数据处理方法、数据识别和学习方法及其装置与流程
技术特征:
1.一种数据处理方法,包括:
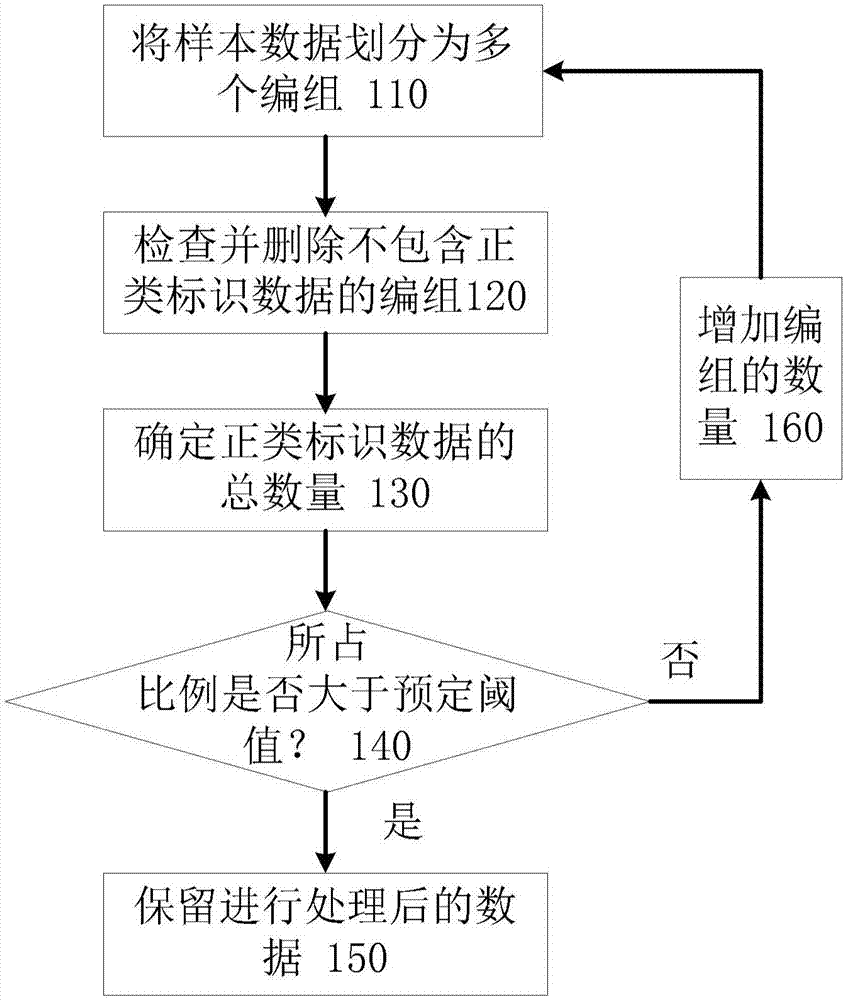
(a)通过聚类的方式将样本数据划分为多个编组;
(b)检查所述多个编组中每个编组是否存在正类标识数据,并删除不包含正类标识数据的编组;
(c)确定所述多个编组中正类标识数据的总数量;
(d)确定所述正类标识数据的总数量在所述样本数据中所占比例是否大于第一预定阈值;以及
(e)在所述比例大于所述第一预定阈值的情况下,保留进行步骤(b)处理后的数据。
2.根据权利要求1所述的数据处理方法,还包括:
(f)在所述比例小于所述第一预定阈值的情况下,将步骤(b)处理后的数据作为所述样本数据执行步骤(a)-(e),其中,在重复执行的步骤(a)中增加编组的数量。
3.根据权利要求2所述的数据处理方法,还包括:
设置编组的最大数量值;
在步骤(f)中,如果当前编组的数量大于等于所述最大数量值,不再增加编组的数量,并保留最近一次步骤(b)处理后的数据,结束所述数据处理。
4.根据权利要求1至3中任一项所述的数据处理方法,其中,采用k-means算法来实现所述聚类的方式,
其中,通过k-means算法确定所述编组的初始数量,使得在所述初始数量处,各个聚类内的数据方差的总体变化减缓。
5.根据权利要求4所述的数据处理方法,其中,步骤(a)包括:
(a1)在所述样本数据中随机抽取多个样本数据分别作为所述多个编组中每个编组的中心点,所述多个数据样本的数量与要划分的所述多个编组的数量相等;
(a2)计算所有数据样本到每个中心点的距离,将每个数据样本划分到距离其最近的中心点所在的编组中;
(a3)计算每个编组中所有数据样本的平均值,并将所述平均值作为所述每个编组中新的中心点;
(a4)针对所述每个编组,判断所述新的中心点与之前的中心点之差是否大于第二预定阈值,以及如果中心点之差大于所述第二预定阈值,则使用所述新的中心点执行步骤(a2)和(a3),如果中心点之差不大于所述第二预定阈值,将所述新的中心确定为最优聚类中心;以及
(a5)计算所有样本数据到每个最优聚类中心点的距离,将每个样本数据重新划分到距离其最近的最优聚类中心点所在的编组中。
6.一种用于模式识别和学习的方法,包括:
基于权利要求1至5中任一项所述的数据处理方法获得样本数据的经处理的多个编组;以及
基于所述样本数据的经处理的多个编组来执行模式识别和学习。
7.一种数据处理装置,包括:
编组划分模块,用于通过聚类的方式将样本数据划分为多个编组;
数据检查模块,用于检查所述多个编组中每个编组是否存在正类标识数据;
数据删除模块,用于删除不包含正类标识数据的编组;
数据数量确定模块,用于确定所述多个编组中正类标识数据的总数量;
数据比例确定模块,用于确定所述正类标识数据的总数量在所述样本数据中所占比例是否大于第一预定阈值;以及
数据保留模块,用于在所述比例大于所述第一预定阈值的情况下,保留所述数据删除模块处理后的数据。
