪状态,而不会受单一的道路状况、车辆状况、面部特征和语音特征等影响,能更加准确的识别出车内人员的情绪。所以,本发明提出的情绪识别方案环境适应性更强,可以适合更多环境中的驾驶员的情绪识别。下面就通过几个具体实施例对本发明的具体实施过程进行详细阐述。
在本发明的第一实施例中,提供一种驾驶员情绪识别方法,如图1所示,包括如下步骤:
步骤S101,采集驾驶员的图像数据、驾驶员的语音数据以及驾驶车辆的行驶数据中的至少两种数据;
步骤S102,分别根据采集的多种数据,对驾驶员的情绪进行识别,得到每种数据类型下的情绪识别结果;
步骤S103,基于得到的每种数据类型下的情绪识别结果,按照设定的情绪判定策略,判定出驾驶员的情绪。
基于上述原理阐述,下面给出几个具体及优选实施方式,用以细化和优化本发明所述方法的功能,以使本发明方案的实施更方便,准确。需要说明的是,在不冲突的情况下,如下特征可以互相任意组合。
本发明实施例中,所述的情绪识别结果包括:识别出的情绪类型及识别出该情绪类型的置信度。其中,情绪类型包括但不限于为:高兴、伤心、愤怒、厌烦、疲劳、激动和正常。
进一步地,本发明实施例中,通过布设在车内外的设备传感器采集驾驶车辆的行驶数据,所述设备传感器可以包括至少以下一种或几种传感器的组合:加速度传感器、速度传感器、红外传感器、角速度传感器、激光测距传感器、超声波传感器等。根据车辆上布设的这些传感器获取的信息,就可以得到当前车辆的姿态信息、当前车况信息、当前路况信息、驾驶时长、车辆驾驶轨迹信息等,从而根据以上车辆的行驶数据进行驾驶员的情绪状态判断。
在本发明的一个具体实施例中,根据驾驶车辆的行驶数据对驾驶员的情绪进行识别,包括:从所述相关行驶数据中提取相关行驶特征,根据相关行驶特征在预设的分类器中进行分类,根据所述分类器中的分类结果识别与所述相关行驶特征相对应的驾驶员情绪,最后给出对应的识别置信度。具体的,本发明实施例中,采集预设时间内汽车行驶中的训练行驶信息,并从所述训练行驶信息中提取训练行驶特征;获取针对不同训练行驶特征标注的不同驾驶员情绪,并基于预设的分类算法对不同训练行驶特征标注的不同驾驶员情绪进行学习、训练,形成预设的分类器。
进一步的,本发明实施例中,通过图像采集装置,如摄像头,采集驾驶员的图像数据。在本发明的一个具体实施例中,根据采集的图像数据,对驾驶员的情绪进行识别,包括:在先需要进行人脸的离线训练,所述离线训练使用人脸的数据库训练人脸的检测器、同时在人脸上标定标记点,根据所述人脸标记点训练标记点拟合器,并且,通过人脸标记点和情绪的关系训练情绪分类器。当进行人脸的在线运行时(即需要根据图像数据进行情绪识别时),通过人脸检测器在图像数据中检测人脸,然后通过标记点拟合器拟合人脸上的标记点,情绪分类器根据人脸标记点判断当前驾驶员的情绪,最后给出对应的分类置信度。本发明实施例中个,基于图像的情绪识别的置信度为情绪分类器根据获取的面部图像中的人脸标记点而得到的用户面部表情与在先情绪训练得到的用户在不同情绪类型下的面部表情模型进行匹配的匹配度,当匹配度(即置信度)达到一定的阈值,判定为识别出用户的情绪类型,例如,若匹配的结果为90%(置信度)以上的检测结果为“愉悦”,则认为“此用户为愉悦”。
进一步的,本发明实施例中,通过音频采集装置,如麦克风,采集驾驶员的声音数据。在本发明的一个具体实施例中,根据采集的语音数据,对驾驶员的情绪进行识别,包括:在先需要进行人声的离线训练,所述人声的离线训练,使用语音数据库训练人声检测器,同时训练语音特征向量提取模型用于从人声中提取特征向量的声音,采用已标定好的语音特征向量以及情绪的训练集训练情绪分类器。当进行人声的在线运行时(即需要根据语音数据进行情绪识别时),通过人声检测器在输入的声音流中检测人声数据,并从人声数据中提取语音特征向量,最后使用情绪分类器从语音特征向量分辨当前用户的情绪,并给出识别的置信度。可选地,本发明实施例中,还对所述语音数据中的语义进行识别。当根据语音特征向量进行情绪识别时,可以结合语义识别结果,进行综合识别判断,得到基于语音数据的最终识别结果。本实施例中,基于语音的情绪识别的置信度为情绪分类器将获取的语音数据中的语音特征向量与在先已训练好的用户在不同情绪类型下的语音向量模型进行匹配的匹配度,当匹配度大于设定的阈值时,判定出用户的情绪,例如,若匹配的结果为80%(置信度)以上的检测结果为“愉悦”,则认为“此用户为愉悦”。
