一种应用于游戏道具推荐的频繁项集挖掘方法与流程
本发明属于数据挖掘领域,更具体地,涉及一种频繁项集挖掘方法。
背景技术:
数据挖掘技术自诞生以来就致力于发现隐藏在数据中有价值的信息,数据挖掘有六种模式:分类模式、聚类模式、回归模式、关联模式、序列模式和偏差模式。其中关联模式分析是其重要研究的方向。而频繁项集挖掘是关联规则挖掘算法的重要组成部分。通过频繁项集挖掘算法能够在大数据中找出有用的规则,这种方法可以应用于很多领域,如网页日志挖掘、商业销售方面、金融业方面针对不同类型客户群体推荐他们可能感兴趣的金融业务以及游戏应用道具推荐等等。然而,在大数据的背景下传统的单机挖掘方式已经无法满足人们的需求,单纯的通过提高CPU运算速度以及内存容量的方法不仅造价过高,也不现实,硬件的发展远远赶不上人们对运算速度的需求,这时并行化的运算模式显得尤为重要,通过改进或创新数据挖掘算法,并与分布式运算模式相结合是当前一个很好的可选方案。
随着网络信息时代的到来,网络游戏产业应运而生。网络游戏是文化、艺术与高科技的融合,它给我们提供了一种新的休闲娱乐方式。与此同时,网络游戏产业蓬勃发展,市场进一步扩大,网络游戏逐渐成为网络经济的领头羊。当游戏的选择越来越多,玩家的眼光越来越挑剔,只有适合玩家的游戏才能在市场上经久不衰。数据挖掘已经引起了游戏行业的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。以此来改善游戏品质,提高运营效率,为游戏运营商赢取更多用户。数据挖掘已经在各个行业得以充分运用,但网络游戏这块市场并没有充分开发完全。同时行之有效的处理游戏数据的方法还尚未明朗。
现有的频繁项集挖掘算法主要拥有以下几个缺点:
1)算法效率过低,无法再有限时间里面得到挖掘结果;
2)并行算法无法均衡的划分负载。
技术实现要素:
针对现有技术的缺陷或迫切技术需求,本发明公开了一种在MapReduce平台上并行的频繁项集挖掘方法,依据负载预测合理划分数据,保证负载均衡;通过优化递归挖掘流程,大大减少密集型数据挖掘时间,解决了算法效率低、负载不均衡的问题。
为实现上述目的,本发明有以下步骤:
一种频繁项集挖掘方法,包括以下步骤:
(1)通过Mapreduce统计原始数据中各项的出现次数;
(2)依据各项出现次数筛选出频繁一项,将频繁一项按照出现次数由高到低排序构成F-List;
(3)按照负载均衡原则对F-List中的各项分组,得到包含项和其所属组号信息的G-List;
(4)Mapper对原始数据进行分配:
(4-1)对每条原始数据的各项按照F-List中项顺序进行重新排序;
(4-2)从每条原始数据的最后一项开始读取项item,在G-List中查找item的组号gid,然后以gid作为键key,将数据中排在item前面的所有项作为值value构成键值对<key=gid,value=items>,作为Mapper输出的键值对,若组号gid已出现过,则忽略,继续取前一项进行相同操作,直到一条数据处理完毕;
(5)Reducer对Mapper输出的键值对进行频繁项集挖掘:
(5-1)根据Mapper输出的key=gid,将value=items分配给相应的reducer,reducer构建PPCtree;PPCtree为树状结构,每个节点包含五个属性值:名字、支持度frequency、子节点、前序遍历序号pre和后序遍历序号post;
(5-2)对于PPC-tree中每个节点Ni,将<Ni.pre,Ni.post,Ni.frequency>命名为PP-code,将各PP-code按照pre的升序排序,构建得到F-List中每个频繁一项的N-List;
(5-3)构建Reducer的G-Subsume:G-Subsume(A)={A,B∈I1,其中,A和B表示两个不同的频繁一项,A.gid表示项A的组号,Reducer.gid表示Reducer对应的组号,g(X)表示包含频繁一项X的数据ID的集合,X=A或B,I1表示频繁一项的集合;
(5-4)递归挖掘,其子步骤如下:
