一种基于配置的大数据监控方法、装置和平台与流程
本发明涉及大数据监控方法,尤其是涉及一种基于配置的大数据监控方法、装置和平台。
背景技术:
随着社会高速发展,科技进步,信息流通,人们之间的交流越来越密切,生活也越来越方便。伴随信息量爆炸性的增长,大数据作为这个高科技时代的产物,应运而生。
大数据时代所带来的影响是深远的,使人们正在经历一个大规模生产、分享、分析和应用数据的时代——人们第一次有机会和条件,广泛和深入地获得并应用全面数据、完整数据和系统数据。社会中日常产生大量离散而又相互关联的非结构化和半结构化数据,这些简称为原生态数据。合理有效地利用这些数据,能为决策层提供战略级的规划,能为管理层提供战役级的设计,能为运营层提供战术级的管控。
因此,大数据应用在当代社会各行各业都牵起一番热潮,然而大数据中的数据是离散的、多样的、无序的,要通过现有的技术手段形成有价值能应用的数据需要各行各业针对各自特点去分析、设计与开发,数据本身类别及实际应用场景的多样性增加了数据转化的难度,技术上缺乏对数据统一的规划与分类抽象,使得大数据的应用手段在不同的行业中存在不同的壁垒。不同应用场景、不同数据类型没法做到跨行业、多类型、全覆盖,若要全面覆盖会直接导致需求分析以及开发的工作量成倍增加,不符合当前软件开发的复用性的特性。
技术实现要素:
(一)要解决的技术问题
为了解决现有技术的不足,本发明提供一种基于配置的大数据监控方法、装置和平台,将不同应用场景,不同数据类型的源数据转化为同一数据结构的数据进行发布的功能,对于发布数据的使用者,不需要对数据进行任何处理,实现数据的全面覆盖。
(二)技术方案
为了达到上述目的,本发明采用的主要技术方案包括:
一种基于配置的大数据监控方法,其包括:
101,获取离散的非结构化的原生态的原始数据;
102,对所述原始数据进行预处理;
103,确定预处理后数据中的结构项;
104,根据配置文件对所述结构项进行结构拼接,形成统一数据结构的最终数据;
105,发布所述最终数据。
可选地,步骤103具体包括:
103-1,确定预处理后数据的数据项总数量L;
103-2,根据如下公式确定预处理后数据中的各数据项的结构概率P;
其中,Wn为第n个数据项的权重值,i为第i个数据项,fn为预处理后数据中第n个数据项的有效数据量;
103-3,将结构概率大于预设阈值的数据项确定为结构项。
可选地,步骤102具体包括:
对所述原始数据进行去噪处理。
可选地,步骤104具体包括:
104-1,根据配置文件确定各结构项之间的结构关系;
104-2,根据结构关系对各结构项进行拼接,形成统一数据结构的最终数据;
所述结构关系包括隶属关系、相邻关系、交叉关系、同级关系、关联关系、主键关系、引用关系。
除此之外,本发明采用的主要技术方案还包括:
一种基于配置的大数据监控装置,该装置包括:
获取单元,用于获取离散的非结构化的原生态的原始数据;
预处理单元,用于对所述原始数据进行预处理;
确定单元,用于确定预处理后数据中的结构项;
拼接单元,用于根据配置文件对所述结构项进行结构拼接,形成统一数据结构的最终数据;
发布单元,用于发布所述最终数据。
可选地,所述确定单元,包括:
第一确定子单元,用于确定预处理后数据的数据项总数量L;
第二确定子单元,用于根据如下公式确定预处理后数据中的各数据项的结构概率P;
其中,Wn为第n个数据项的权重值,i为第i个数据项,fn为预处理后数据中第n个数据项的有效数据量;