进一步的,本发明实施例中,为了根据不同数据类型得到的识别结果进行驾驶员的情绪判定,要预先按照数据类型,进行情绪置信度阈值的设定。具体的,设定与图像数据类型相对应的第一情绪置信度阈值、设定与语音数据类型相对应的第一情绪置信度阈值、以及设定与行驶数据类型相对应的第一情绪置信度阈值。其中,不同数据类型下的第一情绪置信度阈值可以相同,也可以不同,具体值可根据需求灵活设定。
对此,本发明实施例中,基于得到的每种数据类型下的情绪识别结果,按照设定的情绪判定策略,判定出驾驶员的情绪,具体包括:
检测是否至少两个情绪识别结果中的情绪类型相同且置信度分别大于等于设定的对应数据类型的第一情绪置信度阈值,并在是的情况下,将所述至少两个情绪识别结果中的情绪类型作为最终识别出的驾驶员的情绪;
可选地,本发明实施例中,可以设定每个数据类型下的第一情绪置信度阈值为两个等级,即第一等级下的情绪置信度阈值P1和第二等级下的情绪置信度阈值P2,其中,同一数据类型下的P2大于P1。第一等级的阈值P1用于三种类型数据下识别结果的判断,第二等级的阈值P2用于两种数据类型下识别结果的判断。具体的,当得到三种数据类型下的三个情绪识别结果时,如果三个情绪识别结果的情绪类型相同,且对应的置信度均大于对应的第一等级下的阈值P1,则以三个情绪识别结果识别出的情绪类型作为最终识别出的驾驶员的情绪。当得到至少两种数据类型下的至少两个情绪识别结果时,如果有两个情绪识别结果的情绪类型相同,且对应的置信度均大于对应的第二等级下的阈值P2,则直接以这两个情绪识别结果识别出的情绪类型作为最终识别出的驾驶员的情绪。
进一步地,考虑到有些情况下,基于某种数据类型的识别置信度很高,具有很高的可信性,此时,可以直接利用置信度很高的数据类型对应的识别结果作为最终的识别结果,具体实现时,可检测各情绪识别结果中是否存在一个情绪识别结果的情绪类型的置信度大于等于设定的对应数据类型的第二情绪置信度阈值,并在是的情况下,将该情绪识别结果中的情绪类型作为最终识别出的驾驶员的情绪。其中,同一数据类型下的第一情绪置信度阈值小于第二情绪置信度阈值。
下面通过具体示例,对上述提出的情绪判定过程进行解释说明:
本示例中,设定基于语音数据的情绪识别置信度阈值为70%、基于图像数据的情绪识别置信度阈值为80%、基于行驶数据的情绪识别置信度为60%,则:
当基于语音数据识别出的情绪类型为激动,且情绪识别置信度为“70%”以上、基于图像数据识别出的情绪类型为激动,且情绪识别置信度为“80%”以上、且基于行驶数据识别出的情绪类型为激动,且情绪识别置信度为:“60%”以上,则判断出此用户“情绪为激动”。
本示例中,还可以进一步进行阈值设定,例如设定基于语音数据的情绪识别置信度阈值为80%、基于图像数据的情绪识别置信度为85%、基于行驶数据的情绪识别置信度为75%;则:
当基于语音数据识别出的情绪类型为激动,且情绪识别置信度为“80%”以上、基于图像数据识别出的情绪类型为激动,且情绪识别置信度为“85%”以上,则直接判断出此用户“情绪为激动”。或者,当基于语音数据识别出的情绪类型为激动,且情绪识别置信度为“80%”以上、基于行驶数据的情绪识别结果为激动,且情绪识别置信度为“75%”以上,则直接判断出此用户“情绪为激动”。或者,当基于图像数据识别出的情绪类型为激动,且情绪识别置信度为“85%”以上、基于行驶数据的情绪识别结果为激动,且情绪识别置信度为“75%”以上,则直接判断出此用户“情绪为激动”。
