基于微容器实现的大数据云平台的制作方法
本发明涉及大数据云平台领域,尤其涉及分布式大数据框架的云平台领域,具体是指一种基于微容器实现的大数据云平台。
背景技术:
随着大数据需求的不断攀升以及云计算平台的不断普及,对于大数据和云平台的结合开始受到大家的广泛关注。而现有云平台通常采用VM等重量级虚拟机技术,镜像的调度比较迟缓,并且现有的虚拟云平台大多无法满足跨越物理机网络进行快速部署分布式计算框架。本发明给出了一种轻量级云平台的构建技术,并且能够完成对于大数据框架的定制化镜像服务,秒级速度完成大数据框架跨物理机的快速部署和销毁,最大程度简化了大数据平台的构建成本。
在通常情况下,企业单位中仍然使用裸机安装Hadoop,Spark,Storm等大数据应用,尽管现在拥有了Yarn、Mesos等资源统一协调调度方案,但是粒度较粗,尤其针对多样性集群(集群中机器配置不一致)难以完成资源的合理利用和分配。并且针对不同租户的应用场景,计算资源和存储资源结合过于紧密,很难做到计算资源的自由创建和销毁。而如果采用传统意义上的虚拟云平台,虚拟机的创建和回收开销过大。
技术实现要素:
为了克服上述现有技术中的问题,本发明提出了一种开销小、支配计算资源的自由度大的基于微容器实现的大数据云平台。
本发明的基于微容器实现的大数据云平台具体如下:
该基于微容器实现的大数据云平台,其主要特点是,所述的大数据云平台包括上层和下层,其中所述的上层包括多个Docker容器,所述的下层为存储系统,且所述的存储系统向所述的所有的Docker容器开放。
较佳地,所述的存储系统为一通过Ambari搭建的基于HDFS的分布式存储系统。
更佳地,所述的基于HDFS的分布式存储系统其上还设置有一Hive层,该Hive层用以实现对结构化数据的处理,所述的Hive层包括一Hive数据接口,所述的基于HDFS的分布式存储系统包括一HDFS数据接口,所述的Hive层和所述的基于HDFS的分布式存储系统分别通过所述的Hive层数据接口和所述的HDFS数据接口与所述的所有的Docker容器相连接。
较佳地,所述的Docker容器中封装有该大数据云平台实现所需的计算资源。
较佳地,所述的计算资源通过所述的上层中的一Docker_FILE组件进行镜像定制。
更佳地,所述的大数据云平台包括一Swarm管理框架,该Swarm管理框架用以实现对所述的Docker容器的启停、编排管理,并用以分发和管理所述的镜像。
尤佳地,所述的Swarm管理框架还内设置有一Overlay网络,该Overlay网络实现所述的上层和下层的交互,以及消除连接至该大数据云平台的不同物理主机上各个容器的网络访问限制。
较佳地,所述的大数据云平台通过管理员端部署Consule组件以协调跨物理主机容器的网络分配,且所述的所有的Docker容器均通过Consule组件完成网络分配。
较佳地,所述的上层还包括一本地镜像仓库,用以存储镜像源,且所述的本地镜像仓库还包括所述的计算资源的文本编排后获取所述的计算资源的编排文本。
更佳地,所述的上层还包括一Shipyard组件,用以实现对所述的镜像源生成的大数据集群的启停、销毁和可视化状态维护的操作,且该Shipyard组件还对所述的计算资源的编排文本进行引用和具体部署操作。
采用了该发明的基于微容器实现的大数据云平台,由于其中采用了轻量级虚拟技术Docker与大数据框架进行结合的方式,并采用了存储资源和计算资源分离的方式,该大数据框架部署方案兼具了自由创建和销毁计算资源的能力和很小的系统开销。其中存储资源由管理员进行统一管理,计算资源通过使用者发起,管理者授权并且申请,然后将资源分配给使用者,当使用者使用完毕后,可以自由销毁。
