一种基于特征变量算法的图像内容信息分析方法与流程
本发明涉及图像内容信息分析技术领域,特别是一种基于特征变量算法的图像内容信息分析方法。
背景技术:
随着互联网技术的发展,信息传播速度越来越快,在能够获取大量信息的同时,网络上肆意传播的低俗内容图片污染网络环境,如何能够快速准确地识别出含有低俗内容的图片是亟待解决的问题。目前的图片低俗成人检出方法,一般分为两类方法。一种是人工检测,此种方法需要人力成本大,检测速度慢,标准不一致,对于大量的互联网信息,效果并不理想;另一种方法是通过整幅图像的颜色进行简单判别,此类方法误判性高,使用效果差。
深度学习是机器学习里面的一个热门领域,起源于多层人工神经网络,目前已成功应用于计算机视觉。其中卷积神经网络在图像识别领域已经取得了令人瞩目的成就,相比传统的图片内容识别方法方法有了很大的提升。
简单的训练方法和结果处理模式并不能够满足多样的低俗图片内容检测需求,因此,研究一种适应于深度网络模型低俗内容的层级分类方法及结果优化策略对于低俗内容检测领域具有重要的研究价值和应用前景。
技术实现要素:
本发明需要解决的技术问题是提供一种基于特征变量算法的图像内容信息分析方法。
为解决上述的技术问题,本发明的一种基于特征变量算法的图像内容信息分析方法,包括以下步骤,
(1)将所有的训练样本集图片根据需求分为多个一级大类,并在一级大类基础上二次划分为多个一级类;
(2)使用训练完成的深度网络模型对图片进行分类,模型计算得出的各类别置信度Pi,通过对比置信度差值P=PTOP1-PTOP2与阈值Th的关系,若P小于阈值Th,则根据PTOP1和PTOP2类别,进行相应的优化策略调整;若P大于阈值Th,则认为分类结果可信,不做调整,直接输出。
进一步的,步骤(1)中确定每个一级类下多个二级类的方法为应用聚类算法,提去样本图片的颜色信息和纹理信息作为聚类依据,确定最为合理地二级类分类方法。
进一步的,步骤(2)中阈值Th的计算方法为对于所有一级大类测试样本的分类结果,存在正确分类样本和错误分类样本,将所有正确分类样本置信度结果的前两位做差值并求和取平均得到正确分类样本的平均置信度差值;同样的,将所有错误分类样本置信度结果的前两位和做差值并求和取平均得到错误分类样本的平均置信度差值;分别计算正确分类样本的平均置信度差值和错误分类样本的平均置信度差值与惩罚系数的乘积,将两结果相加得到阈值。
更进一步的,步骤(2)中阈值Th的计算公式为:其中,为正确分类样本的平均置信度差值,为错误分类样本的平均置信度差值,α为错误惩罚系数。
更进一步的,确定所述平均置信度差值的公式为:其中,为样本的平均置信度差值,PTOP1为样本的置信度结果最高值,PTOP2为样本的置信度结果次高值,N为样本数量。
采用上述方法后,本发明应用多层级分类策略,将简单的正样本和负样本的二类划分方法细化,并使用聚类算法优化划分结果,得到二级类间距最大的划分方式,有助于加大类间区别,增加深度学习网络对图片特征的认识能力,提高整体识别精准度。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1为本发明层级分类及优化策略流程图。
图2为本发明阈值计算流程图。
具体实施方式