本示例中,还可以进一步进行阈值设定,例如设定基于语音数据的情绪识别置信度阈值为95%、基于图像数据的情绪识别置信度为98%、基于行驶数据的情绪识别置信度为90%,则:
当基于语音数据识别出的情绪类型为激动,且情绪识别置信度为“95%”以上、则直接判断出此用户“情绪为激动”。或者,基于行驶数据的情绪识别结果为激动,且情绪识别置信度为“90%”以上,则直接判断出此用户“情绪为激动”。或者,基于图像数据识别出的情绪类型为激动,且情绪识别置信度为“98%”以上,则直接判断出此用户“情绪为激动”。
需要指出的是,在根据置信度阈值进行判断时,如果出现判断结果冲突的情况,则丢弃当前识别结果,继续根据实时采集的数据进行判断。例如,当基于语音数据的情绪识别结果为激动且置信度为95%、而基于图像数据的情绪识别结果为高兴且置信度为98%,此时,需要丢弃当前识别结果,继续进行判断。
进一步地,本发明实施例中,在判定出驾驶员的情绪之后,还包括:根据预设的情绪类型的置信度与情绪类型级别的对应关系,得到最终识别出的驾驶员的情绪的情绪级别。具体的,本实施例中,可以预先建立识别出的情绪类型的置信度与该情绪类型级别的对应关系,并在得到多个情绪识别结果时,根据识别结果中的识别置信度,匹配当前情绪类型的情绪级别(例如:激动、非常激动等)。
综上可知,本发明实施例通过至少两种类型的数据对驾驶员的情绪进行综合识别判断,提高了情绪识别的稳定性和准确度,提升了用户的使用体验。
在本发明的第二实施例中,提供一种驾驶员情绪识别方法,继续如图1所示,包括如下步骤:
步骤S101,采集驾驶员的图像数据、驾驶员的语音数据以及驾驶车辆的行驶数据中的至少两种数据;
步骤S102,分别根据采集的多种数据,对驾驶员的情绪进行识别,得到每种数据类型下的情绪识别结果;
步骤S103,基于得到的每种数据类型下的情绪识别结果,按照设定的情绪判定策略,判定出驾驶员的情绪。
本发明实施例中,情绪识别及判定过程与第一实施例相同,在此不再赘述。
本发明实施例中,在进行情绪识别的同时还进行驾驶员的身份识别,具体如下:
当采集到图像数据或者语音数据时,根据所述图像数据或者语音数据,识别出驾驶员的身份;
当采集到图像数据和语音数据时,分别根据所述图像数据和语音数据,对驾驶员的身份进行识别,得到两种数据类型下的两个身份识别结果,并基于得到的两个身份识别结果,按照设定的身份判定策略,判定出驾驶员的身份。
本发明实施例中,所述的身份识别结果包括:识别出的用户及识别出该用户的置信度。
进一步地,本发明实施例中,通过图像采集装置,如摄像头,采集驾驶员的图像数据。在本发明的一个具体实施例中,根据采集的图像数据,对驾驶员的身份进行识别,包括:在先需要进行人脸的离线训练,所述离线训练使用人脸的数据库训练人脸的检测器、同时在人脸上标定标记点,根据所述人脸标记点训练标记点拟合器,并且,通过人脸标记点和身份的关系训练身份分类器;当进行人脸的在线运行时,通过人脸检测器在图像数据中检测人脸,然后通过标记点拟合器拟合人脸上的标记点,身份分类器根据人脸标记点判断当前驾驶员的身份,最后给出对应的分类置信度。本实施例中,基于图像的身份识别的置信度为身份分类器将获取的面部图像中的人脸标记点与在先训练的已知身份的人脸标记点进行匹配的匹配度,当匹配度(即置信度)达到一定的阈值,判定为识别出用户身份,例如,若匹配度为85%(置信度)以上的检测结果为用户A,则认为“此用户为用户A”。
进一步的,本发明实施例中,通过音频采集装置,如麦克风,采集驾驶员的声音数据。在本发明的一个具体实施例中,根据采集的语音数据,对驾驶员的身份进行识别,包括:在先需要进行人声的离线训练,所述人声的离线训练,使用语音数据库训练人声检测器,同时训练语音特征向量提取模型用于从人声中提取特征向量的声音,采用已标定好的语音特征向量以及身份的训练集训练身份分类器。当进行人声的在线运行时,通过人声检测器在输入的声音流中检测人声数据,并从人声数据中提取语音特征向量,最后使用身份分类器从语音特征向量分辨当前用户的身份,并给出识别的置信度。本实施例中,基于语音的身份识别的置信度为身份分类器将获取的语音数据中的语音特征向量与在先已训练好的已知用户的语音向量模型进行匹配的匹配度,当匹配度大于设定的阈值时,判定出用户的身份,例如,若匹配的结果为85%(置信度)以上的检测结果为用户A,则认为“此用户为用户A”。