第三确定子单元,用于将结构概率大于预设阈值的数据项确定为结构项。
可选地,所述预处理单元,用于对所述原始数据进行去噪处理。
可选地,所述拼接单元,包括:
确定子单元,用于根据配置文件确定各结构项之间的结构关系;
拼接子单元,用于根据结构关系对各结构项进行拼接,形成统一数据结构的最终数据;
所述结构关系包括隶属关系、相邻关系、交叉关系、同级关系、关联关系、主键关系、引用关系。
除此之外,本发明采用的主要技术方案还包括:
一种基于配置的大数据监控平台,该平台包括:源数据库、预处理数据库、数据基础处理模块、配置管理工具、中枢管理与调度模块、临时数据管理模块、单元制作模块和集成管理与控制发布模块;
源数据库,用于存储获取到的离散的非结构化的原生态的原始数据;
预处理数据库,用于存储预处理后数据,所述预处理后数据由对所述原始数据进行预处理得到;
数据基础处理模块,用于预处理后数据,根据配置文件对所述结构项进行结构拼接,形成统一数据结构的最终数据;
配置管理工具,用于存储和管理配置文件;
中枢管理与调度模块,用于控制临时数据管理模块和单元制作模块管理和调度最终数据;
临时数据管理模块,用于针对发布场景加工所述最终数据;
单元制作模块,用于对加工后的最终数据的发布进行可视化和监控;
集成管理与控制发布模块,用于发布可视化后的最终数据。
可选地,所述源数据库为Oracle数据库,或者,DB2数据库,或者,MySQL数据库,或者,MSSQL数据库。
(三)有益效果
本发明的有益效果是:对原始数据进行预处理,确定预处理后数据中的结构项,根据配置文件对结构项进行结构拼接,形成统一数据结构的最终数据,发布最终数据,实现将不同应用场景,不同数据类型的源数据转化为同一数据结构的数据进行发布的功能,对于发布数据的使用者,不需要对数据进行任何处理,实现数据的全面覆盖。
附图说明
图1为本发明一个实施例提供的一种基于配置的大数据监控方法流程图;
图2为本发明一个实施例提供的一种基于配置的大数据监控平台结构示意图;
图3为本发明一个实施例提供的另一种基于配置的大数据监控方法流程图;
图4为本发明一个实施例提供的另一种基于配置的大数据监控方法流程图;
图5为本发明一个实施例提供的一种基于配置的大数据监控装置结构示意图;
图6为本发明一个实施例提供的一种确定单元结构示意图;
图7为本发明一个实施例提供的一种拼接单元结构示意图。
具体实施方式
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
对于离散的、多样的、无序的数据要形成有价值能应用的数据需要各行各业针对各自特点去分析、设计与开发,随着数据本身类别及实际应用场景的多样性增加了数据转化的难度,本发明提供一种基于配置的大数据监控方法、装置和平台,对原始数据进行预处理,确定预处理后数据中的结构项,根据配置文件对结构项进行结构拼接,形成统一数据结构的最终数据,发布最终数据,实现将不同应用场景,不同数据类型的源数据转化为同一数据结构的数据进行发布的功能,对于发布数据的使用者,不需要对数据进行任何处理,实现数据的全面覆盖。
参见图1,本实施例提供的一种基于配置的大数据监控方法,包括:
101,获取离散的非结构化的原生态的原始数据。
102,对原始数据进行预处理。
103,确定预处理后数据中的结构项。
可选地,步骤103具体包括:
103-1,确定预处理后数据的数据项总数量L;
103-2,根据如下公式确定预处理后数据中的各数据项的结构概率P;