考虑到目前网络中有大量低俗和限制内容图片无法被精确快速检出过滤的问题,本发明使用了深度学习网络模型对图片内容进行识别分类,并引入层级分类以及结果优化策略对网络模型进行优化,大大提高了检测精度。
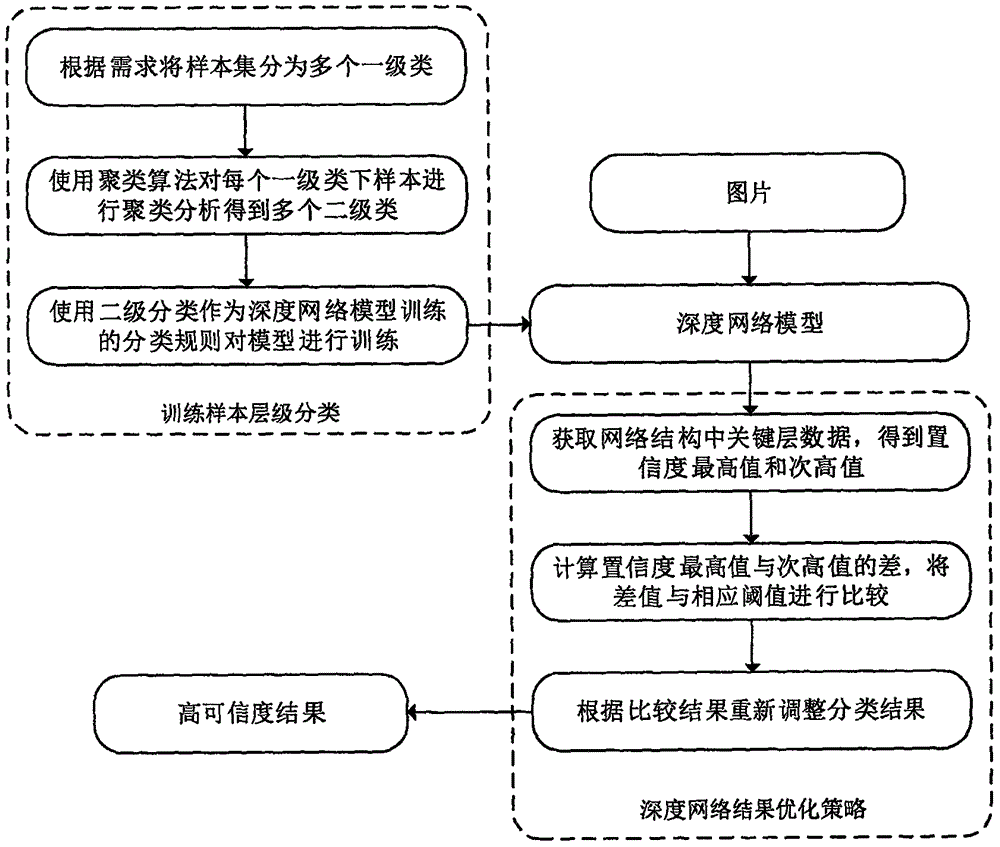
如图1所示,本发明一种基于特征变量算法的图像内容信息分析方法,在使用数据对深度网络模型进行训练之前,先对训练样本集进行层级分类处理,具体步骤如下:
(1)将所有的训练样本集图片根据需求分为多个一级大类,并在一级大类基础上二次划分为多个一级类;
(2)使用训练完成的深度网络模型对图片进行分类,模型计算得出的各类别置信度Pi,通过对比置信度差值P=PTOP1-PTOP2与阈值Th的关系,若P小于阈值Th,则根据PTOP1和PTOP2类别,进行相应的优化策略调整;若P大于阈值Th,则认为分类结果可信,不做调整,直接输出。
步骤(1)中确定每个一级类下多个二级类的方法为应用聚类算法,提去样本图片的颜色信息和纹理信息作为聚类依据,确定最为合理地二级类分类方法。训练样本集层级分类处理结束后,使用分好类的16000张训练集图片对深度学习网络模型进行训练得到适用于低俗内容检测的分类模型。
使用低俗内容检测分类模型进行图片低俗内容识别时,提取网络模型中“Softmax”层数据,对结果进行优化处理,具体步骤为:
1.提取置信度最高值PTOP1和置信度次高值PTOP2。
2.计算PTOP1和PTOP2差值P。
3.将P和阈值Th比较,进行相应的结果优化调整并输出。
其中,阈值的计算流程图如图2所示,具体步骤为:
1.使用10000张测试图片对得到的网络进行测试,得到测试结果。
2.将一级类测试结果分为正确分类和错误分类两大类。
3.提取每个样本的PTOP1和PTOP2。
4.计算置信度差值P=PTOP1-PTOP2。
5.分别求所有正确分类样本的平均置信度差值和错误分类样本的平均置信度差值的计算公式为:其中,为样本的平均置信度差值,PTOP1为样本的置信度结果最高值,PTOP2为样本的置信度结果次高值,N为样本数量。
本范例中,如图2所示,使用得到的优化策略如下:
1.低俗大类和限制内容大类的类别阈值Thd-x为0.10,即PTOP1和PTOP2所属二级类别分别为低俗内容二级类和限制内容二级类时,P小于0.10则认为是低俗内容。
2.限制内容大类和正常内容大类的类别阈值Thx-z为0.15,即PTOP1和PTOP2所属二级类别分别为正常内容二级类和限制内容二级类时,P小于0.15则认为是限制内容。
3.低俗大类和正常内容大类的类别阈值Thd-z为0.20,即PTOP1和PTOP2所属二级类别分别为正常内容二级类和低俗内容二级类时,P小于0.25则认为是低俗内容。
4.置信度差值P为0.5以上,则认为是置信度最高的二级类所述一级类为最终分类结果。
5.置信度最高PTOP1低于0.4时,且与置信度次高值PTOP2相差在0.15以下时,不论最高分值类别,归为正常内容一级类。
虽然以上描述了本发明的具体实施方式,但是本领域熟练技术人员应当理解,这些仅是举例说明,可以对本实施方式作出多种变更或修改,而不背离本发明的原理和实质,本发明的保护范围仅由所附权利要求书限定。
- 还没有人留言评论。精彩留言会获得点赞!