基于关键路径的违法网站识别系统及其方法与流程
本发明涉及网站识别分类领域,尤其涉及违法网站识别
技术领域:
,具体是指一种基于关键路径的违法网站识别系统及其方法。
背景技术:
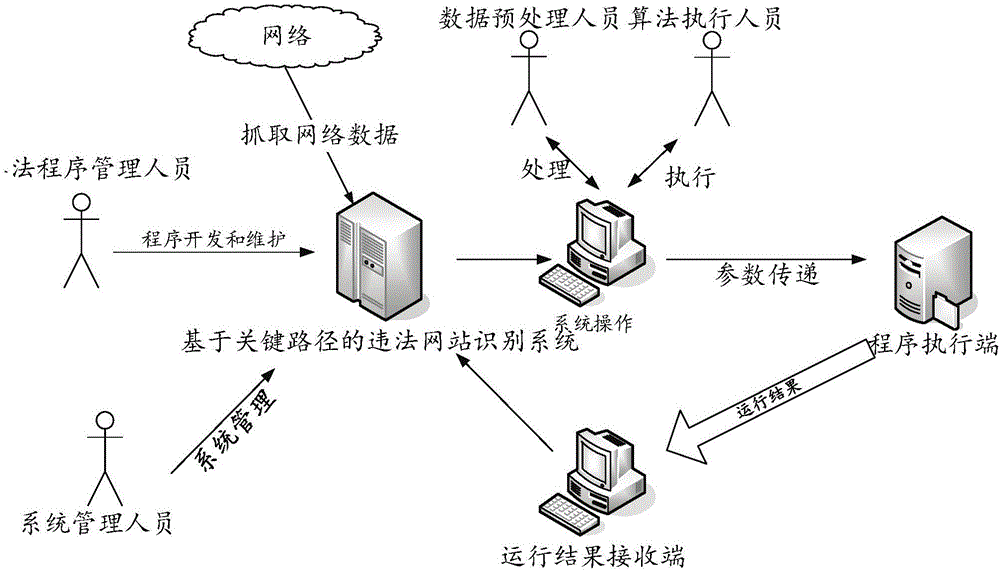
:识别违法网站是网络安全领域的一项重要工作,其识别方法的准确性和时效性也有了更高的要求。目前,现有的网站聚类研究多从用户访问行为的角度出发,从Web日志中获取用户访问网站的数据,包括用户的访问路径、访问频率、访问时间以及访问爱好等,建立用户事务矩阵,进而对用户群体和网站进行聚类。然而,这种间接的网站聚类方法不够准确,不能实现违法网站的快速识别。在违法网站自动识别的专业领域,已有研究主要基于黑名单、静态检测和动态检测三类技术,但建立和维护黑名单的工作量大且成本高,静态检测多数通过网络爬虫获取网站静态数据,对未知违法网站检测不够及时,动态检测实施难度大,并且主要针对挂马类网站,能识别的网站类别有限。综上可见,目前通过网站相似度和网站关键路径识别违法网站的研究还不多,尤其是针对违法网站URL关键路径的研究还很少。技术实现要素:为了克服上述现有技术中的问题,本发明提出了一种工作量小、能及时检测未知违法网站、实施难度小、能识别多种网站类别的基于关键路径的违法网站识别系统及其方法。本发明的基于关键路径的违法网站识别系统及其方法具体如下:该基于关键路径的违法网站识别系统,包括用户层、应用服务层、技术支撑层和数据存储层,其主要特点是,所述的用户层用以提供系统主要账户;所述的应用服务层用以提供系统主要功能模块,供所述的用户层中的系统主要账户调用;所述的技术支撑层用以提供系统开发工具及核心的算法程序,供所述的应用服务层的系统主要功能模块调用;所述的数据存储层用以为所述的用户层、应用服务层和技术支撑层提供和存储数据。较佳地,所述的系统主要账户包括数据预处理账户、算法程序管理账户、算法执行账户和系统管理账户,其中:所述的数据预处理账户用以实现该系统的数据处理程序的开发、数据处理程序的运行以及数据处理后该系统所获取数据的管理;所述的算法程序管理账户用以实现对该系统的算法的开发与维护,其中,所述的算法包括相似度算法、聚类算法、关键路径提取算法和违法网站识别算法;所述的算法执行账户用以实现按需调整算法参数、在ApacheSpark平台运行算法以及存储和管理算法的运行结果;所述的系统管理账户用以实现对所述的系统中的账户、角色和权限资源信息的分配和维护以及数据库的备份。较佳地,所述的系统主要功能模块包括数据预处理模块、网站相似度计算模块、网站聚类模块、违法网站关键路径提取模块和违法网站识别模块,其中,所述的数据预处理模块用以对其获取的训练网站的URL进行预处理,获取Host和Path;所述的网站相似度计算模块用以根据该系统获取的训练网站的URL的Host和Path获取训练网站的Path相似度和Host相似度;所述的网站聚类模块用以获取一最优相似度阈值;所述的违法网站关键路径提取模块用以提取违法网站的关键路径构成一识别违法网站的关键路径知识库,该识别违法网站的关键路径知识库位于所述的数据存储层;所述的违法网站识别模块用以结合所述的违法网站关键路径知识库判断待识别网站是否为违法网站。该基于以上所述的系统实现基于关键路径的违法网站识别方法,其主要特点是,所述的方法包括以下步骤:(1)所述的违法网站识别系统分析训练网站,构建一违法网站识别系统关键路径知识库;(2)所述的违法网站识别系统根据从待识别网站中获取的数据、所述的违法网站识别系统关键路径知识库以及所述的违法网站识别模块判断该待识别网站是否为违法网站。