多标准误分类代价敏感决策树构建方法与流程
本发明涉及人工智能、数据挖掘和机器学习领域,具体涉及一种多标准误分类代价敏感决策树构建方法。
背景技术:
在归纳学习技术中如何尽量减少误分类错误是主要焦点,例如CART和C4.5。在归纳问题上误分类不仅是一个错误,即错误分类所带来的代价不容忽略。在代价敏感学习CLS算法中,误分类代价为同一单位标准,但在现实世界的应用程序误分类代价通常有不同的单位。把不同单位标准的误分类代价量化成一个唯一单位代价是非常困难的。分裂属性选择是决策树构建的一个关键又基本过程,最流行的属性选择方法侧重于测量属性的信息增益。当错误分类所引起的代价不容忽视时,很自然地把降低代价机制和属性信息结合起来作为分裂属性选择标准,这样构成的决策树既提高了分类精度,同时误分类代价达到最优,我们的目的就是得到最低的误分类代价。这样形成的决策树更适合在医疗诊断过程中。基于这种需求,本发明提出多标准误分类代价敏感决策树构建方法。
技术实现要素:
本发明所要解决技术问题是决策过程中误分类代价和属性信息之间的平衡性问题、误分类代价不同单位机制问题以及构成的决策树过度拟合问题,提供一种多标准误分类代价敏感决策树构建方法。
为解决上述问题,本发明的是通过以下技术方案实现的:
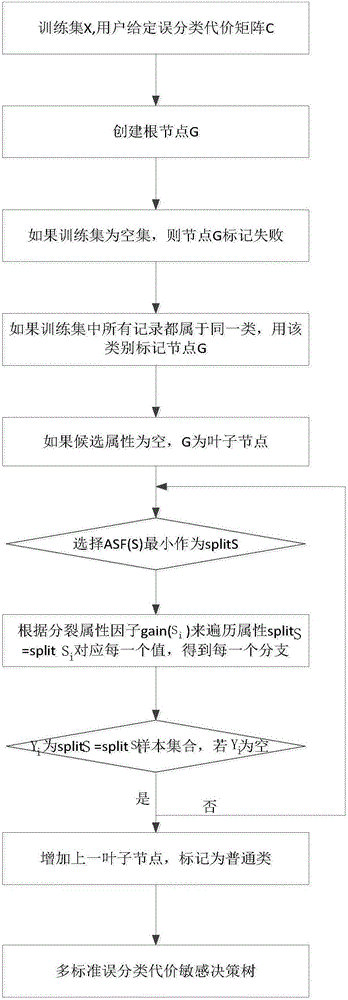
多标准误分类代价敏感决策树构建方法,包括如下步骤:
步骤1.设训练集中有X个样本,属性个数为n,即n=(s1,s2,…sn),同时分裂属性sr对应了m个类L,其中Li∈(L1,L2…,Lm),r∈(1,2…,n),i∈(1,2…,m)。设误分类代价矩阵为C,C由用户指定。
步骤2:创建根节点G。
步骤3:如果训练数据集为空,则返回节点G并标记失败。
步骤4:如果训练数据集中所有记录都属于同一类别,则以该类型标记节点G。
步骤5:如果候选属性为空,则返回G为叶子节点,标记为训练数据集中最 普通的类。
步骤6:根据代价敏感的候选属性选择因子ASF候选属性中选择splitS。
候选属性选择因子ASF:
averagegain(S)为选择属性S的平均信息增益,reduce_mc(S)为选择属性S作为分裂属性时的误分类代价减少率。
当选择属性splitS满足目标函数ASF(S)最小时,则找到标记节点G。如果一些属性具有相同的ASF值,为了打破平局的标准,再按照更大的reduce_mc(S)值来优先选择候选属性。这样构建的决策树优先遵从误分类代价最低的原则。
步骤7:标记节点G为属性splitS。
步骤8:由根据基尼指数gini(Si)值延伸出满足条件为splitS=splitSi分支。
8.1这里假设Yi为训练数据集中splitS=splitSi的样本集合。满足以下两条件之一,则终止建树。
(1)如果Yi为空,加上一个叶子节点,标记为训练数据集中最普通的类。
(2)在一节点中所有例子属于相同类。
步骤9:非8.1中情况,则递归调用步骤6至步骤8。
步骤10:为避免决策树中存在过渡拟合问题,利用后剪支技术对决策树进行剪支操作。
本发明的有益效果:
1,对属性信息增益进行优化处理,避免因属性信息增益过小而忽略了属性信息的风险。
2,把不同单位标准的误分类代价量化为同一单位标准,降低了误分类代价单位异质性对分裂属性选择的影响。
3,考虑了误分类代价和属性信息之间的平衡性,在决策过程中,使得误分类代价达到最小,同时提高了决策树分类精度。
