基于核极限学习机的泄露气体监测浓度数据虚拟扩展方法与流程
本发明涉及基于核极限学习机的危险化学品气体泄露监测浓度数据虚拟扩展方法,属于危险化学品技术领域。
背景技术:
面对危险化学品泄漏事件,尤其是毒气泄漏,突发情况、信息缺失等是泄漏事故存在的普遍问题,在泄漏源信息都是未知的条件下,相关部门需要在最短的时间内进行决策,进而确定泄漏的影响范围,划出相应的应急疏散区域和安全距离。因此,研究泄露源特性反演技术(包括反演源释放速率、源位置、源高度、风速、风向等参数)对于制定应急响应决策,提高应急疏散效果,从而减少人员伤亡和财产损失具有重要意义。
在危险化学品气体泄露源特性反算问题中,常常需要在下风向不同空间位置采集大量监测点浓度数据。在传感器个数有限或较少时,仅由少量的有效浓度数据进行反演,精度较低。若采用多次测量,则工作量很大,工作效率较低。为此,研究并解决在有限的传感器个数条件下,仅通过较少空间位置处的气体浓度监测,获取不便测量或其它未监测到的空间位置处的气体浓度数据,对于解决在突发事故中,当有限信息或信息缺失条件时,用最短时间确定未知泄露源特性问题尤为重要。
技术实现要素:
针对上述问题,本发明要解决的技术问题是提供基于核极限学习机的泄露气体监测浓度数据虚拟扩展方法。
本发明的基于核极限学习机的泄露气体监测浓度数据虚拟扩展方法,它的扩展方法为:首先选取已监测空间区域s1位置点坐标xs,ys和浓度数据作为训练样本集;其中坐标值为网络的输入值,而浓度数据作为网络输出值,这样就构造出网络并进行训练;然后根据需要外推或内插的虚拟监测点空间位置s2-s1确定坐标(xpn,ypn),n为预测的点数,并且同训练样本集中的坐标组成预测样本集中的输入值,输入至前面训练好的网络;网络的输出值为要预测的目标值,即虚拟扩展后的空间s2全部监测点的气体浓度数据,并保持初始监测面s1上的数据不变。
作为优选,所述训练样本为核极限学习机训练。
与现有技术相比,本发明的有益效果为:通过将小孔径监测点内的气体浓度数据进行外推和内插估计,虚拟出其它未监测的空间位置处的气体浓度数据,有效扩大了监测面,增大了监测点个数。将该方法与其它泄露源特性反算方法(例如遗传算法、粒子群算法、模式搜索算法等)相结合,对危化品泄露源源释放速率、源位置、源高度、方向、风速等源特性进行反演,体现了本方法的优越性。在传感器个数较少时,采用kelm技术对监测点浓度数据进行外推或插值,在不增加测点的情况下有效地提高源特性反算精度,并节省工作量,提高工作效率。
附图说明
为了易于说明,本发明由下述的具体实施及附图作以详细描述。
图1为本发明的流程图;
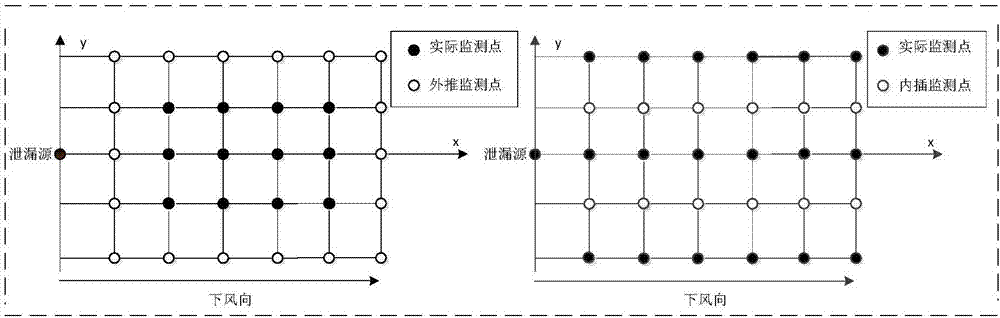
图2为本发明中空间监测浓度数据外推与内插示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面通过附图中示出的具体实施例来描述本发明。但是应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
如图1所示,本具体实施方式采用以下技术方案:它的扩展方法为:首先选取已监测空间区域s1位置点坐标xs,ys和浓度数据作为训练样本集;其中坐标值为网络的输入值,而浓度数据作为网络输出值,这样就构造出网络并进行训练;然后根据需要外推或内插的虚拟监测点空间位置s2-s1确定坐标(xpn,ypn),n为预测的点数,并且同训练样本集中的坐标组成预测样本集中的输入值,输入至前面训练好的网络;网络的输出值为要预测的目标值,即虚拟扩展后的空间s2全部监测点的气体浓度数据,并保持初始监测面s1上的数据不变。