进一步地,本发明实施例中,当采集到图像数据和语音数据时,为了根据两种数据类型得到的识别结果进行驾驶员的身份判定,要预先按照数据类型,进行身份置信度阈值的设定。具体的,设定与图像数据类型相对应的第一身份置信度阈值以及设定与语音数据类型相对应的第一身份置信度阈值。其中,不同数据类型下的第一情绪置信度阈值可以相同,也可以不同,具体值可根据需求灵活设定。
对此,本发明实施例中,基于得到的两个身份识别结果,按照设定的身份判定策略,判定出驾驶员的身份,包括:
当两个身份识别结果中识别出的用户相同且置信度分别大于等于设定的对应数据类型的第一身份置信度阈值时,以共同识别出的用户作为最终的用户身份识别结果;
当两个身份识别结果中有一个身份识别结果中识别出的用户的置信度大于等于设定的对应数据类型的第二身份置信度阈值时,以用户的置信度大于等于第二置信度身份阈值对应的用户,作为最终的用户身份识别结果;
其中,同一数据类型下的第一身份置信度阈值小于第二身份置信度阈值。
下面通过一个具体示例,对上述提出的身份判定过程进行解释说明:
本示例中,设定基于语音数据的身份识别置信度阈值为85%,基于图像数据的身份识别置信度阈值为90%,则:当基于语音数据识别出的身份为用户A,且身份识别置信度为85%以上,基于图像数据识别出的身份为用户A,且身份识别置信度为90%以上,则判断出此用户为用户A。
本示例中,还可以进一步进行阈值设定,例如设定基于语音数据的身份识别置信度阈值为95%,基于图像数据的身份识别置信度阈值为98%,则:当基于语音数据识别出的身份为用户A,且身份识别置信度为95%以上,则直接判断出驾驶员身份为用户A;或者,当基于图像数据识别出的身份为用户A,且身份识别置信度为98%,则直接判断出驾驶员身份为用户A。
综上可知,语音、图像的置信度需要同时大于第一阈值,认为是用户A;或者,语音和图像的置信度需要至少有一个大于第二阈值,则认为是用户A,其中第二阈值大于第一阈值。
在本发明的一个较佳实施例中,在确定出驾驶员的身份后,还包括:将识别的身份和情绪信息发送到大数据推荐引擎,由大数据推荐引擎利用得到的驾驶员的身份,在预先建立的各用户行为习惯模型中匹配出与该驾驶员对应的用户行为习惯模型,并将驾驶员的情绪信息输入到匹配的用户行为习惯模型中,以对驾驶员的状态和/或行为进行预判,并根据预判结果,主动提供与预判结果相匹配的服务。
其中,根据预判结果,主动提供与预判结果相匹配的服务,具体包括:
确定与所述预判结果相匹配的服务,向用户发出是否需要所述服务的询问,并在确定出用户需要时,向用户提供所述服务。
本实施例中,向用户提供的与预判结果相匹配的服务,包括:内容服务和/或设备状态控制服务;所述设备状态控制服务包括:控制所述智能语音设备和/或与所述智能语音设备连接的设备到目标状态。
下面通过几个具体应用案例对主动提供服务的过程进行说明。
案例一:若基于语音数据的情绪识别结果为“激动77%”、基于图像的情绪识别结果为“激动90%”、以及基于车辆相关行驶数据的情绪识别结果为“激动65%”,则可判断出此用户“情绪为激动”;同时若基于语音数据的身份识别结果为“李女士88%”、基于图像数据的身份识别结果为“李女士95%”,则可判断出此用户为李女士。那么总的情绪、身份识别结果为“李女士情绪为激动”。
将李女士情绪为激动的识别结果发送到大数据推荐引擎,大数据推荐引擎触发语音交互,并发送语音播报文件到智能车载中控自动发起语音交互:
智能车载中控:“刚刚学会了一个新笑话,李女士想不想听啊”
李女士:“好的,说吧”
智能车载中控:“课堂上奥特曼举手了,然后老师就死了”。