4,构建多标准误分类代价敏感决策树有效地避免了过度拟合的问题。
附图说明
附图为多标准误分类代价敏感决策树结构流程图
具体实施方式
1、上述步骤1中误分类代价矩阵C的设定过程如下:
类别标识个数为m,则该数据的代价矩阵m×m方阵是:
其中Cij表示第j类数据分为第i类的代价,如果i=j为正确分类,则Cij=0,否则为错误分类Cij≠0,其值由相关领域用户给定,这里i,j∈(1,2,…,m)。
2、上述步骤6中求解候选属性选择因子ASF,需求解出候选属性S的平均信息增益averageGain(S)、误分类代价减损率reduce_mc(S),其具体求解过程如下:
步骤6.1,训练集X的基尼指数gini(X)
其中m为训练集X的类个数,p(Li)为训练集X对应Li类的概率。
步骤6.2.候选属性S的信息增益Gain(S)
根据基尼指数gini(X)定义,属性S的信息增益为:
Gain(S)=gini(X)-gini(S,X)
其中gini(S,X)表示当属性S作为分裂属性分裂后在所有类中剩余的基尼指数,即:
这里属性S有j个属性值,则第j个属性值样本数为Xj,即Xj>0;
p(Li)为属性值Sj对应的类概率。
即候选属性S的信息增益:
步骤6.3,候选属性S的平均信息增益averageGain(S)
根据Gain(S),可得平均候选属性S的信息增益averageGain(S)
其中j为属性S的属性值个数,即分支节点个数。
averageGain(S)作用:有更好的分类精度。
步骤6.4误分类代价减损率reduce_mc(S)
mc是在候选属性S分裂前的误分类代价,这里S有j个分支,则表示候选属性S分裂之后总的误分类代价。
reduce_mc(S)作用:把误分类代价不同单位机制量化为同一单位,降低了误分类代价单位异质性对分裂属性选择的影响。
步骤6.5分裂属性选择因子ASF
(2averagegain(S)-1)作用:对属性信息增益进行优化处理,避免因属性信息增益过小而忽略了属性信息的风险。
ASF(S)能够很好的平衡由于误分类代价以及平均信息增益之间存在的异构难题,把属性分类能力与误分类代价共同融合进行候选属性选择,可以更好提高分类精度和降低误分类代价。
3、上述步骤8中求解基尼指数gini(Si),其具体求解过程如下:
splitS=splitSi分支基尼指数gini(Si)
设训练数据集X,其类有m个,那么其gini指标为:
其中p(Li/Si)为分裂属性Si属于Li类的相对频率,当gini(Si)=0,即在此结点处所有样例都属于同一类,表示能得到最大有用信息;当此结点所有样例对于类别字段来讲均匀分布时,gini(Si)最大,表示能得到最小的有用信息。
4、上述步骤10中利用后剪支技术对决策树进行剪支,目的是减少误分类,如悲观性错误剪枝和最小错误剪枝。悲观性错误剪枝通过比较剪枝前和剪枝后的错分样本数来判断是否剪枝,指在减少错分样本数。最小错误剪枝指在通过剪枝得到一棵相对于独立数据集来说具有最小期望错误率的决策树。
其剪支条件为:
根据条件Reduce_mc(S)<α
α为用户指定的值,剪枝的条件首先要满足尽可能使代价减损达到用户指定条件。
多标准误分类代价敏感决策树构建方法的伪代码如下:
输入:X个样本训练集,训练集的误分类代价矩阵C。
输出:多标准误分类代价敏感决策树。
- 还没有人留言评论。精彩留言会获得点赞!