较佳地,所述的步骤(1)的具体步骤为:(1.1)所述的违法网站识别系统通过所述的数据预处理模块获取训练网站URL的Host和Path;(1.2)所述的违法网站识别系统根据所述的步骤(1.1)中获取的训练网站URL的Host的数据、Path的数据和所述的网站相似度计算模块获取训练网站间的Host相似度和Path相似度;(1.3)所述的违法网站识别系统根据所述的步骤(1.2)中的Host相似度、Path相似度和所述的网站聚类模块确定一最优相似度阈值;(1.4)所述的违法网站识别系统根据所述的步骤(1.2)中获取的Host相似度和Path相似度和所述的步骤(1.3)中获取的最优相似度阈值以及所述的违法网站关键路径获取训练网站的关键路径,并将训练网站的关键路径并入一违法网站识别系统关键路径知识库,该违法网站识别系统关键路径知识库存储于所述的数据存储层。更佳地,所述的步骤(1.1)中的获取网站URL的Host和Path具体为:所述的违法网站识别系统获取训练网站的URL,并通过所述的数据预处理模块提取训练网站的URL的Host和Path,其中,所述的数据预处理模块通过SQL语句将其获取的待识别网站的URL切分为Host、Path和Query。更佳地,所述的步骤(1.2)中的违法网站识别系统获取网站的相似度具体为:所述的违法网站识别系统通过所述的网站相似度计算模块获取该网站的Host相似度和Path相似度,其中,所述的违法网站识别系统通过一Host相似度计算模块获取Host相似度,该违法网站识别系统通过一Path相似度计算模块获取Path相似度。尤佳地,所述的违法网站识别系统通过其获取的Path计算模块获取Path相似度具体为:所述的违法网站识别系统通过所述的网站相似度计算模块将其获取的训练网站的Path按Path层级存储到所述的数据存储层,并比较训练网站处于同一层级的Path以获取相似度;所述的违法网站识别系统通过其获取的Host获取Host相似度具体为:所述的违法网站识别系统通过所述的网站相似度计算模块将其获取到的训练网站的最大Path相似度作为训练网站的Host相似度。更佳地,所述的步骤(1.3)中的违法网站识别系统选择相似度阈值的具体步骤为:(1.3.1)所述的违法网站识别系统根据其所获取的Path相似度和Host相似度确定一相似度阈值,并将其获取的Host相似度与该相似度阈值进行比较,高于该相似度阈值的即作为有效相似度,低于该相似度阈值即作为无效相似度;(1.3.2)所述的违法网站识别系统将其获取的具有有效相似度的训练网站通过所述的网站聚类模块进行聚类运算,聚类运算的算法为FastUnfolding算法,且该违法网站识别系统判断聚类运算结果是否满足实际需要,如果满足实际需要,则该相似度阈值即为最优相似度阈值;否则修改该相似度阈值,并进入步骤(1.3.1)。更佳地,所述的步骤(1.4)中的违法网站识别系统获取训练网站的关键路径具体为:所述的违法网站识别系统通过所述的违法网站关键路径提取模块将其获取的Host相似度高于最优相似度阈值的Host中包括的Path作为关键Path,并将其加入所述的违法网站识别系统关键路径知识库。更佳地,所述的步骤(2)中的违法网站识别系统判断该待识别网站是否为违法网站具体步骤为:(2.1)所述的违法网站识别系统通过所述的数据预处理模块预处理该待识别网站的数据以获取Path、Host和Query;(2.2)所述的违法网站识别系统通过所述的违法网站识别系统分析待识别网站的Path是否含有所述的违法网站识别系统关键路径知识库中包括的关键路径;如果待识别网站的Path含有所述的违法网站识别系统关键路径知识库中包括的关键路径,则继续步骤(2.3);否则继续步骤(2.4);(2.3)所述的违法网站识别系统判定该待识别网站为违法网站;(2.4)所述的违法网站识别系统判定该待识别网站并非违法网站。