基于神经网络的特征点识别方法与流程
本发明涉及虚拟现实领域,更具体地说,涉及一种基于神经网络的特征点识别方法。
背景技术:
空间定位一般采用光学或超声波的模式进行定位和测算,通过建立模型来推导待测物体的空间位置。一般的虚拟现实空间定位系统采用红外点和光感摄像头接收的方式来确定物体的空间位置,红外点在近眼显示装置的前端,在定位时,光感摄像头捕捉红外点的位置进而推算出使用者的物理坐标。如果知道至少三个光源和投影的对应关系,再调用PnP算法就可得到头盔的空间位置,而实现这一过程的关键就是确定投影对应的光源ID(Identity,序列号)。目前的虚拟现实空间定位在确定投影对应光源ID时常常存在对应不准确和对应时间过长的缺点,影响了定位的准确性和效率。
技术实现要素:
为了解决当前虚拟现实空间定位方法确定投影ID(Identity,序列号)的准确性和效率不高的缺陷,本发明提供一种可以提高投影ID准确性和效率的基于神经网络的特征点识别方法。
本发明解决其技术问题所采用的技术方案是:提供一种基于神经网络的特征点识别方法,包括以下步骤:
S1:利用经过预处理的图片训练神经网络;
S2:保持虚拟现实头盔的红外点光源处于开启状态,红外摄像头拍摄;
S3:对图片进行预处理,得到预处理图像;
S4:将S3得到的预处理图像输入神经元即可得到每个光斑对应的所述红外点光源的ID。
优选地,所述图像预处理可以采用如下方法:
S11:对于给定的输入图像,将图像经过处理单元转换为32×32像素的黑白图像,
S12:找到每个光斑的中心点,在每个中心点上叠加一个小半径的区别于周围环境的其它颜色的光斑,叠加上去的光斑占用1个像素的大小。
优选地,叠加的所述光斑的颜色为黑色。
优选地,神经元输入等于每个像素的归一化后的灰度值,越靠近黑色其值越接近1,越靠近白色其值越接近0。
优选地,通过所述红外摄像头捕捉各个方向和各种位置下的所述红外点光源图像,将这些图像经过图像预处理后用于神经网络训练。
优选地,所述处理单元结合上一帧已知的历史信息对上一帧图像的光斑点做一个微小的平移使上一帧图像的光斑点与当前帧图像的光斑点产生对应关系,根据该对应关系和上一帧的历史信息判断当前帧图像上有对应关系的每个光斑点的对应ID。
与现有技术相比,本发明通过将神经网络的算法引入虚拟现实空间定位的方法,提供了一种确定光斑ID的方法,准确且高效。通过对训练图像和测试图像进行预处理,防止了图片的多样化对识别准确率产生影响,将多样化的图片进行标准化处理,大大增加了ID识别的成功率和准确性。32×32像素的黑白图像及1个像素值的光斑一方面减少了神经元的个数,提升了计算速度,另一方面保证了识别的准确性。通过灰度判断神经元输入的值可以简化判断过程,增加识别效率。通过各个方向和各种位置下虚拟现实头盔的红外点光源的显示来制作训练材料,使ID识别更加全面。后续跟踪定位时,通过添加位移的方式判断新增光斑及其对应ID,使得定位过程更加简单,不需要一遍遍地重新进行识别。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明基于神经网络的特征点识别方法原理示意图;
图2是本发明基于神经网络的特征点识别方法红外点光源分布示意图;
图3a是用于训练的预处理图像之一示意图;
图3b是用于训练的预处理图像之二示意图;
图3c是用于训练的预处理图像之三示意图;
图3d是用于训练的预处理图像之四示意图;
图3e是用于训练的预处理图像之五示意图。
具体实施方式
为了解决当前虚拟现实空间定位方法确定投影ID的准确性和效率不高的缺陷,本发明提供一种可以提高投影ID准确性和效率的基于神经网络的特征点识别方法。
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
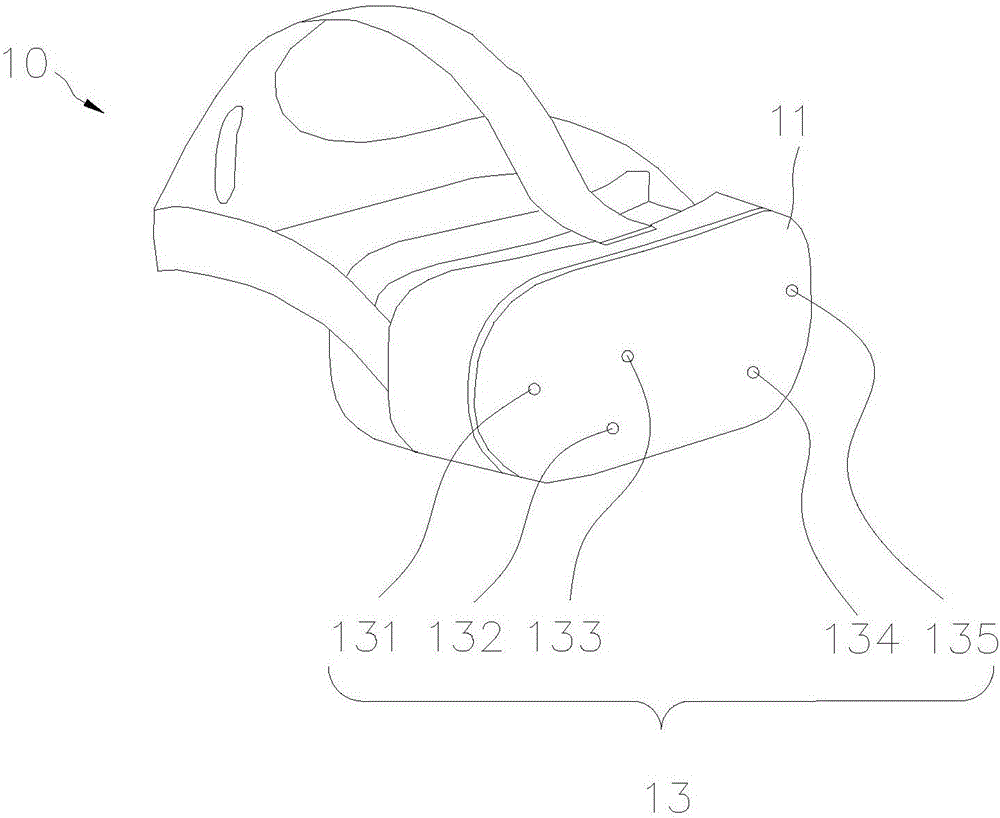