案例二:若基于语音数据的情绪识别结果为“疲劳84%”、基于图像数据的情绪识别结果为“疲劳93%”,则可判断出此用户“情绪为疲劳”,同时若基于语音数据的身份识别结果为“张先生88%”、基于图像数据的身份识别结果为“张先生95%”,则可判断出此用户为“张先生”。那么总的情绪、身份识别结果为“张先生情绪为疲劳”。
将张先生情绪为疲劳的识别结果发送到大数据推荐引擎,大数据推荐引擎触发语音交互,并发送语音播报文件到智能车载中控自动播放音乐:
智能车载中控:“张先生,要不要给您放点动感的歌啊,看你开车都累了”。
张三:“好的啊”
智能车载中控打开音乐播放器,并播放轻松欢快歌曲,并结合用户的音乐历史数据推荐张三可能喜欢的歌手与音乐类型。
案例三:若基于图像数据的情绪识别结果为“愤怒80%”、基于车辆行驶数据的情绪识别结果为“愤怒99%”,则可判断出此用户“情绪为愤怒”,同时若基于语音数据的身份识别结果为“周先生88%”、基于图像数据的身份识别结果为“周先生95%”,则可判断出此用户为“周先生”。那么总的情绪、身份识别结果为“周先生情绪为愤怒”。
将周先生情绪为愤怒的识别结果发送到大数据推荐引擎,大数据推荐引擎触发语音交互,并发送语音播报文件到智能车载中控自动发起语音交互,争取用户的功能操作的认同:
智能车载中控:“周先生,看您今天怎么有点恼火啊,要不要帮您降降温,打开空调呢”。
周先生:“好的,开吧”
智能车载中控接收到语音信息后,打开空调。
综上可知,本发明实施例提出了一种全新的驾驶员情绪识别与身份识别的方法,并将身份、情绪识别结果发送到大数据推荐引擎,由大数据推荐引擎根据身份及情绪的识别结果,推荐匹配的服务,包括但不限于为UI展示,语音播报,内容服务提供,车内设备控制等,从而实现了主动为用户提供更人性化的服务,提高了用户的使用体验。
在本发明的第三实施例中,提供一种驾驶员情绪识别装置,如图2所示,具体包括:
信息采集模块210,用于采集驾驶员的图像数据、驾驶员的语音数据以及驾驶车辆的行驶数据中的至少两种数据;
情绪识别模块220,用于分别根据采集的多种数据,对驾驶员的情绪进行识别,得到每种数据类型下的情绪识别结果;
情绪判定模块230,用于基于得到的每种数据类型下的情绪识别结果,按照设定的情绪判定策略,判定出驾驶员的情绪。
基于上述结构框架及实施原理,下面给出在上述结构下的几个具体及优选实施方式,用以细化和优化本发明所述装置的功能,以使本发明方案的实施更方便,准确。具体涉及如下内容:
本发明实施例中,所述情绪识别结果包括:识别出的情绪类型及识别出该情绪类型的置信度。其中,情绪类型包括但不限于为:高兴、伤心、愤怒、厌烦、疲劳、激动和正常。
进一步地,本发明实施例中,信息采集模块210包括布设在车内外的设备传感器、布设在车内的图像采集装置和音频采集装置。
具体的,本实施例中,通过布设在车内外的设备传感器采集驾驶车辆的行驶数据,所述设备传感器可以包括至少以下一种或几种传感器的组合:加速度传感器、速度传感器、红外传感器、角速度传感器、激光测距传感器、超声波传感器等。根据车辆上布设的这些传感器获取的信息,就可以得到当前车辆的姿态信息、当前车况信息、当前路况信息、驾驶时长、车辆驾驶轨迹信息等。进一步的,本发明实施例中,通过图像采集装置,如摄像头,采集驾驶员的图像数据;以及通过音频采集装置,如麦克风,采集驾驶员的声音数据。
在本发明的一个具体实施例中,情绪识别模块220根据驾驶车辆的行驶数据对驾驶员的情绪进行识别,包括:从所述相关行驶数据中提取相关行驶特征,根据相关行驶特征在预设的分类器中进行分类,根据所述分类器中的分类结果识别与所述相关行驶特征相对应的驾驶员情绪,最后给出对应的识别置信度。具体的,本发明实施例中,采集预设时间内汽车行驶中的训练行驶信息,并从所述训练行驶信息中提取训练行驶特征;获取针对不同训练行驶特征标注的不同驾驶员情绪,并基于预设的分类算法对不同训练行驶特征标注的不同驾驶员情绪进行学习、训练,形成预设的分类器。