采用该种结构的基于关键路径的违法网站识别系统及其方法,由于其系统基于网站相似度算法,使用Path关键路径,并基于训练网站间的相似度进行网站聚类,通过发现使违法网站聚为一簇的关键URL,提取违法网站的URL关键路径,进而得到违法网站的关键路径知识库;通过网站关键路径的匹配技术,分析未知违法网站的Path并与所述的违法网站识别系统关键路径知识库中的关键Path进行比对,若该未知网站中的Path在所述的违法网站识别系统关键路径知识库中有对应的Path,则该未知网站被判定为违法网站,若该未知网站中的Path在所述的违法网站识别系统关键路径知识库中没有对应Path,则该未知网站被判定为非违法网站。采用此类方法,检测识别未知违法网站时工作量大大减少,且能够及时检测违法网站、并由于Path的多样性,该系统不仅能准确、快速地识别违法网站,而且能长期积累URL关键路径,建立违法网站的关键路径知识库,可为后续的违法网站研究提供可靠的基础,为网络安全管理工作提供可靠的技术支持。附图说明图1为本发明的基于关键路径的违法网站识别系统的系统框架图。图2为本发明的基于关键路径的违法网站识别系统的系统物理框架图。图3为本发明的基于关键路径的违法网站识别系统的系统功能模块图。图4为本发明的基于关键路径的违法网站识别系统的数据预处理规则示意图。图5为本发明的基于关键路径的违法网站识别系统的Path相似度计算流程。图6为本发明的基于关键路径的违法网站识别系统的一种具体实施例中的方法流程图。图7为本发明的基于关键路径的违法网站识别系统的聚类效果示例图。具体实施方式为了更好的描述本发明的技术方案,下面给出具体实施例进行进一步说明。请参阅图1所示,该基于关键路径的违法网站识别系统,包括用户层、应用服务层、技术支撑层和数据存储层。,请参阅图2所示,所述的用户层用以提供系统主要账户,包括数据预处理账户、算法程序管理账户、算法执行账户和系统管理账户,其中:所述的数据预处理账户用以实现该系统的数据处理程序的开发、数据处理程序的运行以及数据处理后该系统所获取数据的管理所述的算法程序管理账户用以实现对该系统的算法的开发与维护,其中,所述的算法包括相似度算法、聚类算法、关键路径提取算法和违法网站识别算法;所述的数据预处理账户和所述的算法程序管理账户根据需求调用系统的各个功能模块,设定程序执行的各个参数,运行的结果通过将接收端回传给本系统,并将参数传递至程序执行端;所述的算法执行账户用以实现按需调整算法参数、在ApacheSpark平台运行算法以及存储和管理算法的运行结果,且所述的算法程序管理账户可查看系统运行的结果,并在必要时对算法进行修改和优化;所述的系统管理账户用以实现对所述的系统中的账户、角色和权限资源信息的分配和维护以及数据库的备份。所述的应用服务层用以提供系统主要功能模块,供所述的用户层中的系统主要账户调用,包括数据预处理模块、网站相似度计算模块、网站聚类模块、违法网站关键路径提取模块和违法网站识别模块。所述的数据预处理模块用以对其获取的训练网站的URL进行预处理,获取Host和Path;所述的网站相似度计算模块用以根据该系统获取的训练网站的URL的Host和Path获取训练网站的Path相似度和Host相似度;所述的网站聚类模块用以获取一最优相似度阈值;所述的违法网站关键路径提取模块用以提取违法网站的关键路径构成一识别违法网站的关键路径知识库,该识别违法网站的关键路径知识库位于所述的数据存储层;所述的违法网站识别模块用以结合所述的违法网站关键路径知识库判断待识别网站是否为违法网站。所述的技术支撑层用以提供系统开发工具及核心的算法程序,供所述的应用服务层的系统主要功能模块调用;所述的数据存储层用以为所述的用户层、应用服务层和技术支撑层提供和存储数据。