a)以F-List作为第一轮的递归初始数据,在F-List中取最后一项L,将最后一项L与其G-Subsume(L)结合,生成频繁二项集,写入结果数组Result;
b)在递归初始数据中从前往后逐一取项X,将其N-List即NX的PP-code与L的N-List即NLast的PP-code进行比较,若X存在于G-Susbume(L)中,则继续取后一项,否则:当NX的PP-code的pre小于NLast的PP-code,且NX的PP-code的post大于NLast的PP-code的post,则生成频繁二项集XL,将<NX.PP-code.pre,NX.PP-code.post,NLast.PP-code.frequency>加入频繁二项集XL的N-List即NXL,且NLast的PP-code后移;当NX的PP-code的pre小于NLast的PP-code,且NX的PP-code的post小于NLast的PP-code的post,则NX的PP-code后移;当NX的PP-code的pre大于NLast的PP-code,则NLast的PP-code后移,直到NLast和NX的PP-code都遍历完毕;
NX的PP-code遍历完毕后,若最后结果XL的N-List的PP-code的支持度之和不满足阈值,则删除XL,若满足则XL为频繁二项集;
c)继续从递归初始数据中取下一项,重复步骤b),直至递归初始数据中最后一项L之前的所有项比较完毕,即得到了以最后一项L为后缀的频繁二项集及其N-List,写入结果数组Result并将其N-List作为频繁三项集挖掘的初始数据,该频繁二项集直接与G-Subsume(L)合并得到以L为后缀的部分频繁三项集,加入数组Result;
d)在递归初始数据中取倒数第二项,重复上述步骤a)、b)、c),直至递归初始数据中所有项操作完毕,即得到了所有的频繁二项集和部分频繁三项集;
e)提取仅前缀不一样的频繁二项集作为第二轮的递归初始数据,从最后一项开始,按照与步骤b)-d)的相同方式处理,得到所有的频繁三项集,并将频繁三项集中后缀有G-Subsume的项与其G-Subsume结合得到频繁四项集;
f)以此类推,直到最后通过N-List比较得到唯一的频繁K项集,递归结束;
(5-5)Reducer输出<key=item∈gid,value=Result>,至此完成所有的频繁项集挖掘过程。
进一步的,所述步骤(1)的具体实现步骤为:
(1-1)对原始数据库进行水平分片处理,分片得到的每一个子文件叫做Block块,Block块被分配到集群中的节点上;
(1-2)Block块作为每个Map函数的输入数据,对于Block块中的一条数据Ti中的每一个项aj,Mapper的输出键值对<key=aj,value=1>;
(1-3)所有key=aj的键值对将被分配到同一个Reducer,则Reducer的输入是<key=aj,value={1,1,...,1}>,Reducer进行一次求和输出<key=aj,value=sum{1,1,...,1}>。
进一步的,所述步骤(3)中负载均衡原则为:将F-list中各项的排序号作为负载值,依据负载值对F-List中的各项分组。
进一步的,所述G-List采用哈希表存储。
本发明采用上述方案,在性能上优于其他并行算法方案,并且在游戏挖掘性能上得到很大的提升,具体如下:
1)使用N-List,这种方法可以减小复杂度,在一般的频繁项集挖掘方法中,均使用树来进行递归,不仅占用空间而且树递归复杂度远远超过该方法的递归,同时本方法采用独特的比较方法,并没有将N-List中的每个PP-code进行比较,若将两个N-List的每个PP-code进行比较,复杂度为O(mn),m和n分别为两个N-List的长度,而这种独特比较方法的复杂度仅为O(m+n),也大大减小了递归复杂度;
2)使用新的概念G-Subsume用于MapReduce的并行,在频繁项集挖掘过程中,通过G-Subsume可以减少N-List的合并比较次数,而是直接与G-Subsume进行合并,大大提高了挖掘效率;