其中,Wn为第n个数据项的权重值,i为第i个数据项,fn为预处理后数据中第n个数据项的有效数据量;
103-3,将结构概率大于预设阈值的数据项确定为结构项。
104,根据配置文件对结构项进行结构拼接,形成统一数据结构的最终数据。
可选地,步骤104具体包括:
104-1,根据配置文件确定各结构项之间的结构关系;
104-2,根据结构关系对各结构项进行拼接,形成统一数据结构的最终数据;
结构关系包括隶属关系、相邻关系、交叉关系、同级关系、关联关系、主键关系、引用关系。
105,发布最终数据。
本实施例的有益效果是:对原始数据进行预处理,确定预处理后数据中的结构项,根据配置文件对结构项进行结构拼接,形成统一数据结构的最终数据,发布最终数据,实现将不同应用场景,不同数据类型的源数据转化为同一数据结构的数据进行发布的功能,对于发布数据的使用者,不需要对数据进行任何处理,实现数据的全面覆盖。
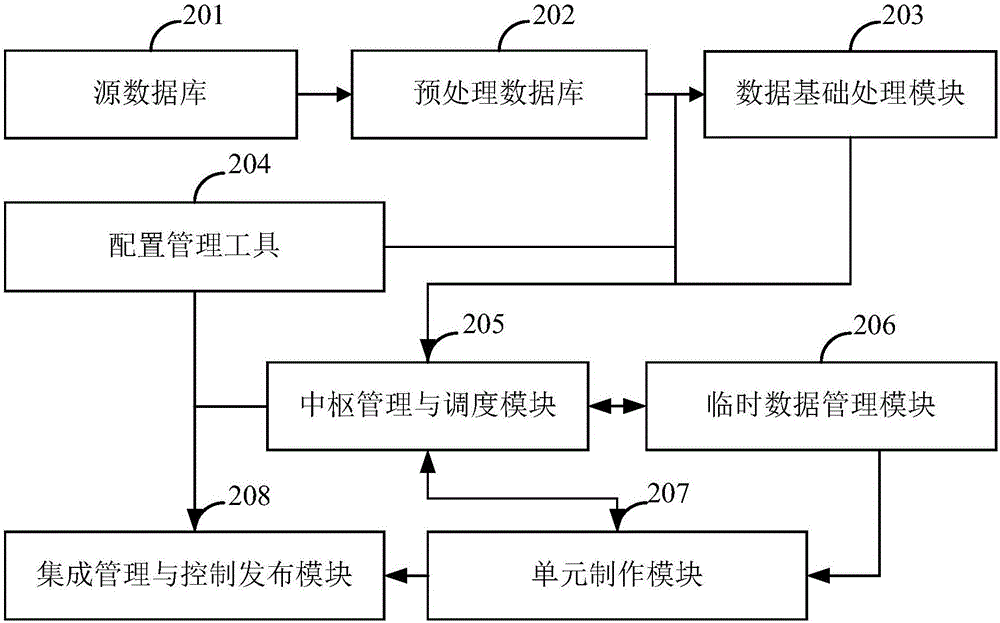
本发明提供的基于配置的大数据监控方法应用于图2所示的基于配置的大数据监控平台中。
该基于配置的大数据监控平台包括:源数据库SDB 201、预处理数据库PDB 202、数据基础处理模块203、配置管理工具204、中枢管理与调度模块205、临时数据管理模块206、单元制作模块207和集成管理与控制发布模块208;
源数据库201,用于存储获取到的离散的非结构化的原生态的原始数据;
预处理数据库202,用于存储预处理后数据,预处理后数据由对原始数据进行预处理得到;
数据基础处理模块203,用于预处理后数据,根据配置文件对结构项进行结构拼接,形成统一数据结构的最终数据;
配置管理工具204,用于存储和管理配置文件;
中枢管理与调度模块205,用于控制临时数据管理模块和单元制作模块管理和调度最终数据;
临时数据管理模块206,用于针对发布场景加工最终数据;
单元制作模块207,用于对加工后的最终数据的发布进行可视化和监控;
集成管理与控制发布模块208,用于发布可视化后的最终数据。
其中,源数据库201为Oracle数据库,或者,DB2数据库,或者,MySQL数据库,或者,MSSQL数据库。
下面结合图2所示的基于配置的大数据监控平台,对本发明提供的基于配置的大数据监控方法进行再次说明,参见图3。
301,获取离散的非结构化的原生态的原始数据。
302,对原始数据进行预处理。
本步骤通过数据库技术把离散的非结构化的原生态的原始数据(存储于原数据库201中)进行整理、归纳,该过程称为去噪过程。使用一系列的SQL、触发器、定时器、存储过程等数据库技术把原生态数据逐步生成有一定规律的预处理数据并存放于预处理数据库202,本步骤中的数据预处理是对不同类型、跨行业数据适配的关键。
303,确定预处理后数据中的结构项。
本步骤具体包括:
303-1,确定预处理后数据的数据项总数量L;
303-2,根据如下公式确定预处理后数据中的各数据项的结构概率P;
其中,Wn为第n个数据项的权重值,i为第i个数据项,fn为预处理后数据中第n个数据项的有效数据量;
303-3,将结构概率大于预设阈值的数据项确定为结构项。
304,根据配置文件对结构项进行结构拼接,形成统一数据结构的最终数据。
本步骤具体包括:
304-1,根据配置文件确定各结构项之间的结构关系;
304-2,根据结构关系对各结构项进行拼接,形成统一数据结构的最终数据;
结构关系包括隶属关系、相邻关系、交叉关系、同级关系、关联关系、主键关系、引用关系。
