一种基于MIC集群的深度学习框架Caffe系统及算法的制作方法
本发明涉及高性能计算领域,尤其涉及一种基于集群系统针对深度学习框架的数据、任务并行处理及保证进程、节点间负载均衡的优化方法。
背景技术:
Caffe(Convolution Architecture For Feature Extraction)作者是博士毕业于UC Berkeley的贾扬清,目前是最受欢迎的深度学习框架之一,其特点是上手快、模块化、开放性。Caffe中包含多种卷积神经网络实现模型,包括googlenet、alexnet等,整个卷积神经网络的训练过程由卷积、降采样等一层一层计算实现。
随着需要解决的问题越来越复杂和对卷积神经网络性能的要求越来越高,导致网络中需要的训练数据越来越多,分布式的存储在网络中,相应地需要更多的可训练参数和计算量,而原始版本的Caffe版本一般是基于单机系统串行实现,这样导致相当长时间需要花费在训练一个使用大量数据的复杂模型上。
原始版本Caffe在单机单进程运行的局限性导致扩展性及性能受限,同时在Caffe内核部分ForwardBackward计算中,涉及复杂的矩阵、方程等运算,原始版本Caffe关于这部分的计算基于串行单线程执行,而当矩阵规模较大时,单节点上运行时间复杂度会相当大。
技术实现要素:
本发明为解决上述技术问题。为此,本发明提供一种基于MIC集群的深度学习框架Caffe系统及算法,实现同一进程内多线程并行计算,在卷积神经网络中涉及大量的矩阵计算,多线程并行主要用在矩阵计算上,通过设置并行线程数,最大程度发挥MIC处理器性能,提高Caffe运行时间性能。
为了实现上述目的,本发明采用如下技术方案。
一种基于MIC集群的深度学习框架Caffe系统,包括,MIC集群内多节点,所述节点包括主节点和从节点,各节点与数据库连接,并通过MPI通信共享数据和任务。所述主节点负责对各节点反馈的信息进行计算汇总后将更新后的参数分发至各节点。从节点利用新参数进行下一轮迭代计算,并将执行结果反馈给主节点。
优选的,节点内包含多进程,每个节点内设置1对n方式,一个主进程和n个从进程。主进程负责从数据库中读取数据并将数据分发给该节点内对应的n个从进程,从进程接收数据后进行ForwardBackward计算。
一种基于MIC集群的深度学习框架Caffe算法,通过MPI技术运行在MIC集群多节点上,各节点间通过MPI通信将任务和数据均分,不同节点间并行执行子任务、处理子数据,进行Caffe中ForwardBackward计算,将执行结果反馈给主节点由主节点对各节点反馈的权值信息进行计算汇总后将更新后的参数分发至各节点,各从节点利用新参数进行下一轮迭代计算。
优选的,执行结果为权值参数。
优选的,由设置于节点内的主进程负责从数据库中读取数据并将数据分发给该节点内对应的n个从进程,各从进程接收数据后进行ForwardBackward计算。减少不同节点间通信开销。关于n的设置需要结合每个进程内开启的线程数。
优选的,对Caffe内核计算部分采用OpenMp多线程并行计算。
本发明的有益效果:
1、本发明基于MIC集群采用MPI多进程+OpenMp多线程实现,一方面保证程序的并行度和扩展性,另一方面,基于最新MIC处理器Knights Landing充分利用MIC的众多核心,达到性能优化效果。
2、通过MPI技术实现深度学习框架Caffe运行时的任务并行和数据并行,框架设计为主进程和从进程,主进程开启多线程,进行数据读取、数据分发和任务分发,多个从进程均分数据并且针对不同数据并发执行子任务,较串行执行方式性能显著提高。
3、对Caffe内核计算部分采用OpenMp多线程并行计算,提高内核计算效率。
4、各进程间进行任务或数据的均分,当集群节点或进程数要求较高时,框架设计为多个主进程和多个从进程,各主进程对应数个从进程,避免单个主进程负载较重的情况。在集群多节点的情况下,尽量保证每个节点只有一个主进程,保证各节点间负载均衡。