在本发明的一个具体实施例中,情绪识别模块220根据采集的图像数据,对驾驶员的情绪进行识别,包括:在先需要进行人脸的离线训练,所述离线训练使用人脸的数据库训练人脸的检测器、同时在人脸上标定标记点,根据所述人脸标记点训练标记点拟合器,并且,通过人脸标记点和情绪的关系训练情绪分类器。当进行人脸的在线运行时(即需要根据图像数据进行情绪识别时),通过人脸检测器在图像数据中检测人脸,然后通过标记点拟合器拟合人脸上的标记点,情绪分类器根据人脸标记点判断当前驾驶员的情绪,最后给出对应的分类置信度。
在本发明的一个具体实施例中,情绪识别模块220根据采集的语音数据,对驾驶员的情绪进行识别,包括:在先需要进行人声的离线训练,所述人声的离线训练,使用语音数据库训练人声检测器,同时训练语音特征向量提取模型用于从人声中提取特征向量的声音,采用已标定好的语音特征向量以及情绪的训练集训练情绪分类器。当进行人声的在线运行时(即需要根据语音数据进行情绪识别时),通过人声检测器在输入的声音流中检测人声数据,并从人声数据中提取语音特征向量,最后使用情绪分类器从语音特征向量分辨当前用户的情绪,并给出识别的置信度。可选地,本发明实施例中,还对所述语音数据中的语义进行识别。当根据语音特征向量进行情绪识别时,可以结合语义识别结果,进行综合识别判断,得到基于语音数据的最终识别结果。
进一步的,本发明实施例中,为了根据不同数据类型得到的识别结果进行驾驶员的情绪判定,要预先按照数据类型,进行情绪置信度阈值的设定。具体的,设定与图像数据类型相对应的第一情绪置信度阈值、设定与语音数据类型相对应的第一情绪置信度阈值、以及设定与行驶数据类型相对应的第一情绪置信度阈值。其中,不同数据类型下的第一情绪置信度阈值可以相同,也可以不同,具体值可根据需求灵活设定。
对此,本发明实施例中,情绪判定模块230基于得到的每种数据类型下的情绪识别结果,按照设定的情绪判定策略,判定出驾驶员的情绪,具体包括:
当至少两个情绪识别结果中的情绪类型相同且置信度分别大于等于设定的对应数据类型的第一情绪置信度阈值时,将所述至少两个情绪识别结果中的情绪类型作为最终识别出的驾驶员的情绪;
进一步地,考虑到有些情况下,基于某种数据类型的识别置信度很高,具有很高的可信性,此时,可以直接利用置信度很高的数据类型对应的识别结果作为最终的识别结果,具体实现时,可检测各情绪识别结果中是否存在一个情绪识别结果的情绪类型的置信度大于等于设定的对应数据类型的第二情绪置信度阈值,并在是的情况下,将该情绪识别结果中的情绪类型作为最终识别出的驾驶员的情绪;其中,同一数据类型下的第一情绪置信度阈值小于第二情绪置信度阈值。
进一步地,本发明实施例中,情绪判定模块230,还用于在判定出驾驶员的情绪之后,根据预设的情绪类型的置信度与情绪类型级别的对应关系,得到最终识别出的驾驶员的情绪的情绪级别。
在本发明的一具体实施例中,所述装置还包括:
身份识别模块240,用于当所述信息采集模块210采集到图像数据或者语音数据时,根据所述图像数据或者语音数据,识别出驾驶员的身份;当所述信息采集模块采集到图像数据和语音数据时,分别根据所述图像数据和语音数据,对驾驶员的身份进行识别,得到两种数据类型下的两个身份识别结果;
身份判定模块250,用于当所述身份识别模块240得到一种数据类型下的身份识别结果时,直接以该结果作为识别出的驾驶员的身份;当所述身份识别模块240得到两种数据类型下的两个身份识别结果时,基于得到的两个身份识别结果,按照设定的身份判定策略,判定出驾驶员的身份。
本发明实施例中,所述身份识别结果包括:识别出的用户及识别出该用户的置信度。
在本发明的一个具体实施例中,身份识别模块240根据采集的图像数据,对驾驶员的身份进行识别,包括:在先需要进行人脸的离线训练,所述离线训练使用人脸的数据库训练人脸的检测器、同时在人脸上标定标记点,根据所述人脸标记点训练标记点拟合器,并且,通过人脸标记点和身份的关系训练身份分类器;当进行人脸的在线运行时,通过人脸检测器在图像数据中检测人脸,然后通过标记点拟合器拟合人脸上的标记点,身份分类器根据人脸标记点判断当前驾驶员的身份,最后给出对应的分类置信度。