步骤303和步骤304在数据基础处理模块203执行完成,实现预处理后数据的基础处理。即把预处理后数据按照配置管理工具204中的配置文件进行基础处理,把数据库数据格式转化成程序可直接使用的数据结构,便于数据在整个处理过程的使用,为数据有效的应用提供基础的准备。步骤303和步骤304执行完成后之后把最终数据存放于中枢管理与调度模块205数据共享区,中枢管理与调度模块205根据数据共享区数据的状态以及配置文件的参数进行调度控制与管理,会根据实际的需要调用单元制作模块207以及调用临时数据管理模块206。
单元制作模块207是数据可视化的最小单元、基础单元,承担着数据监控呈现的最小显示,单元制作的产出会同步到中枢管理与调度模块205数据共享区;临时数据管理模块206可以为了数据监控呈现的聚焦与效果,滚动产生与存放临时数据,提供给单元制作模块207使用,同时临时数据管理模块206产生的数据会同步到中枢管理与调度模块205数据共享区中。
305,发布最终数据。
集成管理与控制发布模块208会根据中枢管理与调度模块205数据共享区中的数据及其配置文件参数,把共享区中的数据进行集成控制与发布,最终形成用户大数据监控平台。
对于图2所示的配置的大数据监控平台,其通过执行本发明提供的基于配置的大数据监控方法实现数据的全面覆盖。
具体的,
1、源数据库201为离散的非结构化的源数据,量大无序,作为预处理数据库的数据来源。源数据库201为目前支持主流的数据库:Oracle、DB2、MySQL、MSSQL等,仅需支持SQL语言数据库开发即可。
2、预处理数据库202为对源数据进行预处理与存放,是兼容适配不同数据类型的关键,该数据库目前使用Oracle数据库,便于plsql数据库开发。
3、数据基础处理模块203根据配置管理工具204里面的配置参数把预处理数据库202里面的有一定规律的数据转化成程序可识别、可使用的数据结构,以便于数据的存放与使用,为数据有效的应用提供基础的准备,同时把基础处理完成的数据同步存放于中枢管理与调度模块205中的共享区中,以供后续调度与制作使用。
4、中枢管理与调度模块205根据数据共享区数据的状态以及配置工具中的配置参数进行调度控制与管理,根据实际的需要调用单元制作模块207以及临时数据管理模块206。该过程由中枢管理与调度模块205实时识别共享区数据的状态信息,主动调度临时数据管理模块206与单元制作模块207。
5、单元制作模块207是数据可视化图形化的最小单元模块,承担着数据监控的最小显示。
6、临时数据管理模块206属于为了便于把大数据监控呈现效果聚焦,便于各种单元制作以及集成管理模块的组合应用场景的使用,属于数据再加工过程。
7、集成管理与控制发布模块208用于把各种单元制作好的可视化图形化的呈现根据配置工具的配置参数进行集成与组合起来,形成多维度多层次多方位的呈现。
各模块执行本实施例提供的基于配置的大数据监控方法的流程图参见图4。
通过执行本发明提供的基于配置的大数据监控方法,基于配置的大数据监控平台可以实现适配跨行业、多类型、全覆盖的大数据监控,该平台具有自动化、可视化、配置化、可复用的特点。自动化是指所有从采集到过程处理再到最后呈现都是全自动化的;可视化是指所有数据的呈现都可以通过配置呈现不同的形式图表;配置化是指高度定制与自定义每一过程步骤及其呈现形式;可复用是指过程的每一步骤以及整个大数据监控平台都是具备高度复用性,使得能够适配多种数据与各种应用场景。