3)一般情况下,G-List会采取取余的方式来进行分组,但是有些项递归时间久,有的递归时间短,会造成最后结果等待时间以最久的项为准,同时也会造成负载不均衡,为了均衡负载,本发明提前预估每个项的负载:在深度优先模式下,PPCTree树的深度影响着对树进行先序、后序遍历的时间,深度越大耗时越多;每一项所在PPCTree树的最大路径长度等于它在F-List中相应的排序号,而该项所对应的N-List结构的最大长度等于该项的支持数与2n-1二者之间的最小值,其中n为该项在F-List中的序号。根据以上两个规则可以轻易的预估每个项的负载,即可以实现本发明的负载均衡。
附图说明
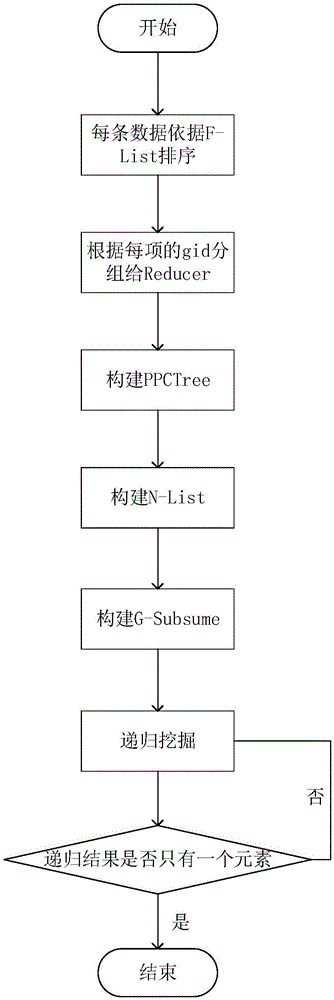
图1为本发明频繁挖掘方法的流程图;
图2为Mapper和Reducer进行频繁项集挖掘的流程图;
图3为本发明PPCTree的构建过程;
图4为本发明递归挖掘中由频繁一项集得到频繁二项集的流程图;
图5为本发明负载均衡策略的示意图;
图6为本发明MapReduce过程的示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本方面进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本方面,并不用于限定本发明。
首先对本发明涉及的术语进行说明:
频繁项集:也称为项集,项的集合称为项集;只要项集出现比例达到给定的常数s,这些项集都是频繁项集。
频繁K项集:K个项的项集且是频繁项集的称为频繁K项集。
支持度:项集的出项频率是包含项集的事务数,简称为项集的支持度。
MapReduce:是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)"是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
图1所示为本发明频繁挖掘方法的流程图。本发明方法应用于MapReduce平台,首先在MapReduce上得到每项出现次数,经过排序以及阈值筛选,剔除不符合的项,得到F-List,然后划分F-List得到G-List,根据G-List的划分,记录传给Mapper,并经过Mapper处理,将各个事务传给Reducer,在Reducer上进行MapReduce的挖掘部分。首先需要得到每个Reducer上的PPCTree,得到PPCTree后进而得到N-List,以及各个Reducer上对应项的G-Subsume,最后根据N-List和G-Subsume递归得到最终的频繁项集。
更具体而言,本发明频繁挖掘方法的详细流程如下:
为实现上述目的,本发明有以下步骤:
(1)通过Mapreduce统计原始数据中各项的出现次数。其子步骤为:
(1-1)对原始数据库进行水平分片处理,分片得到的每一个子文件叫做Block块,Block块被分配到集群中的节点上,该步骤由Hadoop平台自动进行;
(1-2)Block块作为每个Map函数的输入数据,Mapper的输入键值对是<key,value=Ti>,Ti表示Block块中的一条数据。对于数据Ti中的每一个项aj,Mapper输出键值对<key=aj,value=1>;
(1-3)Reduce合并来自各个Mapper的键值对。具体而言,所有key=aj的键值对将被分配到同一个Reducer,所以Reducer的输入是<key=aj,value={1,1,...,1}>。Reducer只需要进行一次求和,然后输出<key=aj,value=sum{1,1,...,1}>;
(2)依据各项出现次数筛选出频繁一项,并按照出现次数由高到低排序构建得到包含频繁一项和对应出现次数信息的F-List。其子步骤如下:
(2-1)上述操作完成后,Reducer的输出键值对结果保存在HDFS上,从HDFS上读取结果文件;
(2-2)排序并剔除不符合项。根据键值对中value值进行降序排序,同时,根据给定阈值,剔除小于阈值的项,得到F-List;
(3)按照负载均衡原则对F-List中的各项分组,得到包含项和其所属组号信息的G-List。其子步骤如下:
(3-1)提前对F-List中的每一项负载进行预测,按照负载均衡原则划分F-List;
(3-2)根据F-List划分结果构建G-List。G-List包含两项:项和其所属组号信息gid。同时,构造哈希表存储;
(4)Mapper对原始数据进行分配:
(4-1)对每条数据的各项按照F-List中项顺序进行重新排序;
(4-2)从每条数据的最后一项开始读取项item,在G-List中查找item的组号gid,然后以gid作为键key,将排在item前面的所有项作为值value构成键值对<key=gid,value=items>,作为Mapper输出的键值对,若组号gid已出现过,则忽略,继续取前一项进行相同操作,直到一条数据处理完毕;
(5)Reducer对Mapper输出的键值对进行频繁项集挖掘:
(5-1)根据Mapper输出的key=gid,将value=items分配给相应的reducer,reducer构建PPCtree;PPCtree为树状结构,每个节点包含五个属性值:名字、支持度frequency、子节点、前序遍历序号pre和后序遍历序号post;
(5-2)对于PPC-tree中每个节点Ni,将<Ni.pre,Ni.post,Ni.frequency>命名为PP-code,将各PP-code按照pre的升序排序,构建得到F-List中每个频繁一项的N-List;
(5-3)构建该Reducer的G-Subsume。G-Subsume为本发明提出的新概念:G-Subsume(A)={A,B∈I1,A和B表示两个不同的频繁一项,A.gid表示项A的组号,Reducer.gid表示Reducer对应的组号。G-Subsume仅针对于频繁一项集,即找出所有该Reducer对应gid的对应的频繁一项集的G-Subsume。A.gid∈Reducer.gid表示仅针对Reducer.gid对应的频繁一项集寻找G-Subsume。每条数据有对应的ID,g(X)表示包含项X的数据ID的集合,则表示包含项A的每条数据中一定包含项B,而包含项B的每条数据中不一定包含项A。G-Subsume等价于针对Reducer.gid对应的频繁一项集找到其祖先的集合,在后续挖掘中,显而易见,若A的G-Subsume为{A1,A2,…,Am},则该集合的2m-1个非空子集与A的结合的支持度等于A的支持度,该特性可以用于后续频繁项集挖掘,如若G-Susbume(A)={B},XA是频繁项,则XBA必为频繁项。
(5-4)递归挖掘,其子步骤如下:
a)以F-List作为第一轮的递归初始数据,从最后一项L的N-List即NLast开始进行递归,将最后一项L与其G-Subsume结合,生成频繁二项集,写入结果数组Result,并不作为递归挖掘频繁三项集的初始数据,仅作为结果数据加入Result;
b)在递归初始数据中从前往后的分别将项X的N-List即NX的PP-code与NLast的PP-code进行比较,若X存在于L的G-Susbume中,则继续取后一项,否则:当NX的PP-code的pre小于NLast的PP-code,且NX的PP-code的post大于NLast的PP-code的post,则将结果<NX.PP-code.pre,NX.PP-code.post,NLast.PP-code.frequency>加入新的N-List,名字为XL,且NLast的PP-code后移;若当NX的PP-code的pre小于NLast的PP-code,且NX的PP-code的post小于NLast的PP-code的post,则NX的PP-code后移;若当NX的PP-code的pre大于NLast的PP-code,则NLast的PP-code后移,直到NLast和NX的PP-code都遍历完毕,这种方法可以减小复杂度,若将NLast和NX的每个进行比较,复杂度为O(mn),m和n分别为NLast和NX的长度,而这种方法的复杂度仅为O(m+n),NX的PP-code遍历完毕后,若最后结果XL的N-List的PP-code的支持度之和不满足阈值,则删除XL,若满足则XL为频繁二项集;