在本发明的一个具体实施例中,身份识别模块240根据采集的语音数据,对驾驶员的身份进行识别,包括:在先需要进行人声的离线训练,所述人声的离线训练,使用语音数据库训练人声检测器,同时训练语音特征向量提取模型用于从人声中提取特征向量的声音,采用已标定好的语音特征向量以及身份的训练集训练身份分类器。当进行人声的在线运行时,通过人声检测器在输入的声音流中检测人声数据,并从人声数据中提取语音特征向量,最后使用身份分类器从语音特征向量分辨当前用户的身份,并给出识别的置信度。
进一步地,本发明实施例中,当采集到图像数据和语音数据时,为了根据两种数据类型得到的识别结果进行驾驶员的身份判定,要预先按照数据类型,进行身份置信度阈值的设定。具体的,设定与图像数据类型相对应的第一身份置信度阈值以及设定与语音数据类型相对应的第一身份置信度阈值。其中,不同数据类型下的第一情绪置信度阈值可以相同,也可以不同,具体值可根据需求灵活设定。
对此,本发明实施例中,身份判定模块250基于得到的两个身份识别结果,按照设定的身份判定策略,判定出驾驶员的身份,具体包括:
当两个身份识别结果中识别出的用户相同且置信度分别大于等于设定的对应数据类型的第一身份置信度阈值时,以共同识别出的用户作为最终的用户身份识别结果;
当两个身份识别结果中有一个身份识别结果中识别出的用户的置信度大于等于设定的对应数据类型的第二身份置信度阈值时,以用户的置信度大于等于第二置信度身份阈值对应的用户,作为最终的用户身份识别结果,其中,同一数据类型下的第一身份置信度阈值小于第二身份置信度阈值。
在本发明的又一具体实施例中,所述装置还包括:
大数据推荐引擎模块260,用于利用得到的驾驶员的身份,在预先建立的各用户行为习惯模型中匹配出与该驾驶员对应的用户行为习惯模型,并将驾驶员的情绪信息输入到匹配的用户行为习惯模型中,以对驾驶员的状态和/或行为进行预判,并根据预判结果,主动提供与预判结果相匹配的服务。
其中,大数据推荐引擎模块260,具体用于确定与所述预判结果相匹配的服务,向用户发出是否需要所述服务的询问,并在确定出用户需要时,向用户提供所述服务。其中,确定用户是否需要,可通过对用户输入语音进行语音识别,得到文本信息,再通过文本信息进行语义识别来确定。
本实施例中,向用户提供的与预判结果相匹配的服务,包括:内容服务和/或设备状态控制服务;所述设备状态控制服务包括:控制所述智能语音设备和/或与所述智能语音设备连接的设备到目标状态。
综上可知,本发明实施例所述装置可分别根据图像数据、语音数据和车辆行驶数据中的至少两种进行情绪识别,并根据得到的多个情绪识别结果综合判断驾驶员的情绪状态,这种情绪状态识别方式不会受单一的道路状况、车辆状况、面部特征和语音特征等影响,识别出的驾驶员的情绪更加符合实际的驾驶员情绪状态,提高了情绪识别的准确性及环境适应性。
另外,本发明实施例所述装置还可以分别根据图像数据和语音数据进行驾驶员的身份识别,并根据得到的两个身份识别结果综合判断驾驶员的身份,提高了身份识别的准确性和环境适应性;
再者,本发明还可以根据识别的驾驶员的情绪和身份,进行主动的服务推荐,提高了用户的使用体验。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是其与其他实施例的不同之处。尤其对于装置实施例而言,由于其基本相似与方法实施例,所以,描述的比较简单,相关之处参见方法实施例的部分说明即可。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:ROM、RAM、磁盘或光盘等。
总之,以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!