基于时序聚合算法的海量小文件实时存储方法及装置与流程
本发明涉及一种文件存储方法及装置,特别是涉及一种基于时序聚合算法的海量小文件实时存储方法及装置。
背景技术:
现有的分布式文件系统,包括底层的本地文件系统,主要应用于大文件的处理,针对海量小文件,在元数据管理、数据布局及缓存管理等过程实现方面造成存储性能的大幅降低,具体表现为:
(1)元数据管理低效。分布式文件系统在设计上侧重于大尺寸文件高聚合带宽。就本地磁盘的文件系统而言,访问一个文件需要经过至少三次独立的访问,包括目录项、索引结点和数据。并发访问小文件带来大量低效的随机访问。同时,由于单个目录元数据组织能力低效,大量的小文件通常采用多级目录组织存储。随着目录层次的深入,文件的访问效率进一步下降。而对于分布式文件系统而言,大量的小文件存储将产生过多的元数据,加大了主控服务元数据管理的资源消耗,增大了主控服务器负载。
(2)数据布局低效。磁盘文件系统通常以块作为磁盘数据的组织单位并通过索引节点索引文件的数据块。在存储数据时文件系统往往优先考虑大文件读写带宽。在进行大文件写入时,文件的数据块会被系统尽可能的连续分配,使文件的多个数据块间具有很好的空间局部性。而在进行小文件写入时,系统消耗大量索引节点,同时使数据块分配更加分散无序。由于数据块随机分布在磁盘上的不同物理位置,磁盘碎片化严重,造成存储空间的浪费。
(3)缓存管理低效。在分布式存储服务器端Cache设计中,大量小文件的随机性访问导致过低的Cache命中率,造成小文件访问额外的开销。而客户端Cache的有效性往往局限于所在本地机器。当用户从不同终端读取同一文件时需将数据拷贝到本地客户端缓存中并且当Cache中数据存在更新时,需通知所有缓存了该数据的客户端进行数据更新或无效化。
技术实现要素:
本发明就是为了解决现有分布式文件系统用于海量小文件时存在的存储效率低的技术问题,提供一种存储效率高的基于时序聚合算法的海量小文件实时存储方法及装置。
本发明的有益效果是:基于时序队列的数据聚合,采用时序数据聚合策略将小文件批量写入合并文件,减少索引结点的消耗并将随机写转化为顺序写,提高数据的存储效率。同时,可建立二级索引机制用于聚合数据中小文件的读取,将索引信息逻辑分割将部分负载分配给存储节点,减小代理节点的负载压力,索引维护代价更低。
本发明在Swift海量小文件对象存储系统中增加数据聚合存储方法,在数据量如表1中是得到的性能对比如图5和图6所示。本发明较现有海量小文件存储方法的性能具有显著提升。
表1是实验基本数据
附图说明
图1是基于时序聚合算法的海量小文件实时存储方法的总体架构图;
图2是海量小文件实时存储系统的示意图;
图3是聚合数据读取流程图;
图4是聚合数据读取流程图;
图5是本发明较Swift原始方法写入性能对比结果;
图6是本发明较Swift原始方法数据读取时间对比结果。
附图中符号说明:
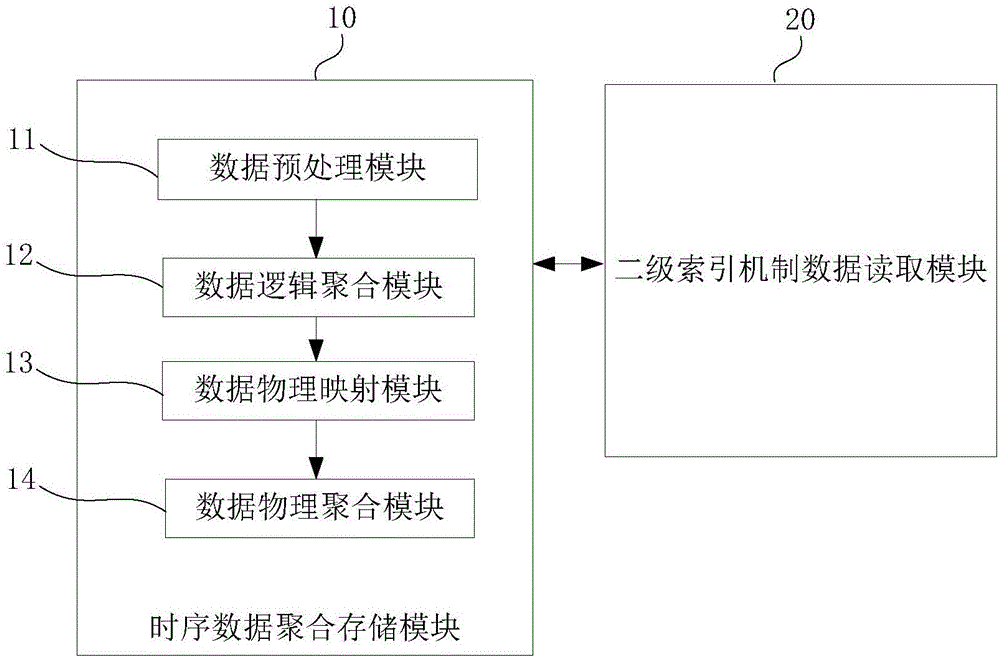
10.时序数据聚合存储模块;20.二级索引机制数据读取模块;11.数据预处理模块;12.数据逻辑聚合模块;13.数据物理映射模块;14.数据物理聚合模块。
具体实施方式
在具体介绍本发明的具体实施例之前,首先对一些概念解释如下:
对象存储(Object-based Storage)是一种以对象形式管理数据的分布式存储架构。小文件对象通常指文件大小在5MB以下的文件。聚合空间是一种逻辑概念,在小文件对象聚合时,聚合空间内的文件会进行聚合,并以一个或者多个数据文件形式存储在分布式文件系统中。
MD5加密算法:MD5即Message-Digest Algorithm 5(信息-摘要算法5),用于确保信息传输完整一致,是计算机广泛使用的杂凑算法之一。该算法具备如下特性:1、压缩性:任意长度的数据,算出的MD5值长度都是固定的。2、容易计算:从原数据计算出MD5值很容易。3、抗修改性:对原数据进行任何改动,哪怕只修改1个字节,所得到的MD5值都有很大区别。4、强抗碰撞:已知原数据和其MD5值,想找到一个具有相同MD5值的数据(即伪造数据)是非常困难的。