附图说明
图1是MIC集群多节点设计框架图。
图2是本实施例主-从节点、进程分配示意图。
图3是内核部分多线程并行优化示意图。
具体实施方式
下面结合附图与实施例对本发明作进一步说明。
实施例1
基于MIC集群的深度学习框架Caffe算法系统,包括,MIC集群内多节点,所述节点包括主节点和从节点,各节点间通过MPI通信共享数据和任务。所述主节点负责对各节点反馈的信息进行计算汇总后将更新后的参数分发至各节点。从节点利用新参数进行下一轮迭代计算,并将执行结果反馈给主节点。
基于MIC集群的深度学习框架Caffe算法,通过MPI技术运行在MIC集群多节点上,各节点间通过MPI通信将任务和数据均分,不同节点间并行执行子任务、处理子数据,进行Caffe中ForwardBackward计算,将执行结果反馈给主节点由主节点对各节点反馈的权值信息进行计算汇总后将更新后的参数分发至各节点,各从节点利用新参数进行下一轮迭代计算。
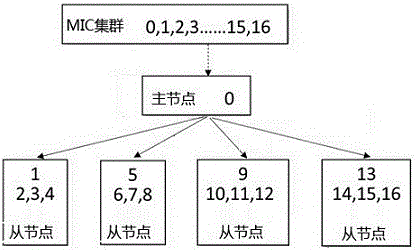
本发明的整体框架设计如图1所示,集群版本框架分为主节点和从节点,每个节点即每台服务器,主节点只有一个,从节点则根据集群中服务器个数进行分配。0号进程分配在主节点中,该进程负责任务分配(在卷积神经网络计算中,将迭代计算任务分配给各从节点),各从节点根据任务分配进行迭代计算,并将每次迭代的计算结果(权值Weight信息,ΔW)反馈给0号主进程,0号主进程接收各从节点的反馈结果,对权值累计取平均,进行参数更新计算,最后将更新后的参数W传送给各从节点,进行下一轮迭代计算。其中在每个从节点中可包含多个进程,其中有一个主进程控制n个从进程(从进程个数n的设定综合考虑MIC核数和每个进程开启的线程数,以保证每个节点上的程序能充分利用MIC线程数,达到最优性能),主进程负责从数据库中读取数据,并将读取的数据以多线程方式分别分配给对应的从进程。主-从节点、主-从进程方式的设定,既可保证集群系统中节点间的负载均衡,又可保证各进程间的负载均衡。
关于主从节点的设定方式如下:若集群中要求m个节点的并行,则选取一个节点作为主节点,0号进程分配在主节点中,其余m-1个节点作为从节点,在MIC平台上,由于核数较多,每个节点设计一个主进程和n个从进程以充分利用MIC平台线程数。比如MIC上可支持的最大并行线程数为256,每个从进程进行ForwardBackward计算并行线程数为64,则令n=3,每个节点上一个主进程对应3个从进程,主进程开启多线程分配数据给对应从进程,从进程多线程ForwardBackward卷积计算。
实施例2
以5个节点为例,主-从节点及主-从进程分配方式如图2所示,MIC集群包含编号为0-16的节点,编号为0的节点设为主节点,主节点分别通过线程与4个从节点连接。每个从节点内包含1个主进程和3个从进程。从节点1中包括主进程1和从进程2、3、4。从节点2中包括主进程5和从进程6、7、8。从节点3中包括主进程9和从进程10、11、12。从节点4中包括主进程13和从进程14、15、16。
在从进程计算并行线程数变化的情况下,从进程个数n会进行相应增加或减少,以保证每个MIC节点上线程数的充分利用。
实施例3
与实施例1不同在于,在Caffe内核部分ForwardBackward计算中,涉及复杂的矩阵、方程等运算,采用OpenMp多线程并发执行的计算方式将复杂运算分解,多线程并行的设置方式为并行外层循环来减少线程调度的开销,结果证明通过并行矩阵运算在很大程度上提高了整个程序的计算效率。内核部分多线程并行主要基于convolution、pooling等层的bach_size分解,即图片的并行读取与处理,降低程序的时间复杂度,提高性能。多线程并行实现流程图如图3所示。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!