以上系统实现基于关键路径的违法网站识别方法包括以下步骤:(1)所述的违法网站识别系统分析训练网站,构建一违法网站识别系统关键路径知识库,其中,步骤(1)的具体步骤为:(1.1)所述的违法网站识别系统通过所述的数据预处理模块获取训练网站URL的Host和Path,其中,获取网站URL的Host和Path具体为:所述的违法网站识别系统获取训练网站的URL,并通过所述的数据预处理模块提取训练网站的URL的Host和Path,其中,所述的数据预处理模块通过SQL语句将其获取的待识别网站的URL切分为Host、Path和Query;(1.2)所述的违法网站识别系统根据所述的步骤(1.1)中获取的训练网站URL的Host的数据、Path的数据和所述的网站相似度计算模块获取训练网站的Host相似度和Path相似度,其中,违法网站识别系统获取训练网站的相似度具体为:所述的违法网站识别系统通过所述的网站相似度计算模块获取该网站的Host相似度和Path相似度,其中,所述的违法网站识别系统通过一Host相似度计算模块获取Host相似度,通过所述的网站相似度计算模块将其获取到的训练网站的最大Path相似度作为训练网站的Host相似度;该违法网站识别系统通过一Path相似度计算模块获取Path相似度,利用所述的网站相似度计算模块将其获取的训练网站的Path按Path层级存储到所述的数据存储层,并比较训练网站处于同一层级的Path以获取相似度;(1.3)所述的违法网站识别系统根据所述的步骤(1.2)中的Host相似度、Path相似度和所述的网站聚类模块确定一最优相似度阈值,其中,违法网站识别系统选择相似度阈值的具体步骤为:(1.3.1)所述的违法网站识别系统根据其所获取的Path相似度和Host相似度确定一相似度阈值,并将其获取的Host相似度与该相似度阈值进行比较,高于该相似度阈值的即作为有效相似度,低于该相似度阈值即作为无效相似度;(1.3.2)所述的违法网站识别系统将其获取的具有有效相似度的训练网站通过所述的网站聚类模块进行聚类运算,聚类运算的算法为FastUnfolding算法,且该违法网站识别系统判断聚类运算结果是否满足实际需要,如果满足实际需要,则该相似度阈值即为最优相似度阈值;否则修改该相似度阈值,并进入步骤(1.3.1);(1.4)所述的违法网站识别系统根据所述的步骤(1.2)中获取的Host相似度和Path相似度和所述的步骤(1.3)中获取的最优相似度阈值以及所述的违法网站关键路径获取训练网站的关键路径,并将训练网站的关键路径并入一违法网站识别系统关键路径知识库,该违法网站识别系统关键路径知识库存储于所述的数据存储层,具体为:所述的违法网站识别系统通过所述的违法网站关键路径提取模块将其获取的Host相似度高于最优相似度阈值的Host中包括的Path作为关键Path,并将其加入所述的违法网站识别系统关键路径知识库;(2)所述的违法网站识别系统根据从待识别网站中获取的数据、所述的违法网站识别系统关键路径知识库以及所述的违法网站识别模块判定该待识别网站是否为违法网站其中,所述的违法网站识别系统判断该网站是否为违法网站具体步骤为:(2.1)所述的违法网站识别系统通过所述的数据预处理模块预处理该待识别网站的据以获取Path、Host和Query;(2.2)所述的违法网站识别系统通过所述的违法网站识别系统分析待识别网站的Path是否含有所述的违法网站识别系统关键路径知识库中包括的关键路径;如果待识别网站的Path含有所述的违法网站识别系统关键路径知识库中包括的关键路径,则继续步骤(2.3);否则继续步骤(2.4);(2.3)所述的违法网站识别系统判定该待识别网站为违法网站;(2.4)所述的违法网站识别系统判定该待识别网站并非违法网站。请参阅图3,按功能详细划分,基于关键路径的违法网站识别系统的功能模块包括:数据预处理、网站相似度计算、网站聚类、违法网站关键路径提取、违法网站识别。其中网站相似度计算模块细分为Path相似度计算和Host相似度计算两个子模块。下面分别对这六个功能模块的工作原理进行详细介绍。(1)数据预处理:使用SQL语句对数据进行预处理。请参阅图4,数据预处理将网站的URL切分为“Host”、“Path”、“Query”三个部分。(2)Path相似度计算:请参阅图5,每个网站包含多个不同的URL,即一个Host对应多个Path,Path代表用户访问网页的动作路径,同类网站具有类似的动作路径。