一致性哈希算法:一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法。
布鲁姆过滤器(英语:Bloom Filter)是1970年由布鲁姆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布鲁姆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
如图1和2所示,海量小文件实时存储装置包括时序数据聚合存储模块10和二级索引机制数据读取模块20,时序数据聚合存储模块10包括数据预处理模块11、数据逻辑聚合模块12、数据物理映射模块13、数据物理聚合模块14。
数据预处理模块11,使用分布式系统进行数据的时序处理,分布式系统分为代理节点和存储节点,代理节点作为数据相关操作的控制节点,存储节点作为数据的实际存储节点。在代理节点中,系统根据文件的时间先后顺序进行文件对象逻辑上的排序,在存储节点中进行文件的物理排序,形成时序数据队列。
数据逻辑聚合模块12,用于时序数据队列到相应聚合空间的逻辑分配。在该发明中,聚合空间是一种逻辑概念,小文件聚合即是聚合空间内的文件聚合,并以一个或者多个数据文件形式存储在分布式文件系统中。聚合空间的唯一标识名为合并文件名(MobjName)。聚合空间具有三种状态,分别以#、*、&三种符号表示,分别代表聚合空间的初始状态、维持状态以及释放状态。聚合空间的状态包含三个状态参数:空间文件数,空间累计大小,空间累计存在时间。状态参数达到阀值时,代理节点将通过重置形式释放原有聚合空间,重新生成聚合空间的合并文件名(MobjName)。聚合空间的初始状态代表聚合空间正在进行小文件对象聚合,维持状态代表聚合空间内文件已经聚合完成维持稳定状态,释放状态代表聚合空间状态参数达到阀值释放原有聚合空间时刻的状态。具体过程是:
(1)在代理节点中,进行已逻辑排序的小文件到合并文件的逻辑聚处理,并得到合并文件名作为该聚合空间的唯一标识,合并文件名由代理节点中系统当前时间使用MD5加密算法生成。
(2)代理节点进行小文件对象的语义标注,语义标注由合并文件名、聚合空间状态标记、合并文件中小文件顺序的偏移量组成。
数据物理映射模块13,用于在存储节点中相应聚合空间到物理存储分区的逻辑分配。具体过程是:
(1)系统代理节点根据一致性哈希算法生成映射信息,映射信息由小文件名(ObjName),合并文件名(MobjName),生成时间(TimeStamp),物理设备编号(DeviceId),物理分区编号(PartitionId)组成。代理节点将映射信息存储到映射信息数据库(如MySQL数据库)中,该信息将作为文件查询的一级索引。
(2)代理节点将标注过的小文件名的存储请求转发到存储节点,由存储节点完成数据物理聚合存储操作。
数据物理聚合模块14,用于指定分区的聚合空间数据在对应存储节点进行存储操作。在存储节点中,采用文件队列模式进行文件存储,文件队列是文件存放的一种形式,它具有FIFO的特征,可用于海量小文件时序排列后的存储。具体过程是:
(1)在存储节点中,根据合并文件名(MobjName)生成文件队列,合并文件名作为队列的唯一标识。此时,该文件队列是以该合并文件名为标识的聚合空间的物理存储层的表现形式。根据小文件名(ObjName)中的语义标注分配到相应队列,标注中的合并文件名是文件分配指定队列的依据。
(2)当小文件的标注中状态标记为初始状态时,将物理数据层海量小文件信息加入队列,同时写入磁盘。
(3)当标注中状态标记为维持状态时,队列不发生变化。
(4)当标记为释放状态时,将文件加入队列后把队列内容批量写入磁盘并重置队列状态信息。同时进行新队列的生成以及数据的重新分配操作。存储节点和代理节点的状态信息的阈值一致,保证合并文件正常写入磁盘。通过限定合并文件大小和包含文件个数,一定程度上减少文件访问的I/0次数,提高读取速率。
二级索引机制数据读取模块20用于数据的读取,如图5所示,具体过程是:
(1)通过查询数据映射信息,找到合并文件名,通过一致性哈希映射找到相应的存储节点。
(2)通过BoomFilter注册已写入磁盘的队列文件,将无效的磁盘读取请求屏蔽,同时将读取操作转为内存数据查找。
(3)通过对合并文件的访问,以其扩展属性中局部索引为指导,将相应偏移量下的数据进行读取。
海量小文件实时存储方法如下:
步骤1:在代理节点中,系统根据文件的时间先后顺序进行文件对象逻辑上的排序,在存储节点中进行文件的物理排序,形成时序数据队列。
步骤2:在代理节点中,进行已逻辑排序的小文件到合并文件的逻辑聚处理,并得到合并文件名作为该聚合空间的唯一标识,合并文件名由代理节点中系统当前时间使用MD5加密算法生成。
步骤3:代理节点进行小文件对象的语义标注,语义标注由合并文件名,聚合空间状态标记,合并文件中小文件顺序的偏移量组成。
步骤4:系统代理节点根据一致性哈希算法生成映射信息,映射信息由小文件名(ObjName),合并文件名(MobjName),生成时间(TimeStamp),物理设备编号(DeviceId),物理分区编号(PartitionId)组成。代理节点将映射信息存储到映射信息数据库(如MySQL数据库)中,该信息将作为文件查询的一级索引。
步骤5:代理节点将标注过的小文件名的存储请求转发到存储节点,由存储节点完成数据物理聚合存储操作。
步骤6:在存储节点中,根据合并文件名(MobjName)生成文件队列,合并文件名作为队列的唯一标识。此时,该文件队列是以该合并文件名为标识的聚合空间的物理存储层的表现形式。根据小文件名(ObjName)中的语义标注分配到相应队列,标注中的合并文件名是文件分配指定队列的依据。当小文件的标注中状态标记为初始状态时,将物理数据层海量小文件信息加入队列,同时写入磁盘。当标注中状态标记为维持状态时,队列不发生变化。当标记为释放状态时,将文件加入队列后把队列内容批量写入磁盘并重置队列状态信息。同时进行新队列的生成以及数据的重新分配操作。存储节点和代理节点的状态信息的阈值一致,保证合并文件正常写入磁盘。
如图3所示,海量小文件聚合存储读取方法如下:
步骤1:通过查询数据映射信息,找到合并文件名,通过Ring的一致性哈希映射找到相应的存储节点。
步骤2:通过计数BoomFilter注册已写入磁盘的队列文件,将无效的磁盘读取请求屏蔽,同时将读取操作转为内存数据查找。
步骤3:通过对合并文件的访问,以其扩展属性中局部索引为指导,将相应偏移量下的数据进行读取。
海量小文件聚合存储读取方法是:通过文件大小读取阀值K判断是否使用索引查找,如果需要就进行索引查找,如果不是就直接读取文件。进行索引查找时候根据文件名得到一级索引,通过BoomFilter过滤判断之后确定是否可以进行二级索引查找,查找到之后根据二级索引读取文件,否则通过判断文件是否存在于内存中,然后通过内存读取或者返回未查找到的错误信息。
如图4所示,具体算法如下
步骤S601,开始。
步骤S602,输入需要读取的文件名objName,设置文件大小阈值K。
步骤S603,判断objName文件的大小是否大于K,如果大于K,进入步骤S612,否则进入步骤S604。
步骤S604,通过查询数据映射信息,找到合并文件名MobjName,得到一级索引。
步骤S605,通过BoomFilter过滤,如果过滤成功,进入步骤S606,否则进入步骤S609。
步骤S606,根据MobjName和objName找到二级索引。
步骤S607,根据所得到的二级索引读取文件。
步骤S608,结束。
步骤S609,判断文件是否在内存中,如果在内存中,则进入步骤S610,否则进入步骤S611。
步骤S610,从内存中读取文件,进入步骤S611。
步骤S611,返回未查找到的错误信息“not found”,进入步骤S608。
步骤S612,直接读取文件,进入步骤S608。
以上所述仅对本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。
- 还没有人留言评论。精彩留言会获得点赞!