该平台可以适应不同类别数据,基于配置化实现产品真实环境下大数据的多角度、多方位、多层次、多维度的呈现。将原本离散的数据进行整理、归纳、分析,并通过多维度的图表方式展现。可以全面、深入、直观地看到产品实时的宏观与微观运行情况。
该平台通过对大量产品真实环境下大数据的抽象与整理,分析与提炼过程,使用友好的可视化、流畅的切换与滚动技术等能自定义用户体验关注聚焦,从而实现真正针对数据作为对象,基于配置化而产生并能聚焦各种各样的应用需求,技术上实现能适配跨行业、多类型、全覆盖的自动化、可视化、配置化、可复用。把大数据提炼、整理、挖掘的过程进行单元化模块划分,每一个单元步骤独立又关联地工作,即承担独立的工作任务,而其工作任务是由统一的中枢模块调度管理,不同的单元模块的工作任务又是相互依赖与关联。
通过执行本发明提供的基于配置的大数据监控方法,基于配置的大数据监控平台的优点有:
1、具有高度适配性,能适配各种类型、跨行业的大数据。
2、具有全自动化,大数据监控过程实现全自动化。
3、具有高度复用性,不同的数据仅需进行数据预处理即可实现大数据监控。
4、具有高度的配置化,适用不同的应用场景。
5、通过配置可实现自定义的多种维度组合呈现(图表)。
6、通过配置可实现自定义宏观与微观呈现。
7、通过配置可实现自定义各种数据聚焦关注。
8、通过配置可实现各种页面尺寸适配。
本实施例的有益效果是:对原始数据进行预处理,确定预处理后数据中的结构项,根据配置文件对结构项进行结构拼接,形成统一数据结构的最终数据,发布最终数据,实现将不同应用场景,不同数据类型的源数据转化为同一数据结构的数据进行发布的功能,对于发布数据的使用者,不需要对数据进行任何处理,实现数据的全面覆盖。
基于同一发明构思,本发明还提供一种基于配置的大数据监控装置,该装置解决问题的原理与基于配置的大数据监控方法相似,因此该装置的实施可以参见一种基于配置的大数据监控方法的实施,重复之处不再赘述。
参见图5,该基于配置的大数据监控装置,包括:
获取单元501,用于获取离散的非结构化的原生态的原始数据;
预处理单元502,用于对原始数据进行预处理;
确定单元503,用于确定预处理后数据中的结构项;
拼接单元504,用于根据配置文件对结构项进行结构拼接,形成统一数据结构的最终数据;
发布单元505,用于发布最终数据。
参见图6,确定单元503,包括:
第一确定子单元5031,用于确定预处理后数据的数据项总数量L;
第二确定子单元5032,用于根据如下公式确定预处理后数据中的各数据项的结构概率P;
其中,Wn为第n个数据项的权重值,i为第i个数据项,fn为预处理后数据中第n个数据项的有效数据量;
第三确定子单元5033,用于将结构概率大于预设阈值的数据项确定为结构项。
优选地,预处理单元502,用于对原始数据进行去噪处理。
参见图7,拼接单元504,包括:
确定子单元5041,用于根据配置文件确定各结构项之间的结构关系;
拼接子单元5042,用于根据结构关系对各结构项进行拼接,形成统一数据结构的最终数据;
其中,结构关系包括隶属关系、相邻关系、交叉关系、同级关系、关联关系、主键关系、引用关系。
本实施例的有益效果是:对原始数据进行预处理,确定预处理后数据中的结构项,根据配置文件对结构项进行结构拼接,形成统一数据结构的最终数据,发布最终数据,实现将不同应用场景,不同数据类型的源数据转化为同一数据结构的数据进行发布的功能,对于发布数据的使用者,不需要对数据进行任何处理,实现数据的全面覆盖。
- 还没有人留言评论。精彩留言会获得点赞!