Path相似度指计算不同URL的Path部分的相似度,Path部分按照层级划分,通过比较不同Path在同一层级的值来计算相似度。如“http://www.sekongge1.com/attachment/js/foothf.js”,其中“http://www.sekongge1.com”为Host,“attachment”称为路径Path的1级目录,“js”称为路径Path的2级目录,依此类推。(3)Host相似度计算:每个Host有多个Path,基于Path相似度计算模块,已经得到了所有的Path相似度,取Path相似度中的最大值作为这两个Host间的相似度。两个Host之间的相似度取Path相似度的最大值,而不是所有Path相似度的总和或平均值,这在一定程度上能减弱每个Host路径数量不同这个问题带来的影响。并且,这种最长路径之间的匹配,能体现两个Host之间的最大相似程度。(4)网站聚类:基于上述网站间相似度计算的结果,确定相似度的阈值,即筛选出高于此阈值的相似度作为有效的相似度,然后再对网站进行聚类。若聚类效果不满足要求,则再次修改相似度阈值,重新进行聚类,如此循环,直到聚类效果符合要求。此过程可发现最优的相似度阈值,这是提取违法网站URL关键路径的重要基础。网站与网站之间的联系形成一个复杂的网络,在复杂网络中发现联系紧密的社区,即可将相似网站进行聚类。在一种具体的实施例中,可选择FastUnfolding这种社区发现算法进行聚类。FastUnfolding算法是一种基于模块最大化(ModularityOptimization)的启发式方法,根据Modularity值的大小评估社区发现的效果。通过使Modularity值最大化,得到最优的社区发现策略,从而达到最优的网站聚类效果。在一种具体的实施例中,可使用人工标注过的网站进行聚类运算,即每个网站的网站类型是已知的,因此聚类运算后可通过人工核对来评价聚类的实际效果。(5)违法网站URL关键路径提取:在违法网站有效聚类的基础上,研究使得违法网站聚为一簇的关键因素,即可抽取这些违法网站的关键路径,并入违法网站识别系统关键路径知识库。根据网站相似度计算模型,选取最大的Path相似度作为网站间的Host相似度,当此聚类有效时,说明这些相似度对应的Path就是使得违法网站聚为一簇的关键因素。(6)违法网站识别:基于违法网站识别系统关键路径知识库,通过代码实现,可检测未知网站的Path是否含有违法网站识别系统关键路径知识库中的关键路径,从而判断该网站是否是违法网站。在一个具体实施例中,基于关键路径的违法网站识别系统以网站本身的特征作为研究的着手点,开发基于Path相似度计算程序,能够准确地计算网站间的相似度,基于网站相似度和FastUnfolding聚类算法得到有效的关键路径,最后,根据违法网站识别系统关键路径知识库,只需分析得待识别网站的Path、并对该待识别网站的Path与所述的违法网站识别系统关键路径知识库中的关键Path进行快速匹配,即可发现未知网站中的违法网站。请参阅图6,本系统的方法主要包括两个步骤:(1)数据预处理,具体指从真实的网络环境中抽取数据,通过数据预处理,提取网站URL的Host和Path部分。以人工标注过的违法网站为训练集,抽取这些违法网站的Host和Path数据。(2)相似度计算,是基于本系统中的相似度计算模型,计算违法网站的Path相似度和Host相似度。(3)网站聚类,是基于违法网站的Host相似度,使用FastUnfolding算法进行网站聚类,通过评估聚类效果,选择使聚类效果达到最优相似度阈值。(4)抽取违法网站的关键路径,基于网站聚类中确定的最优相似度阈值,确定从URL路径中抽取关键路径的层级数,从而提取违法网站的关键路径,并入到违法网站关键路径知识库中。(5)识别违法网站是根据积累的违法网站关键路径知识库,检测待识别网站的Path部分是否包含这些关键路径,以此判断是否是违法网站。