请参阅图1—图2。本发明基于神经网络的特征点识别方法包括虚拟现实头盔10、红外摄像头20和处理单元30,红外摄像头20与处理单元30电性连接。虚拟现实头盔10包括前面板11,在虚拟现实头盔10的前面板11及上、下、左、右四个侧面板分布有多个的红外点光源13。红外点光源13的数量至少要满足PnP算法可以运行的最小数量。红外点光源13的形状没有特别的限制,为了举例说明,我们取红外点光源13数量为5个,5个红外点光源组成近似“w”的形状。5个红外点光源13包括设置在前面板11上的第一红外点131、第二红外点132、第三红外点133、第四红外点134、第五红外点135,其中,第一红外点131、第三红外点133、第五红外点135排列成一条直线。多个红外点光源13可以通过虚拟现实头盔10的固件接口根据需要点亮或者关闭。虚拟现实头盔10上的红外点光源13通过红外摄像头20在图像上形成光点,由于摄像头透视变换的固有性质,同一直线上的红外点光源13在图像上形成的光点仍然在同一直线上。
图3a—3e示出了用于训练的图像示意图。在利用神经网络对输入图像进行处理之前,首先需要对神经网络进行训练。用于训练的图像材料主要为各个方向各种位置下的虚拟现实头盔10上的红外点光源13通过红外摄像头20捕捉到的图像,这些图像经过图像预处理后被转换为32×32像素的黑白图像,光斑占用1个像素。图像预处理可以采用如下方法:对于给定的输入图像,将图像经过处理单元30转换为32×32像素的黑白图像,然后通过SimpleBlob等用于寻找光斑中心点的方法找到每个光斑的中心点,在每个中心点上叠加一个小半径的区别于周围环境的其它颜色的光斑,叠加上去的光斑占用1个像素的大小,便于处理单元30进行识别。这里我们将像素的颜色设定为黑色,背景颜色设定为白色。神经网络的训练采用Backpropagation算法进行处理,输入层与输入图像直接相连,神经元个数等于图片的像素点数。我们首先用32×32像素的黑白图像对神经网络进行训练,在这些图像中,光斑占用1个像素,神经元输入等于每个像素的归一化后的灰度值,例如越靠近黑色其值越接近1,越靠近白色其值越接近0。输出层代表期望输出的一个编码,本发明的输出层取5个神经元。图3a—3e的5幅图像是用于训练的图像的其中5幅,分别对应(1,1,1,1,0)、(1,1,1,0,1)、(1,1,0,1,1,)、(1,0,1,1,1)、(0,1,1,1,1,)。输入图像经过预处理后会以32×32像素的黑白图像进行输入。
当ID识别开始时,虚拟现实头盔10处于初始状态,保持前面板11上的5个红外点光源13处于点亮状态,为了确保识别准确性,需要尽量保证所有光源都能通过红外摄像头20形成光斑,不被遮挡或者处于红外摄像头20的视场之外,如果过多的红外点光源13被遮挡对于ID识别和空间定位都会有一定的影响。5个红外点光源13在图像上会形成光斑,处理单元30对图像进行预处理形成32×32像素的黑白图像并将其输入经过训练的神经元,即可对应得出图像上每个光斑对应的红外点光源的ID。
在ID识别结束后,处理单元30可以跟踪每个光斑点并标定对应ID,具体方法是:在空间定位时,由于每帧的采样时间足够小,一般为30ms,所以一般情况下上一帧的每个光斑点和当前帧上的每个光斑点的位置差别很小,处理单元30结合上一帧已知的历史信息对上一帧图像的光斑点做一个微小的平移使上一帧图像的光斑点与当前帧图像的光斑点产生对应关系,根据该对应关系和上一帧的历史信息即可判断当前帧图像上有对应关系的每个光斑点的对应ID。
ID识别完成后,处理单元30再调用PnP算法就可得到头盔的空间定位位置,PnP算法属于现有技术,本发明不再赘述。
与现有技术相比,本发明通过将神经网络的算法引入虚拟现实空间定位的方法,提供了一种确定光斑ID的方法,准确且高效。通过对训练图像和测试图像进行预处理,防止了图片的多样化对识别准确率产生影响,将多样化的图片进行标准化处理,大大增加了ID识别的成功率和准确性。32×32像素的黑白图像及1个像素值的光斑一方面减少了神经元的个数,提升了计算速度,另一方面保证了识别的准确性。通过灰度判断神经元输入的值可以简化判断过程,增加识别效率。通过各个方向和各种位置下虚拟现实头盔10的红外点光源13的显示来制作训练材料,使ID识别更加全面。后续跟踪定位时,通过添加位移的方式判断新增光斑及其对应ID,使得定位过程更加简单,不需要一遍遍地重新进行识别。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!