c)继续将后一个项的N-List的PP-code与NLast的PP-code进行比较即重复步骤b),直至所有项比较完毕,即得到了以最后一项L为后缀的频繁二项集的集合{AL,BL…}及其每项的N-List,写入结果数组Result并将其N-List作为频繁三项集挖掘的初始数据,由于上述(5-3)介绍的特性,该频繁二项集直接与L的G-Subsume合并得到以L为后缀的部分频繁三项集,加入Result;
d)继续取前一项进行上述a)、b)、c)操作,直至所有项操作完毕,即得到了所有的频繁二项集和部分频繁三项集,上述步骤可知所有与G-Subsume合并得到的频繁项集不作为递归挖掘的初始数据,即下一步挖掘频繁三项集并不使用与G-Subsume合并得到的频繁项集;
e)得到所以的频繁二项集后,进一步挖掘频繁三项集,仅前缀不一样的两项才可能得到频繁三项集,即AX和BX才能进行判断是否能得到频繁三项集。提取仅前缀不一样的频繁二项集作为第二轮的递归初始数据,从最后一项开始与其前面的项进行比较,从前往后比较,比较方式与b)-d)步骤相同,对AX和BX的N-List进行比较,最后循环比较得到所有的频繁三项集,并将频繁三项集中后缀有G-Subsume的项与其G-Subsume结合得到频繁四项集;
f)以此类推,直到最后通过N-List比较得到的频繁K项集(即不包括G-Subsume合并得到的频繁K项集)中只有一个项,递归结束;
(5-5)Reducer输出<key=item∈gid,value=Result>,完成所有的频繁项集挖掘过程。
至此完成频繁项集挖掘的所有步骤,下面以游戏应用为例讲解该发明的应用:
1)对游戏用户分群,本发明采用根据用户使用英雄个数和用户使用英雄序列长度来制作热度图,进而分割用户群体。
2)数据去噪,在原始数据中,存在很多无用的干扰数据,如第一局游戏中必须使用的英雄,该数据没有任何意义,需要进行数据去燥,得到不同人群用户的有意义的使用英雄序列。
3)将该算法应用于该序列,得到挖掘的最后结果,即用户使用英雄序列的频繁模式,逐步引导用户由用户使用个数少、用户使用英雄序列长度短到用户使用个数多、用户使用英雄序列长度长的人群中。
图2所示为本发明Mapper和Reducer进行频繁项集挖掘的流程图,首先在Mapper中,每条数据按照F-List的顺序进行排序,根据G-List的划分,每条数据经过循环处理,将处理结果传给Reducer;在Reducer上,首先需要得到每个Reducer上的PPCTree,得到PPCTree后进而得到N-List,以及G-Subsume,最后根据递归挖掘得到最终的频繁项集。
图3所示为本发明中PPCTree的构建过程,以图中输入为实例,首先按照ABC的顺序依次向根节点为空的树中插入,第二条数据为B、C,首先查找根节点下是否B节点,未发现B节点,新建并插入B节点,查找B节点下是否有C节点,未发现C节点,新建并插入C节点;第三条数据为A、B、D,首先查到到A和B节点,但是B节点的子节点未发现D节点,在B节点下新建插入D节点;最后一条数据为B、D,首先查找到B节点,但未在B节点的子节点中发现D节点,在B节点下新建并插入D节点,最后完成PPCTree的构建。
图4所示为本发明递归挖掘中由频繁一项集得到频繁二项集的流程图,首先由最后一项Ln与其G-Subsume合并得到部分频繁二项集,从前往后,将每一项与Ln的G-Subsume进行比较,看该项是否包含于G-Subsume中,若包含则去下一项,不包含则将该项的N-List与Ln的N-List进行比较,比较每个PP-code,比较规则如下:当Nx的PP-code的pre小于Nn的PP-code,且Nx的PP-code的post大于Nn的PP-code的post,则将结果<Nx.PP-code.pre,Nx.PP-code.post,Nn.PP-code.frequency>加入新的N-List,名字为LxLn,且Nn的PP-code后移;若当Nx的PP-code的pre小于Nn的PP-code,且Nx的PP-code的post小于Nn的PP-code