在一个具体实施例中,以3万个赌博网站为样本,通过本系统进行计算,3分钟内计算得到了1170个赌博网站的关键路径,根据这些网站的关键路径匹配到了22066条访问赌博网站的记录,准确率为98%。在一个具体实施例中,Host间相似度计算示如下表所示,Hosta和Hostb之间的相似度为30。以10万个URL为计算实例(该数据为真实网络环境中获取的数据)。这10万个URL是人工进行标注之后的数据,网站类型是已知的。将数据导入到本系统中,进行预处理和计算,部分相似度计算结果下表所示。Host1Host2相似度0002.amljw027.com20002.amm.309111.com20002.amm.5448ii.com20002.amwww.22hh163.com60002.amwww.7111x.com60002.amwww.54bwin.com60002.am444ylg.com6请参阅图7,基于网站相似度计算结果进行网站聚类,违法网站主要分为赌博、色情、涉恐三大类。请参阅下表,本系统的基于关键路径的违法网站识别系统及其方法对待识别网站进行分析,可得到各类网站的关键路径,以赌博网站为例。关键路径/app/member/account/app/member/add_reg_mem.php/app/member/check_ip_enable.php/app/member/check_login_domain.php/app/member/check_user.php/app/member/FT_browse根据得到的关键路径知识库,在未知网站库中进行匹配,以赌博网站的关键路径识别到了22066条访问赌博网站的记录,准确率为98%。采用该种结构的基于关键路径的违法网站识别系统及其方法,由于其系统基于网站相似度算法,使用Path关键路径,并基于训练网站间的相似度进行网站聚类,通过发现使违法网站聚为一簇的关键URL,提取违法网站的URL关键路径,进而得到违法网站的关键路径知识库;通过网站关键路径的匹配技术,分析未知违法网站的Path并与所述的违法网站识别系统关键路径知识库中的关键Path进行比对,若该未知网站中的Path在所述的违法网站识别系统关键路径知识库中有对应的Path,则该未知网站被判定为违法网站,若该未知网站中的Path在所述的违法网站识别系统关键路径知识库中没有对应Path,则该未知网站被判定为非违法网站。采用此类方法,检测识别未知违法网站时工作量大大减少,且能够及时检测违法网站、并由于Path的多样性,该系统不仅能准确、快速地识别违法网站,而且能长期积累URL关键路径,建立违法网站的关键路径知识库,可为后续的违法网站研究提供可靠的基础,为网络安全管理工作提供可靠的技术支持。在此说明书中,本发明已参照其特定的实施例作了描述。但是,很显然仍可以作出各种修改和变换而不背离本发明的精神和范围。因此,说明书和附图应被认为是说明性的而非限制性的。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 智能选择性的基于流的数据路径结构的制作方法
- 具有管理多路重现路径视频数据的重现的数据结构的记录介质及记录和重现的方法和装置的制作方法
- 具有管理多路重现路径视频数据重现的数据结构的记录介质及记录和重现的方法和装置的制作方法
- 具有用于管理记录在其上面的关于标题的至少一个分段的多个再现路径视频数据的再现 ...的制作方法
- 导航设备及导航路径上关键路况的提示方法与装置的制作方法
- 关系型数据库和网状数据结构相结合的关系路径搜索方法
- 基于改进万有引力算法的多时间窗车辆路径选择方法
- 一种基于动态选路算法的临床路径变异管理的系统和方法
- 基于遥感图像变化检测算法的投资项目智能搜索技术的制作方法
- 一种基于关键路径和禁忌搜索的测试任务调度方法