该大数据云平台可以轻松实现不同版本的Spark等计算资源协同运作,实现多种不同的计算资源互不干扰的运作。由于建立在轻量级云平台之上,该大数据平台可以实现灵活插拔,且数据管理变得更加可靠,资源利用变得更加合理,同时应用之间的竞争和资源锁被消除,无需针对不同用户需求重复搭建不同应用环境,一劳永逸,将零散的环境搭建整理为统一完善的镜像资源管理,将可能存在互斥性场景的应用编排整理为自由灵活的容器资源管理。
附图说明
图1为本发明的基于微容器实现的大数据云平台的基础架构图。
图2为本发明的基于微容器实现的大数据云平台的系统架构图。
图3为本发明的基于微容器实现的大数据云平台的工作原理图。
图4为本发明的基于微容器实现的大数据云平台的基本流程图。
具体实施方式
为了更好的说明对本发明进行说明,下面举出一些实施例来对本发明进行进一步的说明。
该基于微容器实现的大数据云平台,其主要特点是,所述的大数据云平台包括上层和下层,其中所述的上层包括多个Docker容器,,所述的Docker容器中封装有该大数据云平台实现所需的计算资源,所述的下层为存储系统,且所述的存储系统向所述的所有的Docker容器开放,所述的计算资源通过所述的上层中的一Docker_FILE组件进行镜像定制,且所述的大数据云平台通过管理员端部署Consule组件以协调跨物理主机容器的网络分配,且所述的所有的Docker容器均通过Consule组件完成网络分配。
在一种较佳的实施例中,所述的存储系统为一通过Ambari搭建的基于HDFS的分布式存储系统。
在一种更佳的实施例中,所述的基于HDFS的分布式存储系统其上还设置有一Hive层,该Hive层用以实现对结构化数据的处理,所述的Hive层包括一Hive数据接口,所述的基于HDFS的分布式存储系统包括一HDFS数据接口,所述的Hive层和所述的基于HDFS的分布式存储系统分别通过所述的Hive层数据接口和所述的HDFS数据接口与所述的所有的Docker容器相连接。
在一种较佳的实施例中,所述的大数据云平台包括一Swarm管理框架,该Swarm管理框架用以实现对所述的Docker容器的启停、编排,并用以分发和管理所述的镜像,且所述的Swarm管理框架还内设置有一Overlay网络,该Overlay网络实现所述的上层和下层的交互,以及消除连接至该大数据云平台的不同物理主机上各个容器的网络访问限制。
在一种较佳的实施例中,所述的上层还包括一本地镜像仓库,用以存储镜像源,且所述的本地镜像仓库还包括所述的计算资源的文本编排后获取所述的计算资源的编排文本,且所述的上层还包括一Shipyard管理集群,用以实现对所述的镜像源生成的大数据集群的启停、销毁和可视化状态维护的操作,且该Shipyard管理集群还对所述的计算资源的编排文本进行引用和具体部署操作。
请参阅图1,在一种具体的实施方式中,所述的大数据平台采用存储资源和计算资源隔离的方式,首先在底层通过Ambari搭建基于HDFS的分布式存储系统,而上层使用Docker容器封装计算资源,通过Docker容器制作Spark镜像,Storm镜像和Hbase镜像等虚拟化资源后,再通过微容器管理框架Swarm完成对Docker容器的启停和编排。
基于HDFS的分布式存储系统上层部署有一Hive层,用以完成对于结构化数据的处理,Hive层和基于HDFS的分布式存储系统分别具有Hive数据接口和HDFS数据接口,且Hive数据接口和HDFS数据接口向所有Docker容器开放,达到Docker容器可以自由访问数据的目的。