的post,则Nx的PP-code后移;若当Nx的PP-code的pre大于Nn的PP-code,则Nn的PP-code后移,直到Nn和NX的PP-code都遍历完毕,若最后结果XL的N-List的PP-code的支持度之和不满足阈值,则删除XL,若满足则XL为频繁二项集;继续将后一个项的N-List的PP-code与Nn的PP-code进行比较,直至所有项比较完毕,即得到了以最后一项Ln为后缀的频繁二项集,再取Ln的前一项,进行同样的操作,直至取到第二项结束,即得到了所有的频繁二项集,后续频繁k项集的挖掘方法类似于频繁二项集的挖掘方法,不做过多阐述,需要注意的是G-Subsume后续合并是根据频繁项后缀的G-Subsume来进行合并,以及采用G-Subsume与项合并产生的频繁k项集不需要作为频繁k+1项集的初始数据,仅仅作为挖掘结果,以及后续频繁k项集挖掘中,N-List的比较仅仅在仅前缀不同的两项中进行比较,如AX和BX进行比较。
图5所示为本发明中负载均衡策略的示意图,对于每项,需要将其加入对应的G-List中的组,组号gid,一般情况下,会采取取余的方式来进行分组,但是有些项递归时间久,有的递归时间短,会造成最后结果等待时间以最久的项为准,同时也会造成负载不均衡,为了均衡负载,采取该负载均衡策略,本发明提前预估每个项的负载,预估采用以下几个依据:
1)在深度优先模式下,PPCTree树的深度影响着对树进行先序、后序遍历的时间,深度越大耗时越多;
2)当合并两个频繁项集对应的N-List时其时间复杂度为两个N-List长度之和;
3)每一项所在PPCTree树的最大路径长度等于它在F-List中相应的排序号,而该项所对应的N-List结构的最大长度等于该项的支持数与2n-1二者之间的最小值,其中n为该项在F-List中的序号;
所以用F-List中的相应序号估算每项的负载,估算负载后,为了达到负载均衡,本发明采用贪心算法,将每项加入现有组负载之和最小的那一组中,直到所有项分配完毕。
图6所示为本发明中MapReduce过程的示意图。本发明要经历两次MapReduce过程,第一MpaReuce由Map输出<key=item,value=1>,Reducer进而对每项的value相加,输出<key=item,value=sum{1,1…1}>,第二次MapReduce则是进行数据挖掘,得到了F-List和G-List后,依照N-List和Subsume进行数据挖掘得到最终结果。
本发明采用上述方案,在性能上优于其他并行算法方案,并且在游戏挖掘性能上得到很大的提升,具体如下:
1)使用N-List,这种方法可以减小复杂度,在一般的频繁项集挖掘方法中,均使用树来进行递归,不仅占用空间而且树递归复杂度远远超过该方法的递归,同时本方法采用独特的比较方法,并没有将N-List中的每个PP-code进行比较,若将两个N-List的每个PP-code进行比较,复杂度为O(mn),m和n分别为两个N-List的长度,而这种独特比较方法的复杂度仅为O(m+n),也大大减小了递归复杂度;
2)使用新的概念G-Subsume用于MapReduce的并行,在频繁项集挖掘过程中,通过G-Subsume可以减少N-List的合并比较次数,而是直接与G-Subsume进行合并,大大提高了挖掘效率;
3)一般情况下,G-List会采取取余的方式来进行分组,但是有些项递归时间久,有的递归时间短,会造成最后结果等待时间以最久的项为准,同时也会造成负载不均衡,为了均衡负载,本发明提前预估每个项的负载:在深度优先模式下,PPCTree树的深度影响着对树进行先序、后序遍历的时间,深度越大耗时越多;每一项所在PPCTree树的最大路径长度等于它在F-List中相应的排序号,而该项所对应的N-List结构的最大长度等于该项的支持数与2n-1二者之间的最小值,其中n为该项在F-List中的序号。根据以上两个规则可以轻易的预估每个项的负载,即可以实现本发明的负载均衡。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!