一、神经网络核极限学习机(kelm)理论:
神经网络是一种模仿人脑信息处理机制的网络系统,能够进行学习、记忆、识别和推理等功能。它具有很强的鲁棒性和容错性。拥有自我学习、联想存储以及高速寻优的能力。网络本身通常是对某种逻辑策略的表达或是对某种算法及函数的逼近。常用的神经网络主要有前馈型神经网络、反馈型神经网络和局部逼近神经网络。其中,由于单隐层前馈神经网络具有良好的学习性能使其在许多领域中得到了较为广泛的应用。本具体实施方式采用的极限学习机(extremelearningmachine,elm)算法就是一种单隐层前馈神经网络的新算法,该算法随机产生输入层与隐含层之间的权值和隐含层神经元阈值。网络训练的过程中,只需要设定隐含层神经元个数,便可获得唯一最优解。该方法与传统的训练方法相比具有学习速度快、泛化性能好等优点。
令输入层神经元个数为n,表示有n个输入;隐含层有l个神经元;输出层有m个神经元,代表m个输出,用b表示隐含层神经元阈值,w代表隐含层和输入层间的权值,β代表其与输出层间的权值,则w,β,b可表示为:
式中,wji表示隐含层中第j个神经元和输入层中第i个神经元间的权值,βjk表示其与输出层第k个神经元间的权值。
用x表示网络的训练输入样本,y表示网络的训练输出样本,q表示训练样本个数,即:
令隐含层神经元的激活函数为g(x),则由式1可得,网络的输出t为:
其中,wi=[wi1,wi2,l,win],xj=[x1j,x2j,l,xnj]t,上式可表示为:
hβ=t'(3)
式中,t'为t的转置;h称为神经网络的隐含层输出矩阵,表达式为:
在此基础上,隐含层与输出层之间的连接权值β可以写作:
其最小二乘解为:
其中,h+为隐含层输出矩阵h的mp广义逆。
通过上式得到的输出权值不但获得了最小的训练误差,得到最优的泛化性能,而且不会产生局部最优解。通过把预测样本当作测试集进行测试,就可以得到测试集对应的输出预测值矩阵:
f(x)=h(x)β(7)
其中,h(x)为测试集的隐含层输出矩阵。当训练样本数远大于隐含层节点数时:
否则有:
通过在h+h或hh+的对角线上添加一正项
则输出函数可表示为:
式中,k(u,v)为核函数,通常采用径向基核函数(rbfkernel),k(u,v)=exp(-γ||u-v||2)对于参数c和γ,采用交叉验证方法寻找其最佳值,然后利用最佳参数训练模型。通过引入核函数,避免了选择隐含层神经元个数和定义隐含层的输出矩阵,进一步提高了kelm的学习速度和泛化能力。
二、基于kelm的危化品泄露气体监测浓度虚拟扩展技术:
由于核极限学习机(kelm)具有良好的学习性能和泛化性能,具有逼近非线性函数的能力,使其适用于解决信号处理过程中的分类辨识和回归拟合问题。而毒气泄露扩散模型正是高度非线性函数,其与泄露源源释放速率、源位置、源高度、风速、风向、泄露气体密度、地面粗糙度、雨水吸附、大气稳定度等参数密切相关,该扩散模型很难用公式有效表达。基于此,提出将该方法用于危化品泄露气体监测浓度虚拟扩展问题中。
该方法把位于不同空间位置处的监测点浓度数据当成网络的训练样本进行学习,将未知的空间位置浓度当作目标值进行预测,有效地减小了监测点孔径,减少工作量,提高工作效率。具体说,监测点浓度数据虚拟扩展技术包括监测点浓度数据的外推和内插两部分。如图2所示,由测量区域中的监测点浓度外推或内插未测点浓度,并保证预测值尽可能接近真实值。将外推及内插的虚拟监测点浓度与实际监测点浓度进行组合,相当于间接增大了浓度监测信息。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!