8.根据权利要求7所述的数据处理装置,其中,所述编组划分模块还用于在所述比例小于所述第一预定阈值的情况下,将所述数据删除模块处理后的数据作为所述样本数据来执行编组划分,以重复所述数据检查模块、所述数据删除模块、所述数据数量确定模块、所述数据比例确定模块和所述数据保留模块的操作,其中,在对所述数据删除模块处理后的数据的编组操作中增加编组的数量。
9.根据权利要求8所述的数据处理装置,还包括:
最大编组数设置模块,用于设置编组的最大数量值;
其中,如果当前编组的数量大于等于所述最大数量值,则所述编组划分模块在重复执行数据编组操作时不再增加编组的数量,且所述数据保留模块保留最近一次所述数据删除模块处理后的数据。
10.根据权利要求7-9中任一项所述的数据处理装置,其中,所述编组划分模块采用k-means算法来实现所述聚类的方式,
其中,所述编组划分模块通过k-means算法确定所述编组的初始数量,使得在所述初始数量处,各个聚类内的数据方差的总体变化减缓。
11.根据权利要求8所述的数据处理装置,其中,所述编组划分模块还包括:
中心点确定子模块,用于在所述样本数据中随机抽取多个样本数据分别作为所述多个编组中每个编组的中心点,所述多个数据样本的数量与要划分的所述多个编组的数量相等;
中心点距离确定子模块,用于计算所有数据样本到每个中心点的距离,将每个数据样本划分到距离其最近的中心点所在的编组中;
中心点重确定子模块,用于计算每个编组中所有数据样本的平均值,并将所述平均值作为所述每个编组中新的中心点;
最优聚类中心确定子模块,用于针对所述每个编组,判断所述新的中心点与之前的中心点之差是否大于第二预定阈值,以及如果中心点之差大于所述第二预定阈值,则将所述新的中心点发送到所述中心点距离确定子模块,以重新执行数据编组和新中心点确定,如果中心点之差不大于所述第二预定阈值,将所述新的中心确定为最优聚类中心;以及
编组确定子模块,用于计算所有样本数据到每个最优聚类中心点的距离,将每个样本数据重新划分到距离其最近的最优聚类中心点所在的编组中。
12.一种用于模式识别和学习的装置,包括:
数据编组获取模块,用于从根据权利要求7至11中任一项所述的数据处理装置获得样本数据的经处理的多个编组;以及
识别和学习子模块,用于基于所述样本数据的经处理的多个编组来执行模式识别和学习。
13.一种数据处理装置,包括:
存储器,用于存储可执行指令;以及
处理器,用于执行存储器中存储的可执行指令,以执行根据权利要求1至5中任一项所述的方法。
14.一种用于模式识别和学习的装置,包括:
存储器,用于存储可执行指令;以及
处理器,用于执行存储器中存储的可执行指令,以执行根据权利要求6所述的方法。
15.一种其上承载由计算机程序的存储器设备,当由处理器执行所述计算机程序时,所述计算机程序使所述处理器执行根据权利要求1至5中任一项所述的方法。
16.一种其上承载由计算机程序的存储器设备,当由处理器执行所述计算机程序时,所述计算机程序使所述处理器执行根据权利要求6所述的方法。
- 还没有人留言评论。精彩留言会获得点赞!