且上层计算资源通过Docker_File进行镜像定制化,通过Swarm管理框架完成镜像的分发和管理。管理员端部署Consule组件,用以完成对于跨物理主机容器网络分配的协调工作,所有Docker容器通过Consule组件完成网络分配,确保容器IP不会产生冲突。
且整个Docker容器集群向Swarm管理集群构建Overlay网络,用以消除不同物理主机上各个Docker容器的网络访问限制,由于各个Docker容器在物理主机会被分配Docker网桥所划分的内网地址,Docker网桥和宿主机连通,所以当前物理主机上容器只能连通当前物理主机,无法实现跨物理主机的互相访问,通过以上方法既完成了跨域访问,同时又完成了IP地址的统一分配。
底层的构建完毕,上层镜像制作完成,网络打通,便可以通过自由参数来灵活创建定制化的大数据集群。
接着通过部署Shipyard组件完成大数据集群启停,销毁和状态维护的可视化,一键完成Spark等上层分布式计算平台的部署工作。
最后建立本地镜像仓库,通过社区力量和定制化镜像完成镜像源的扩充,制作针对每一组计算资源的编排文本,统一将容器编排文本进行管理和存储,通过Shipyard界面完成对编排后的计算资源的文本文件的引用和具体部署实施,针对最常用的计算集群保存模板,实现真正的一键部署,一键销毁。
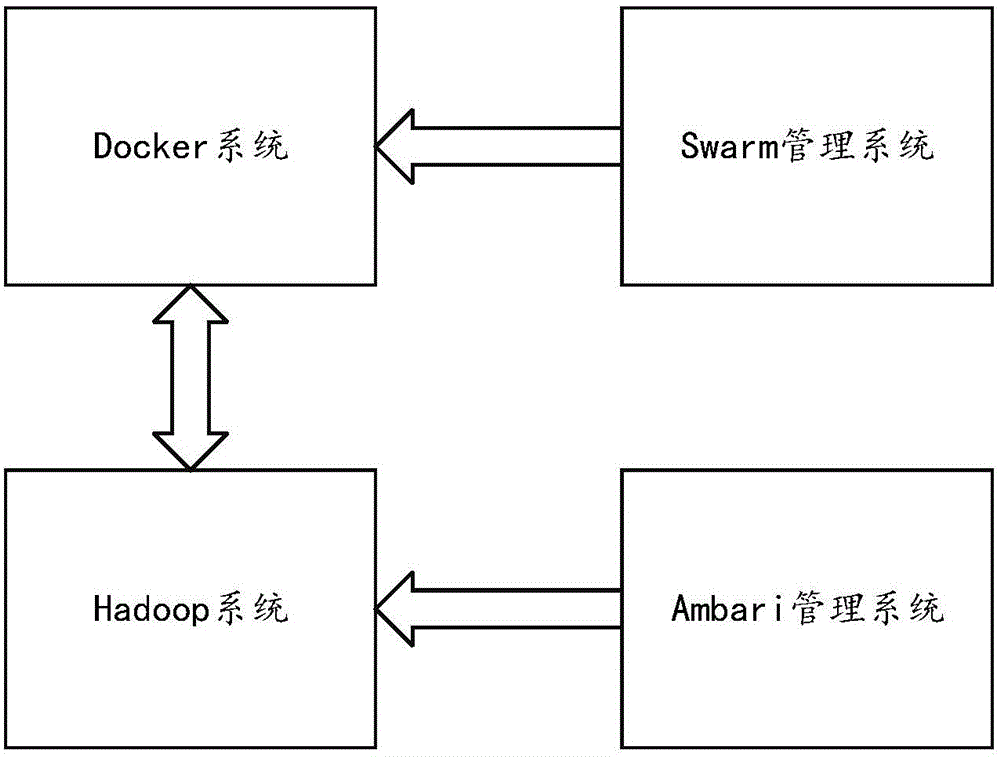
请参阅图2,在一种具体实施例中,所述的上层为由Swarm管理系统管理的Docker系统,所述的下层为由Ambari管理系统管理的Hadoop系统。
请参阅图3,在一种具体的实施例中,所述的Swarm管理系统中还部署有一Overlay网络层,用以实现Hadoop系统和Docker系统的交互。
请参阅图4,在一种具体的实施例中,该大数据云平台的应用过程如下:
用户进行资源申请,通过页面提交请求,管理员针对用户请求进行授权,通过页面进行资源申请,并且选取用户需求的调度脚本,由Swarm统一完成资源的分配,启动完毕所有的计算资源之后,系统分配给用户一个具有VNC功能的容器,用户通过页面获取到VNC容器访问的地址和端口,然后通过WEB浏览器开始对于计算集群的使用。
用户使用完毕后,可以将数据存储到本地挂靠的存储卷中或者基于HDFS的分布式存储系统中。然后可以手动销毁所申请的计算资源或者交由管理员端进行销毁,Swarm接受到用户的销毁请求调用销毁脚本完成对容器的删除操作,资源进行归还。
采用了该发明的基于微容器实现的大数据云平台,由于其中采用了轻量级虚拟技术Docker与大数据框架进行结合的方式,并采用了存储资源和计算资源分离的方式,该大数据云平台兼具了自由创建和销毁计算资源的能力和很小的系统开销。其中存储资源由管理员端进行统一管理,计算资源通过使用者发起,管理者端授权并且申请,然后将资源分配给使用者,当使用者使用完毕后,可以自由销毁。
该大数据云平台可以轻松实现不同版本的Spark等计算资源协同运作,实现多种不同的计算资源互不干扰的运作。由于建立在轻量级云平台之上,该大数据平台可以实现灵活插拔,且数据管理变得更加可靠,资源利用变得更加合理,同时应用之间的竞争和资源锁被消除,无需针对不同用户需求重复搭建不同应用环境,一劳永逸,将零散的环境搭建整理为统一完善的镜像资源管理,将可能存在互斥性场景的应用编排整理为自由灵活的容器资源管理。
在此说明书中,本发明已参照其特定的实施例作了描述。但是,很显然仍可以作出各种修改和变换而不背离本发明的精神和范围。因此,说明书和附图应被认为是说明性的而非限制性的。
- 还没有人留言评论。精彩留言会获得点赞!